


Linux学习111 基于LVS实现4层负载均衡模式和场景应用
一、回顾
1、Linux Cluster
a、LB/HA/HP
b、分布式系统:存储/计算
2、LB Cluster
a、硬件:F5-BigIP/Netscaler/A10
b、软件:
四层:lvs(真四层),伪四层:nginx(stream)/haproxy(mode tcp)
七层:http:nginx(http)/httpd/haproxy(mode http)/ats/peribal/pound
mysql:ProxySQL,...
3、lvs:Linux Virutal Server
a、vs/rs;cip/vip/dip/rip
b、lvs type:
nat/dr/tun/fullnat
nat类型:多目标IP的DNAT,通过修改请求报文的目标IP和PORT来实现调度
dr类型:通过为请求报文重新封装一个MAC首部进行转发:源MAC是DIP所在的接口的MAC,目标MAC是某挑选出的RS的RIP所在接口的MAC地址
二、LVS(2)
1、lvs-tun
a、转发方式:不修改请求报文的IP首部(源IP为CIP,目标IP为VIP),而是在原IP报文之外再封装一个IP首部(源IP是DIP,目标IP是RIP),将报文发往挑选出的目标RS;RS直接响应给客户端(源IP是VIP,目标IP是CIP);
b、DIP,VIP,RIP都应该是公网地址
c、RS的网关不能,也不可能指向DIP
d、请求报文要经由Director,但响应不能经由Director
e、不支持端口映射
f、RS的OS得支持隧道功能
g、在nat和DR模式中,我们双绞线的最大传输距离只有一百米,并且DIP所属的网卡与RIP所属的网卡需要在同一个物理网络。这两种方式所能带来的结果就是你的RS和Director都应该在非常近的距离上,一般来讲他是无法跨机房的。那么如果我想做灾备的话要怎么办呢?即假如我们有两个RS,一个在东京机房,一个在北京机房,还有一个在纽约机房,假如我们东京机房翻车了我们北京和纽约机房还能正常工作。如果都托管在东京的话一翻车就全翻车了,如果是这种方案的话前两种模式就都没法工作了,这种的话就需要用到我们的隧道模型。隧道模型指的是互连网上有一个主机当Director,后面的RS可以是互联网上其它地方的主机,这些主机上也都可以配置好VIP地址。和我们DR模型一样他们也应该有VIP,因为对tun模型来讲也是请求报文要有Director而响应报文没有Director,即请求报文要过Director而响应报文是由RS直接响应给客户端的。在我们DR模式中我们说过在RS上不能做ARP广播通告也不能做响应,而我们在做tun模式时各主机因为也要做VIP那么是否也需要不能做ARP广播通告和做响应呢?其实是不用的,因为大家都不在同一网络中,我们广播和通告只是在本地局域网中实现的,所以是不会有任何干扰的。那么我们因为都有VIP那么用户请求直接发给了RS了要怎么办呢?这个其实可以这样来,既然大家相距很远那么所属的网段就不同,在互联网上一个网段,比如12.12.12.0,可不可能在不同区域的RS上分布呢?这是不可能的。因此假如我们对外宣称的VIP地址是互联网上的可达地址并且配置在Director上,所以只有Director这个地址在互联网上路由器路由可达的,因为在Director上这个地址一定所属的网络必须是你的直接地址所应该属于的网络,所以假设我们的Director的地址是12.12.12.1/24,我们其它的RS上是不可能是12.12.12.0网络中。所以我们后端的RS上配置的VIP和自身的RIP肯定是不在同一网段的。
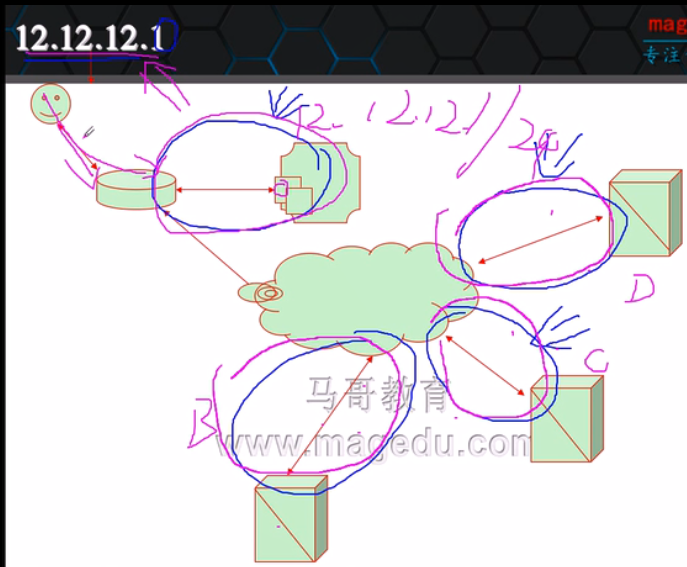
所以基于此互连网上用户的请求报文主要是对这个VIP进行请求,如果我们要VIP可达的话那么这个地址得属于你的Director主机上所配置的网络中的某一地址才行,既然他只能送到VIP这个网络,只要我们各RS没有与Director在同一个网络中那么他们都不可能收到请求的。至少说不可能直接收到请求。所以所有在互联网上的报文请求都应该而且只能路由给Director,也不无需配置其它东西,那么到Director的报文怎么转发到RS呢?
当用户请求到达Director时,源IP为CIP,目标IP为VIP,Director收到请求报文以后一看目标IP是自己,于是交给INPUT,INPUT一检查是集群服务,于是该转发了,他转发后目标IP就发不出去了,这时候要怎么办呢?在请求报文中有我们原来的源CIP,目标地址VIP等IP守护,这些都不会动,相当于Director会在此守护之外重新封装一个IP,这个IP守护中的源IP是DIP,目标IP是某一个RIP,很显然他扔回来给路由器,即给自己网关,然后网关就以RIP来作为目标IP进行路由了,RIP应该是后端的RS中的某一个RS的地址,比如是D网络中的主机,此时我们的B和C网络是不会收到报文请求的。D网络中的主机RS1收到报文后发现目标IP是自己的IP,于是拆除封装,然后一看又有一个IP守护,他就会觉得莫名其妙,因此我们这个RS必须要理解隧道的功能协议才行,知道为什么会有两层IP报文守护,于是拆开外层IP报文守护以后发现内层IP守护居然是VIP,我们的VIP是不是我们RS1自己也有呢,于是继续拆,然后他就会认为这个报文请求的是VIP的某个端口,而VIP肯定是自己啊,端口肯定是本地某一个端口,所以响应报文就交给这个进程,既然请求报文目标地址是VIP于是他封装响应报文时,比如他发回去的时候,源IP就是自己的VIP,目标IP就是CIP,然后就直接扔到互联网上,然后路由以后CIP就收到了。就完成了我们请求和响应报文的传输。

2、lvs-funllnat(注意:此类型默认不支持)
a、通过同时修改请求报文的源IP地址和目标IP地址进行转发;
1)、CIP <--> DIP
2)、VIP <--> RIP
b、VIP是公网地址,RIP和DIP是私网地址,且通常不在同一IP网络,因此,RIP的网关一般不会指向DIP
c、RS收到的请求报文源地址是DIP,因此,只需响应给DIP,但Director还要将其发往Client
d、请求和响应报文都经由Director
e、支持端口映射
f、其实我们在请求报文上是有一定问题的,每一个报文在传输时你的网络设备有MTU的概念,即最大传输单元,我们整个传输报文加一个IP首部再加mac假如就已经到MTU上限了,如果再加一个就超出MTU大小了,即1500,好在多数情况下请求报文不会带更多数据。那么如果我们只是跨一个楼房,用隧道的话传输效率肯定不会太高。所以我们就可以用funllnat,这个的话是需要你自己在内核中打补丁的,因为内核中ipvs自己没有带。
g、funllnat指的是我们修改转发的时候IP地址都要进行改变。首先我们的CIP通过互联网层层路由到达VIP,我们的VIP也工作于NAT模式下,所不同的是请求报文来的时候源IP是CIP,目标IP是VIP,Director收到以后要基于目标转换的方式发送给我们后端的RS,他与我们RS直接隔了层层的路由设备,此时我们RS的网关已经无法指向DIP,只能指向自己的网关,然后由自己的网关层层路由路由到互联网上去了,不会经由Director,因为我们请求报文是改过的那么我们的响应报文要怎么办呢?所以对于NAT类型来讲他的请求和响应报文都要经过Director,请求报文是被Director中相应的规则修改以后调度的,而响应报文则是由Director自己追踪以后来相应修改的。所以响应报文必须经过Director,否则他是没法将请求报文进行返回的。
h、所以收到请求报文后Director将源IP改成DIP,目标IP改成了RIP,然后经过层层路由后报文到达RS,RS收到报文后一看目标IP是自己,然后他就进行处理,处理完以后响应给谁呢?他会响应给DIP,因为源IP是DIP,所以既然目标IP为DIP那么他就一定会到达Director,然后我们的DIP收到以后发现是自己NAT之后转发的,所以他会查找NAT的连接追踪表,把响应报文的目标IP从DIP改成CIP,把源地址从RIP改成VIP。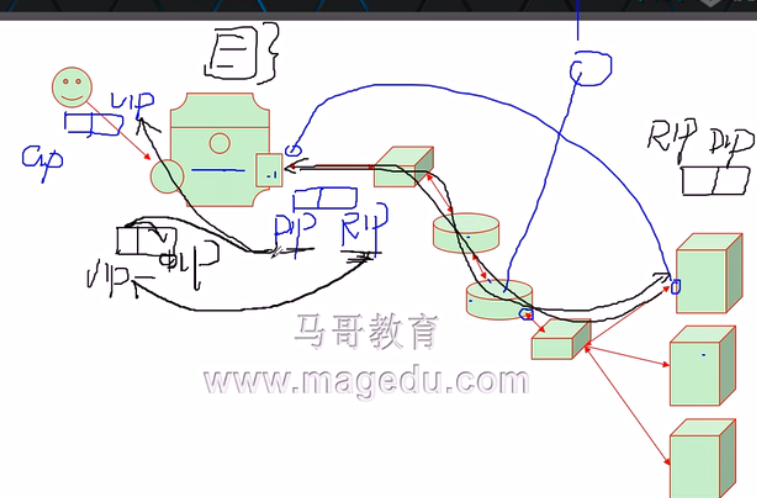
3、总结:
a、lvs-nat,lvs-fullnat:请求和响应报文都经由Director
(1)、lvs-nat:RIP的网关要指向DIP
(2)、lvs-fullnat:RIP和DIP未必在同一IP网络,但要能通信
b、lvs-dr,lvs-tun:请求报文要经由Director,但响应报文由RS直接发往Client
(1)、lvs-dr:通过封装新的MAC首部实现,通过MAC网络转发
(2)、lvs-tun:通过在原IP报文之外封装新的IP报文实现转发,支持远距离通信
三、ipvs scheduler
1、根据其调度时是否考虑备RS当前的负载状态,可分为静态方法和动态方法两种
2、静态方法:仅根据算法本身进行调度
a、RR:roundrobin,轮询
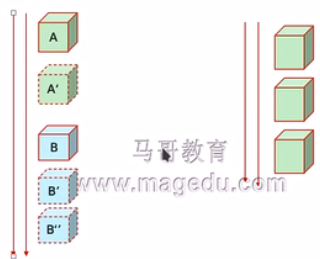
b、WRR:Weighted RR,加权轮询。一加权就意味着一个服务器有可能当多个用了。假如我们有2台服务器,a主机权重为2你可以理解为a主机被虚拟成了2台,b主机权重为3你可以理解为b主机被虚拟成了3台,来了5个请求的话第一二个会给第一个服务器,第三四五个会给第二个服务器。
c、SH:Source Hashing,实现session sticy,源IP地址hash;将来自于同一个IP地址的请求始终发往第一次挑中的RS,从而实现会话绑定。他有个最大的问题在于他是基于IP地址绑定的。很多客户端是通过代理来访问的,所以有可能会是同一个IP,如果用种算法可能会造成后端某个RS负载过大。因此我们一般而言我们都在七层进行绑定不在此处绑定。
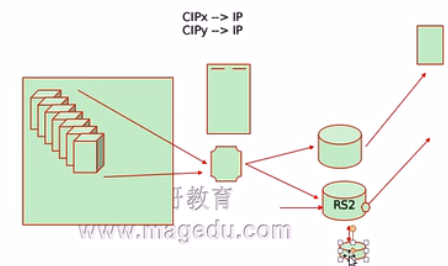
d、DH:Destination Hashing;目标地址哈希,将发往同一个目标地址的请求始终转发至第一次挑中的RS,典型使用场景是正向代理缓存场景中的负载均衡。相当于我们内网服务器要上网的话先将我们的请求发送给负载均衡器,然后由负载均衡器将用户请求代理到两个代理服务器,然后由代理服务器发送到互联网进行请求。因此我们代理服务器可以缓存所以会访问的非常快。
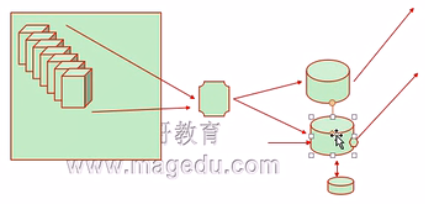
但是这里有一个新的问题,第一个服务器请求被负载到第一个代理服务器,然后第一个代理服务器可以将资源缓存下来,然后第二个服务器的相同的访问请求被负载到第二个代理服务器的话那么我们的缓存就用不上了,我们为了让缓存能够用的上我要怎么办呢?一句话大家访问的是同一个资源所以他的目标IP都是一致的,假如我们访问的是搜狐网的IP地址,我们不管你的源IP是什么,至少你的目的IP是一致的,假如你第一个服务器访问被代理到RS2了,然后你第二台服务器访问时我们的负载均衡器发现目的IP是一样的,所以他把请求也发给RS2。这样我们的缓存就能被命中了
3、动态方法:主要根据每RS当前的负载状态及调度算法进行调度
a、Overhead= #负载值
b、LC:least connections :最少连接,谁的Overhead值小就挑选谁
Overhead=activeconns*256+inactiveconns #活动连接加上非活动连接
c、WLC:Weighted LC :加权最少连接,活动连接加上非活动连接再除以权重,权重越大Overhead越小,也就越容易被挑选出来,他是lvs中的默认算法。但是我们WLC有一个问题,即如果我们所有服务器的Overhead值一样要怎么挑呢?可以通过轮询或加权轮询自上而下挑选。我们刚刚说过我们的轮询是将我们服务器虚拟成多个自上而下进行挑选的,万一有一台服务器权重非常低有一台服务器权重非常高,并且此前一计算Overhead都一样,那么应该挑谁呢?于是我们来看下面的SED
Overhead=(activeconns*256+inactiveconns)/weight
d、SED:Shortest Expection Delay :最短期望延时:他直接不考虑非活动连接。我们可以从下面看到,权重越大,Overhead值也就越小,假如第一个权重是1,第二个是3,如果按照权重来计算,大家刚开始的时候活动连接数都一样,比如都为0,那么我们 (0+1)/1的结果为1,(0+1)/3的结果为1/3,很显然第二个服务器的值越小,他也就会被挑选出来了。
Overhead=(activeconns+1)*256/weight #活动数+1除以权重
e、NQ:Never Queue :我们的SED很完美的解决了WLC的问题,但是他又引入了新问题,比如两台服务器的权重比值刚好相差很大,假如为1/10,那么第一个请求给第二个服务器,第二个请求还是给第二个服务器,因此前9个请求会全到第二个服务器,第10个请求才会到第一个服务器,这种方式是不妥当的,于是就有了第四个方法叫NQ,即从不排队,如果大家现在负载一样,那么没关系,来了请求以后按照权重由大而小依次一人先排一个,比如现在我们有两个服务器,一个权重是1一个权重是10,请求来了后,于是第一个请求给权重为10的,第二个请求给权重为1的,后面的第三第四等等都可以给第二个服务器都没问题,至少让你第一台服务器负载了一个,所以大家都不等待排队。这个虽然看上去非常公平但是其会增加我们调度器的负担,所以我们一般不怎么用。
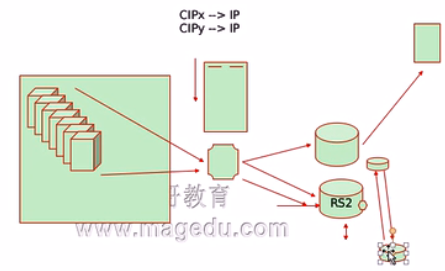
f、LBLC:Locality-Based LC,动态DH算法:也就是我们前面所说的DH算法。即我们内网服务器先将请求发给我们的负载均衡器,然后由我们负载均衡器调度至我们的代理服务器,但是假如我们的一个代理服务器很忙一个代理服务器很闲,这时候我们就需要用到我们的LBLC算法,即如果来了一个新请求此前没有绑定过那么我们的调度算法不是轮询而是根据后端服务器的负载找一个负载较轻的来处理。
g、LBLCR:LBLC with Replication,带复制功能的LBLC。首先我们将我们的调度情况先打散,即我们请求交给我们第二台服务器时假如我们第二台服务器上面没有缓存,他会先去问第一台服务器是否有缓存,如果有的话他就把第一台的缓存给复制过来。
四、配置ipvsadm/ipvs
1、集群和集群之上的各RS是分开管理的
a、集群定义
b、RS定义
2、ipvs:
a、检查是否支持ipvs:
grep -i -C 10 "ipvs" /boot/config-VERSION-RELEASE.x86_64
支持的协议:TCP,UDP,AH,ESP,AH_ESP,SCTP
[root@www ~]# grep -i -C 10 "ipvs" /boot/config-3.10.0-693.el7.x86_64 CONFIG_NETFILTER_XT_MATCH_CPU=m CONFIG_NETFILTER_XT_MATCH_DCCP=m CONFIG_NETFILTER_XT_MATCH_DEVGROUP=m CONFIG_NETFILTER_XT_MATCH_DSCP=m CONFIG_NETFILTER_XT_MATCH_ECN=m CONFIG_NETFILTER_XT_MATCH_ESP=m CONFIG_NETFILTER_XT_MATCH_HASHLIMIT=m CONFIG_NETFILTER_XT_MATCH_HELPER=m CONFIG_NETFILTER_XT_MATCH_HL=m CONFIG_NETFILTER_XT_MATCH_IPRANGE=m CONFIG_NETFILTER_XT_MATCH_IPVS=m CONFIG_NETFILTER_XT_MATCH_LENGTH=m CONFIG_NETFILTER_XT_MATCH_LIMIT=m CONFIG_NETFILTER_XT_MATCH_MAC=m CONFIG_NETFILTER_XT_MATCH_MARK=m CONFIG_NETFILTER_XT_MATCH_MULTIPORT=m CONFIG_NETFILTER_XT_MATCH_NFACCT=m CONFIG_NETFILTER_XT_MATCH_OSF=m CONFIG_NETFILTER_XT_MATCH_OWNER=m CONFIG_NETFILTER_XT_MATCH_POLICY=m CONFIG_NETFILTER_XT_MATCH_PHYSDEV=m -- CONFIG_IP_SET_HASH_NET=m CONFIG_IP_SET_HASH_NETPORT=m CONFIG_IP_SET_HASH_NETIFACE=m CONFIG_IP_SET_LIST_SET=m CONFIG_IP_VS=m CONFIG_IP_VS_IPV6=y # CONFIG_IP_VS_DEBUG is not set CONFIG_IP_VS_TAB_BITS=12 # # IPVS transport protocol load balancing support #支持的协议 # CONFIG_IP_VS_PROTO_TCP=y CONFIG_IP_VS_PROTO_UDP=y CONFIG_IP_VS_PROTO_AH_ESP=y CONFIG_IP_VS_PROTO_ESP=y CONFIG_IP_VS_PROTO_AH=y CONFIG_IP_VS_PROTO_SCTP=y # # IPVS scheduler #支持的调度算法 # CONFIG_IP_VS_RR=m CONFIG_IP_VS_WRR=m CONFIG_IP_VS_LC=m CONFIG_IP_VS_WLC=m CONFIG_IP_VS_LBLC=m CONFIG_IP_VS_LBLCR=m CONFIG_IP_VS_DH=m CONFIG_IP_VS_SH=m CONFIG_IP_VS_SED=m CONFIG_IP_VS_NQ=m # # IPVS SH scheduler # CONFIG_IP_VS_SH_TAB_BITS=8 # # IPVS application helper # CONFIG_IP_VS_FTP=m CONFIG_IP_VS_NFCT=y CONFIG_IP_VS_PE_SIP=m # # IP: Netfilter Configuration # CONFIG_NF_DEFRAG_IPV4=m CONFIG_NF_CONNTRACK_IPV4=m
b、安装ipvs
yum install -y ipvsadm
ipvsadm是用来生成规则然后送给内核中ipvs框架中。

