
Kubernetes 学习23 kubernetes资源指标API及自定义指标API
一、概述
1、上集中我们说到,官方文档提示说从k8s 1.11版本开始,将监控体系指标数据获取机制移向新一代的监控模型。也就意味着对于我们的k8s来讲现在应该有这样两种资源指标被使用。一种是资源指标,另一种是自定义指标。意思是说HeapSter提供了指标数据的收集,存储和监控的基本功能。并支持多个数据接收器。比如influxdb来存储指标数据,而后每个存储后端的代码本身都驻留在HeapSter仓库中。意思是HeapSter为了能够支持各种各样的存储后端他就不得不去适配驱动每一个存储后端,这其中包含我们刚刚说的inflxdb,更悲惨的是这每一个适配器都是由第三方组织研发的,第三方万一哪一天没兴趣了也就不维护了。以至于HeapSter中为了适配很多的存储后端,整合了近十几个后端存储的适配器。有些适配器自从整合至HeapSter以后再也没有修改过。但是HeapSter为此却不得不付出代码量很庞大的代价。所以这就意味着HeapSter的设计架构不适用于这种所谓云原生的监控体系。因为他会假设数据存储是一个原始的时间序列存储数据库。而且每个接收器都作为HeapSter核心代码的一部分。使得我们整个监控结构定义和使用起来越来越麻烦。而且维护起来代价也越来越大。所以这样子他开始去支持新一代的监控架构。这就是我们尝试着废弃HeapSter的原因。
2、当然k8s本身如此强大,一个核心原因在于他的灵活扩展性,他的很多功能使用addon来实现。所以也就意味着他们的替换不是一件难事。而且现在的版本中的k8s还支持开发人员自己轻松定义自己的API服务器来扩展核心API服务。什么意思呢?如果用户觉得我们系统内置的这些资源类型不够用,比如svc,pod等等不能解决我们的问题的时候我们要把特殊应用程序的特殊使用方式的维护技巧维护步骤柔和到我们对应的资源中去。那么我们应该怎么去扩展自己的k8s系统所支持的资源类型呢?一般来说我们有三种方式:
a、直接使用CRD(自制资源定义)
b、我们自己去修改代码,开发一个新的apiserver。里面提供其它API并通过所谓的API聚合器和自己的k8s的ApiServer二者建立起一个聚合关系把他们聚合在一处去使用。
c、如果有需要的话直接修改k8s的源代码去新增一些资源定义。
3、刚刚说过有一种方式就是允许由开发人员轻松使用自己的API服务器来扩展附加到已有的k8s之上来实现聚合进更多的API功能来。比如我们k8s自己有个APIserver,他的apiserver支持哪些API组件应该都是事先定义好的。如果我们需要的api这里面没有怎么办呢?你可以自己去开发一个apiserver单独运行,甚至还可以托管在k8s上运行,然后在k8s自己的服务器和你的apiserver前端加一个代理服务,而后所有的对api的请求就直接对这个代理服务请求,它既能获取到k8s自己已有的api也能使用你定义的api,这种就叫聚合器。k8s从1.8开始引入了资源指标API,我们把资源的内容也当做api接口中的数据直接进行获取而不像早期的HeapSter中是靠HeapSter来提供,和apiserver没什么关系。有单独自己的获取路径,意思是传统时代HeapSter时代我们大多数功能都是通过ApiServer来获取的,但有一个功能不是,我们要想获取资源指标数据得专门部署一个addon,即HeapSter,因此我们系统上的很多组件如果获取资源指标得到你的addon上来,这个addon没部署就没用。或者其它指标数据的获取都应该通过apiserver来获取。有两路方式来获取资源。

4、那我们能不能干脆把资源指标中的这些数据也直接整合进apiserver呢?意思是任何客户端通过apiserver能够获取到他的所有数据,包括指标。即能够监控到每一个pod到底使用了多少cpu多少内存,此前这些apiserver是不负责的,所以从1.8以后他们就引入了资源指标api,就用api这种接口方式去输出每一个资源对象的指标。另外,k8s从1.6开始引入自定义指标。这个功能挺早了。其实我们有很多系统级的组件都是依赖于这些指标api的功能的。比如我们的kubectl top,如果没有资源指标的api接口或者有一个专门的资源指标供给他是没办法运行的。另外,像HPA(水平pod自动伸缩器),这些也是需要根据获取当前pod的cpu比如已经到达80%,说明负载已经很高了,这个时候就给你加一个或者加几个pod。如果我们pod的cpu使用率一直低于%5,我们可以删几个,这样腾出来一些资源和空间。让其它pod所使用。大家知道你的pod无论运行与否他只要有request,只要被调度到这个节点上这个节点上的资源就要预留给pod使用。pod一直在这儿放着又不用又不运行就很可惜,我们可以把它移除,多腾出一些资源空间以给其它Pod运行和使用。因此这些组件都是要依赖于资源指标才能工作的。早期他们都是要依赖于HeapSter来实现。
5、早期的k8s之上你必须部署了HeapSter才能使用top命令,另外才能使用HPA,就是刚刚所说的能水平自动伸缩你的Depolyment之下的pod的应用规模。但是我们说过这些指标之前只能通过HeapSter来提供,而且他所能提供的指标还是有限的。尤其其伸缩只能根据cpu的用量来伸缩。假如我想根据io,内存等其它指标伸缩在这个时代借助HeapSter还是做不到的。所以他们期望能够根据越来越多的指标进行伸缩。比如cpu利用率很低但是这个pod的并发访问量很大了。这个时候我们也应该加些pod但是他不会根据这个指标进行添加,仅仅只是根据cpu的使用量。因此仅根据cpu不足以反馈出我们应用规模所需要伸缩的所有场景,他只能反馈出来一个很小很小的场景。这个时候我们就需要引入更多的能够支撑HPA工作能力的资源指标。早期HeapSter不支持。就是在这种情况下我们就有了新的资源指标api的模型以及我们需要整合自定义指标的模型。
二、新一代的指标
1、资源指标:新一代的资源指标API的获取的主要方式是靠metrics-server来实现的。他主要是定义资源指标的。
2、自定义指标:另外用户也允许开始去使用很多的自定义指标。比如说有一些监控系统,比如普罗米修斯,他已经被直接收录进CNCF。他已经是CNCF旗下的一个直接的项目。也就是云原生计算基金会下第一个是k8s,第二个就是普罗米修斯了。可以看出其强大的江湖地位。普罗米修斯可以收集各种维度的指标。比如他不但能收集你的cpu利用率还能收集你的网络连接的数量,网络报文的速率,内存,进程的新建和回收的速率等等。而这个指标早期k8s是不支持的。所以我们需要把普罗米修斯所能够监控采集到的很多指标数据直接整合进k8s中,让k8s能用,能拿来作为HPA判断是否需要伸缩pod规模的一个基本标准。因此后来自定义指标就通过prometheus来实现。他自己即作为一个监控系统使用也作为一些特殊的资源指标的提供者来提供,不过这个指标他不是内建的标准核心指标。我们把它称为自定义指标。但是如果prometheus想要把其监控的采集数据转成指标格式需要一个特殊的组件来实现。叫k8s-prometheus-adapter,这是早期时候的版本。
三、新一代监控架构:我们目前来讲新一代的k8s的监控系统的架构主要有两部分组成
1、核心指标流水线:由kubelet、metrics-server以及由API server提供的api组成;这里面主要是提供最核心的指标的,他主要是让各位通过k8s自身的组件去了解内部组件和核心使用程序的指标;目前主要包含cpu的累积使用率和内存的实时使用率,以及Pod的资源占用率及容器的磁盘占用率。除了这些指标有可能还需要去评估网络连接数量,可用网络带宽之类的。这些度量标准一般而言就需要第三方监控组件使用了,因为核心指标是不适合委托给第三方的,因为这些核心指标将会被我们系统中的很多组件使用,kubectl top,dashboard等等,因此我们称之为核心指标。
2、监控流水线:简单来讲就是我们在系统之上部署一个监控系统,监控系统收集各种各样监控系统本身所感兴趣的指标数据。所以他的功能是用于从系统收集各种指标数据并提供终端用户、存储系统以及HPA。我们也称之为非核心指标。但他通常包含核心指标。即包含上面所描述的指标。除此之外又包含很多非核心指标。
3、但是既然不是核心指标那么他就没法被k8s所解释,即k8s不理解他是什么东西。比如prometheus采集的数据是prometheus语境中保存的,prometheus可以理解他没问题,但是k8s理解不了,这就是为什么需要一个k8s-prometheus-adapter的原因,他需要把prometheus采集到的数据转换成k8s可以理解的格式。
4、另外,k8s自身肯定不会提供这样的组件。通常就算是要用也会使用第三方的。如果用户自己不打算使用他你甚至可以不用部署。但是核心指标流水线是必须要部署的。核心指标流水线早期是由HeapSter提供的,而他在1.11上开始要废弃了。目前来讲替代他的就是metrics-server,它是由metrics-server来聚合提供的。他是一个第三方开发的API server服务器,这个服务器是用来服务资源指标服务API,不是服务k8s的API,而是仅仅用于服务于我们cpu利用率内存使用率等这些对象的,但是他本身又不是k8s的组成部分,他是托管运行在k8s之上的一个pod,所以为了能够让用户可以使用metrics-server中的API在k8s上可以无缝的使用,因此我们不得不在新一代的结构中这么去组织他们。第一,k8s的API server正常运行。第二,又metrics-server提供另外一组API,我们需要把两组API合并成一个使用,因此我们需要在两个之间加一个代理,这个代理我们称之为聚合器。相当于把来自多个不同地方的api聚合成一个来使用,不光能聚合metrics-server,还能聚合很多其它的第三方或者用户自定义的api server,即kube-aggregator(聚合器),而这个聚合器所提供的资源指标我们将通过/apis/metrics.k8s.io/v1beta1的版本来获取。说白了就是默认是没有这个对应的群组的,他是由metrics-server提供的。
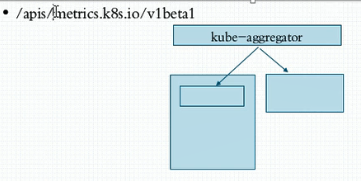
5、另外HeapSter被废了,因此metrics-server已经成为了k8s多个核心组件的先决条件,没有他就没法运行了,比如kubectl top,HPA等等,所以我们现在就不得不去部署我们的metrics-server以便能提供这些资源指标数据。
四、部署metrics-server
1、首先我们卸载前面部署的HeapSter各个组件。
2、接下来我们去部署metrics-server,对应链接为https://github.com/kubernetes/kubernetes/tree/release-1.11/cluster/addons/metrics-server。找到v1.11版本下载即可
[root@k8smaster metrics-server]# pwd && ls /root/manifests/metrics/metrics-server auth-delegator.yaml auth-reader.yaml metrics-apiservice.yaml metrics-server-deployment.yaml metrics-server-service.yaml resource-reader.yaml [root@k8smaster metrics-server]# kubectl apply -f . clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator configured rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader unchanged apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io configured serviceaccount/metrics-server unchanged configmap/metrics-server-config unchanged deployment.extensions/metrics-server-v0.2.1 unchanged service/metrics-server unchanged clusterrole.rbac.authorization.k8s.io/system:metrics-server configured clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server configured
可以看到已经有metrics的api群组了,这个群组其实不是k8s的api提供的,而是由我们刚刚提供的metrics-server提供的。
[root@k8smaster metrics-server]# kubectl get pods -n kube-system |grep me metrics-server-v0.2.1-fd596d746-44k9k 2/2 Running 0 1m [root@k8smaster metrics-server]# kubectl api-versions |grep me metrics.k8s.io/v1beta1
3、我们确认metrics-server已经部署而且对应的pod已经正常运行起来以后接下来就可以获取他的监控的数据。如果他已经收集到数据了我们就可以看看有没有了,可以使用curl命令直接获取
a、首先我们使用kubectl proxy打开一个反代接口
[root@k8smaster metrics-server]# kubectl proxy --port=8080 Starting to serve on 127.0.0.1:8080
b、使用curl来访问api中数据。可以看到我们有node和pod的数据。
[root@k8smaster metrics-server]# curl http://localhost:8080/apis/metrics.k8s.io/v1beta1 { "kind": "APIResourceList", "apiVersion": "v1", "groupVersion": "metrics.k8s.io/v1beta1", "resources": [ { "name": "nodes", "singularName": "", "namespaced": false, "kind": "NodeMetrics", "verbs": [ "get", "list" ] }, { "name": "pods", "singularName": "", "namespaced": true, "kind": "PodMetrics", "verbs": [ "get", "list" ] } ] }
查看node的数据或pod的数据
[root@k8smaster metrics-server]# curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/nodes { "kind": "NodeMetricsList", "apiVersion": "metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/metrics.k8s.io/v1beta1/nodes" }, "items": [] }[root@k8smaster metrics-server]# curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/pods { "kind": "PodMetricsList", "apiVersion": "metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/metrics.k8s.io/v1beta1/pods" }, "items": [] }
中间会有一些小问题,参照https://www.cnblogs.com/dingbin/p/9728458.html这位大佬博客即可。
c、此时我们的kubectl top 即可使用
[root@k8smaster ~]# kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes)(内存已用空间) MEMORY%(内存已用空间所占百分比) k8smaster 648m 16% 1166Mi 67% k8snode1 145m 7% 888Mi 51% k8snode2 114m 5% 782Mi 45% [root@k8smaster ~]# kubectl top pods NAME CPU(cores) MEMORY(bytes) myapp-deploy-5d9c6985f5-46rtw 0m 3Mi myapp-deploy-5d9c6985f5-7nhwq 0m 2Mi myapp-deploy-5d9c6985f5-p8gsg 0m 2Mi
五、prometheus
1、此时核心指标我们通过metrics-server已经可以获取到了,但是自定义指标,尤其是除了节点和pod cpu,内存之外的其它指标我们依然无法获取,还需要借助于prometheus,但是prometheus提供的资源指标数据是不能被k8s解析的,要想在k8s上使用 prometheus我们还得额外去加一个k8s的关于prometheus的组件。
2、简单来讲我们prometheus自己就是一个监控系统,他也通过自己的监控代理插件就像我们的zabbix在每一个组件上都要部署一个zabbix-agent,prometheus也是类似的监控软件,所以他自己有一个prometheus server,我们姑且称之为Prometheus,这个server端不停的通过数据采集的方式从每一个被监控主机那里来获取数据,这个被监控主机如果是一个正常的节点而不是Pod那么我们就应该在这个节点上部署一个专门的软件,这个软件就是prometheus的agent,他们通常称为node_exporter,他是一个能够让prometheus server通过它来采集指标数据的一个组件,但这个组件只是用来去暴露输出采集当前节点的节点级指标数据的,如果要采集其它的数据,比如mysql的,你还需要去部署mysql的exporter,他有很多重量级服务的专用exporter。我们要去采集pod的话,pod在k8s上本身就有获取采集数据的接口api。也不一定非要去额外部署,更何况节点的每一个容器的日志都在节点上。在/var/log/containers/中。因此,简单来讲我们prometheus就是通过一个专门的metrics-url到各pod获取数据的。把它部署到k8s上之后能到每一个pod上直接采集你定义需要采集的各种各样的指标数据。采集完以后我们用户怎么看呢?prometheus提供了一个非常强大的接口叫 PromQL,即prometheus的查询语句,他支持非常非常强大的restful接口的查询条件表达式。能通过PromQL查询他所监控到的各种指标数据,当然这个指标数据不能被api server所解析,因此如果期望能够通过k8s的apiserver像在api中获取数据一样来获取指标数据,而且是prometheus所采集的指标数据。那么我们必须把这个PromQL所实现的功能数据格式转为k8s的api的查询接口的格式。所以假如上面这个是我们k8s的apiserver,甚至是我们自定义的apiserver,即Custom Metrics API,即我们自定义指标API,而不再是我们刚刚所提到的核心指标API了。那怎么能把它转为自定义指标API以后能通过这些指标接口获取到我们监控数据呢?我需要在下面再嵌套进来一个组件,这个组件我们称之为kube-state-metrics,转换后还不能通过apiserver获取,获取需要k8s-prometheus-adpater组件,这是由第三方人员研发的,说不定哪天又用不成了。即这个组件能够用PromQL的语句完成从Prometheus这里查询到一些指标数据,并把它转为k8s的API上的指标格式的数据,并支持能通过APIserver能获取。只需要把Custom Metrics API聚合到我们的APIserver上去,正常就能通过我们的api-versions看到我们的api了。

3、所以我们要想部署这个功能首先我们需要部署Prometheus,然后还需要配置prometueus能从pod上抓取到数据,还得在当前系统上部署一个k8s-prometheus-adpater这个pod,接着这个pod输出以后我们还要把它整合到我们对应的apiserver上去。
六、部署prometheus
1、部署步骤大体上包含了。第一,最好使用一个单独的名称空间,当然也可以使用kube-system。不过建议使用单独的名称空间去放我们的prometheus,而后在这个目录中我们去用prometheus的各种各样的配置文件。对应链接为https://github.com/kubernetes/kubernetes/tree/release-1.11/cluster/addons/prometheus。
2、部署prometheus时需要注意:
a、我们在k8s上去部署prometheus时因为其是有状态应用因此我们需要使用statefulset去控制他。如果一个副本的话到底是statefulset或deployment就不重要了。
3、为了简化过程,我们将部署的statefulset改为deployment,不然的话还要准备pv和pvc才行。因此,我们在马哥的https://github.com/iKubernetes/k8s-prom这个项目的对应路径下可以看到有相应的准备文件。我们可以将其克隆到本地。
4、首先部署名称空间
root@k8smaster k8s-prom-master]# pwd /root/manifests/metrics/k8s-prom-master [root@k8smaster k8s-prom-master]# ls k8s-prometheus-adapter kube-state-metrics namespace.yaml node_exporter podinfo prometheus README.md [root@k8smaster k8s-prom-master]# kubectl apply -f namespace.yaml namespace/prom created
5、部署node_exporter
[root@k8smaster node_exporter]# pwd /root/manifests/metrics/k8s-prom-master/node_exporter [root@k8smaster node_exporter]# ls node-exporter-ds.yaml node-exporter-svc.yaml [root@k8smaster node_exporter]# kubectl apply -f . daemonset.apps/prometheus-node-exporter created service/prometheus-node-exporter created
[root@k8smaster node_exporter]# kubectl get pods -n prom -o wide NAME READY STATUS RESTARTS AGE IP NODE prometheus-node-exporter-fd499 1/1 Running 0 5m 192.168.10.10 k8smaster prometheus-node-exporter-k547l 1/1 Running 0 5m 192.168.10.11 k8snode1 prometheus-node-exporter-mjwjf 1/1 Running 0 5m 192.168.10.12 k8snode2
6、部署prometheus,此处prometheus-deploy.yaml中定义的内存Limit为2G,因为虚拟机一共给的才2G因此不够,所以不满足调度条件,我们将限制项注释掉即可
[root@k8smaster prometheus]# pwd && ls /root/manifests/metrics/k8s-prom-master/prometheus prometheus-cfg.yaml prometheus-deploy.yaml prometheus-rbac.yaml prometheus-svc.yaml [root@k8smaster prometheus]# kubectl apply -f . configmap/prometheus-config unchanged deployment.apps/prometheus-server unchanged clusterrole.rbac.authorization.k8s.io/prometheus configured serviceaccount/prometheus unchanged clusterrolebinding.rbac.authorization.k8s.io/prometheus configured service/prometheus unchanged [root@k8smaster prometheus]# kubectl get all -n prom NAME READY STATUS RESTARTS AGE pod/prometheus-node-exporter-fd499 1/1 Running 0 1h pod/prometheus-node-exporter-k547l 1/1 Running 0 1h pod/prometheus-node-exporter-mjwjf 1/1 Running 0 1h pod/prometheus-server-7c8554cf-j6qgg 1/1 Running 0 4m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/prometheus NodePort 10.110.192.191 <none> 9090:30090/TCP 11m service/prometheus-node-exporter ClusterIP None <none> 9100/TCP 1h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/prometheus-node-exporter 3 3 3 3 3 <none> 1h NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/prometheus-server 1 1 1 1 11m NAME DESIRED CURRENT READY AGE replicaset.apps/prometheus-server-65f5d59585 0 0 0 11m replicaset.apps/prometheus-server-7c8554cf 1 1 1 4m
此时prometheus已经正常运行起来了。我们可以通过30090端口来访问。
7、部署kube-state-metrics
[root@k8smaster kube-state-metrics]# pwd && ls /root/manifests/metrics/k8s-prom-master/kube-state-metrics kube-state-metrics-deploy.yaml kube-state-metrics-rbac.yaml kube-state-metrics-svc.yaml [root@k8smaster kube-state-metrics]# kubectl apply -f . deployment.apps/kube-state-metrics unchanged serviceaccount/kube-state-metrics unchanged clusterrole.rbac.authorization.k8s.io/kube-state-metrics configured clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics configured service/kube-state-metrics unchanged [root@k8smaster kube-state-metrics]# kubectl get pods -n prom NAME READY STATUS RESTARTS AGE kube-state-metrics-58dffdf67d-l2cml 1/1 Running 0 6m prometheus-node-exporter-fd499 1/1 Running 0 2h prometheus-node-exporter-k547l 1/1 Running 0 2h prometheus-node-exporter-mjwjf 1/1 Running 0 2h prometheus-server-7c8554cf-cgldt 1/1 Running 0 37m
8、接下来我们部署k8s-prometheus-adapter,他需要基于https提供服务,因为我们整个k8s的apiserver都是基于https提供服务的。而默认情况下他是http协议的,需要给其提供证书以确保其能工作为https协议,并且这个证书还必须是此k8s服务器认可的CA签署的才行,所以这个证书只能自制。于是我们先去给其创建一个证书,而后把这个证书创建为一个secret。而后在部署k8s-prometheus-adapter的时候加载这个证书。加载这个证书的secret有一个特定的名称,我们把它放在特定的名称空间下,就可以自动加载了。cat custom-metrics-apiserver-deployment.yaml 最后一行即可看到,名称为cm-adapter-serving-certs
a、首先我们去生成一个私钥serving.key
[root@k8smaster ~]# cd /etc/kubernetes/pki/ [root@k8smaster pki]# ls apiserver.crt apiserver.key ca.crt dashboard.crt etcd front-proxy-client.crt sa.pub wohaoshuai.key apiserver-etcd-client.crt apiserver-kubelet-client.crt ca.key dashboard.csr front-proxy-ca.crt front-proxy-client.key wohaoshuai.crt apiserver-etcd-client.key apiserver-kubelet-client.key ca.srl dashboard.key front-proxy-ca.key sa.key wohaoshuai.csr [root@k8smaster pki]# (umask 077; openssl genrsa -out serving.key 2048) Generating RSA private key, 2048 bit long modulus .................+++ .......................................+++ e is 65537 (0x10001)
b、接下来我们去生成一个证书签署请求
[root@k8smaster pki]# openssl req -new -key serving.key -out serving.csr -subj "/CN=serving"
c、接下来我们给其签证
[root@k8smaster pki]# openssl x509 -req -in serving.csr -CA ./ca.crt -CAkey ./ca.key -CAcreateserial -out serving.crt -days 3650 Signature ok subject=/CN=serving Getting CA Private Key
d、接下来我们将其创建为一个secret,名称需要与custom-metrics-apiserver-deployment.yaml 中描述的一致。为cm-adapter-serving-certs.
[root@k8smaster pki]# kubectl create secret generic cm-adapter-serving-certs --from-file=serving.crt=./serving.crt --from-file=serving.key=./serving.key -n prom secret/cm-adapter-serving-certs created [root@k8smaster pki]# kubectl get secret -n prom NAME TYPE DATA AGE cm-adapter-serving-certs Opaque 2 10s default-token-j4x4m kubernetes.io/service-account-token 3 2h kube-state-metrics-token-q7pfw kubernetes.io/service-account-token 3 36m prometheus-token-9r5v4 kubernetes.io/service-account-token 3 1h
e、接下来我们就可以开始部署了。(到此为之吧,这个版本的部署我没时间去研究了)
9、部署完成以后我们可以看到在api-versions中会有一个custom.metrics.k8s.io/v1beta1,这样我们又有了很多新的api指标。通过这些新指标我们就可以创建我们的HPA了,即水平pod自动伸缩控制器。功能用起来也不麻烦。
10、接下来我们需要部署granfana,然后将数据源设置为prometheus即可。
七、HPA
1、HPA是我们k8s非常强大的一个功能,支持应用规模的自动伸缩。当我们pod中资源压力过大时他会自动修改对应的deployment中的副本值。并且是由计算结果得到相应的值。HPA至2018年9月有两个版本:
a、V1版本只支持核心指标进行定义。核心指标只有cpu和内存,但是内存又是非可压缩性资源所以不支持弹性缩放。因此我们只能使用cpu指标进行伸缩。
b、若使用v2版本那么我们v2版本有哪些指标可以用于作为伸缩数据时的基本标准呢?我们可以在官网查看到。
2、HPA的使用。我们可以在kubectl api-versions 中看到有一个autoscaling的api版本,接下来我们演示两种不同的控制器是怎么工作的。
3、HPA V1测试:我们接下来重新创建一个deployment,因为这个新的我们要做资源限制,不做资源限制就没法说这个pod需要伸缩。因为我们定义说一个pod最多只能使用多少多少CPU,最多只能使用多少多少内存,现在我们需要评估他使用的百分比了。
a、首先我们创建一个deployment
[root@k8smaster manifests]# kubectl run myapp --image=ikubernetes/myapp:v1 --replicas=1 --requests='cpu=50m,memory=256Mi' --limits='cpu=50m,memory=256Mi' --labels='app=myapp' --expose --por t=80service/myapp created deployment.apps/myapp created
b、接下来我们需要他能自动伸缩,我们可以用命令定义
[root@k8smaster manifests]# kubectl autoscale deployment myapp --min=1 --max=8 --cpu-percent=60(创建一个最小副本数为1,最大副本数为8,cpu最多使用百分比为60%的hpa) horizontalpodautoscaler.autoscaling/myapp autoscaled
c、接下来我们尝试发起压力测试请求看看效果。
首先我们通过ab来访问
[root@k8smaster ~]# ab -c 100 -n 500000 http://192.168.10.10:30456/index.html This is ApacheBench, Version 2.3 <$Revision: 1430300 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 192.168.10.10 (be patient) apr_pollset_poll: The timeout specified has expired (70007) Total of 9502 requests completed
压测过程中我们可以查看hpa,发现cpu增长时hpa能感应到,并计算出副本需求
[root@k8smaster manifests]# kubectl describe hpa Name: myapp Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Fri, 30 Aug 2019 10:31:19 +0800 Reference: Deployment/myapp Metrics: ( current / target ) resource cpu on pods (as a percentage of request): 70% (35m) / 60% Min replicas: 1 Max replicas: 8 Deployment pods: 2 current / 2 desired #计算出需要两个pod Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale False BackoffBoth the time since the previous scale is still within both the downscale and upscale forbidden windows ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request) ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 48s horizontal-pod-autoscaler New size: 2; reason: cpu resource utilization (percentage of request) above target
此时我们看到我们的副本自动增加了一个
[root@k8smaster ~]# kubectl get pods -w NAME READY STATUS RESTARTS AGE myapp-6985749785-mj64t 1/1 Running 0 15m myapp-6985749785-ppwbl 0/1 Pending 0 0s myapp-6985749785-ppwbl 0/1 Pending 0 0s myapp-6985749785-ppwbl 0/1 ContainerCreating 0 0s myapp-6985749785-ppwbl 0/1 ContainerCreating 0 5s myapp-6985749785-ppwbl 1/1 Running 0 6s
压测完毕后我们可以看到我们hpa计算出我们只需要1个pod了
[root@k8smaster manifests]# kubectl describe hpa Name: myapp Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Fri, 30 Aug 2019 10:31:19 +0800 Reference: Deployment/myapp Metrics: ( current / target ) resource cpu on pods (as a percentage of request): 0% (0) / 60% Min replicas: 1 Max replicas: 8 Deployment pods: 1 current / 1 desired #需要一个pod Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request) ScalingLimited True TooFewReplicas the desired replica count is increasing faster than the maximum scale rate Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 15m horizontal-pod-autoscaler New size: 2; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 10m horizontal-pod-autoscaler New size: 1; reason: All metrics below target
可以看到又回退到一个pod
[root@k8smaster ~]# kubectl get pods -w NAME READY STATUS RESTARTS AGE myapp-6985749785-mj64t 1/1 Running 0 15m myapp-6985749785-ppwbl 0/1 Pending 0 0s myapp-6985749785-ppwbl 0/1 Pending 0 0s myapp-6985749785-ppwbl 0/1 ContainerCreating 0 0s myapp-6985749785-ppwbl 0/1 ContainerCreating 0 5s myapp-6985749785-ppwbl 1/1 Running 0 6s myapp-6985749785-ppwbl 1/1 Terminating 0 5m myapp-6985749785-ppwbl 0/1 Terminating 0 5m myapp-6985749785-ppwbl 0/1 Terminating 0 5m myapp-6985749785-ppwbl 0/1 Terminating 0 5m
4、HPA V2测试。HPA v2控制器表示你可以使用别的指标当做我们资源对应的资源评估扩展时使用的指标。此处只看一下定义的配置文件即可
[root@k8smaster metrics-server]# cat hpa-v2-demo.yaml apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: myapp-hpa-v2 spec: scaleTargetRef: apiVersion: apps/v1 #对谁来进行扩展 kind: Deployment name: myapp #Deployment name叫myapp minReplicas: 1 #最小副本数 maxReplicas: 10 #最大副本数 metrics: #依据哪些指标进行评估 - type: Resource #基于资源评估 resource: name: cpu targetAuerageUtilization: 55 #根据cpu的资源使用率进行评估 v1版本只支持cpu,v2版本还支持内存 - type: Resource resource: name: memory targetAverageValue: 50Mi #内存不能超过50%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号