结对第二次—文献摘要热词统计及进阶需求
软工实践文献摘要热词统计及进阶需求
写在前面
- 本次作业链接
- 结队成员:lc me
- 队友博客链接(221600103)
- Github项目
- 作业目标:
1.统计文件的字符数
2.统计文件的单词总数
3.统计文件的有效行数
4.统计文件中各单词的出现次数
5.按照字典序输出到文件result.txt
6.接口封装 - 具体分工:
lc:输入 统计字符数 分割字符 测试
me:统计单词数 统计最多的10个单词及其词频 输出 代码重构与优化
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| Estimate | 估计这个任务需要多少时间 | 400 | 600 |
| Development | 开发 | 520 | 665 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 30 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 20 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 20 | 35 |
| Coding | 具体编码 | 300 | 400 |
| Code Review | 代码复审 | 20 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 630 | 650 |
| Reporting | 报告 | 20 | 30 |
| Test Report | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 1140 | 1285 | |
设计实现过程
前期讨论的时候我们将代码功能分为7块,包括:文件导入、单词分割、统计字符数、统计单词数量、行数统计、统计单词词频、结果写入文件。原定每个功能一个函数,但是经过后期具体编程以及反复考虑之后决定将功能划分为5大块:主函数导入文件、字符统计、单词数量统计以及词频统计、行数统计、结果输出。主函数main导入文件后产生一个ifstream对象,通过调用charCount(ifstream,...)字符统计函数、lineCount(ifstream)行数统计、wordCount(...)单词数量统计以及词频统计函数,printResult(...)结果输出函数实现所需功能。

代码整体流程为先读取文件,读取过程中先将特殊符号替换成空格“ ”,同时每读取一个字符就对字符数进行统计,读取的数据存储到vector容器中。单词的数量统计以及词频统计的流程是将vector中的字符转换为小写后读入到string中,在对string进行用空格分割,分割后得到的每个单词存入vector<string>容器中,再对得到的单词进行合法性筛选,过滤掉不符合单词定义的单词。过滤完成之后,开始遍历每个单词,并将单词和出现次数分别作为map的键和值存储,然后通过vector过渡使用sort函数进行词频由高到低、单词按字典排序。一切统计完成后将组织结果输出到result.txt文件中。
排序部分是比较关键的部分,上面提到用map存储单词及其出现次数,这里详细说明如何排序。先把map中的数据放到vector中:
vector
再利用sort()函数排序:
sort(wordSort.begin(), wordSort.end(), CmpByValue());
CmpByValue结构体中定义次数由大到小和单词按字母表排序:
struct CmpByValue {
bool operator()(const PAIR& lhs, const PAIR& rhs) {
if (lhs.second != rhs.second)
{
return lhs.second > rhs.second;
}
else
{
return lhs.first < rhs.first;
}
}
};
用例测试: ---
从google scholar上下载了10篇cvpr/iccv文章,组成十个测试用例对代码进行测试,结果如下:
测试样例:
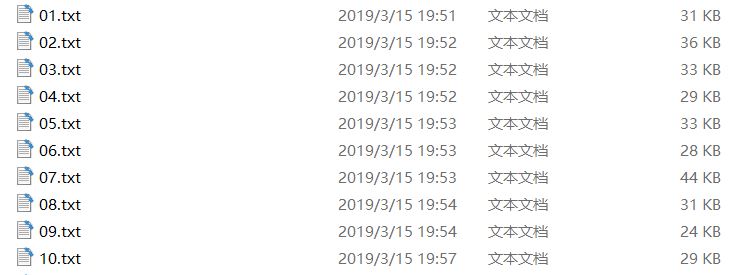
论文样例:

测试过程:
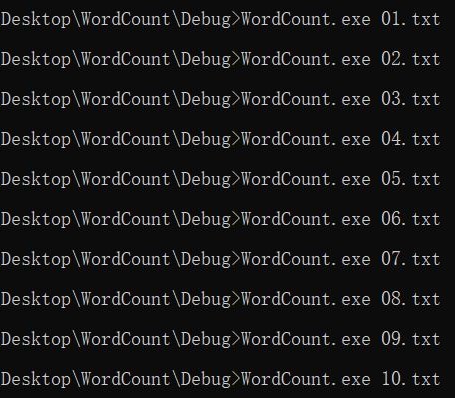
测试结果:

| 功能测试 | 测试情况 | 解决情况 |
|---|---|---|
| 主函数导入文件 | 导入文件正常 | |
| 字符统计 | 字符统计正常 | |
| 单词数量统计以及词频统计 | 容器溢出 | 已解决 |
| 行数统计 | 行数统计正常 | |
| 结果输出 | 单词排序有乱序 | 已解决 |
性能改进
展示性能分析图和程序中消耗最大的函数
经过性能分析后发现wordCount函数中使用CPU较多:
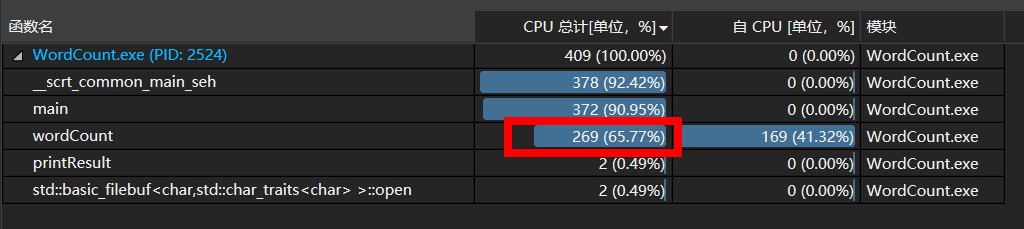
经过观察,该函数使用大量的字符数组存储,相应地也使用了较多的循环去处理,查看性能分析中占用最多的部分发现是单词过滤部分的二重循环中其中的一个二维数组将字母转换成小写的模块,于是变换存储结构,将wordCount函数中的二维数组换成string或者vector,再将小写的转换移到vector转存string是同步进行,并简化不必要的二重循环之后再进行性能分析。优化前wordCount函数的瓶颈段:

优化之后的CPU使用情况如下图所示:
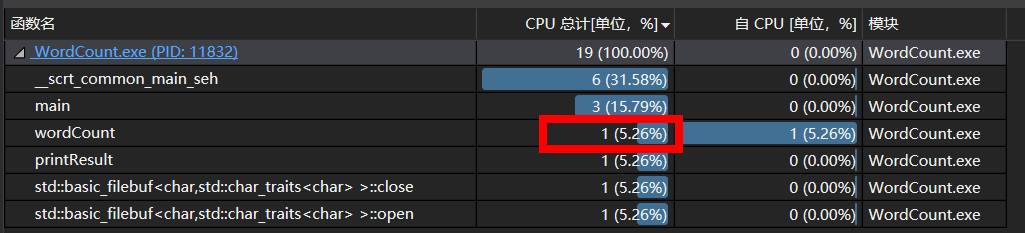
此时的瓶颈段如下:

优化共计使用了10小时,不仅仅是WordCount函数做了优化,程序的多个地方也做了细小的优化,让代码更有效率。
代码说明
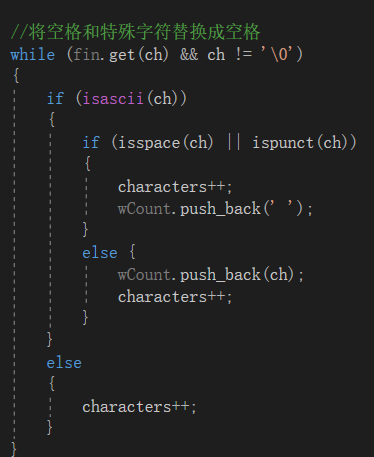
字符统计函数部分代码:读取过程中先将特殊符号替换成空格“ ”,同时每读取一个字符就对字符数进行统计,读取的数据存储到vector容器中。
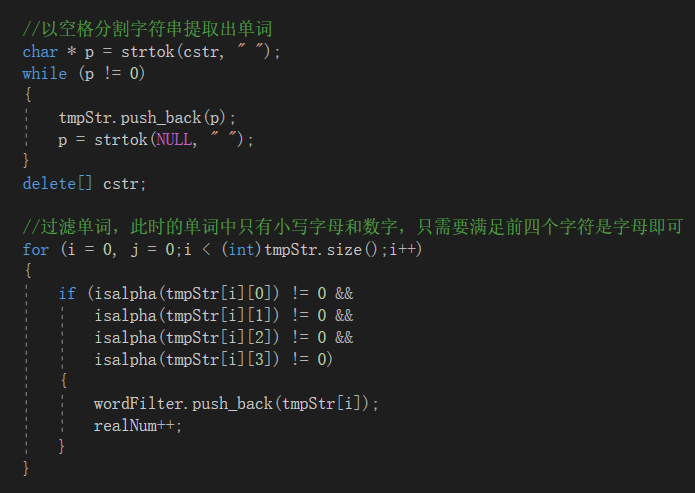
单词数量统计以及词频统计函数部分代码:将vector中的字符转换为小写后读入到string中,在对string进行用空格分割,分割后得到的每个单词存入vector
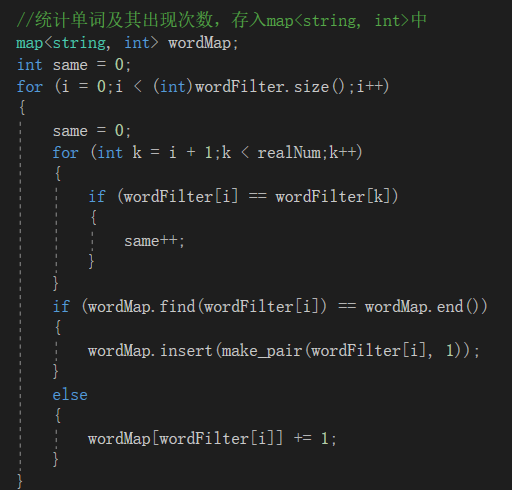
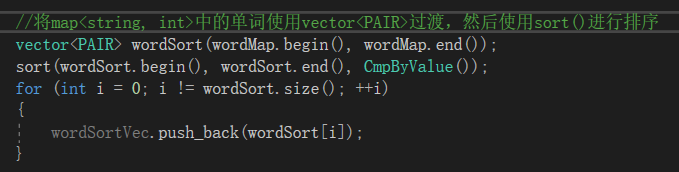
过滤完成之后,开始遍历每个单词,并将单词和出现次数分别作为map的键和值存储,然后通过vector过渡使用sort函数进行词频由高到低、单词按字典排序。
困难及解决方法
在编写WordCount函数体时没有选好存储结构,使用了动态二维数组,导致常常一不小心就越界,报错;通过和队友讨论以及上网查找资料研究之后决定使用string和vector进行存储,这样可以很大程度上节省了维护下标的繁重任务。
我的队友
我的队友是一个非常认真细心的人,她的代码很规范,代码风格很好,有很好的阅读体验。而且编程逻辑很严密,这点是我要向她学习的地方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号