Kubernetes 学习25 创建自定义chart及部署efk日志系统
一、概述
1、我们说过在helm架构中有这么几个关键组件,helm,tiller server,一般托管运行于k8s之上,helm能够通过tiller server在目标k8s集群之上部署应用程序,而后,helm对应程序部署来自于helm能访问到的仓库中的chart。并且我们可以把chart通过配置生成为 Release,其中config是来自于我们chart中的values.yaml文件,对chart来讲其内部没有太多复杂的地方,无非就是把我们此前所自己编写的配置清单改写为可复用格式,所谓的可复用格式就是指的是我把整个可配置清单写完以后他只能作为特定的部署,比如我们用某一特定的镜像文件某一特定的deployment控制器或其它控制器将其部署完以后想去部署别的就得回过头重新去修改这个配置文件或者我们去重新制作一个新版本的配置文件才能使得我们配置被复用,而helm的chart引入了一种机制,他能把我们此前定义的配置清单中的特定的内容配置为模板文件中的模板内容。只不过在这个模板中他们所能调用的属性或变量值可以来自于不同的位置,有一些是我们helm内建的,来自于chart,或者是来自于部署时的release,也有一些属性值需要由用户通过所谓的值文件来额外进行提供。

2、究竟一个chart是由哪些内容组成呢?我们可以在官方文档中看到其结构(https://docs.helm.sh)
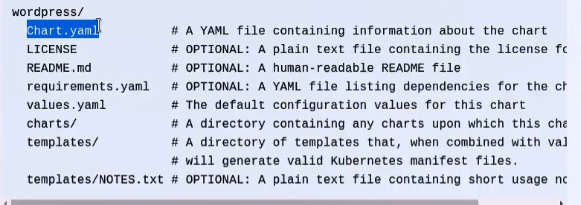
a、Chart.yaml:用来做整个模块初始化,用来对外表明自己的元数据信息。他是一个yaml格式的文件,里面记录的是当前chart的版本,名称,维护者,内部的应用程序版本等元数据信息。
b、LICENSE:许可证
c、README.md:markdown 格式的文件,项目说明
d、requirements.yaml:在一个分层架构或在一个组织复杂的微服务结构中我们部署的应用和应用直接很有可能是存在依赖关系的,比如nmt架构中m应该是被t所依赖的,t应该是被n所依赖的,如果这三个应用我们分别定义成独立的chart这每个chart都应该去单独部署,我们应该先去部署mysql的chart然后是tomcat的chart而不是nginx的chart,类似于这种格式部署,这就是依赖关系,因此这个文件就是让我们去定义当前chart依赖于谁。
e、templates/:目录,我们所有的模板文件,即我们此前经常去写的所谓的配置清单,大家知道我们部署一个mysql有可能会用到好几个清单,第一个清单中定义我们mysql的deployment或stateful这样的控制器,另外一个清单中我们定义的应该是service,并且我们有可能还会用到pvc等其它资源清单。这些资源清单为了便于被复用他们被改造为能通过属性值或字段值都被改造为能通过模板编程语言基于模板编程语言基于模板编程语言执行的结果生成配置信息并自动替换在代码所在处。这个就是我们的templates目录。但是我们要想自己去写templates要求我们对Go或json模板语法能有充分的了解才能更加熟练的去改造我们此前所使用的配置清单。
f、values.yaml:模板有了那么模板中的代码尤其是变量引用的值来自于何处呢?我们说过有三种位置。第一,可以是当前chart自身的信息,比如chart的名称,chart的版本等等。第二、可以把chart运行为release时的release的信息。第三、也可以是来自于用户自定义的信息。有些值用户为了避免用户在部署时不用必须得给每一个自定义变量都得赋值那么我们可以使用或者我们chart要求其开发人员必须提供一个默认的配置文件以提供其自定义属性值的默认值。即values.yaml,这个文件主要就是为templates/中的自定义变量的引用设置默认值的。
g、charts/:其作用和requirements.yaml很相像,他里面放置的是每一个被当前chart所依赖到的其它chart的打包格式的文件,一般都是tgz格式的,他们被放置在charts/目录中,要注意的是只要把一个tgz格式的打包好的chart文件放在这个目录下那么他将始终被依赖。也就是说无论有没有requirements.yaml文件他都是能自动定义依赖关系的。这两项很多时候我们不必要同时提供。但是我们只是在第一个文件中提供有一个好处就是当他分析的时候就会自动去下载被依赖的包放在里面,如果你手动放进来就不必要定义这个文件了。这就是我们chart的组织结构和他的文件路径组织关系。
h、事实上如果我们自己想自定义一个chart他也有非常简单的实现方式,我们不必要非得每一个文件都得重头去创建,helm有一命令能自动帮我们生成基础目录结构,甚至是能够在目录结构中帮我们生成一个基础的框架的模板文件,值文件等信息。我只需要在他们的基础上略加修改就能够完成我们的目标了。
二、chart文件格式
1、接下来我们说一说Chart.yaml这个文件的基本语法格式,这个文件其实也会被自动生成,生成以后里面要求必须要具备的字段也会被自动生成有如下字段
a、apiVersion:用来标识当前helm 的Chart所属的helm的api的版本,永远都是v1就行
b、name:chart的名称,要与chart的目录名保持一致
c、version:版本格式定义规范
d、kubeVersion:表示我们对应的chart要依赖于至少运行在哪个版本及以上版本的kubernetes的版本之上
e、description:描述信息
...
2、接下来说一说requirements.yaml格式
a、dependencies:引入一个列表,每一个列表都是一个对象,每一个对象都是定义一个被依赖到的chart,指明chart名称,chart版本,或chart所在的仓库的路径,所以我们自己在把当前的chart打包时分析这个文件的文件格式把每一个所依赖的chart从指定的仓库中下载至本地,而后再完成打包。其实我们也可以通过模板文件去定义一些条件式的依赖关系。比如你启用一个功能那么这个包可能就要依赖他,没有启动这个功能这个包就不会被依赖。

b、我们可以通过helm dep 这个命令来执行分析依赖关系。他能够分析这个文件去了解依赖关系,并且下载相应的被依赖的chart到charts/目录中。因此我们以后部署一个应用把所依赖到的应用都定义在一个包中就能在打包后一个应用被执行时把被依赖的包也自动安装完成。所以我们使用requirements.yaml这个文件去维护依赖关系是比较易用的。

c、事实上我们如果自行知道依赖关系把相应的chart直接下载好以后扔到chart目录中他也是可用的,另外有些chart被依赖时他有可能会通过不同的名称被依赖,因此chart定义依赖关系时也可以使用别名定义。
3、如果有必要的话我们有可能需要自己去开发自己需要的模板文件,并为模板文件中的每一个自定义属性赋予默认值。那么我们要怎么去管理这些文件呢?接下来就说到templetes和values
4、如果我们想要自定义一个chart我们可以使用helm create 命令,创建后会自动帮你生成一个目录
[root@k8smaster helm]# helm create myapp Creating myapp [root@k8smaster helm]# tree myapp/ myapp/ ├── charts ├── Chart.yaml ├── templates │?? ├── deployment.yaml │?? ├── _helpers.tpl │?? ├── ingress.yaml │?? ├── NOTES.txt │?? └── service.yaml └── values.yaml 2 directories, 7 files
a、首先我们查看Chart.yaml并修改
[root@k8smaster myapp]# cat Chart.yaml apiVersion: v1 appVersion: "1.0" description: A Helm chart for Kubernetes name: myapp version: 0.1.0 [root@k8smaster myapp]# vim Chart.yaml [root@k8smaster myapp]# cat Chart.yaml apiVersion: v1 appVersion: "1.0" description: A Helm chart for Kubernetes myapp chart name: myapp version: 0.0.1 maintainer: - name: wohaoshuai email: wohaoshuai@qq.com url: http://www.wohaoshuai.com/
b、我们查看templates下deployment.yaml文件
[root@k8smaster templates]# cat deployment.yaml apiVersion: apps/v1beta2 kind: Deployment metadata: name: {{ template "myapp.fullname" . }} labels: app: {{ template "myapp.name" . }} chart: {{ template "myapp.chart" . }} release: {{ .Release.Name }} heritage: {{ .Release.Service }} spec: replicas: {{ .Values.replicaCount }} selector: matchLabels: app: {{ template "myapp.name" . }} release: {{ .Release.Name }} template: metadata: labels: app: {{ template "myapp.name" . }} release: {{ .Release.Name }} spec: containers: - name: {{ .Chart.Name }} image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}" imagePullPolicy: {{ .Values.image.pullPolicy }} ports: - name: http containerPort: 80 protocol: TCP livenessProbe: httpGet: path: / port: http readinessProbe: httpGet: path: / port: http resources: {{ toYaml .Values.resources | indent 12 }} {{- with .Values.nodeSelector }} nodeSelector: {{ toYaml . | indent 8 }} {{- end }} {{- with .Values.affinity }} affinity: {{ toYaml . | indent 8 }} {{- end }} {{- with .Values.tolerations }} tolerations: {{ toYaml . | indent 8 }} {{- end }}
c、我们查看templates下service.yaml和ingress.yaml文件
apiVersion: v1 kind: Service metadata: name: {{ template "myapp.fullname" . }} labels: app: {{ template "myapp.name" . }} chart: {{ template "myapp.chart" . }} release: {{ .Release.Name }} heritage: {{ .Release.Service }} spec: type: {{ .Values.service.type }} ports: - port: {{ .Values.service.port }} targetPort: http protocol: TCP name: http selector: app: {{ template "myapp.name" . }} release: {{ .Release.Name }}
{{- if .Values.ingress.enabled -}}
{{- $fullName := include "myapp.fullname" . -}}
{{- $ingressPath := .Values.ingress.path -}}
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: {{ $fullName }}
labels:
app: {{ template "myapp.name" . }}
chart: {{ template "myapp.chart" . }}
release: {{ .Release.Name }}
heritage: {{ .Release.Service }}
{{- with .Values.ingress.annotations }}
annotations:
{{ toYaml . | indent 4 }}
{{- end }}
spec:
{{- if .Values.ingress.tls }}
tls:
{{- range .Values.ingress.tls }}
- hosts:
{{- range .hosts }}
- {{ . }}
{{- end }}
secretName: {{ .secretName }}
{{- end }}
{{- end }}
rules:
{{- range .Values.ingress.hosts }}
- host: {{ . }}
http:
paths:
- path: {{ $ingressPath }}
backend:
serviceName: {{ $fullName }}
servicePort: http
{{- end }}
{{- end }}
d、上述所有变量值都是在myapp路径下values.yaml文件中定义的
[root@k8smaster helm]# cat myapp/values.yaml |grep -vE ".*#|^$" image: tag: v1 pullPolicy: IfNotPresent service: type: ClusterIP port: 80 ingress: enabled: false path: / hosts: - chart-example.local tls: [] limits: cpu: 100m memory: 128Mi requests: cpu: 100m memory: 128Mi nodeSelector: {} tolerations: [] affinity: {}
e、接下来做语法检查
[root@k8smaster helm]# helm lint myapp/ ==> Linting myapp/ [INFO] Chart.yaml: icon is recommended 1 chart(s) linted, no failures
f、接下来就可以给chart打包,打包后就可以上传到仓库上分享给其他人使用了。
[root@k8smaster helm]# helm package myapp/ && ls Successfully packaged chart and saved it to: /root/manifests/helm/myapp-0.0.1.tgz myapp myapp-0.0.1.tgz redis redis-9.1.7.tgz tiller-rbac.yaml values.yaml
5、现在对应的这个chart我们能不能使用呢?对helm来讲他去搜索chart时将搜索你所指定的各种repo,默认stable,local默认也是存在的,他会去找http://127.0.0.1:8879/charts,如果该端口没有监听那么我们在指定目录下去运行就可以了 ,使用hem serve命令即可,这是一个简单的由helm自带的web服务器,用来提供仓库服务,其实任何nginx或者http一样的web服务器都可以作为仓库服务器使用。而且这里他和我们此前所使用的github,dockerhub不一样的地方在于他不允许我们直接使用命令行上传我们的chart文件。你要上传chart要使用其他方式,意味着他的外部服务是只读的,只允许客户端获取而不允许匿名用户或普通用户使用http协议上传其它资源。
a、启动服务并查看
[root@k8smaster helm]# helm serve Regenerating index. This may take a moment. Now serving you on 127.0.0.1:8879
[root@k8smaster ~]# helm search myapp NAME CHART VERSION APP VERSION DESCRIPTION local/myapp 0.0.1 1.0 A Helm chart for Kubernetes myapp chart
b、在我们helm应用中在我们templates目录下NOTES.txt文件一定要写清楚到底要怎么向客户端提供帮助信息。
c、接下来我们来部署这个myapp
[root@k8smaster helm]# helm install --name myapp3 local/myapp NAME: myapp3 LAST DEPLOYED: Sat Sep 14 09:18:06 2019 NAMESPACE: default STATUS: DEPLOYED RESOURCES: ==> v1/Pod(related) NAME READY STATUS RESTARTS AGE myapp3-7cf7947c98-28cq8 0/1 ContainerCreating 0 1s myapp3-7cf7947c98-r8b9c 0/1 Pending 0 1s ==> v1/Service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE myapp3 ClusterIP 10.107.112.115 <none> 80/TCP 1s ==> v1beta2/Deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE myapp3 2 2 2 0 1s NOTES: 1. Get the application URL by running these commands: export POD_NAME=$(kubectl get pods --namespace default -l "app=myapp,release=myapp3" -o jsonpath="{.items[0].metadata.name}") echo "Visit http://127.0.0.1:8080 to use your application" kubectl port-forward $POD_NAME 8080:80 [root@k8smaster helm]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-6985749785-rlk8g 1/1 Running 1 12d myapp3-7cf7947c98-28cq8 1/1 Running 0 15s myapp3-7cf7947c98-r8b9c 1/1 Running 0 15s
d、获取当前release状态
[root@k8smaster helm]# helm status myapp3 LAST DEPLOYED: Sat Sep 14 09:18:06 2019 NAMESPACE: default STATUS: DEPLOYED RESOURCES: ==> v1/Service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE myapp3 ClusterIP 10.107.112.115 <none> 80/TCP 2m ==> v1beta2/Deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE myapp3 2 2 2 2 2m ==> v1/Pod(related) NAME READY STATUS RESTARTS AGE myapp3-7cf7947c98-28cq8 1/1 Running 0 2m myapp3-7cf7947c98-r8b9c 1/1 Running 0 2m NOTES: 1. Get the application URL by running these commands: export POD_NAME=$(kubectl get pods --namespace default -l "app=myapp,release=myapp3" -o jsonpath="{.items[0].metadata.name}") echo "Visit http://127.0.0.1:8080 to use your application" kubectl port-forward $POD_NAME 8080:80
e、清楚所有信息
[root@k8smaster helm]# helm delete --purge myapp3 release "myapp3" deleted
6、接下来去说一说如何去使用系统上在官方的chart仓库中提供其它的chart。我们可以在官方网站上https://hub.kubeapps.com 中搜索elastic关键词可以看到会有很多种版本的仓库。可以将其添加进来,我们可以通过helm repo add来添加
a、添加 helm repo add http://storage.googleapis.com/kubernetes-charts-incubator
三、EFK
1、EFK是ELK的另一种形式。
a、E:elasticsearch,他是一个标准搜索引擎
b、L:logstash:主要是用于帮助我们生成日志的节点负责收集节点上的日志并转换格式后注入到elasticsearch中去,注入进去的格式应该是json格式的。他能扮演两重功用,在收集日志的节点上能扮演成agent收集日志的代理程序,所以在k8s上如果每一个节点都要部署一个并且部署一个就够了我们可以使用控制器daemonset,生成日志以后应该发送给logstash server,统一整理之后再发送给elasticsearch中去,一般情况下es应该是一个集群,并且logstash agent和server端中间可以加一个消息队列。logstash server扮演了一个非常重要的作用可以把所有的节点所发来的日志做统一的格式转换等额外操作以后把日志信息注入到我们的es集群中。所以logstash server有很重要的作用,我们也讲过logstash如果去做收集日志的agent这个功能来讲就太重量级了,所以我们说过他还可以使用filebeat来替换。所以可以做成ELFK或ELLK。
2、我们接下来说的EFK可不是上面所说的F,用于在节点上工作能够收集日志信息的组件不光有logstash或filebeat,还有Fluentd,他是一个组织研发的,在k8s集群上运行了很多节点每一个也需要收集日志,并且还有pod,每一个pod中有可能不止一个容器,每一个容器都会生成应用程序日志的,我想去了解这些日志信息,如果我们没有统一的日志收集平台我们管理日志将会变成什么情形?我们突然之间发现我们某一个pod中的容器崩了,我想知道容器中的日志是什么我们此时的做法是什么呢?可以使用kubectl logs 连入容器内部。所以我们需要实时获取每一个pod中的每一个容器中的单独的获取方式不是一个理想的解决方案。我们使用kubectl logs 尽管能获取日志但是对于死掉的容器这种做法都是不可行的因此我们非常有必要应该把pod中的容器包括我们的节点运行中所生成的日志提前收集到一个专门的日志存储中,以免在节点丢失pod down掉或容器down掉时我们想分析日志你还得想办法去把其硬盘扯下来找日志,这个很多时候几乎是不可能的。所以我们说在k8s上复杂的云环境中几乎必须要用到一个日志收集平台以便于能够提供一个统一的接口让我们去查看和分析日志,因此从这个角度来讲日志统一收集存储平台是k8s之上除标准的四大附件之外的另外一个算不上附件的非常重要的基础组件。所以我们说一个完整意义上的k8s集群我们应该部署像 kube-dns(coredns),ingress-controller,heapster(metrics-server),dashboard这四大附件,EFK是一个日志统一收集工具不是基础附件但是基本算是一个完整意义上的k8s必须提供的组件
3、因此接下来我们来部署这个组件。在k8s上收集日志的风格有两种,第一种我们可以外置收集日志,第二种就是在每一个Pod上都能生成日志,每一个pod单独发送日志给日志存储,但是这个时候我们需要在每一个pod内额外部署一个seidcar容器,因为一个容器中只运行一个应用程序,你的主容器中运行redis后他就不可能再运行一个日志收集工具和发送工具了,所以这个时候我们只能在Pod中同时运行两个容器,主容器提供服务,附容器用来收集主容器日志并发送给日志统一收集平台
a、但这样一来,万一我们部署一万个Pod那么就要运行一万个日志收集容器,虽然我们一个pod包含两个容器,pod是我们最小粒度单位,但真正意义上来讲两个容器在节点上是需要同时运行的,这样一来就悲剧了。我们也可以在一个容器上运行两个进程但是我们一般不建议这样干,所以最常用的方式我们一般都是基于节点直接部署一个统一的插件,这个节点上的所有容器包括节点自身的日志都由这个插件统一收集以后统一发往日志收集平台,那么这个日志收集平台是应该部署在k8s之上还是之外呢?假如我们使用es存储日志信息,那么es应该运行在集群之上还是集群之外呢?其实都可以。单独部署一套和k8s没关系的集群也可以。因此只有确保k8s自身不会统一所有都出问题时这种情况下才应该把他部署在k8s之上,我们可以把很多应用和k8s这样的应用组合起来统一工作的,这没有任何问题。
b、在每一个节点上部署一个fluentd,在fluentd基于节点的ip工作向节点之外的没有运行在k8s上的es集群发日志也可以,但是以后我们通过fluentd来作为日志收集器,一般来讲在k8s上用的时候可以用filebeat,只不过用fluentd的居多。假如我们要使用flu的话我们对于flu来说他是部署为守护进程呢还是部署为k8s之上的pod?
c、首先flu本身是通过我们节点的本地文件系统/var/log来获取日志的,其实我们节点上的每一个容器的日志都被输出到 /var/log/containers/下的,也就意味着我们通过/var/log目录可以获取到所有日志的。都是节点级别的目录,说白了就是要节点的文件系统,因此我们把flu运行为节点的守护进程也是理所当然的,但是我们说过如果flu在节点上挂了怎么办呢?因此如果把flu本身也运行在k8s上运行为daemonset并使用hostpath方式直接把节点的/var/log关联到相关节点的pod上去就能让pod直接访问节点的某特定路径下的文件中的内容了。因此flu可以部署为daemonset托管在k8s上。flu负责收集日志发送给es,es中的内容让kibana来展示,kibana我们也可以运行为容器。并且它是无状态的因此用deployment都可以控制。
d、在 elk中我们通常使用logstash或filebeat去收集节点日志并同一发给logstash server,由logstash server将格式转换以后再发给es,现在我们提到flu时logstash就没了么?其实为了让我们的es能运行在k8s之上,es官方就直接制作好了相关镜像打包好了相关文件让其直接能运行在我们k8s上,这个镜像文件一般而言他可以运行三种格式,首先他把es拆为两部分,由master和date两部分组成,master节点负责处理轻量化的查询请求,data节点负责重量级别的比如索引构建等请求,所以他把两重任务给隔离开来,master负责接入,data负责处理。因此一般而言我们的es每一个节点就是一个完整的节点,他应该拥有既能负责查询又能负责构建索引的功能,现在我们把他分成两层来分开实现,而后这也就意味着master是客户端接入的唯一入口了。如果master down了data也就没法工作了。因此一般而言我们有三个节点就可以,主要的目的是为了做冗余,万一节点宕机了我们服务还能持续进行,当然如果考虑到我们访问量较大时这三个节点不够用要横向扩展他也可以。和data互不干扰的进行扩展。考虑到都要处理数据那么他们几乎都应该使用存储卷以便于持久存储数据。
e、master就算是三个节点我们应该判定一旦出现节点之间集群发生分裂了找不着了我们至少要有两个节点才能让他处于正常运行状态,因此以后就不是我们弄三个节点组成es集群了而是我们做两个集群,一个是接入的一个是处理数据的。即master集群和data集群。除此之外他还需要有client集群即客户端,他其实不是真正的client而叫上载,即摄入节点。他帮忙收集任何的日志收集工具由其同一生成特定格式以后再发给我们的master节点,你也可以把它理解为logstash server。
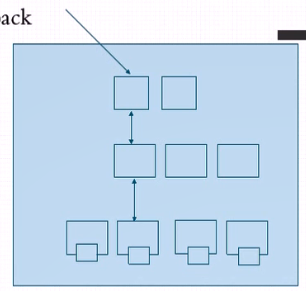
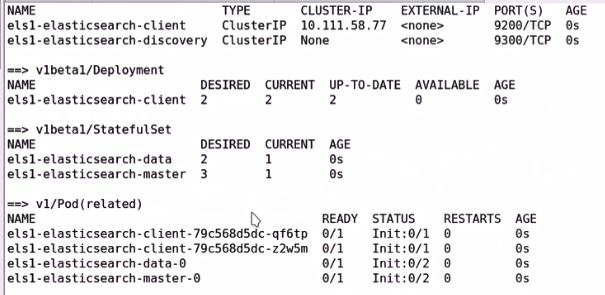
f、考虑到在生产环境中我们使用妥当的方式去部署,我们如果自己去部署的话可能一个Logstash或部署多个flu也就完事了,但使用helm部署时他们开发的这个应用尽可能考虑是在生产环境中使用的,所以他们部署非常完整和完善,也就意味着我们通过helm获取到的es他就是按照这种格式来组织和部署的。因此有几个master和data节点就需要几个存储卷,因为es的master或data都是有状态的。因为每一个节点只负责一部分任务,存储数据也支持一部分,他不是复制状态的而是分布式的,同样的data也是分布式的,这么一来也就意味着他的master和后端的data都是有状态的,因此他们的存储卷每一个都是独立,一共有几个master data加起来就需要有几个 存储卷。不过考虑到此处只是测试我们就暂时关掉了。
四、部署和使用EFK
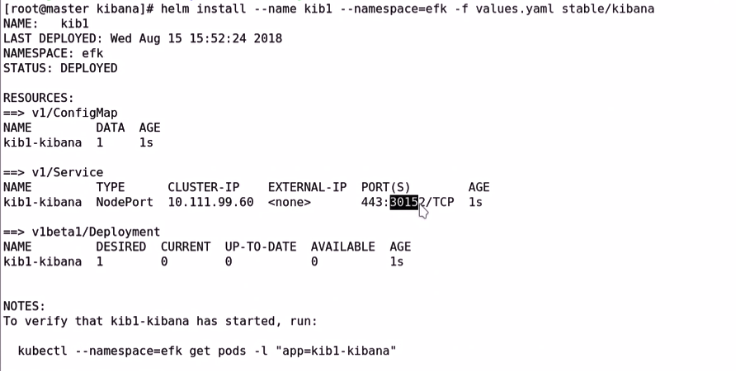
1、部署和使用es

2、部署fluentd

3、部署kibana