


Linux学习121 企业级高可用集群介绍以及开源软件应用
一、高可用方案
1、业内常用的方案
a、keepalived
b、hearbeat(几乎已经废弃)
c、corosync:通用的,专业的高可用集群解决方案。
2、通信层面
a、消息层(messaging layer)也叫心跳层(heartbeat layer)也叫基础设施层(infrastructure layer)。
b、资源管理器层:在这个层次之上会再有一层,决定哪些资源该被监控,一旦出现故障时哪些资源该被启动以及在哪个节点上启动,资源更倾向于在哪个节点上启动等等。这一层我们称之为集群资源管理器(cluster resource manager),也叫crm。他负责组织资源成高可用服务,并利用底层。资源管理器也是每个节点上都应该装的。我们虽然认为说他是一个通用层,但是实际上他还是靠通信来实现的,所以每一个资源管理器都只能与自己本地节点上底层的心跳层来进行通信,他利用心跳层传递过来的信号判定其他节点是不是故障,crm层与心跳层之间彼此之间是有协议的,但是该怎么做需要依赖于底下的这个心跳层所传递的消息来做出判定。资源和资源必须在一起才能组织成可用服务的。

c、本地资源管理器层:资源管理器只是负责做决策的,他并不真正去执行把资源抢过来或运行起来这个功能,要执行这个功能还需要再向上一层,我们称之为本地资源管理器(local resource manager,也叫LRM)。他主要负责接收下面这一层(资源管理器)所发来的指令,比如,你帮我把IP地址启动起来,把IP地址拿掉,把nginx进程启动起来,或者把nginx进程拿掉,或者取得nginx状态是否ok。他就接收一个个指令负责执行,一样的,LRM也是一个层次,他怎么执行那么多资源和服务呢?因为每一个执行的方式都不一样的。所以LRM把这一个又一个具体的资源管理委托给了外部的功能,他自己不具体实现,因为这里需要实现的功能太多了。因为每一个服务都可能有一个脚本或一个unit file,并且我们的IP地址如果要配置时是需要给一个IP地址和掩码才能配置上去的。所以各有不同,因此LRM把每一个具体操作通过一个接口输出出来,用户可自行定义一个脚本,把这个脚本委托给LRM就行了,下一次你想我启动我就激活这个脚本就行了,启动就传递start参数就行,停止就传递stop,如果要看状态就status。所以这里有一个一个又一个具体的实现某一个特定资源的监控或管理的脚本或者是支撑的unit file。这一个一个又一个的实现我们通常称之为资源代理(resource agent,也叫RA),他们不是资源,但是他们可以帮你去管理资源,是脚本,也可能是unit file。
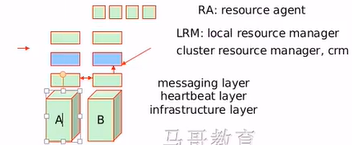
d、在这种框架下他们平时是怎么工作的呢?假如现在A主机是主的,那么A主机会定期一秒钟或半秒钟向B主机发一次心跳,告诉B主机自己工作正常。很可能告诉B自己有着更高的优先级。然后他会优先使用资源,此时只有A挂了B才能拥有继承权。一个集群中有可能不止两个节点,并且B主机连不到A主机也不一定是A出现问题了,也有可能是中间网络坏了,这种不能真正判定A挂了,因此可以有仲裁节点。所以一般集群会有3个或以上节点,并且为奇数。比如有ABC三个节点,B节点连不到A节点但是能连接到C节点,说明A节点挂了。
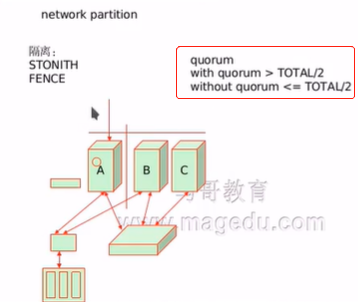
e、隔离:假如我们集群中某台主机挂了,我们可以将其进行隔离,隔离有如下方式
(1)、STONITH(一枪打在其他节点头上):即爆头的意思,其需要借助设备来实现。这种通常很暴力很残忍。他属于节点级别的隔离。
(2)、FENCE(隔离):一般来讲我们只要想办法让判定为故障的节点不再访问一个关键资源就可以了,比如A,B,C判定为A故障,B就把IP地址拿过来,如果A没故障,A再拿回去,B再拿过来A再拿回去不会造成致命结果的。这种最多用户一会儿能访问一会儿不能访问,没有致命损害,而有些时候这种操作行为可能带来致命损害的。比如A上面挂了一个存储正在写,然后IP被B抢过去了,B也将该存储挂上,此时A还没有宕机,A也正在写着,此时两个节点都在对存储进行写操作,然后文件系统元数据就会崩溃,元素据崩溃了文件系统也就崩溃了。因此此种情况就必须要进行爆头,即干掉故障的这个。当然也可以不用爆头,用隔离的方式,他可以在交换机侧屏蔽A设备或者B设备接进来的信号,以达到隔离的效果。他属于资源级别的隔离,只隔离对某个关键资源的访问。
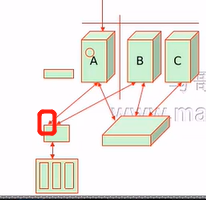
f、网络故障是很有可能会发生的,发生后为了避免大家各自工作,我们需要保证只有一方能够代表集群工作而这种判定机制我们就称之为quorum机制。
推荐paxos,raft两篇论文
3、高可用方式
a、N/M模型:N个节点,M个服务。我们可以在资源级别定义对节点的倾向性,比如x资源更倾向于A节点,y资源更倾向于B节点。
b、vrrp:virtual routing redundant protocol(虚拟路由冗余协议)
二、keepalived
1、官方架构图
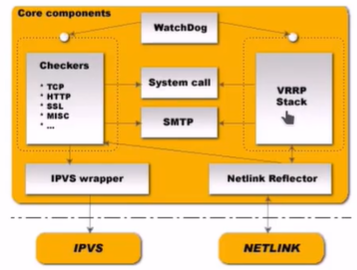
2、keepalive相应术语
a、虚拟路由器:由一个Master路由器和多个Backup路由器组成,主机将虚拟路由器当作默认网关。
b、VRID:虚拟路由器的标识,有相同VRID的一组路由器构成一个虚拟路由器。比如我们一个集群有3台主机,每个主机都有4块网卡,我们可以将每台主机的第一个网卡标记为1,然后将这几块网卡组织成1号路由器。然后我们还可以将每台主机的第二个网卡标记为2,然后将标记为2的这三个网卡组织成2号路由器,以此类推我们就可以组织4个虚拟路由器,那么这些路由器我们彼此之间怎么区别呢?我们就可以通过VRID来进行区分。因此简单来讲我们VRID就是标识虚拟路由器的。
c、Master路由器:虚拟路由器中承担报文转发任务的路由器。
d、Backup路由器:Master路由器出现故障时,能够代替Master路由器工作的路由器。
e、虚拟IP地址:虚拟路由器的IP地址。一个虚拟路由器可以拥有一个或多个IP地址。
f、IP地址拥有者:接口IP地址与虚拟IP地址相同的路由器被称为IP地址拥有者。
g、虚拟MAC地址:一个虚拟路由器拥有一个虚拟MAC地址。虚拟MAC地址的格式为00-00-5E-00-01-{VRID}。通常情况下,虚拟路由器回应ARP请求使用的是虚拟MAC地址,只有虚拟路由器做特殊配置的时候,才回应接口的真实MAC地址。
h、优先级:VRRP根据优先级来确定虚拟路由器中每台路由器的地位。
i、非抢占方式:如果Backup路由器工作在非抢占方式下,则只要Master路由器没有出现故障,Backup路由器即使随后被配置了更高的优先级也不会成为Master路由器。
j、抢占方式:如果Backup路由器工作在抢占方式下,当它收到VRRP报文后,会将自己的优先级与通告报文中的优先级进行比较,如果自己的优先级比当前的Master路由器的优先级高,就会主动抢占成为Master路由器,否则,将保持Backup状态。

