MySQL 第十天(视图、存储过程、函数、触发器)
MySql高级—视图、函数、存储过程、触发器
目录
一、视图
1、视图的定义
视图的定义:
视图是由查询结果形成的一张虚拟表,是表通过某种运算得到的一个投影。
同一张表可以创建多个视图
创建视图的语法:
create view view_name as select 语句
说明:
(1)视图名跟表名是一个级别的名字,隶属于数据库;
(2)该语句的含义可以理解为:就是将该select命名为该名字(视图名);
(3)视图也可以设定自己的字段名,而不是select语句本身的字段名——通常不设置。
(4)视图的使用,几乎跟表一样!

2、视图的作用
(1)可以简化查询。
案例1:查询平均价格前3高的栏目。
传统的sql语句写法
select cat_id,avg(shop_price) as pj from ecs_goods group by cat_id order by pj desc limit 3;
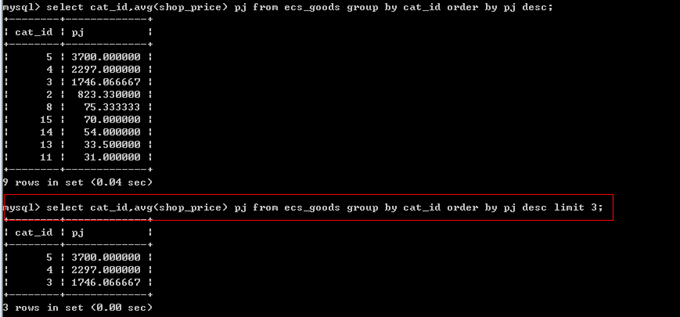
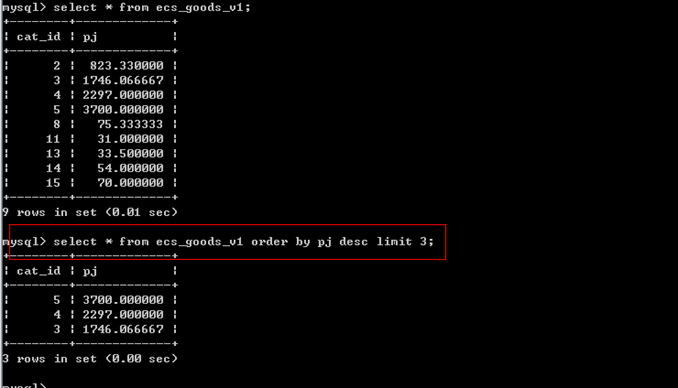
创建一个视图,简化查询。
语法:
create view ecs_goods_v1 as select cat_id,avg(shop_price) pj from ecs_goods group by cat_id;
查询平均价格前3高的栏目,我们只需查询视图即可。
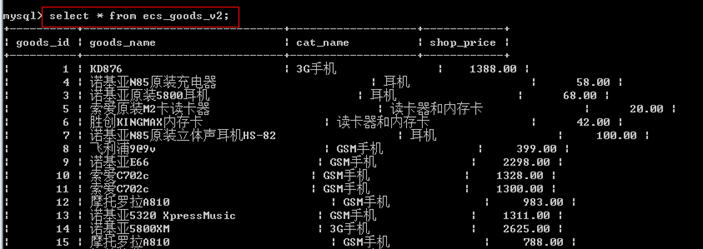
案例2:查询出商品表,以及所在的栏目名称;
传统写法:
select goods_id,goods_name,b.cat_name,shop_price from ecs_goods a left join ecs_category b on a.cat_id=b.cat_id;
创建一个视图
create view ecs_goods_v2 as select goods_id,goods_name,b.cat_name,shop_price from ecs_goods a left join ecs_category b on a.cat_id=b.cat_id;
查询视图;
select * from ecs_goods_v2;
(2)可以进行权限控制
把表的权限封闭,但是开放相应的视图权限,视图里只开放部分数据,比如某张表,用户表为例,2个网站搞合作,可以查询对方网站的用户,需要向对方开放用户表的权限,但是呢,又不想开放用户表中的密码字段。
再比如一个goods表,两个网站搞合作,可以相互查询对方的商品表,比如进货价格字段不能让对方查看。
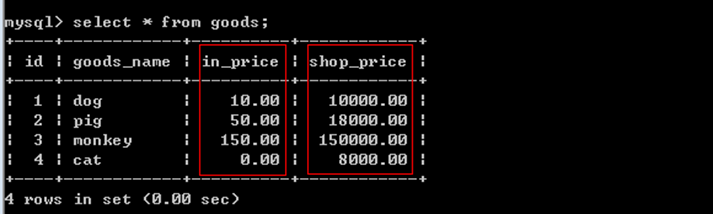
第一步:创建一个视图,视图中不能包含in_price字段。
语法: create view goods_v1 as select id,goods_name,shop_price from goods;
第二步:创建一个用户,授予查询权限,只能操作goods_v1表(视图)
语法:grant select on php.goods_v1 to 'xiaotian'@'%' identified by '1234456';

第三步:我们就测试一下,

3、查询视图
语法:select * from 视图名 [where 条件]
视图和表一样,可以添加where 条件
4、修改视图
alter view view_name as select XXXX
5、删除视图
drop view 视图名称

6、查看视图结构
和表一样的,语法,desc 视图名称
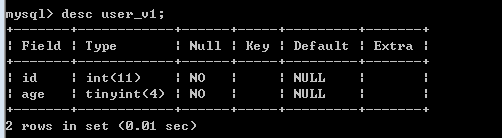
7、查看所有视图
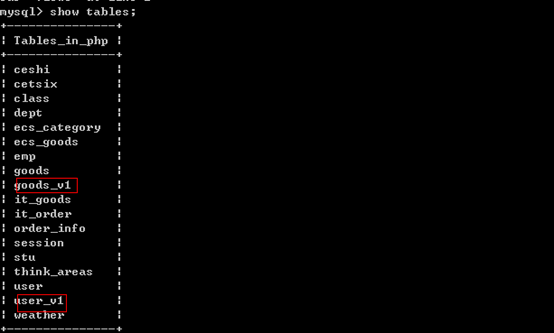
和表一样,语法:show tables;
注意:没有show views语句;
8、视图与表的关系
视图是表的查询结果,自然表的数据改变了,影响视图的结果。
(1)视图的数据与表的数据一一对应时,可以修改。
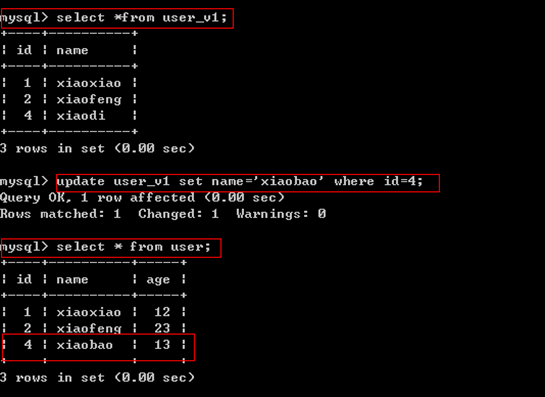
对视图的修改,也会影响到数据库表的修改。
(2)视图增删改也会影响表,但是视图并不是总是能增删改的。
create view lmj as select cat_id,max(shop_price) as lmj from goods group by cat_id;
mysql> update lmj set lmj=1000 where cat_id=4;
ERROR 1288 (HY000): The target table lmj of the UPDATE is not updatable
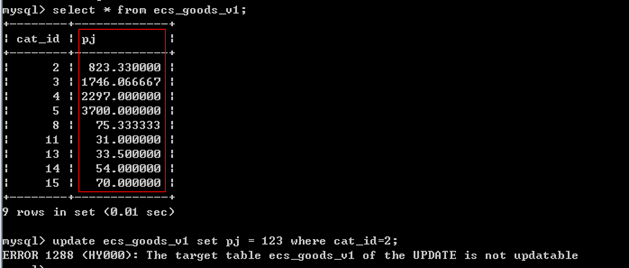
注意:视图的数据与表的数据一一对应时,可以修改,
(3)对于视图insert还应注意,视图必须包含表中没有默认值的列。
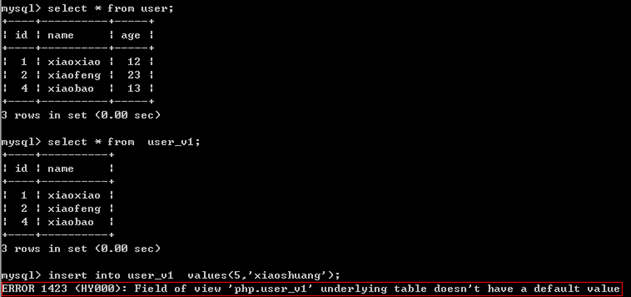
以上对user_v1的操作,就类似于,如下sql语句的操作,原因就是age字段没有默认值,我们里面,没有包含age字段,
create table user(
id int not null,
name varchar(32) not null,
age tinyint not null
)engine myisam charset utf8;
insert into user values(12,'xiaofan');
注意:一般来说,视图只是用来查询的,不应该执行增删改的操作。
9、视图算法
algorithm= merge/temptable/undefined
merge:当引用视图时,引用视图的语句与定义视图的语句合并(默认)。
temptable:当引用视图时,根据视图的创建语句建立一个临时表。
undefined:未定义,自动让系统帮你选。
merge:意味着,视图只是一个语句规则,当查询视图时,把查询视图的语句(比如where那些)与创建时的语句where子句等合并,
分析,形成一条 select语句。
temptable:是根据创建语句瞬间创建一张临时表,然后查询视图的语句,从该临时表查数据。
比如如下视图的算法为merge
#在创建视图时的语句:where shop_price>1000;
#查询视图时,where shop_price<3000;
#那么查此视图时,真正发生的是where (select where) and (view where)
#where shop_price <3000 and shop_price >1000;
#分析出最终语句还是去查goods表
二、SQL 编程
1、变量声明
(1)会话变量
定义形式:
set @变量名 = 值;
说明:
1,跟php类似,第一次给其赋值,就算定义了
2,它可以在编程环境和非编程环境中使用!
3,使用的任何场合也都带该"@"符号。
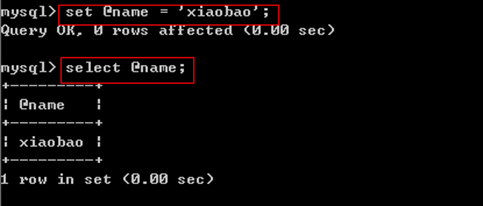
(2)普通变量
定义形式:
declare 变量名 类型 【default 默认值】;
说明:
1、它必须先声明(即定义),此时也可以赋值;
2、赋值跟会话变量一样: set 变量名 = 值;
3、它只能在编程环境中使用!!!
说明:什么是编程环境?
存储过程,函数,触发器就是编程环境
(3)变量赋值形式
语法1:
set 变量名 = 表达式;#此语法中的变量必须先使用declare声明
语法2:
set @变量名=表达式;
#此方式可以无需declare语法声明,而是直接赋值,类似php定义变量并赋值。

语法3:
select @变量名:=表达式;
#此语句会给该变量赋值,同时还会作为一个select语句输出'结果集'。

语法4:
select 表达式 into @变量名;#此语句虽然看起来是select语句,但其实并不输出'结果集',而是给变量赋值。
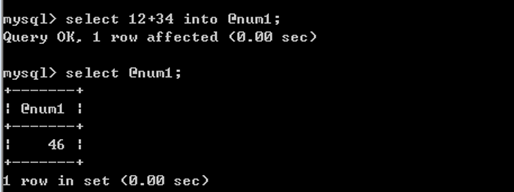
2、运算符
(1)算术运算符
+、-、*、/、%
注意:mysql没有++和—运算符
(2)关系运算符
>、>=、<、<=、=(等于)、<>(不等于)!=(不等于)
(3)逻辑运算符
and(与)、or(或)、not(非)
3、语句块包含符
所谓语句块包含符,在js或php中,以及绝大部分的其他语言中,都是大括号:{}
它用在很多场合:if, switch, for, function
而mysql编程中的语句块包含符是。

4、if判断
MySQL支持两种判断,第一个是if判断,第二个 case判断
if语法
单分支
if 条件 then
//代码
end if;
双分支
if 条件 then
代码1
else
代码2
end if;
多分支
if 条件 then
代码1
elseif 条件 then
代码2
else
代码3
end if;
案例:接收4个数字,
如果输入1则输出春天,2=》夏天 3=》秋天 4 =》冬天 其他数字=》出错
我们使用存储过程来体验if语句的用法,
create procedure 存储过程名(参数,参数,…)
begin
//代码
end
注意:通常情况下,";"表示SQL语句结束,同时向服务器提交并执行。但是存储过程中有很多SQL语句,每一句都要以分号隔开,这时候我们就需要使用其他符号来代替向服务器提交的命令。通过delimiter命令更改语句结束符。

具体的语句;
create procedure p1 (n int)
begin
if n=1 then
select '春天' as '季节';
elseif n=2 then
select '夏天' as '季节';
elseif n=3 then
select '秋天' as '季节';
elseif n=4 then
select '冬天' as '季节';
else
select '无法无天' as '季节';
end if;
end$
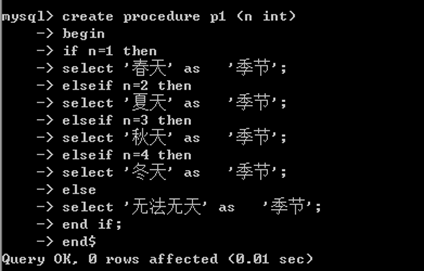
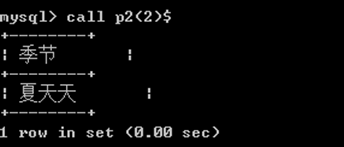
调用:语法:call 存储过程的名称(参数)

5、case判断
case 变量
when值 then 语句;
when值 then 语句;
else 语句;
end case ;
案例:接收4个数字,
如果输入1则输出春天,2=》夏天 3=》秋天 4 =》冬天 其他数字=》出错
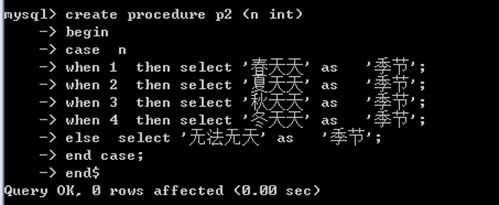
create procedure p2 (n int)
begin
case n
when 1 then select '春天天' as '季节';
when 2 then select '夏天天' as '季节';
when 3 then select '秋天天' as '季节';
when 4 then select '冬天天' as '季节';
else select '无法无天' as '季节';
end case;
end$
6、循环
MySQL支持的循环有loop、while、repeat循环
(1)loop循环
标签名:loop
leave 标签名 --退出循环
end loop;

(2)while 循环
[标签:]while 条件 do
//代码
end while;

(3) repeat 循环
repeat
//代码
until 条件 end repeat;

三、存储过程
1、概念
存储过程(procedure)
概念类似于函数,就是把一段代码封装起来,当要执行这一段代码的时候,可以通过调用该存储过程来实现。在封装的语句体里面,
可以同if/else ,case,while等控制结构。
可以进行sql编程。
查看现有的存储过程。
show procedure status
2、存储过程的优点
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。
(1)存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
(2)当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
(3)存储过程可以重复使用,可减少数据库开发人员的工作量
(4)安全性高,可设定只有某些用户才具有对指定存储过程的使用权
3、创建存储过程
create procedure 存储过程名(参数,参数,…)
begin
//代码
end
存储过程的参数分为输入参数(in)、输出参数(out)、输入输出参数(inout),默认是输入参数。
如果存储过程中就一条语句,begin和end是可以省略的。
说明:
(1)存储过程中,可有各种编程元素:变量,流程控制,函数调用;
(2)还可以有:增删改查等各种mysql语句;
(3)其中select(或show,或desc)会作为存储过程执行后的"结果集"返回;
(4)形参可以设定数据的"进出方向":
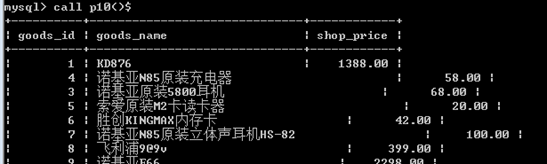
案例1:查询一个表里面某些语句

调用结果:
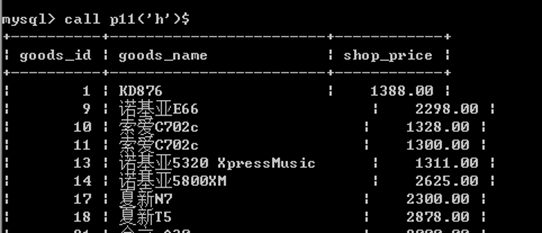
案例2:第二个存储过程体会参数
输入一个字符串,如果等于h则取出价格大于1000的商品,输入其他的值,则输出小于1000的商品。
create procedure p11(str char(1))
begin
if str='h' then
select goods_id,goods_name,shop_price from ecs_goods where shop_price>1000;
else
select goods_id,goods_name,shop_price from ecs_goods where shop_price<=1000;
end if;
end$
4、调用存储过程
语法:call 存储过程()
mysql_query("call存储过程名称()")
5、删除存储过程
语法:drop procedure [if exists] 存储过程名
6、创建复杂的存储过程
案例1:体会循环,计算1到n的和:

案例2:带输出参数的存储过程


案例3:带有输入输出参数的存储过程

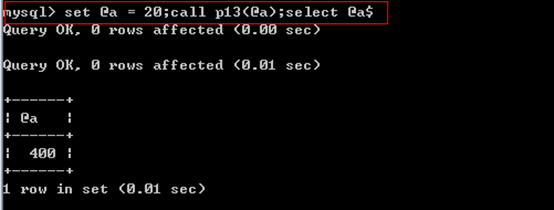
7、declare声明局部变量
在编程环境中使用。
用户变量只要在前面加一个@符即可
set @name='李白';
select @name;
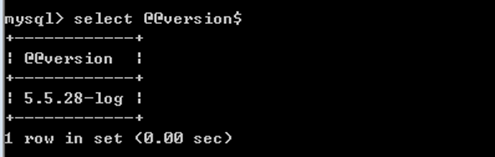
8、系统变量
MySQL启动的时候就存在的变量,以@@开头的都是系统变量
select @@version$
四、函数
1、自定义函数
它跟php或js中的函数几乎一样:需要先定义,然后调用(使用)。
只是规定,这个函数,必须要返回数据——要有返回值
(1)定义语法:
create function 函数名(参数,参数的类型) returns 返回值类型
begin
//代码
end

说明:
(1)函数内部可以有各种编程语言的元素:变量,流程控制,函数调用;
(2)函数内部可以有增删改等语句!
(3)但:函数内部不可以有select(或show或desc)这种返回结果集的语句!
(2)调用
跟系统函数调用一样:任何需要数据的位置,都可以调用该函数。
案例1:返回两个数的和
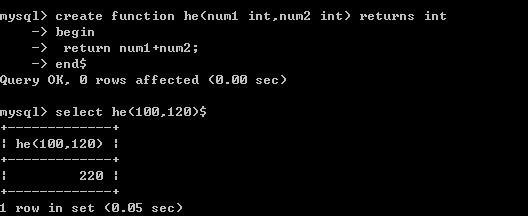
案例2:定义一个函数,返回1到n的和。

注意:创建的函数,是隶属于数据库的,只能在创建函数的数据库中使用。
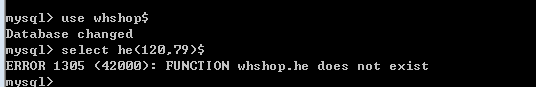
2、系统函数
(1)数字类
mysql> select rand();//返回0到1间的随机数
mysql>select * from it_goods order by rand() limit 2;//随机取出2件商品
mysql>select floor(3.9)//输出3
mysql>select ceil(3.1)//输出4
mysql>select round(3.5)//输出4四舍五入
(2)大小写转换
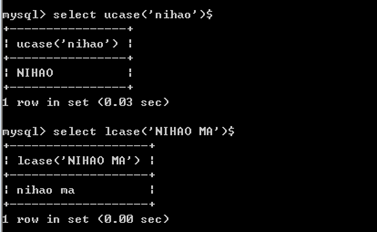
mysql> select ucase('I am a boy!') // --转成大写
mysql> select lcase('I am a boy!') // --转成小写
(3)截取字符串
mysql> select left('abcde',3)// --从左边截取
mysql> select right('abcde',3) // --从右边截取
mysql> select substring('abcde',2,3)// --从第二个位置开始,截取3个,注意:位置从1开始
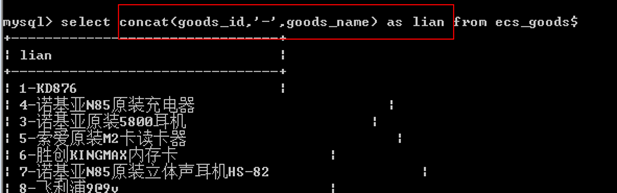
mysql> select concat(10,':锄禾日当午')// --字符串相连
mysql> select coalesce(null,123);
coalesce(str1,str2):如果第str1为null,就显示str2
mysql> select stuname,stusex,coalesce(writtenexam,'缺考'), coalesce(labexam,'缺考') from stuinfo natural left join stumarks//
mysql> select length('锄禾日当午') // 输出10 显示字节的个数
mysql> select char_length('锄禾日当午') // 输出5 显示字符的个数
mysql> select length(trim(' abc ')) // trim用来去字符串两边空格
mysql> select replace('abc','bc','pache')// 将bc替换成pache
(4)时间类
mysql> select unix_timestamp()// --时间戳

mysql> select from_unixtime(unix_timestamp()) // --将时间戳转成日期格式

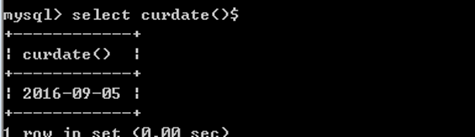
curdate();返回今天的时间日期:
mysql> select now()// --取出当前时间

mysql>select year(now()) 年,month(now()) 月 ,day(now()) 日, hour(now()) 小时,minute(now()) 分钟,second(now()) 秒//
mysql>select datediff(now(),'1997-7-1') // 两个日期相距多少天
if(表达式,值1,值2):类似于三元运算符
mysql> select concat(10,if(10%2=0,'偶数','奇数'))//
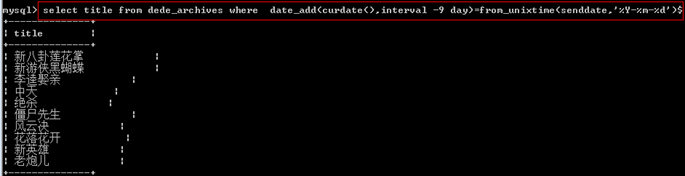
案例1:比如一个电影网站,求出今天添加的电影;在添加电影时,有一个添加的时间戳。
//curdate()求出今天的日期
//把添加的时间戳,转换成日期
select title from dede_archives where curdate()=from_unixtime(senddate,'%Y-%m-%d')$

案例2:比如一个电影网站,求出昨天添加的电影;在添加电影时,有一个添加的时间戳。
思路:
把添加的时间戳,转换成日期,和昨天的日期比较,
问题?如何求出昨天的日期,
扩展,如何取出昨天或者指定某个时间的电影:
date_sub和date_add函数:
基本用法:
date_sub(时间日期时间,interval 数字 时间单位)
说明:
(1)时间单位:可以是year month day hour minute second
(2)数字:可以是正数和负数。
比如:取出昨天的日期:
select date_sub(curdate(),interval 1 day)
或
select date_add(curdate(),interval -1 day)
比如:取出前天的日期:
select date_sub(curdate(),interval 2 day)
或
select date_add(curdate(),interval -2 day)
比如:取出后天的日期:
select date_sub(curdate(),interval -1 day)
或
select date_add(curdate(),interval 1 day)
回归案例:
比如一个电影网站,求出昨天添加的电影;在添加电影时,有一个添加的时间戳。
五、触发器
1、简介
(1)触发器是一个特殊的存储过程,它是MySQL在insert、update、delete的时候自动执行的代码块。
(2)触发器必须定义在特定的表上。
(3)自动执行,不能直接调用,
作用:监视某种情况并触发某种操作。
触发器的思路:
监视it_order表,如果it_order表里面有增删改的操作,则自动触发it_goods里面里面增删该的操作。
比如新添加一个订单,则it_goods表,就自东减少对应商品的库存。
比如取消一个订单,则it_goods表,就自动增加对应商品的库存减少的库存。
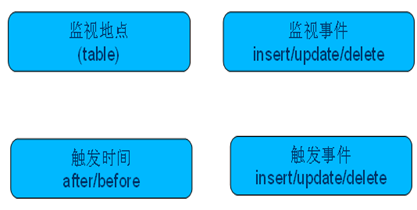
2、触发器四要素
3、创建触发器
创建触发器的语法:
create trigger trigger_name
after/before insert /update/delete on 表名
for each row
begin
sql语句:(触发的语句一句或多句)
end
案例1:第一个触发器,购买一个馒头,减少1个库存。
分析:
监视的地点: it_order表
监视的事件: it_order表的inset操作。
触发的时间: it_order表的inset之后
触发的事件 it_goods表减少库存的操作。
create trigger t1
after insert on it_order
for each row
begin
update it_goods set goods_number=goods_number-1 where id=2;
end$
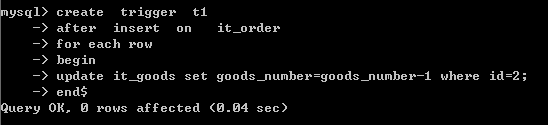
测试效果如下:
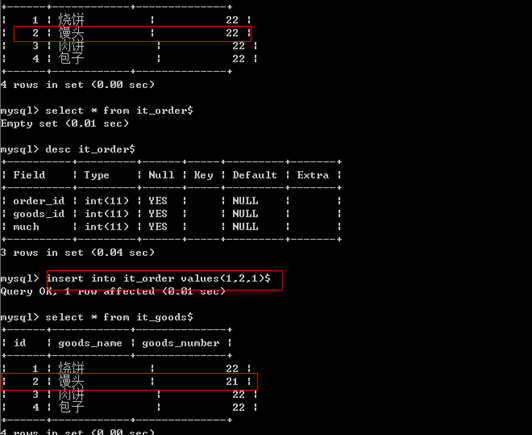
上面我们创建的触发器t1是有问题,我们购买任何商品都是减少馒头的库存。
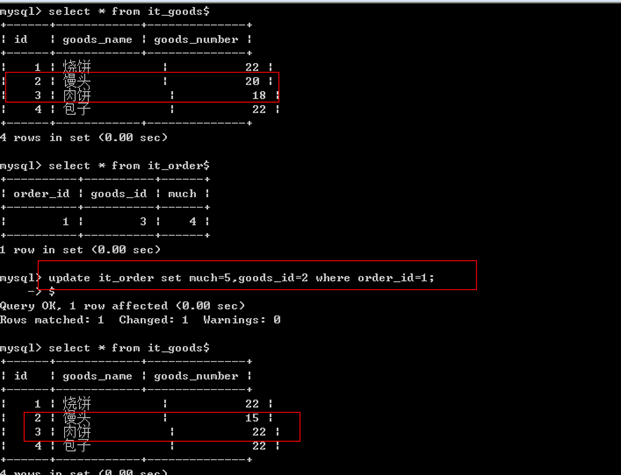
案例2:购买商品,减少对应库存 ,
create trigger t2
after insert on it_order
for each row
begin
update it_goods set goods_number=goods_number-new.much where id=new.goods_id;
end$
注意:如果在触发器中引用行的值。
对于insert 而言,新增的行用new来表示,行中的每一列的值,用 new.列名 来表示。
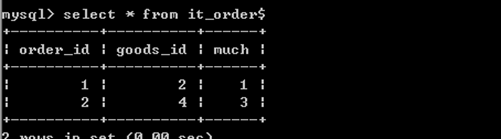
测试效果如下:

案例3:取消订单时,减掉的库存要添加回来。
分析:
监视的地点: it_order表
监视的事件: it_order表的delete操作
触发的时间: it_order表的delete操作之后
触发的事件: it_goods表,把减掉的库存恢复过来。
create trigger t3
after delete on it_order
for each row
begin
update it_goods set goods_number=goods_number+old.much where id=old.goods_id;
end$
注意:对应it_order表,删除的行我们使用old来表示,如果要引用里面的数据,则使用
old.列名 来表示。
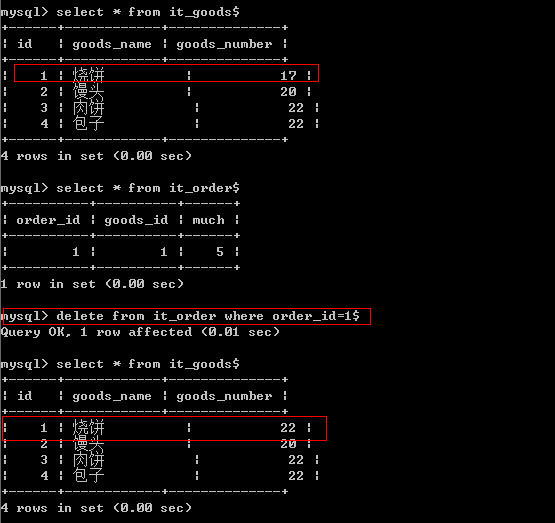
案例4:修改订单时,库存也要做对应修改.(可以修改购买数量,也可以修改类型)
监视的地点: it_order表
监视的事件: it_order表的update操作
触发的时间: it_order表的update操作之后
触发的事件: it_goods表,要修改对应的库存。
create trigger t4
after update on it_order
for each row
begin
update it_goods set goods_number=goods_number+old.much where id=old.goods_id;
update it_goods set goods_number=goods_number-new.much where id=new.goods_id;
end$
完成修改的思路:
(1)撤销订单,it_goods表里面的库存要恢复。
(2)重新下订单,it_goods表里面的库存要减少
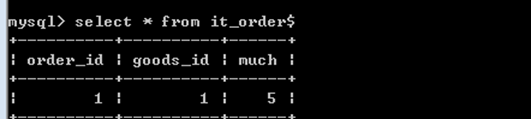
注意:如果是修改操作,要引用it_order表里面的值,
修改前的数据,用old来表示,old.列名 引用被修改之前行中的值。
修改后的数据,用new来表示,new.列名 引用被修改之后行中的值。
4、删除触发器
语法:drop trigger 触发器的名称
5、查看触发器
语法: show triggers
6、before与after的区别
after是先完成数据的增删改,再触发,触发器中的语句晚于监视的增删改,无法影响前面的增删该动作。
就类似于先吃饭,再付钱。
before是先完成触发,再增删改,触发的语句先于监视的增删改发生,我们有机会判断修改即将发生的操作。
就类似于先付钱,再吃饭
典型案例:对于已下的订单,进行判断,如果订单的数量>5,就认为是恶意订单,强制把所定的商品数量改成5
分析:
监视的地点:it_order表
监视的事件:it_order表的insert操作
触发的时间:it_order表的insert操作之前。
触发的事件:如果购买数量大于5,把购买数量改成5。
create trigger t5
before insert on it_order
for each row
begin
if new.much>5 then
set new.much=5;
end if;
end$

目前mysql不支持多个具有同一个动作,同一时间,同一事件,同一地点,的触发器
create trigger t10
after delete on it_order
for each row
begin
update it_goods set goods_number=goods_number+old.much where id=old.goods_id;
end$


 浙公网安备 33010602011771号
浙公网安备 33010602011771号