


Linux 正则
一、引用自:https://www.cnblogs.com/chensiqiqi/p/6285060.html
二、grep示例
grep -i 忽略大小写
grep -w 精准匹配
grep -E 匹配正则
^(以什么开头),.*(任意字符)
三、正则表达式分类
1、基本正则表达式(BRE , basic regular expression)
2、高级功能:扩展正则表达式 (ERE , extended regular expression)
3、BRE和ERE的区别仅仅是元字符的不同:
a、基本正则表达式只承认的元字符有^$.[]*其它字符识别为普通字符:\(\)
b、扩展正则表达式则添加了() {} ? + | 等
c、只有在用反斜杠""进行转义的情况下,字符() {} 才会在基本正则表达式被当做元字符处理,而扩展正则表达式中,任何元符号前面加上反斜杠反而会使其被当做普通字符来处理。
四、如何区分通配符和正则表达式
1、不需要思考的判断方法:在三剑客awk,sed,grep,egrep都是正则,其它都是通配符。
五、基础正则表达式
1、^ : ^word搜索以word开头的内容
grep "^m" aaa.test.txt
2、$ : word$搜索以word结尾的内容
grep "m$" aaa.txt
3、^$ :表示空行,不是空格
grep -n "^$" aaa.txt
4、. : 代表且只能代表任意一个字符(不匹配空行)
grep -n ".m" aaa.txt
5、\ :转义字符,让有特殊含义的字符脱掉马甲现出原形,如 \. 只表示小数点
grep -n "\.c" aaa.txt
6、* : 重复之前的字符或文本0个或多个,之前的文本或字符连续0次或多次
grep -n "q*" aaa.txt
7、.* : 任意多个字符
grep -n ".*" aaa.txt
8、^.* : 以任意多个字符串开头,.*尽可能多,有多少算多少,贪婪性
grep -n "^.*o" aaa.txt
9、括号表达式 : [abc][0-9][\.,/] : 匹配字符集合内的任意一个字符a 或 b 或 c : [a-z] 匹配所有小写字母;表示一个整体,内藏无限可能;[abc]找a或b或c 也可以写成[a-c]
grep -n "^[ade]" aaa.txt
grep -n "[abc]" aaa.txt
10、[^abc] 匹配不包含^后的任意字符a或b或c,是对[abc]的取反,且与^含义不同,若要匹配^字符,则^不能放在[]里的最前面,[ab^c]
grep -n "[^abc]" aaa.txt
grep -n "[ab^c]" aaa.txt
11、a\{n,m\} 重复前面a字符n到m次
grep "d\{2,3\}" aaa.txt
六、扩展正则表达式ERE
1、+ : 重复前一个字符一次或一次以上,前一个字符连续一个或多个,把连续的文本/字符取出

grep -E 等价于 egrep
2、? : 重复前面一个字符0次或1次(.是有且只有1个)
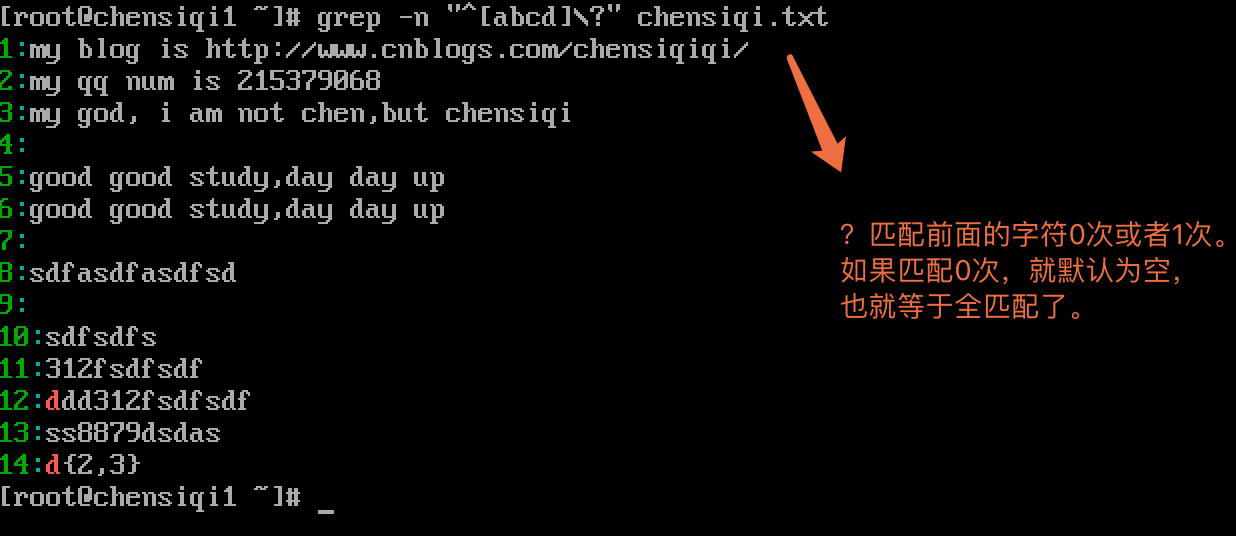
3、管道符 表示或者 同时过滤多个字符
netstat -anpt | grep -E "25|631"
4、() 分组过滤被括起来的东西表示一个整体(一个字符),后向引用
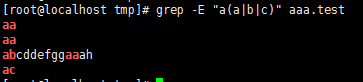
表示aa 或者 ab 或者ac
七、基本正则和扩展正则区别
基本正则BRE 扩展正则ERE
\? ?
\+ +
\{\} {}
\(\) ()
\
八、元字符
1、\b : 单词边界。 \bcool\b,不匹配coolant
2、\B :非单词边界。cool\B匹配coolant不匹配cool
3、\d :单个数字字符 b\db匹配b2b,不匹配bcb
4、\D :单个非数字字符 b\Db匹配bcb不匹配b2b
5、\w :单个单词字符(字母,数字与_) \w匹配1或a,不匹配&
6、\W :单个非单词字符 \W匹配&,不匹配1或a
7、\n :换行符 \n匹配一个新行
8、\s :单个空白字符 x\sx匹配x x,不匹配xx
9、\S :单个非空白字符 x\Sx匹配xkx,不匹配x x
10、\r :回车 ,\r匹配回车
11、\t : 横向制表符,\t匹配一个横向制表符
12、\v :垂直制表符,\v匹配一个垂直制表符
13、\f :换页符,\f匹配一个换页符

