并发编程—进程
目录
进程总结
进程简介
- 进程是计算机中最小的资源分配单位
- 特点:数据隔离、数据不安全、基于操作系统级别、可以利用多核、开启关闭花销时间大
进程三状态图
- 就绪、运行、阻塞
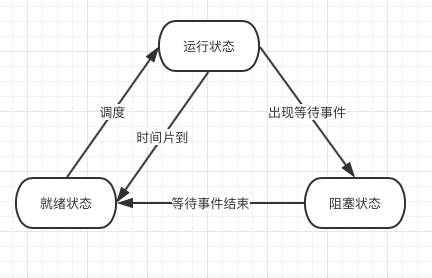
进程的调度算法
-
先来先服务调度算法
- 先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。FCFS算法比较有利于长作业(进程),而不利于短作业(进程)。由此可知,本算法适合于CPU繁忙型作业,而不利于I/O繁忙型的作业(进程)。
-
短作业优先调度算法
- 短作业(进程)优先调度算法(SJ/PF)是指对短作业或短进程优先调度的算法,该算法既可用于作业调度,也可用于进程调度。但其对长作业不利;不能保证紧迫性作业(进程)被及时处理;作业的长短只是被估算出来的。
-
时间片轮转法
- 时间片轮转(Round Robin,RR)法的基本思路是让每个进程在就绪队列中的等待时间与享受服务的时间成比例。在时间片轮转法中,需要将CPU的处理时间分成固定大小的时间片,例如,几十毫秒至几百毫秒。如果一个进程在被调度选中之后用完了系统规定的时间片,但又未完成要求的任务,则它自行释放自己所占有的CPU而排到就绪队列的末尾,等待下一次调度。同时,进程调度程序又去调度当前就绪队列中的第一个进程。显然,轮转法只能用来调度分配一些可以抢占的资源。这些可以抢占的资源可以随时被剥夺,而且可以将它们再分配给别的进程。CPU是可抢占资源的一种。但打印机等资源是不可抢占的。由于作业调度是对除了CPU之外的所有系统硬件资源的分配,其中包含有不可抢占资源,所以作业调度不使用轮转法。 在轮转法中,时间片长度的选取非常重要。首先,时间片长度的选择会直接影响到系统的开销和响应时间。如果时间片长度过短,则调度程序抢占处理机的次数增多。这将使进程上下文切换次数也大大增加,从而加重系统开销。反过来,如果时间片长度选择过长,例如,一个时间片能保证就绪队列中所需执行时间最长的进程能执行完毕,则轮转法变成了先来先服务法。时间片长度的选择是根据系统对响应时间的要求和就绪队列中所允许最大的进程数来确定的。
- 在轮转法中,加入到就绪队列的进程有3种情况(进程的三状态):
- 一种是分给它的时间片用完,但进程还未完成,回到就绪队列的末尾等待下次调度去继续执行。
- 第二种情况是分给该进程的时间片并未用完,只是因为请求I/O或由于进程的互斥与同步关系而被阻塞。当阻塞解除之后再回到就绪队列。
- 第三种情况就是新创建进程进入就绪队列。如果对这些进程区别对待,给予不同的优先级和时间片从直观上看,可以进一步改善系统服务质量和效率。例如,我们可把就绪队列按照进程到达就绪队列的类型和进程被阻塞时的阻塞原因分成不同的就绪队列,每个队列按FCFS原则排列,各队列之间的进程享有不同的优先级,但同一队列内优先级相同。这样,当一个进程在执行完它的时间片之后,或从睡眠中被唤醒以及被创建之后,将进入不同的就绪队列。
-
多级反馈算法
-
多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。在采用多级反馈队列调度算法的系统中,调度算法的实施过程如下所述。
- (1) 应设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,其余各队列的优先权逐个降低。该算法赋予各个队列中进程执行时间片的大小也各不相同,在优先权愈高的队列中,为每个进程所规定的执行时间片就愈小。例如,第二个队列的时间片要比第一个队列的时间片长一倍,……,第i+1个队列的时间片要比第i个队列的时间片长一倍。
- (2) 当一个新进程进入内存后,首先将它放入第一队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队列的末尾,再同样地按FCFS原则等待调度执行;如果它在第二队列中运行一个时间片后仍未完成,再依次将它放入第三队列,……,如此下去,当一个长作业(进程)从第一队列依次降到第n队列后,在第n 队列便采取按时间片轮转的方式运行。
- (3) 仅当第一队列空闲时,调度程序才调度第二队列中的进程运行;仅当第1~(i-1)队列均空时,才会调度第i队列中的进程运行。如果处理机正在第i队列中为某进程服务时,又有新进程进入优先权较高的队列(第1~(i-1)中的任何一个队列),则此时新进程将抢占正在运行进程的处理机,即由调度程序把正在运行的进程放回到第i队列的末尾,把处理机分配给新到的高优先权进程。
-
进程的开启和关闭
开启
- 通过Process模块开启,unix操作系统与iso操作系统开进程的方式有区别,unix是通过import的方式,而ios是通过copy的手段复制
关闭
- 正常退出(自愿,如用户点击交互式页面的叉号,或程序执行完毕调用发起系统调用正常退出,在linux中用exit,在windows中用ExitProcess)
- 出错退出(自愿,python a.py中a.py不存在)
- 严重错误(非自愿,执行非法指令,如引用不存在的内存,1/0等,可以捕捉异常,try...except...)
- 被其他进程杀死(非自愿,如kill -9)
multiprocessing模块中的Process模块
from multiprocessing import Process
import os
def func(name,age):
print(os.getpid(),os.getppid())
print(f'{age}的{name}准备睡觉勒!')
print("准备完毕")
if __name__ == '__main__': #在windows下一定要使用if....格式
print(os.getpid(),os.getppid())
args_ls=[('yzh',18),('团团', 81),('圆圆',15)]
p_ls=[]
for arg in args_ls:
p=Process(target=func,args=arg)
p.start()
# p.join()
p_ls.append(p)
for p in p_ls:
p.join()
#能开启多个子进程,可以给子进程传递参数,但不能获取返回值
#python规定只能在父进程中使用input,在子进程中不能使用input
Process的方法介绍
import os
import time
from multiprocessing import Process
class MyProcess(Process): #面向对象的Process模块
def __init__(self,a,b,c):
self.a = a
self.b = b
self.c = c
super().__init__()
def run(self):
print(os.getppid(),os.getpid(),self.a,self.b,self.c)
if __name__ == '__main__':
p = MyProcess(1,2,3)
p.start()
time.sleep(0.5)
print(p.pid,p.ident) #获取进程的id
print(p.name) #获取进程的名字
print(p.is_alive())
p.terminate() #强制结束一个子进程 同步 异步非阻塞
print(p.is_alive()) #查看进程是否结束,注意:如果直接在terminate()后加alive方法会产生错误答案,因为terminate有延迟
time.sleep(0.01)
print(p.is_alive())
守护进程
- 可以通过.deamon=True的方法对子进程设置守护,使其成为守护进程
- 特点:守护进程等待主进程的代码结束就结束,如果此时还有其他的子进程在运行,守护进程不受影响
import time
from multiprocessing import Process
def son1():
while True:
print('--> in son1')
time.sleep(1)
def son2(): # 执行10s
for i in range(10):
print('--> in son2')
time.sleep(1)
if __name__ == '__main__':
p1 = Process(target=son1)
p1.daemon = True # 表示设置p1是一个守护进程
p1.start()
p2 = Process(target=son2,)
p2.start()
time.sleep(3)
print('in main')
# p2.join() # 等待p2结束之后才结束
# 等待p2结束 --> 主进程的代码才结束 --> 守护进程结束
进程锁
- 进程锁是为了解决进程之间数据不安全的现象,比如,对共同的文件进行操作时
- with lock===lock.acquire( ) lock.release( )
- 互斥锁:互斥锁不能被同一个进程acquire多次
- 加锁可以保证多个进程修改同一块数据时,同一个时间只有一个进程能够操作目标,这样虽然牺牲了速度,但保证了数据的安全性,用时间换安全
- 所以我们需要对方法进行改进,保证既能有速度,又能保证安全,这就是IPC机制
#抢票的例子
import time
import json
from multiprocessing import Process,Lock
def get_ticket(i,lock):
with open('ticket',encoding='utf-8') as f1:
ticket=json.load(f1)
print('%s:还有%s张票'%(i,ticket['num']))
with lock:
# lock.acquire()
with open('ticket', encoding='utf-8') as f1:
ticket = json.load(f1)
if ticket['num']>0:
print('%s抢到票了'%i)
ticket['num']-=1
time.sleep(0.1)
with open('ticket','wt',encoding='utf-8') as f2:
json.dump(ticket,f2)
# lock.release()
if __name__ == '__main__':
lock=Lock()
for i in range(10):
Process(target=get_ticket,args=(i,lock)).start()
进程之间通信(IPC)
基于文件
- 同一台机器上的多个进程之间的通信,是基于socket文件级别的通信来完成数据传递的
- 基于文件的IPC有队列和管道
- 管道是基于双向链表,队列是基于管道+锁
基于网络
- 同一台机器或者多台机器间的多进程的通信
- 一般通过第三方工具(消息中间件)来完成
- redis
- memcache
- kafka
- rabbitmq
- 一般通过第三方工具(消息中间件)来完成
生产者消费者模型
- 生产者消费者模型将获取数据和处理数据两件事情进行解耦,根据生产者和消费者效率的不同调整两者的数量,这样平衡了生产消费的数量,提升了效率
- 使用:爬虫、celery分布式框架(可以近似看成两个生产者消费者模型)
from multiprocessing import Process,Queue
def consumer(name,q):
while True:
ret = q.get()
if ret:
print('%s吃了%s'%(name,ret))
else:break
def procedure(food,q):
for i in range(10):
foods='%s%s'%(food,i)
print('%s生产了%s'%(i,foods))
q.put(foods)
if __name__ == '__main__':
q=Queue() #设置队列
p1=Process(target=procedure,args=('红薯',q))
p1.start()
p2=Process(target=procedure,args=('竹子',q))
p2.start()
c=Process(target=consumer,args=('团团',q))
c.start()
p1.join()
p2.join()
q.put(None)
进程之间数据共享
- 进程之间是数据隔离的,但可以通过Manger模块实现数据间的共享
- Manger模块有list和dict,一般跟lock一起用,保证数据的安全
from multiprocessing import Process,Manager,Lock
def change_dic(dic,lock):
with lock:
dic['count'] -= 1
if __name__ == '__main__':
m = Manager()
# with Manager() as m:
lock = Lock()
dic = m.dict({'count': 100})
#list=m.list([1,2,3])
# dic = {'count': 100}
p_l = []
for i in range(100):
p = Process(target=change_dic,args=(dic,lock))
p.start()
p_l.append(p)
for p in p_l : p.join()
print(dic)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号