Deep Learning-深度学习(六)
深度学习进阶
1、卷积神经网络基础
在之前的手写数字识别中,运用全连接的神经网络会有两个问题,即①图片输入之后空间信息会缺失;②模型的参数过多会发生过拟合的现象。为了弥补这种错误,于是引入了卷积神经网络。
1.1 卷积计算
卷积,数学分析中的一种积分变换的方法。在卷积神经网络中,卷积神经网络中,卷积层的实现方式是数学中的互相关运算,这与数学分析中的卷积有所不同,运算过程如图所示:
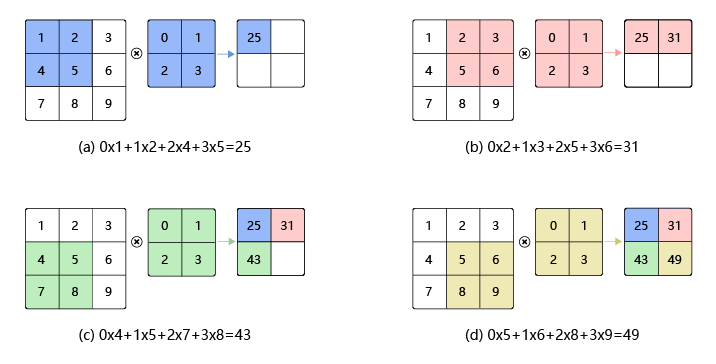
其中,卷积核也称作滤波器,假设卷积核的高和宽分别是K(h)和K(w),则将称为K(h)×K(w)卷积。如上图所示,每一组2×2的数组即为卷积核,通过滑动,从而得到四个值a,b,c,d。
卷积核的计算过程为:
![]()
其中, a 代表输入图片, b 代表输出特征图,w 是卷积核参数,它们都是二维数组,∑u,v 表示对卷积核参数进行遍历并求和。
以上图为例,其中的u,v就都能分别取0和1,即卷积核的长宽所能的长度,该例子计算如下:
![]()
此外,需要注意的是,卷积的每一步有时还有添加偏置的步骤,即加一个余项。
1.2 填充
在上面的例子中,输入图片尺寸为3×3,输出图片尺寸为2×2,经过一次卷积之后,图片尺寸变小。卷积输出特征图的尺寸计算方法如下(卷积核的高和宽分别为kh和kw):
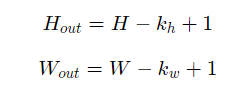
即如果输入尺寸为4,卷积核大小为3时,输出尺寸为4−3+1=2。因为通过卷积过后,图片的大小会减小,为了避免图片变小,通常会在外围进行填充,如下图:
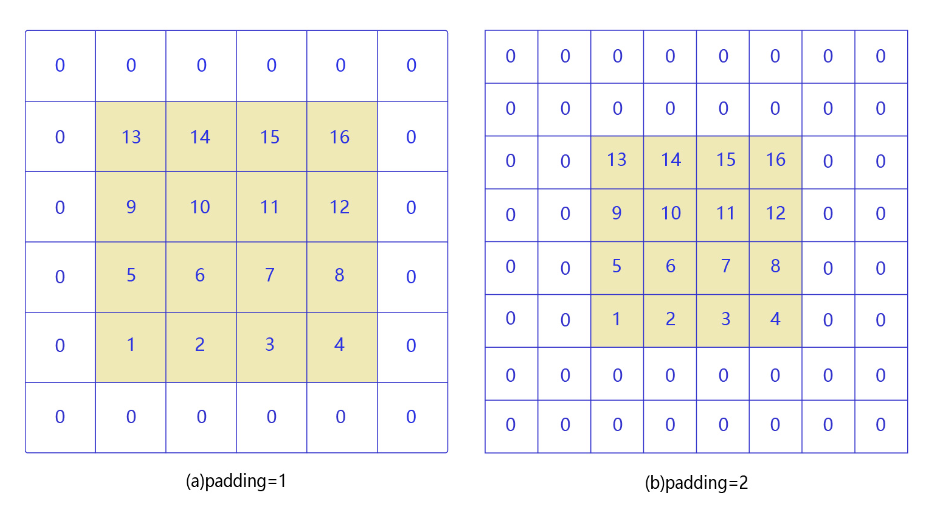
-
如图(a)所示:填充的大小为1,填充值为0。填充之后,输入图片尺寸从4×4变成了6×6,使用3×3的卷积核,输出图片尺寸为4×4。
-
如图(b)所示:填充的大小为2,填充值为0。填充之后,输入图片尺寸从4×4变成了8×8,使用3×3的卷积核,输出图片尺寸为6×6。
如果在图片高度方向,在第一行之前填充ph1行,在最后一行之后填充ph2行;在图片的宽度方向,在第1列之前填充pw1列,在最后1列之后填充pw2列;则填充之后的图片尺寸为
(H+ph1+ph2)×(W+pw1+pw2)。经过大小为kh×kw