


Linux学习124 keepalived和nginx实现高可用故障转移
一、回顾
1、keepalived:HA Cluster
a、vrrp:vrrp_instance
虚拟路由器:物理路由器;
VRID:Virutal Router ID;
Master/Backup
一主一备或一主多备;
priority
抢占模式/非抢占模式
b、ipvs wrapper:通过ipvs wrapper去完成调用内核中的ioctl桶系统调用,从而实现向ipvs上添加或管理规则。ipvs wrapper的变动将取决于各种各样的checkers所获取的结果
checkers:对各vs的各RS做健康状态检测;
应用层检测:HTTP_GET,SSL_GET,SMTP_CHECK
传输层检测:TCP_CHECK
自定义检测:MISC_CHECK
二、使用keepalived + nginx
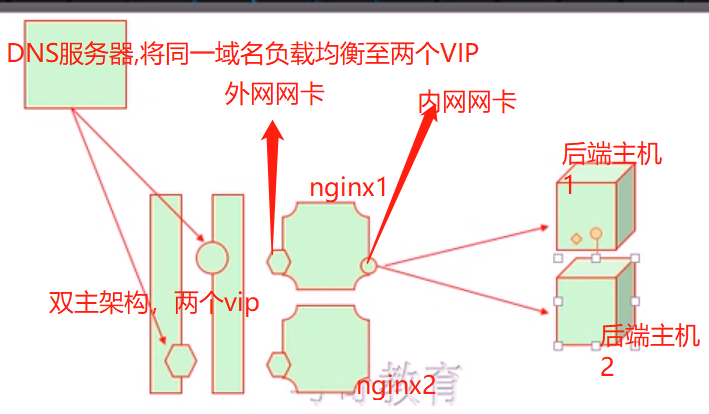
1、架构图
2、配置
a、主机规划:
(1)、nginx1(node1):外网网卡:172.16.10.41 内网网卡:192.168.10.41
(2)、nginx2(node2):外网网卡:172.16.10.42 内网网卡:192.168.10.42
(3)、后端主机1(node3,此处我们只是使用一个后端主机配置多个IP,我们的服务配置多个虚拟主机即可):192.168.10.43,192.168.10.44,192.168.10.45
b、首先后端主机node3上的http服务
(1)、网卡配置如下
[root@node3 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=static DEFROUTE=yes IPV4_FAILURE_FATAL=no NAME=ens33 #UUID=ce6a520c-95ca-4224-a123-f2d2d8592166 DEVICE=ens33 ONBOOT=yes IPADDR0=192.168.10.43 NETMASK=255.255.255.0 GATEWAY=192.168.10.254 IPADDR1=192.168.10.44 IPADDR2=192.168.10.45 DNS1=8.8.8.8 DNS2=114.114.114.114 [root@node3 ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:64:52:46 brd ff:ff:ff:ff:ff:ff inet 192.168.10.43/24 brd 192.168.10.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.10.44/24 brd 192.168.10.255 scope global secondary noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.10.45/24 brd 192.168.10.255 scope global secondary noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe64:5246/64 scope link valid_lft forever preferred_lft forever
(2)、web配置如下
[root@node3 ~]# cat /etc/httpd/conf.d/vhosts.conf <VirtualHost 192.168.10.43:80> ServerName 192.168.10.43 DocumentRoot "/data/web/vhost1" <Directory "/data/web/vhost1"> Options FollowSymLinks AllowOverride None Require all granted </Directory> </VirtualHost> <VirtualHost 192.168.10.44:80> ServerName 192.168.10.44 DocumentRoot "/data/web/vhost2" <Directory "/data/web/vhost2"> Options FollowSymLinks AllowOverride None Require all granted </Directory> </VirtualHost> <VirtualHost 192.168.10.45:80> ServerName 192.168.10.45 DocumentRoot "/data/web/vhost3" <Directory "/data/web/vhost3"> Options FollowSymLinks AllowOverride None Require all granted </Directory> </VirtualHost> [root@node3 ~]# curl 192.168.10.43 <h1>Vhost1</h1> [root@node3 ~]# curl 192.168.10.44 <h1>Vhost2</h1> [root@node3 ~]# curl 192.168.10.45 <h1>Vhost3</h1>
c、接下来配置keepalived高可用nginx,keepalived要想高可用nginx这种服务其内建是没有这种功能的,因此他需要调用外部的服务脚本进行资源监控,我们只需要确保nginx在对应节点始终处于运行状态即可。万一nginx没有运行我们可以想办法把他启动起来,所以这个外部脚本只有一个作用,当地址转移到这个节点上的时候,我们想办法把nginx给启动起来或重启一下。所以keepalived我们就需要去定义这样一个脚本,即一旦地址转移过来或转移走的时候我们都能执行这个脚本,转移过来就启动nginx转移走的话将nginx服务停止即可。我们还可以用这个脚本来做一些外部资源监控,比如看这台主机上nginx进程是否还在运行着,如果在运行着我们就认为这台主机上的nginx服务是正常的,地址不需要转移,如果当前节点nginx进程运行不了了,例如有人把nginx关掉再启动了httpd,再次启动nginx时就启动不了了,因为他的端口被征用了。如果启动不了我们就不能将当前节点作为主节点了,我们就需要降低优先级,本来A主机是100,B主机是96,我们将A主机优先级减去10就变成90了,B主机就变成主节点了。
(1)、keepalived调用外部的辅助脚本进行资源监控,并根据监控的结果状态能实现优先动态调整;
分两步:
1)、先定义一个脚本;
vrrp_script <SCRIPT_NAME> {
script "" #脚本命令,一般而言脚本很简单的话可以直接写到这儿
interval INT #每隔多少时间监控脚本就执行一次
weight -INT #万一失败了当前节点的权重就减去多少,我们一般需要确保减去这个数后当前节点的权重要小于备节点。
}
2)、调用此脚本。(1)中我们是定义的在某个vrrp实例中打算基于这个脚本来决定我们地址是如何转移的,我们调用此脚本的方式如下:
track_script {
SCRIPT_NAME_1
SCRIPT_NAME_2
...
}
(2)、示例
1)、定义一个检查nginx进程的脚本
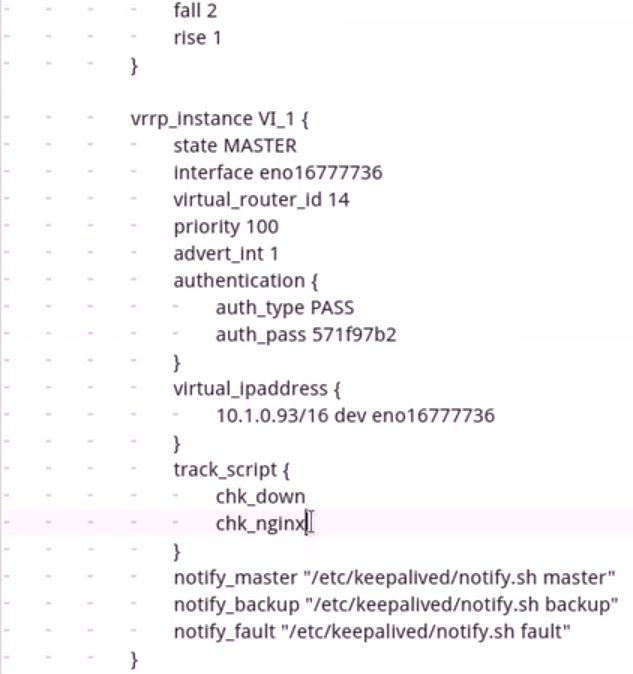
vrrp_script chk_nginx {
script "killall -0 nginx && exit 0 || exit 1" #killall -0 的意思是查询这个进程是否存在但是不真正杀死他,意思是看我的killall命令能否执行,如果这个进程存在表示能执行即测试成功,如果不存在就表示不能执行即测试失败。此处我们的意思是测试成功就返回0,测试失败就返回1。
interval 1 #每隔1s监控脚本就执行一次
weight -5 #如果监测失败了就将优先级降低为5
fall 2 #如果检测不在,至少需要检测两次才能定义检测真失败了
rise 1 #如果此前是失败的然后再次检测他又成功了,只要检测成功了1次就立即把检测失败的权重再加回来。
}
2)、定义一个升降权的脚本,我们可以定义检测/etc/keepalived/down这个文件是否存在,如果存在则降权,虚IP就切换为备,如果不存在则升权,虚IP又被切换回来。如果想手动降权touch /etc/keepalived/down即可,如果想升权将down文件删除即可。
vrrp_script chk_down {
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1
weight -5
}
(3)、脚本定义和调用截图

d、配置node1和node2的keepalived服务
(1)、配置虚IP检测,当/etc/keepalived/down文件存在时虚IP浮动到备节点,不存在时虚IP浮动到主节点。
node1中的配置信息如下
[root@node1 keepalived]# cat keepalived.conf global_defs { notification_email { root@localhost } notification_email_from keepalived@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id node1 vrrp_mcast_group4 224.1.101.33 } vrrp_script chk_down { script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0" #检测/etc/keepalived/down文件是否存在,存在则正常退出,不存在则错误退出。此处最好写成脚本执行而不要直接写成命令。 weight -10 #如果脚本不存在则权重减去10 interval 1 #每隔1s监控脚本就执行一次 fall 1 ##如果检测不在,至少需要检测1次才能定义检测真失败了 rise 1 #如果此前是失败的然后再次检测他又成功了,只要检测成功了1次就立即把检测失败的权重再加回来。 } vrrp_instance VI_1 { state MASTER priority 100 interface ens33 virtual_router_id 51 advert_int 1 authentication { auth_type PASS auth_pass w0KE4b81 } virtual_ipaddress { 192.168.10.100/24 dev ens33 label ens33:0 } track_script { chk_down #根据上述定义的chk_down这个脚本来判定状态是否ok。 } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" }
node2中的配置信息如下
[root@node2 keepalived]# cat keepalived.conf global_defs { notification_email { root@localhost } notification_email_from keepalived@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id node2 vrrp_mcast_group4 224.1.101.33 } vrrp_script chk_down { script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0" #检测/etc/keepalived/down文件是否存在,存在则正常退出,不存在则错误退出,此处最好写成脚本执行而不是命令。 weight -10 #如果脚本不存在则权重减去10 interval 1 #每隔1s监控脚本就执行一次 fall 1 ##如果检测不在,至少需要检测1次才能定义检测真失败了 rise 1 #如果此前是失败的然后再次检测他又成功了,只要检测成功了1次就立即把检测失败的权重再加回来。 } vrrp_instance VI_1 { state BACKUP priority 96 interface ens33 virtual_router_id 51 advert_int 1 authentication { auth_type PASS auth_pass w0KE4b81 } virtual_ipaddress { 192.168.10.100/24 dev ens33 label ens33:0 } track_script { chk_down #根据上述定义的chk_down这个脚本来判定状态是否ok。 } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" }
(2)、我们通过上述配置启动keepalived服务后发现,当创建/etc/keepalived/down文件后我们的vip会从master飘逸到bakup,将该文件删除后vip会从backup飘逸到master。
e、接下来我们来配置keepalived + nginx
(1)、首先我们在node1和node2两个节点安装nginx用作为反向代服务
[root@node1 yum.repos.d]# yum install -y nginx
(2)、接下来我们进行node1和node2中的nginx的配置(两节点配置一致)
[root@node1 nginx]# cat nginx.conf |grep -Ev " *#" user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; upstream websrvs { server 192.168.10.43:80; server 192.168.10.44:80; server 192.168.10.45:80; } include /etc/nginx/conf.d/*.conf; server { listen 80 default_server; listen [::]:80 default_server; server_name _; root /usr/share/nginx/html; include /etc/nginx/default.d/*.conf; location / { proxy_pass http://websrvs; } error_page 404 /404.html; location = /404.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } } }
我们可以看到nginx可以正常代理到后端
[root@node1 nginx]# curl 192.168.10.41 <h1>Vhost1</h1> [root@node1 nginx]# curl 192.168.10.41 <h1>Vhost2</h1> [root@node1 nginx]# curl 192.168.10.41 <h1>Vhost3</h1> [root@node1 nginx]# curl 192.168.10.100 <h1>Vhost1</h1> [root@node1 nginx]# curl 192.168.10.100 <h1>Vhost2</h1> [root@node1 nginx]# curl 192.168.10.100 <h1>Vhost3</h1>
(3)、接下来我们来配置脚本监控nginx服务是否正常,我们可以配置监控脚本来决定地址转移时nginx服务是否启动,一旦当前节点变为备节点我们就将nginx服务给停止,如果当前节点变成主节点我们又需要将nginx服务给启动起来。
1)、我们可以在notify.sh脚本中添加两个命令,在当前节点为主节点的时候将nginx服务启动,在当前节点为备节点的时候将nginx服务停止。(node1和node2节点都添加)
[root@node1 nginx]# cat /etc/keepalived/notify.sh #!/bin/bash # contact='root@localhost' notify(){ mailsubject="$(hostname) to be $1,vip floating" mailbody="$(date +'%F%T'):vrrp transltion,$(hostname) changed to be $1" echo "$mailbody" |mail -s "$mailsubject" $contact } case $1 in master) systemctl start nginx.service notify master ;; backup) systemctl stop nginx.service notify backup ;; fault) systemctl stop nginx.service notify fault ;; *) echo "Usage: $(basename $0) {master|backup|fault}" exit 1 ;; esac
2)、开始我们的vip在node1中,node1和node2中的nginx都停止服务。我们可以在node1中创建/etc/keepalived/down 文件,可以看到vip转移到了node2,并且node2中的nginx服务也启动起来了,然后我们将node1中的down文件删除会发现vip又会漂移至node1,并且node1中的nginx服务自动启动了,node2中的nginx服务也自动停止了。
3)、不过一般而言,为了把nginx自身服务用作进程运行检查脚本的话无论主备节点都不应该把nginx进程停掉,因为停止的话一检查nginx进程没有,那么他就会降权,就算是备节点也会降权的,如果主节点nginx服务挂了,那么主节点就会降权降了10,备节点因为nginx默认是停止的所以一开始降权也是降了10,这样的话主备节点都降权降了10,这样的话主节点的优先级还是要高于备节点,那么地址就转移不出去了。因此我们备节点原则上是不应该停止nginx服务的,而是应该备节点也启动nginx的,他如果停止了我们就启动,他如果出现了故障我们就重启。因此此处我们需要将主备就都配置启动nginx,相应的notify.sh配置应该如下:
[root@node1 keepalived]# cat /etc/keepalived/notify.sh #!/bin/bash # contact='root@localhost' notify(){ mailsubject="$(hostname) to be $1,vip floating" mailbody="$(date +'%F%T'):vrrp transltion,$(hostname) changed to be $1" echo "$mailbody" |mail -s "$mailsubject" $contact } case $1 in master) systemctl start nginx.service notify master ;; backup) systemctl start nginx.service notify backup ;; fault) systemctl stop nginx.service notify fault ;; *) echo "Usage: $(basename $0) {master|backup|fault}" exit 1 ;; esac
此时我们无论哪个node是主备nginx服务就都不会停止了。
f、那么我们如果要在前端主机上对nginx做出监控动作需要怎么办?接下来我们来编辑脚本来监控nginx进程。
(1)、我们配置监控脚本(在两个节点上都需要配置)
[root@node1 /]# cat /etc/keepalived/keepalived.conf global_defs { notification_email { root@localhost } notification_email_from keepalived@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id node1 vrrp_mcast_group4 224.1.101.33 script_user root enable_script_security } vrrp_script chk_down { # script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0" script "/application/test.sh" weight -10 interval 2 fall 2 rise 2 } vrrp_script chk_ngx { script "/application/chk_ngx.sh" weight -10 interval 2 fall 2 rise 2 } vrrp_instance VI_1 { state MASTER priority 100 interface ens33 virtual_router_id 51 advert_int 2 authentication { auth_type PASS auth_pass w0KE4b81 } virtual_ipaddress { 192.168.10.100/24 dev ens33 label ens33:0 } track_script { chk_down chk_ngx } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" } [root@node1 /]# cat /application/chk_ngx.sh #!/bin/bash # #查看nginx是否存在,如果存在则正常退出如果不存在则异常退出 killall -0 nginx && exit 0 || exit 1 [root@node1 /]# chmod +x /application/chk_ngx.sh
(2)、接下来我们重启keepalived服务。此时我们的vip在node1中。然后我们在node1中安装一个httpd后将nginx停止然后启动httpd,这样我们node1中nginx服务就启动不起来了,我们可以看到vip就从node1中漂移到node2中了。然后我们将node1中的httpd服务停掉然后将nginx服务启动起来,然后发现我们的vip又漂移到了node1。

