


Docker 学习1 容器技术基础入门
一、容器是什么

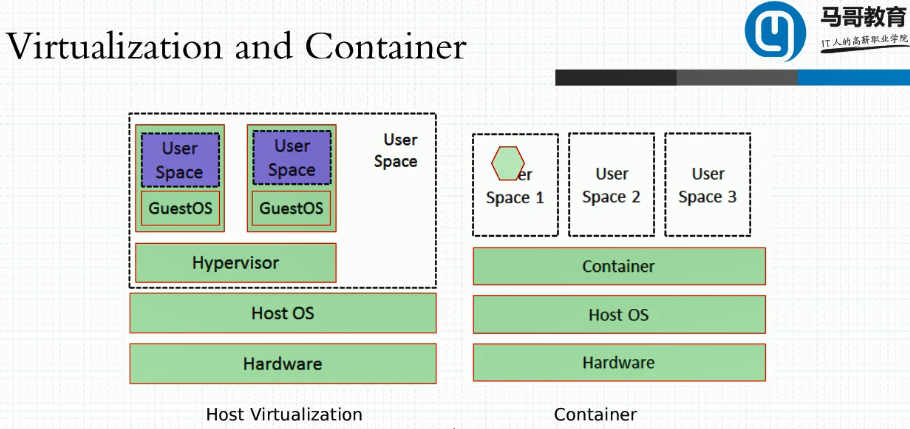
二、虚拟化
1、主机级别虚拟化(两种):虚拟化整个完整的物理硬件平台,比如vmware,可以让我们拿到的虚拟机就像一个裸的物理设备一样。让我们自由的安装操作系统和使用操作系统,安装的操作系统和我们底层的宿主机可以是不同的系统。这种级别的虚拟化首先要有底层硬件平台,并且不管你的vmm下面有没有一层host OS,但是这个虚拟机软件跟我们虚拟出来的环境应该是一个独立的硬件平台,因此用户要使用这个虚拟机就需要在这个虚拟机之上自己部署一个完整的操作系统(自己装内核,内核之上有用户空间,用户空间里跑进程)。但是运行内核不是我们的主要目的,内核的核心作用在于资源分配和管理,所以真正在用户空间跑的程序才是能产生生产力的组件。比如nginx,tomcat等,虽然其是运行在用户空间中,但是也离不开资源分配。 那么假设我们创建一个虚拟机的目的就一个单一的目的,就是为了运行一个单一的web服务器,为此我们却不得不安装内核安装用户空间然后让他去跑一个tomcat,这样代价太大了。并且从二层虚拟化的角度来分析,如果这个进程要运行那么其需要实现两级调度和资源分配,首先需要虚拟机中内核进行运行资源分配,而虚拟机又需要宿主机内核或hypervisor再次进行资源分配,因此,资源开销就不言而喻了。
a、类型一虚拟化:直接在硬件平台上不用装宿主机操作系统而是直接装一个虚拟机管理器,hypervisor,然后在hypervisor之上安装使用虚拟机,也就意味着没有任何主机是直接跑在硬件之上的,所有操作系统都是跑在虚拟机内部
b、类型二虚拟化:在物理机设备上先装一个宿主机操作系统(HOST OS),在宿主机上再装一个vmm(virtual machine manage)虚拟机管理器软件,再在这个软件之上,然后再创建使用虚拟机,像我们的vmware,kvm
2、从一种我们可以看出如果安装虚拟机资源开销会特别大,那么如果我们想要提高效率那么我们可以把虚拟机层面的内核给抽掉只保留进程,这么一来会发现一个问题,我们加虚拟机是为了环境隔离,因此我们现在的一个需求就变为了我们在硬件平台上提供一个所谓的虚拟的隔离环境管理器,而后我们创建一个又一个隔离环境,而后我们让我们需要隔离的进程就跑在隔离的环境内,内核跑在内核空间,进程跑在进程空间,因此我们要隔离的是用户空间。这样我们启动进程时让其运行在隔离的用户空间中, 这样虽然所有用户空间是被底层同一个内核所管理,但是在运行时所看到的边界是自己所属的用户空间边界,这种隔离肯定是没有主机集群隔离的那么彻底,大家可以发现这个用户空间是用来放进程的,给进程提供运行环境并且还能够保护其内部的进程不受其它进程的干扰,这就是容器级别虚拟化
二、docker虚拟化原理
1、需要隔离的资源
a、主机名域名:UTS:在内核中,UTS是可以以名称空间为单位进行隔离的,也就意味着我们可以把在同一个内核上创建出多个名称空间来,而后在名称空间之上我们可以把UTS资源让每一个名称空间和另外的名称空间彼此之间互相隔离,所以每一个名称空间都可以有自己独有的名称。
b、文件系统:Mount
c、各进程间通信:IPC(每一个用户空间都需要一个独立的IPC):可以在内核级切换为多个,每一个里面的进程可以进行互相通信,但是跨边界不可以
d、PID:PID为1的为root用户:一个系统运行无非就两棵树:进程树,文件系统树。很显然,对当前用户空间来讲,既然认为自己所属的这个用户空间是当前系统上唯一的,那么就需要给他弄一个假象让其知道自己是init,要么自己从属于某个init,否则这个用户空间中的进程将无法被管理,在linux管理界面从来都是白发人送黑发人,子进程由其父进程所创建,而子进程终止和回收也是由其父进程来实现,如果init结束了,那么init结束之前其会把其子子孙孙都要干掉其才会放心离开。因此每一个用户空间都应该要有自己的init。因此PID也是要互相隔离的。
e、User 用户,用户组:运行一个进程都应该以某个用户的身份来运行,每一个用户空间都需要有一个root,在一个内核上只能有一个root这是显然的,因此还必须给每一个用户空间伪装出一个root来,这个root在真正的系统上只是一个普通用户,但是对于这个用户空间来讲,我们可以把它伪装为id为0,但是它只能在这个用户空间为所欲为,我把这个用户空间所有权限都给他,并把它伪装成用户id为0,但在宿主机的内核上其又是一个普通用户。比如我们把一个子目录属主属组都改成某个用户,然后chroot过去,这样该用户对这个目录就有所有权限。
f、网络 Net:每一个用户空间都应该像虚拟机一样能够看到自己的专用的网卡和网络接口,有自己专有的TCP/IP协议栈,在内核级TCP/IP协议栈只有一个,因此内核级需要实现隔离。
2、linux内核到今天为止在内核级一共对这六种需要被隔离的资源在内核级已经通过一个名称空间的机制已经被原生支持。(namespace),直接通过系统调用向外输出。创建进程一般使用clone(),将这个进程放到某个名称空间去我们使用setns() 设置名称空间进行调用等等。
3、docker虚拟化就是通过上面六个内核级别的namespace加上chroot来实现的。
4、支持docker内核版本
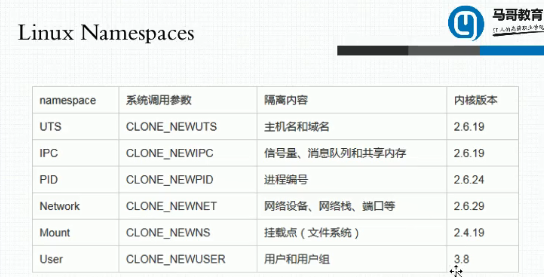
因此要想很好的使用容器技术至少要内核3.8以后才可以,centos6天然就被排除在外,因为其用的是2.6的内核。
三、docker资源限制
1、cgroups (Control Groups 控制组):在创建虚拟机时我们就可以设定几个cpu或多少内存,假如我们宿主机有32核而创建虚拟机给了2核那么剩下的30核此虚拟机是无法使用的,若容器不限制其资源那么其就会一直使用宿主机资源,这样很容易把宿主机资源全部占用,cpu还好一点,若是内存耗尽,因为其为非压缩资源,将直接OOM了。因此cgroups把系统级的资源分成多个组,然后把每一个组内的资源量分配到特定的用户进程空间上去。

2、LXC:LinuX Container 它是除了vserver以外最早一批把完整的容器技术用一组简易使用的工具和模板来极大简化容器技术使用的一个方案,所以他把自己称作linux Container。
lxc-create :可以使用此命令快速创建一个容器,通常称为一个用户空间,创建完一个用户空间以后,这个用户空间应该有最基本的相应的二进制命令文件和相应文件系统的目录结构。因此我们需要一个模板,template,这个模板实际上就是一组脚本,创建完一个名称空间这个脚本自动执行以后其会首先给脚本一个执行环境,这个脚本执行的时候会自动的去实现安装过程,这个安装指向了你所打算创建的那一类名称空间的系统发行版所属的仓库,然后在仓库中把对应程序包下下来安装生成这个新的名称空间。于是这个名称空间就像虚拟机一样可以被使用。 LXC就靠这一组工具帮忙快速的实现了创建空间,利用模板完成内部所需要各种文件的安装,同时还有些工具能够自动帮我们安装完成后chroot切换过去,于是我们就可以愉快的使用用户空间了。
3、但是依然会有很多的门槛,第一,需要学号LXC的各种工具,第二,必要的时候还需要定制模板。第三,更重要的是每一个用户空间都是安装生成的,我们在里面后来运行的过程中生成了很多文件,比如运行程序,编辑配置文件,那么这些数据将来在宿主机出现故障的时候我们想要迁移到其它宿主机上去也不是一件容易的事情,因此后来就出现了docker
3、docker 是什么
docker是LXC的增强版,严格意义上来说docker并不是容器,而是容器的易用工具(前端工具)而已,容器是linux内核中的技术。他只是将这种使用变得简化,得以普及。
四、那么docker是怎么简化的呢,docker构建原理
1、docker早期的版本,其核心就是一个LXC,他是一个LXC的二次封装发行版。功能上利用LXC做容器管理引擎,但是在创建容器时它不再是用模板去现场安装生成(就像操作系统一样安装生成),而是事先通过一种镜像技术。我们尝试着把一个操作系统用户空间所需要用到的所有组件事先准备编排好,编排好以后整体打包成一个文件,这个文件我们称作镜像文件。这个镜像文件是放在一个集中统一的仓库中的。使用时可以通过docker run 或者docker pull 将镜像下载至本地启动。为了让容器更加易于管理,docker 还采用另外一种方式,在一个用户空间中我们可以尝试着运行一组进程或运行一个进程,目的就是为了运行一个能有生产功能的软件程序。比如nginx运行在nginx容器中tomcat运行在tomcat容器中,二者用容器间的通信逻辑来进行通信,所以以后一个容器只运行一个进程,这是docker的目的,而LXC是把一个容器当一个用户空间使用,把容器当虚拟机一样用,里面可以运行n个进程,这样使得管理极为不便,而docker使用在一个容器中只运行一个进程的方式使得各程序进行分布式部署,以微服务的形式进行项目的交付。
2、以前在分发和部署时,尤其是程序员做多版本多环境下开发时及其麻烦和困难,但正是这种容器技术的发展和大规模使用,极大的降低了软件开发的成本和难度。
3、docker 镜像机制:分层构建,联合挂载。(可以好几个层共用一个底层的centos镜像)
3、每个层都只读,如果要能读写,需要在联合挂载的镜像栈的顶层再添加一个层实现读写。

4、因为docker 层是只读的,因此如果要修改文件,需要在联合挂载的镜像栈的最顶层额外附加一个新层,这个才是容器专有的层,能读能写。如果要改基础镜像中的文件,要删除的话只能标记为不可见,要修改的话只能写时复制,然后再在上层进行修改。
五、docker 编排

1、docker 出现以后迅速出现了各种容器编排工具,比如docker自己的machine +swarm + compose,compose是单机编排,只能编排一个docker 服务器之上,如果要把n个docker主机当一个docker主机来管理那么使用swarm
2、mesos 其不是用来专门编排容器的,他是实现统一资源调度和分配的。如果要实现编排容器需要加一个中间层marathon(马拉松)
3、kubernetes --> k8s 谷歌悄悄使用容器已经有十几年的历史了,其内部据说每一周需要新建和销毁的容器多达几十亿个,docker尽然机缘巧合之间摸到了这个门道并且把其做成开源软件,这时候谷歌坐不住了,本来是自己独门武器使用的,但是那货尽然找到了方法还公开给所有人使用了,这个时候docker已经大火了,后来又有个公司拥有自己的容器引擎叫Rocket,谷歌就在后面扶持它的coreOS,后来发现coreOS实在是难以跟docker抗衡,确实上不了台面,后来在谷歌内部有个重要的容器编排工具叫bogey(博格),已经跑了十几年了,该踩的坑都踩完了,因此大规模的容器编排工具k8s横空出世,一出世就几乎横扫一切。然后在17年12月k8s基本占据了百分之八十多的市场份额。在此基础上谷歌还成立了CNCF(容器标准组织)。
4、docker容器运行引擎变化:docker 早期是基于LXC构建的,当后来其略具实力以后就抛弃了LXC然后自建了容器引擎libcontainer,当然这也不能怪他,技术需要与时俱进,后来CNCF成立后纠集起了除了docker以外的容器领域的几乎全部力量,其后来开放概念说如果后期容器技术如果要发展下去那么肯定要走向标准化,肯定要开源。而且不能受控一家公司,那么谁来负责做标准化呢,CNCF如果自己做肯定没有任何问题,但是这样做明摆着太欺负docker了,所以给了docker机会,你来定标准化,同时做一款软件开源出来,所以docker容器引擎由libcontainer 进化到runContainer,现在的新版的docker都是用的此容器引擎,也叫runC,也就是容器运行的引擎环境标准。
linuX Container ----> libcontainer ----> runContainer
镜像文件标准:OCF(开放容器格式标准,已经成为了工业 标准),谁做容器都应该遵循这个标准。

