Deep Learning-深度学习(三)
深度学习入门
1、NumPy案例运用
1.1 计算激活函数
激活函数:就像之前所学习的那样,所有的处理都还是基于线性的,然是在实际的运用当中是具有很多非线性的运算,并不是简单的加权和,而是各种数据直接还会相互影响,互相产生新的数据,从而得到新的数据。对于这些过程就需要激活函数来达到这种复杂非线性的计算。激活函数有几个性质,①可微性,因为是以梯度进行计算学学习,所以必须是要可微的。②单调性,这能保证单层网络是凸函数。③输出值的范围,当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定。
Sigmoid激活函数:使用范围最广的一类激活函数,为指数形状,十分接近物理意义的生物神经元,即S型生长曲线。
![]()
利用NumPy进行实现:
1 # x是1维数组,数组大小是从-10. 到10.的实数,每隔0.1取一个点 2 x = np.arange(-10, 10, 0.1) 3 # 计算 Sigmoid函数 4 s = 1.0 / (1 + np.exp(- x))
ReLU函数:即修正线性单元(Rectified linear unit,ReLU),通常以斜坡或者变种为代表的非线性函数。
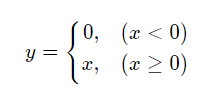
利用NumPy进行实现:
1 # 计算ReLU函数 2 y = np.clip(x, a_min = 0., a_max = None)
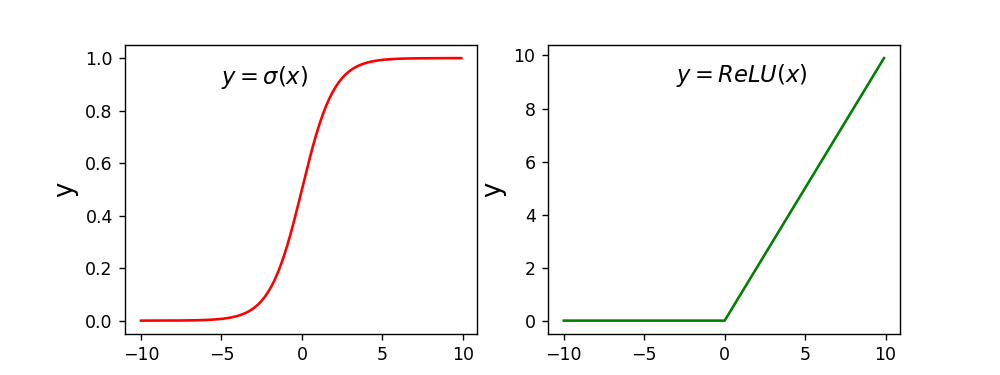
通过画图来直观的进行感受:
1 # 设置两个子图窗口,将Sigmoid的函数图像画在左边 2 f = plt.subplot(121) 3 # 画出函数曲线 4 plt.plot(x, s, color='r') 5 # 添加文字说明 6 plt.text(-5., 0.9, r'$y=\sigma(x)$', fontsize=13) 7 # 设置坐标轴格式 8 currentAxis=plt.gca() 9 currentAxis.xaxis.set_label_text('x', fontsize=15) 10 currentAxis.yaxis.set_label_text('y', fontsize=15) 11 12 # 将ReLU的函数图像画在右边 13 f = plt.subplot(122) 14 # 画出函数曲线 15 plt.plot(x, y, color='g') 16 # 添加文字说明 17 plt.text(-3.0, 9, r'$y=ReLU(x)$', fontsize=13) 18 # 设置坐标轴格式 19 currentAxis=plt.gca() 20 currentAxis.xaxis.set_label_text('x', fontsize=15) 21 currentAxis.yaxis.set_label_text('y', fontsize=15) 22 23 plt.show()
可得到:
这里需要知道的是其中的绘画函数plt.subplot的用法,借鉴一下其他的例子就是:
1 plt.subplot(221) 2 # plt.subplot(222)表示将整个图像窗口分为2行2列, 当前位置为2. 3 plt.subplot(222) # 第一行的右图 4 # plt.subplot(223)表示将整个图像窗口分为2行2列, 当前位置为3. 5 plt.subplot(223) 6 # plt.subplot(224)表示将整个图像窗口分为2行2列, 当前位置为4. 7 plt.subplot(224)
可以发现的是,这里的运算是可以通过np.arange的方式进行计算,可以少掉很多的麻烦,大大增加了简便性。
1.2 图像处理
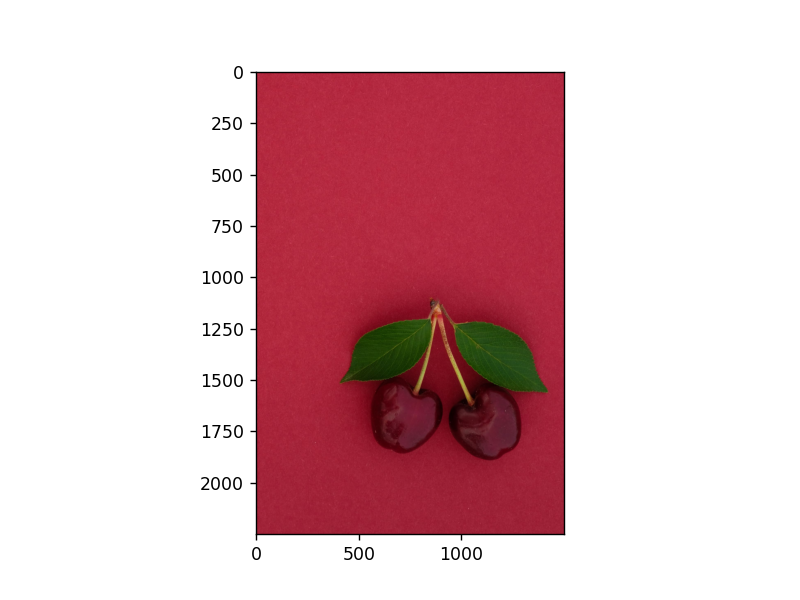
图像在计算机中进行存储是以数字的方式进行的,就是对应于不同位置的不同像素点构成一个矩阵,可以通过矩阵的特征值等进行对图片的处理。这里进行对图片的翻转和剪切,最主要的就是其数值可以用ndarray来表示。首先准备一张图片,如下:

现在对其进行利用代码来进行数据的提取,与数值的转化:
1 # 读入图片 2 image = Image.open('./work/images/000000001584.jpg') 3 image = np.array(image) 4 # 查看数据形状,其形状是[H, W, 3], 5 # 其中H代表高度, W是宽度,3代表RGB三个通道 6 print(image.shape)
该图片的RGB值为:
![]()
可以利用函数plt.imshow函数来查看原始的图片:
1 plt.imshow(image) 2 plt.show()
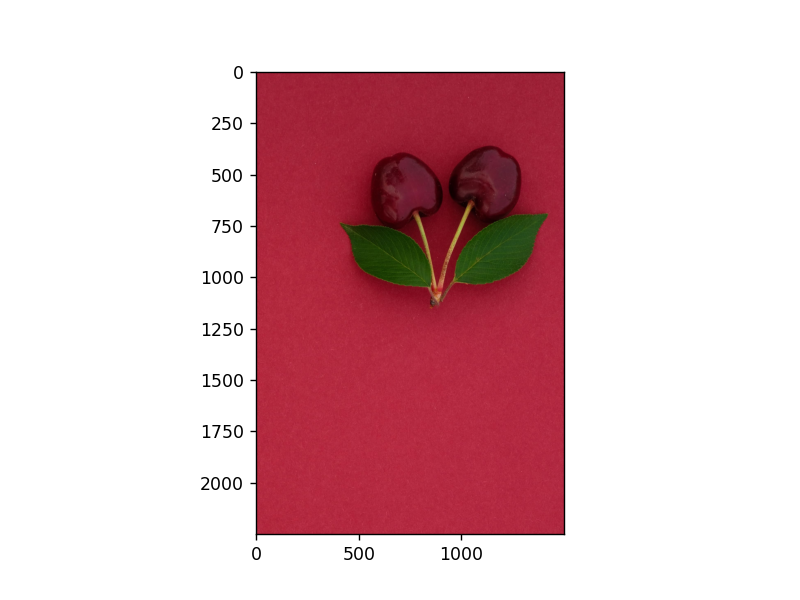
然后就是对图片进行翻转操作,这里的意思是很明显的,因为我们知道,现在的图片展示在计算机当中就是一个n阶的矩阵,进行翻转在计算机当中的意思就是进行矩阵行变换,最后的变为最前的,一 一进行变换。
1 image2 = image[::-1, :, :] 2 plt.imshow(image2) 3 plt.show()
这里使用数组反向切片的方式进行完成,即把图片的最后一行换到第一行,倒数第二行到正数第二行……,其中的::1,表示对于行指标的切片
可以看到结果为:
现在进行左右翻转:
1 image3 = image[:, ::-1, :] 2 plt.imshow(image3) 3 plt.show()
结果为:

这里需要知道的是,img函数的三个参数依次为行指标、列指标、RGB指标,当符号为“:”时,代表不变。
然后是进行裁剪,其原理就是抹去一部分矩阵的数据,如对于高度的裁剪,可以发现定义输出图片的高度(行数)和宽度(列数)。
下面的高度裁剪,是截取图片的1/3到原始最底端的一部分:
1 # 高度方向裁剪 2 H, W = image.shape[0], image.shape[1] 3 # 注意此处用整除,H_start必须为整数 4 H1 = H // 3 5 H2 = H 6 image4 = image[H1:H2, :, :] 7 plt.imshow(image4) 8 plt.show()
查看结果:
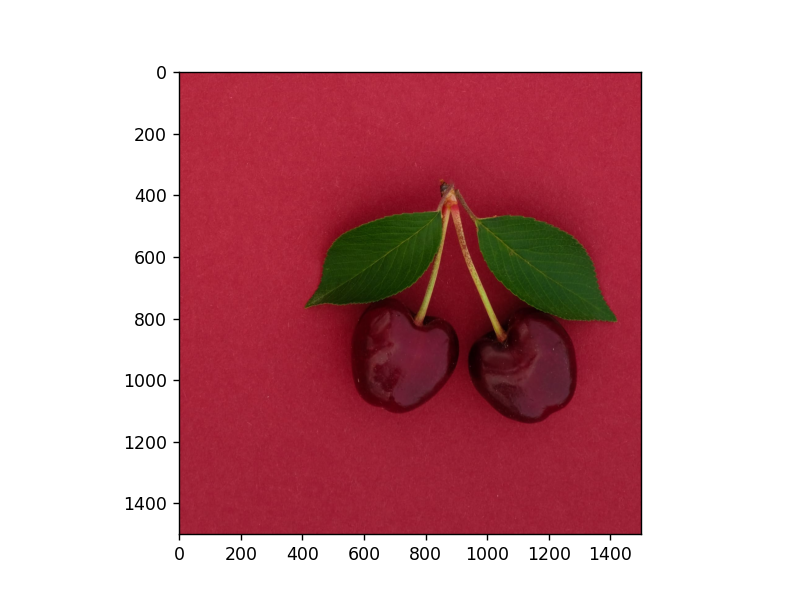
宽度的裁剪:
1 # 宽度方向裁剪 2 H, W = image.shape[0], image.shape[1] 3 W1 = W//6 4 W2 = W//3 * 2 5 image5 = image[:, W1:W2, :] 6 plt.imshow(image5) 7 plt.show()
查看结果:
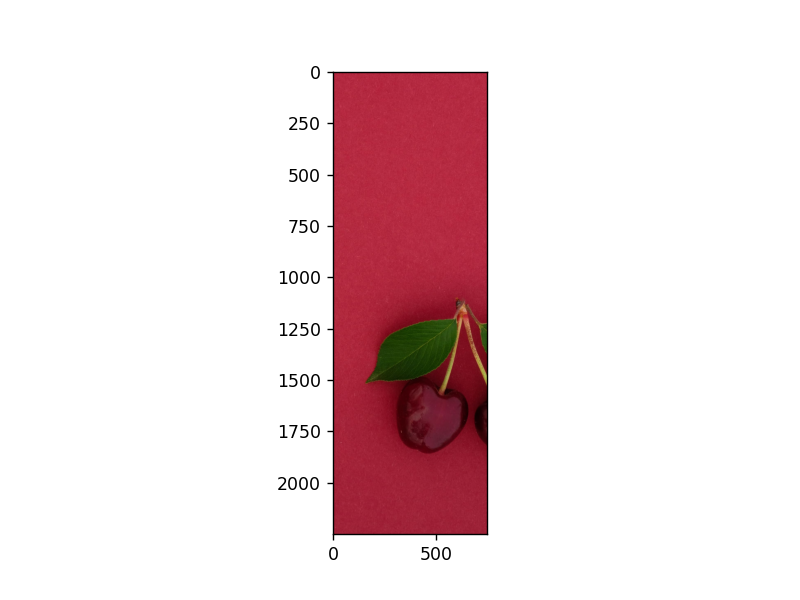
当然也可以同时进行裁剪,只需要再进行设定即可。
调节亮度:即对RGB值进行处理:
1 # 调整亮度 2 image7 = image * 2.0 3 # 由于图片的RGB像素值必须在0-255之间, 4 # 此处使用np.clip进行数值裁剪 5 image7 = np.clip(image7, \ 6 a_min=None, a_max=255.) 7 plt.imshow(image7.astype('uint8')) 8 plt.show()
以下是通过不同值进行处理的图片对比:
依次分别是:
1 image7 = image * 2.0 2 image7 = image * 5.0 3 image7 = image * 0.5
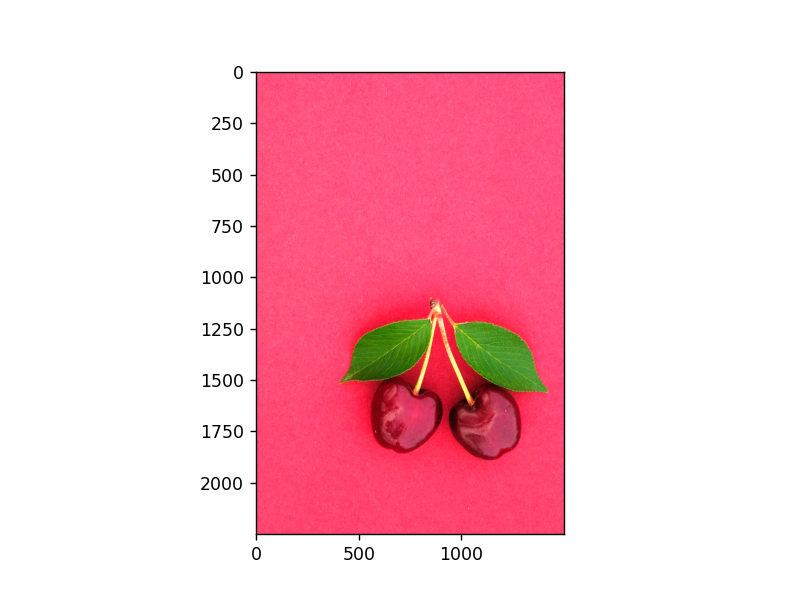
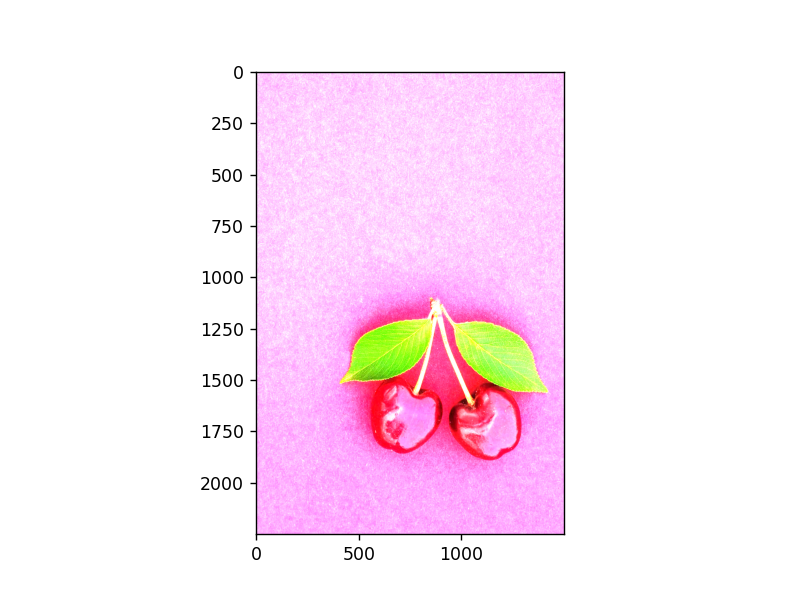
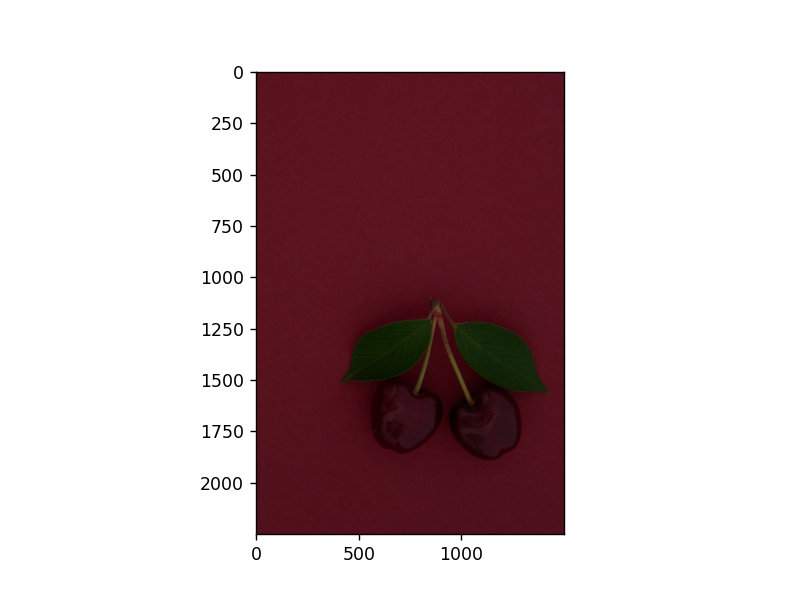
拉伸与压缩:即对像素点的选取方式的处理:
高度上每间隔1个取一次像素点:
1 #高度方向每隔一行取像素点 2 image8 = image[::2, :, :] 3 plt.imshow(image8) 4 plt.show()
查看可看到高度的值减少为原来的1/2。
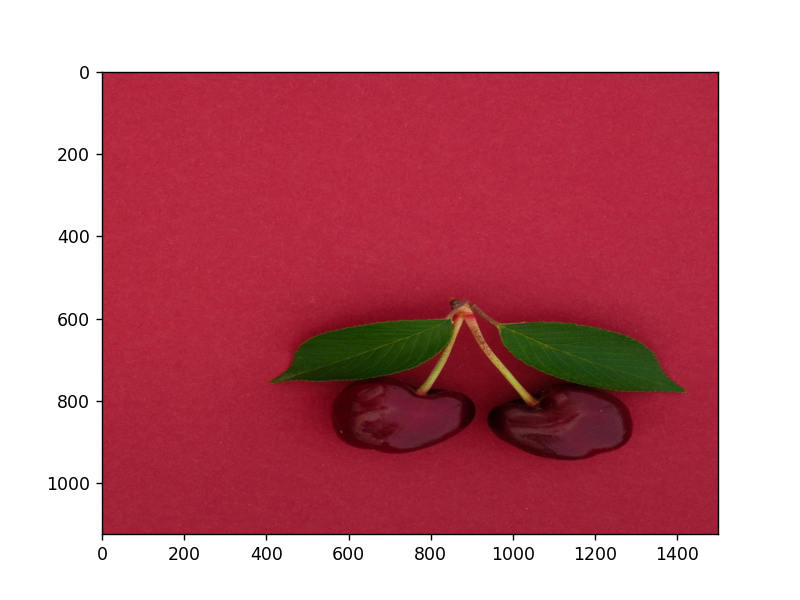
宽度也是同理,只需要改变列指标即可。
最后可以通过函数
1 # 保存图片 2 im3 = Image.fromarray(image) 3 im3.save('im3.jpg')
来将处理后的图片进行保存。
2、Paddle.Tensor
paddle.tensor,一个类型,在我理解而言,可以把他当作更多维度的array,维度更多,即shape[0],shape[1],shape[2]……同时还有更多的数据类型,能够更加灵活的处理一些数据。而且在反向梯度等数据处理上有着很突出的作用。它在计算中,除了可以与Numpy类似的做相乘的操作之外,还可以直接获取到每个变量的导数值。其中要知道的是下面函数:
paddle.to_tensor(data, dtype=None, place=None, stop_gradient=True)
其中:
-
data (scalar|tuple|list|ndarray|Tensor) - 初始化tensor的数据,可以是 scalar,list,tuple,numpy.ndarray,paddle.Tensor类型。
-
dtype (str, optional) - 创建tensor的数据类型,可以是 'bool' ,'float16','float32', 'float64' ,'int8','int16','int32','int64','uint8','complex64','complex128'。 默认值为None,如果
data为python浮点类型,则从get_default_dtype 获取类型,如果data为其他类型, 则会自动推导类型。 -
place (CPUPlace|CUDAPinnedPlace|CUDAPlace, optional) - 创建tensor的设备位置,可以是 CPUPlace, CUDAPinnedPlace, CUDAPlace。默认值为None,使用全局的place。
-
stop_gradient (bool, optional) - 是否阻断Autograd的梯度传导。默认值为True,此时不进行梯度传导。
Tensor还可以与Numppy的数组方便的互转,具体方法为:
1 import paddle 2 import numpy as np 3 4 tensor_to_convert = paddle.to_tensor([1.,2.]) 5 6 #通过 Tensor.numpy() 方法,将 Tensor 转化为 Numpy数组 7 tensor_to_convert.numpy() 8 9 #通过paddle.to_tensor() 方法,将 Numpy数组 转化为 Tensor 10 tensor_temp = paddle.to_tensor(np.array([1.0, 2.0]))
3、手写数字识别任务
对于我们自然人手写在纸上的数字,机器能够进行识别。即:
-
任务输入:一系列手写数字图片,其中每张图片都是相同的像素矩阵。
-
任务输出:经过了大小归一化和居中处理,输出对应的数字标签。
3.1 前提条件
在进行数据的处理前,要引用相关的库:
1 #加载飞桨和相关类库 2 import paddle 3 from paddle.nn import Linear 4 import paddle.nn.functional as F 5 import os 6 import numpy as np 7 import matplotlib.pyplot as plt
3.2 数据处理
首先寻找到相关的数据集,然后用封装好的数据集API(飞桨API支持如下常见的学术数据集:mnist、cifar、Conll05、imdb、imikolov、movielens、sentiment、uci_housing、wmt14、wmt16)设置数据读取器,如通过paddle.vision.datasets.MNIST API设置数据读取器。
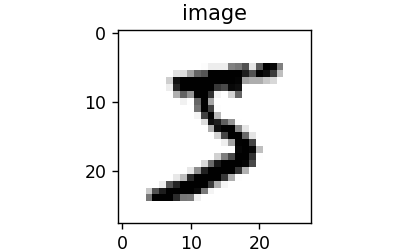
以读取其中一个数字为例子,注意的是mnist 数据集包含60000个训练集和10000测试数据集,分为图片和标签,图片是 28 * 28 的像素矩阵,标签为0~9共10个数字:
1 train_dataset = paddle.vision.datasets.MNIST(mode='train') 2 3 train_data0 = np.array(train_dataset[0][0]) 4 train_label_0 = np.array(train_dataset[0][1]) 5 6 # 显示第一batch的第一个图像 7 import matplotlib.pyplot as plt 8 plt.figure("Image") # 图像窗口名称 9 plt.figure(figsize=(2,2)) 10 plt.imshow(train_data0, cmap=plt.cm.binary) 11 plt.axis('on') # 关掉坐标轴为 off 12 plt.title('image') # 图像题目 13 plt.show() 14 15 print("图像数据形状和对应数据为:", train_data0.shape) 16 print("图像标签形状和对应数据为:", train_label_0.shape, train_label_0) 17 print("\n打印第一个batch的第一个图像,对应标签数字为{}".format(train_label_0))
这里应当注意的点在于,train_dataset = paddle.vision.datasets.MNIST(mode='train'),这句代码,当你目录C:\Users\用户名\.cache\paddle\dataset\mnist下没有对应的数据集时,它会主动下载,但是在python中进行下载,几乎时很费时费力的,所以我建议直接下载数据集在目录下较为方便。
得到的结果为:

3.3 模型设计
因为图像的像素是按照28✖28的,并且是严格按照这个标准来及进行的,对其处理与之前的房价预测一样,还是采用单层网络结构。如下图所示:
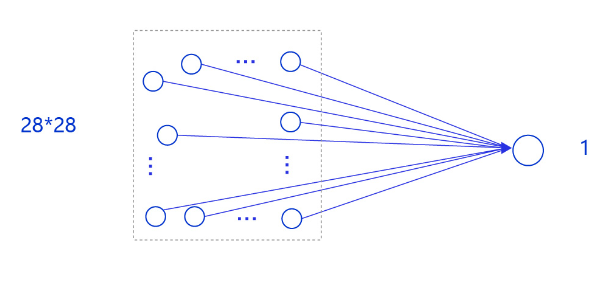
首先建立网络结构(单层网络结构),这与之前的房价预测有些许相似:
1 # 定义mnist数据识别网络结构,同房价预测网络 2 class MNIST(paddle.nn.Layer): 3 def __init__(self): 4 super(MNIST, self).__init__() 5 6 # 定义一层全连接层,输出维度是1 7 self.fc = paddle.nn.Linear(in_features=784, out_features=1) 8 9 # 定义网络结构的前向计算过程 10 def forward(self, inputs): 11 outputs = self.fc(inputs) 12 return outputs
3.4 训练配置
生成模型实例,指设为训练状态,然后设置优化算法和学习率,这里依旧是采用随机梯度下降SGD,学习率为0.001
1 # 声明网络结构 2 model = MNIST() 3 4 def train(model): 5 # 启动训练模式 6 model.train() 7 # 加载训练集 batch_size 设为 16 8 train_loader = paddle.io.DataLoader(paddle.vision.datasets.MNIST(mode='train'), 9 batch_size=16, 10 shuffle=True) 11 # 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001 12 opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
需要注意的是,DataLoader返回一个迭代器,该迭代器根据 batch_sampler 给定的顺序迭代一次给定的 dataset,其参数解释为:
-
dataset (Dataset) - DataLoader从此参数给定数据集中加载数据,此参数必须是
paddle.io.Dataset或paddle.io.IterableDataset的一个子类实例
-
batch_sampler (BatchSampler) -
paddle.io.BatchSampler或其子类的实例,DataLoader通过batch_sampler产生的mini-batch索引列表来dataset中索引样本并组成mini-batch。默认值为None。
-
batch_size (int|None) - 每mini-batch中样本个数,为
batch_sampler的替代参数,若batch_sampler未设置,会根据batch_sizeshuffledrop_last创建一个paddle.io.BatchSampler。默认值为1。
-
shuffle (bool) - 生成mini-batch索引列表时是否对索引打乱顺序,为
batch_sampler的替代参数,若batch_sampler未设置,会根据batch_sizeshuffledrop_last创建一个paddle.io.BatchSampler。默认值为False。
paddle.optimizer.SGD ( learning_rate=0.001, parameters=None, weight_decay=None, grad_clip=None,name=None )中的参数解释:
-
learning_rate (float|_LRScheduler, 可选) - 学习率,用于参数更新的计算。可以是一个浮点型值或者一个_LRScheduler类,默认值为0.001
-
parameters (list, 可选) - 指定优化器需要优化的参数。在动态图模式下必须提供该参数;在静态图模式下默认值为None,这时所有的参数都将被优化
-
weight_decay (float|Tensor, 可选) - 权重衰减系数,是一个float类型或者shape为[1] ,数据类型为float32的Tensor类型。默认值为0.01
-
grad_clip (GradientClipBase, 可选) – 梯度裁剪的策略,支持三种裁剪策略: cn_api_fluid_clip_GradientClipByGlobalNorm 、 cn_api_fluid_clip_GradientClipByNorm 、 cn_api_fluid_clip_GradientClipByValue 。 默认值为None,此时将不进行梯度裁剪。
-
name (str, 可选)- 该参数供开发人员打印调试信息时使用,默认值为None
3.5 训练过程
同样采用两层循环,①内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式;②外层循环:定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置。
1 import paddle 2 # 确保从paddle.vision.datasets.MNIST中加载的图像数据是np.ndarray类型 3 paddle.vision.set_image_backend('cv2') 4 5 # 声明网络结构 6 model = MNIST() 7 8 def train(model): 9 # 启动训练模式 10 model.train() 11 # 加载训练集 batch_size 设为 16 12 train_loader = paddle.io.DataLoader(paddle.vision.datasets.MNIST(mode='train'), 13 batch_size=16, 14 shuffle=True) 15 # 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001 16 opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters()) 17 EPOCH_NUM = 10 18 for epoch in range(EPOCH_NUM): 19 for batch_id, data in enumerate(train_loader()): 20 images = norm_img(data[0]).astype('float32') 21 labels = data[1].astype('float32') 22 23 #前向计算的过程 24 predicts = model(images) 25 26 # 计算损失 27 loss = F.square_error_cost(predicts, labels) 28 avg_loss = paddle.mean(loss) 29 30 #每训练了1000批次的数据,打印下当前Loss的情况 31 if batch_id % 1000 == 0: 32 print("epoch_id: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy())) 33 34 #后向传播,更新参数的过程 35 avg_loss.backward() 36 opt.step() 37 opt.clear_grad() 38 39 train(model) 40 paddle.save(model.state_dict(), './mnist.pdparams')
其中对进行学习训练的数据与label,进行比对,从而计算Loss。不断的更新参数。
要注意的是这里对图片的数据进行了归一化处理:
1 # 图像归一化函数,将数据范围为[0, 255]的图像归一化到[0, 1] 2 def norm_img(img): 3 # 验证传入数据格式是否正确,img的shape为[batch_size, 28, 28] 4 assert len(img.shape) == 3 5 batch_size, img_h, img_w = img.shape[0], img.shape[1], img.shape[2] 6 # 归一化图像数据 7 img = img / 255 8 # 将图像形式reshape为[batch_size, 784] 9 img = paddle.reshape(img, [batch_size, img_h*img_w]) 10 11 return img
最后得到的结果为:

可以发现直到最后,整个Loss依旧是比较高,可见简单的线性并无法使得该模型有良好的预测和识别功能,接下来对其进行测试。
3.6 模型测试
检测之前的模型是否能够准确数字识别,共有以下几个步骤:
-
声明实例
-
加载模型:加载训练过程中保存的模型参数,
-
灌入数据:将测试样本传入模型,模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播。
-
获取预测结果,取整后作为预测标签输出。
读取样例图片,进行归一化操作:
1 # 导入图像读取第三方库 2 import matplotlib.pyplot as plt 3 import numpy as np 4 from PIL import Image 5 6 img_path = 'example_0.jpg' 7 # 读取原始图像并显示 8 im = Image.open('example_0.jpg') 9 plt.imshow(im) 10 plt.show() 11 # 将原始图像转为灰度图 12 im = im.convert('L') 13 print('原始图像shape: ', np.array(im).shape) 14 # 使用Image.ANTIALIAS方式采样原始图片 15 im = im.resize((28, 28), Image.Resampling.LANCZOS) 16 plt.imshow(im) 17 plt.show() 18 print("采样后图片shape: ", np.array(im).shape)
采样前:
采样后:
![]()
对于一张本地的图片进行预测:
1 img_path = 'example_0.jpg' 2 # 读取一张本地的样例图片,转变成模型输入的格式 3 def load_image(img_path): 4 # 从img_path中读取图像,并转为灰度图 5 im = Image.open(img_path).convert('L') 6 # print(np.array(im)) 7 im = im.resize((28, 28), Image.Resampling.LANCZOS) 8 im = np.array(im).reshape(1, -1).astype(np.float32) 9 # 图像归一化,保持和数据集的数据范围一致 10 im = 1 - im / 255 11 return im 12 13 # 定义预测过程 14 model = MNIST() 15 params_file_path = 'mnist.pdparams' 16 img_path = 'example_0.jpg' 17 # 加载模型参数 18 param_dict = paddle.load(params_file_path) 19 model.load_dict(param_dict) 20 # 灌入数据 21 model.eval() 22 tensor_img = load_image(img_path) 23 result = model(paddle.to_tensor(tensor_img)) 24 print('result',result) 25 # 预测输出取整,即为预测的数字,打印结果 26 print("本次预测的数字是", result.numpy().astype('int32'))
得到的结果为:

可以发现手写的数字为0,而体现的数字为1,说明简单的线性加权和并不能很好的进行识别。
4、模型优化
……
5、总结
对以上部分的学习,可以对很多python的函数等知识有一个更多的认识,也对整个模型建立的过程有了一个知识的巩固。但对于其中的详细步骤,还有好几个地方是无法理解的,就像data[0]和data[1]为什么标识图片数据和lable值等,此外模型到目前为止很明显是有很大问题的,需要进一步的改善。
6、参考资料
Paddle.Tensor:https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/to_tensor_cn.html
image错误处理:https://blog.csdn.net/hjxu2016/article/details/70215103
激活函数:https://www.cnblogs.com/missidiot/p/9378079.html
数据集下载:https://aistudio.baidu.com/aistudio/datasetdetail/10595
DataLoader详解:https://lib.yanxishe.com/document/PaddlePaddle/api/paddle.io.DataLoader
paddle.optimizer.SGD函数:https://www.bookstack.cn/read/paddlepaddle-2.0-zh/3aea7f291f9042c8.md
详细教程:https://aistudio.baidu.com/aistudio/projectdetail/4341261

 浙公网安备 33010602011771号
浙公网安备 33010602011771号