包 logging模块 hashlib模块 openpyxl模块 深浅拷贝
包
包是什么
他是一系列文件的结合体,表现形式就是文件夹
包的本质还是模块
他通常会有__init__.py文件
我们首先回顾一下模块导入的过程
import module
首次导入模块(.py文件) 先产生一个执行文件的名称空间 1. 创建模块文件的名称空间 2. 执行模块中的代码,将产生的名字和值传入模块的名称空间 3. 在执行文件中拿到一个指向模块的名称空间的名字
作为比较,包的导入过程是这样的
import package 首次导入包: 先产生一个执行文件的名称空间 1.创建包下面的__init__.py文件的名称空间 2.执行包下面的__init__.py文件中的代码 将产生的名字放入包下面的__init__.py文件名称空间中 3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字
需要注意的是“.”的左边一定是包(文件夹)
使用包的注意事项?
从包的设计者的角度看,为了避免重名,可以使用相对导入
从包的开发者的角度看,如果使用绝对路径来管理的自己的模块,那么它只需要永远以包的路径为基准依次导入模块。
从包的使用者的角度看,你必须得将包所在的那个文件夹路径添加到system path中(环境变量)
python2和python3的区别
python2如果要导入包 包下面必须要有__init__.py文件
python3如果要导入包 包下面没有__init__.py文件也不会报错
当你在删程序不必要的文件的时候 千万不要随意删除__init__.py文件
导入包的过程详解
首先,这是组织结构,poke.py以及图中的init.py都是在dir文件夹下的哦
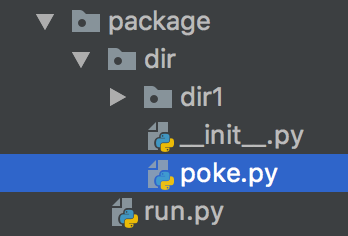
其次,这是run.py/__init__.py/poke.py里面写的内容
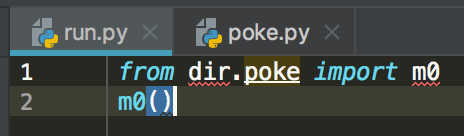
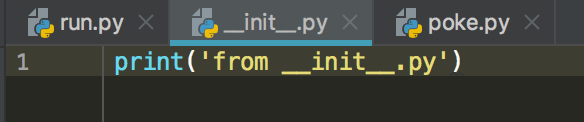

最后,这是执行结果
![]()
1 from dir.poke import m0 2 m0() 3 4 >>> 5 from __init__.py # 这是执行第一行代码得到的, 6 # 因为在dir文件夹下面的__init__.py文件中有 7 # print('from __init__.py')这句话 8 from dir文件夹下的poke.py里面定义的m0方法 9 # 这是执行第二行代码m0()所得 10 # 需要注意的是在引入m0方法时 11 # 要注意不能直接写from dir import m0 12 # 要写from dir.poke import m0,要把路径写全了
logging模块
日志记录示例
下述版本存在以下问题:不能指定字符编码;只能往文件中打印。
import logging logging.basicConfig(filename='access.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', # 日期的格式设置,如前一天介绍的,Y为年,m为月...,p为上午或者下午 level=30, # 这里给level传入的数值,决定了什么级别的日志会打印,这里写30就是指级别大于等于30的会打印 ) logging.debug('debug日志') # 10 logging.info('info日志') # 20 logging.warning('warning日志') # 30 logging.error('error日志') # 40
logging.critical('critical日志') # 50
>>>
2019-07-19 18:58:01 PM - root - WARNING -logging模块: warning日志 2019-07-19 18:58:01 PM - root - ERROR -logging模块: error日志 2019-07-19 18:58:01 PM - root - CRITICAL -logging模块: critical日志
日志模块需要记住的四个对象
1.logger对象:负责产生日志
2.filter对象:过滤日志(了解)
3.handler对象:控制日志输出的位置(文件/终端)
4.formmater对象:规定日志内容的格式
logger对象
''' 注意程序执行结束多出来的两个文件(a1.log, a2.log)的内容与控制台的内容 ''' import logging # 1.logger对象:负责产生日志 logger = logging.getLogger('日志记录')
从上面案例中可以得知,改变日志格式的要点就是 formatter对象,那么他有哪些格式的参数呢?


''' format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息 '''
filter对象(了解)
这里没有用到,暂时不写,只要知道这是日志过滤相关的就可以了。
handler对象
# 3.handler对象:控制日志输出的位置(文件/终端) hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中,传入第二个参数 encoding='utf-8' 防止中文乱码 hd2 = logging.FileHandler('a2.log', encoding='utf-8') hd3 = logging.StreamHandler() # 输出到终端=
formmater对象
# 4.formatter对象:规定日志内容的格式 fm1 = logging.Formatter( fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', ) fm2 = logging.Formatter( fmt='%(asctime)s - %(name)s: %(message)s', datefmt='%Y-%m-%d', )
# 以上从logger开始三部分代码(没有filter相关)加上下述代码,
组合起来便能达到“在控制台,日志文件中分别打印日志”的需求
# 5.给logger对象绑定handler对象(绑定不同的输出文件、终端) logger.addHandler(hd1) logger.addHandler(hd2) logger.addHandler(hd3) # 6.给handler绑定formatter对象 (给他们绑定不同的日志格式) hd1.setFormatter(fm1) hd2.setFormatter(fm2) hd3.setFormatter(fm1) # 7.设置日志等级(debug、info、warning、err、critical),低于这个等级的信息将被过滤(舍弃) logger.setLevel(20) # info # 8.记录日志 logger.debug('debug日志信息') logger.info('info日志信息') logger.error('error日志信息') # -------------* 控制台输出信息 *-------------------- # 2019-07-19 21:52:15 PM - 日志记录 - INFO -test2: info日志信息 # 2019-07-19 21:52:15 PM - 日志记录 - ERROR -test2: error日志信息 在控制台、日志文件中分别打印日志
logging配置字典
👆上面的配置使用起来还是挺麻烦的,接下来介绍一种可以直接调用的现成配置
""" logging配置 """ import os import logging.config ''' -------------------------------------------- ------------* 需要自定义的配置 *------------- -------------------------------------------- ''' # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 定义日志输出格式 结束 # 定义日志文件的存放目录与文件名(一般视情况选择下面的两个即可) logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录 (执行文件starts.py 在bin目录下) # logfile_dir = os.path.abspath(__file__) # log文件的目录 (执行文件starts.py 在项目根目录下) logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # 像日志文件的最大限度、个数限制,日志过滤等级等也可以在下面的对应地方限制 ''' -------------------------------------------- --------------* log配置字典 *--------------- -------------------------------------------- ''' # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, # 一般用不到过滤,所以就空在这里了 'handlers': { # 不需要的话就注释掉吧?终端打印在上线运行的时候会占资源,还是有点浪费的 # 打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, # 终端打印可省略 # 打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024 * 1024 * 5, # 日志大小上限 5M,超过5M就会换一个日志文件继续记录 'backupCount': 5, # 日志文件的数量上限 5个,超出会把最早的删除掉再新建记录日志 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { # logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, }, } def load_my_logging_cfg(): logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(__name__) # 生成一个log实例 logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__': load_my_logging_cfg()
# 注:利用控制台打印日志仅在项目测试阶段用来调试,等项目上线了,要把控制台打印关掉,不然比较占资源。
hashlib模块
什么是hash?
hash是一种算法(Python3.版本里使用hashlib模块代替了md5模块和sha模块,主要提供 SHA1、SHA224、SHA256、SHA384、SHA512、MD5 算法),该算法接受传入的内容,经过运算得到一串hash值。
执行了hash算法后得到的加密数据,并不能解密,想要解密,能做的是将常用的一些加密后的密文以及其对应的原文一一对应保留一下,然后去这个库中查找。
hash的应用场景:明文加密,查看文件是否被篡改
(服务器端对文件会保留一份密文,
等你下载结束后将文件以二进制形式读取并按照相应的加密方法
“用的比较多的是md5”加密后和服务器端的作比较,来判断是否被修改。)
(如果文件比较大,没办法完全用hash加密后对比,
就需要在文件几个固定位置取一部分加密后比较)
明文加密演示
# hashlib模块 加密的模块 import hashlib # 这个加密的过程是无法解密的 md = hashlib.md5() # 生成一个帮你造密文的对象 # 不同的加密算法,使用方法是一样的,修改md5为其他算法就行 # md.update('hello'.encode('utf-8')) # 往对象里传明文数据 update只能接受bytes类型的数据 md.update(b'B055man69') # 往对象里传明文数据 update只能接受bytes类型的数据 print(md.hexdigest()) # 获取明文数据对应的密文 # 5406298b4a3351273717ec3fe20acce3
密文的长度越长 内部对应的算法越复杂
与此同时:
1.时间消耗越长
2.占用空间更大
通常情况下使用md5算法,足以应对大部分场景
hash有什么特点?
- 只要传入的内容一样,不管传入几次,得到的hash值一样,可用于非明文密码传输时密码校验
- 不能由hash值返解成内容,即可以保证非明文密码的安全性
- 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的,可以用于对文本的哈希处理
对于特点1 的演示,即同样的字符串,不管分成几次传入,他的结果都是相同的
import hashlib # 传入的内容 可以分多次传入 只要传入的内容相同 那么生成的密文肯定相同 md = hashlib.md5() # md.update(b'areyouok?') # print(md.hexdigest()) # # 408ac8c66b1e988ee8e2862edea06cc7 md.update(b'are') md.update(b'you') md.update(b'ok?') print(md.hexdigest()) # 408ac8c66b1e988ee8e2862edea06cc7
加盐处理(在需要加密的明文指定位置加入其他字符,然后一起加密)
使用了特点1 的原理
import hashlib md = hashlib.md5() # 公司自己在每一个需要加密的数据之前 先手动添加一些内容 md.update(b'BossTellingU') # 加盐处理 md.update(b'hello') # 真正的内容 print(md.hexdigest()) # 61d4405d9a09787a2e2a86b7bcfda505
但使用上述加盐操作,一旦加盐的内容和位置被得知了,这个公司的相关数据就存在比较大的隐患了,
所以出现了动态加盐。
# 动态加盐 import hashlib def get_md5(data): md = hashlib.md5() md.update('加盐'.encode('utf-8')) # 这里的加盐可以是用户名前一位后一位或者某几位组成(保证了盐不一样,动态的额) md.update(data.encode('utf-8')) return md.hexdigest() password = input('password>>>:') res = get_md5(password) print(res) # password>>>:123 # f9eddd2f29dcb3136df2318b2b2c64d3
openpyxl模块
''' openpyxl 模块: 目前比较火的操作excel表格的模块 之前比较火的是 xlwd -- 写excel xlrt -- 读excel) 他们俩既支持03版本之前的excel文件,也支持03版本之后的excel文件 openpyxl 只支持03版本之后的 -- 只能支持后缀是 xlsx 的 03版本之前 excel文件的后缀名是 xls openpyxl 是第三方模块,要用就得先安装 '''
写操作
from openpyxl import Workbook # 加载工作簿模块 wb = Workbook() # 先生成一个工作簿 wb1 = wb.create_sheet('index', 0) # 创建一个表单页 后面可以通过数字控制位置 wb2 = wb.create_sheet('index1') wb1.title = 'login' # 后期可以通过表单页对象点title修改表单页名称 wb1['A3'] = 666 # 在A 3 这个单元格添加数据 666 wb1['A4'] = 444 wb1.cell(row=6, column=3, value=88888888) # 在第六行第三列添加数字 88888888 wb1['A5'] = '=sum(A3:A4)' # 给A 5 这个单元格用求和函数 wb2['G6'] = 999 wb1.append(['username', 'age', 'hobby']) # 添加表头 wb1.append(['bitten', 18, 'study']) # 表头下面添加记录 wb1.append(['jack', 72, 'meal']) wb1.append(['owen', 84, 'chocolate']) wb1.append(['chock', 23, 'hiking']) wb1.append(['nick', 28, ]) # 不填的数据可以空着 wb1.append(['nick', '', 'swim']) # 保存新建的excel文件 wb.save('test.xlsx') # 后缀名必须是这个 xlsx
读操作
from openpyxl import load_workbook # 读文件 wb = load_workbook('test.xlsx', read_only=True, data_only=True) # data_only=True 就不会读出excel函数公式了 print(wb) print(wb.sheetnames) # ['login', 'Sheet', 'index1'] print(wb['login']['A3'].value) # 获取login表 的 A 3 单元格中的值 print(wb['login']['A4'].value) print(wb['login']['A5'].value) # None,通过代码产生的excel表格必须经过人为操作之后才能读取出函数计算出来的结果值 res = wb['login'] print(res) # 获取到的是一个区域,从A 0 为左上顶角 最右下含值单元格为右下顶角的区域打印出来 ge1 = res.rows for i in ge1: for j in i: print(j.value)
# 注:在每次对xlsx文件写入或者修改时,要关闭该文件,不然会报错。
深浅拷贝
1. 先看赋值运算
l1 = [1,2,3,['bitten','egon']] l2 = l1 l1[0] = 111 print(l1) # [111, 2, 3, ['bitten', 'max']] print(l2) # [111, 2, 3, ['bitten', 'max']] l1[3][0] = 'jack' print(l1) # [111, 2, 3, ['jack', 'max']] print(l2) # [111, 2, 3, ['jack', 'max']]
对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的
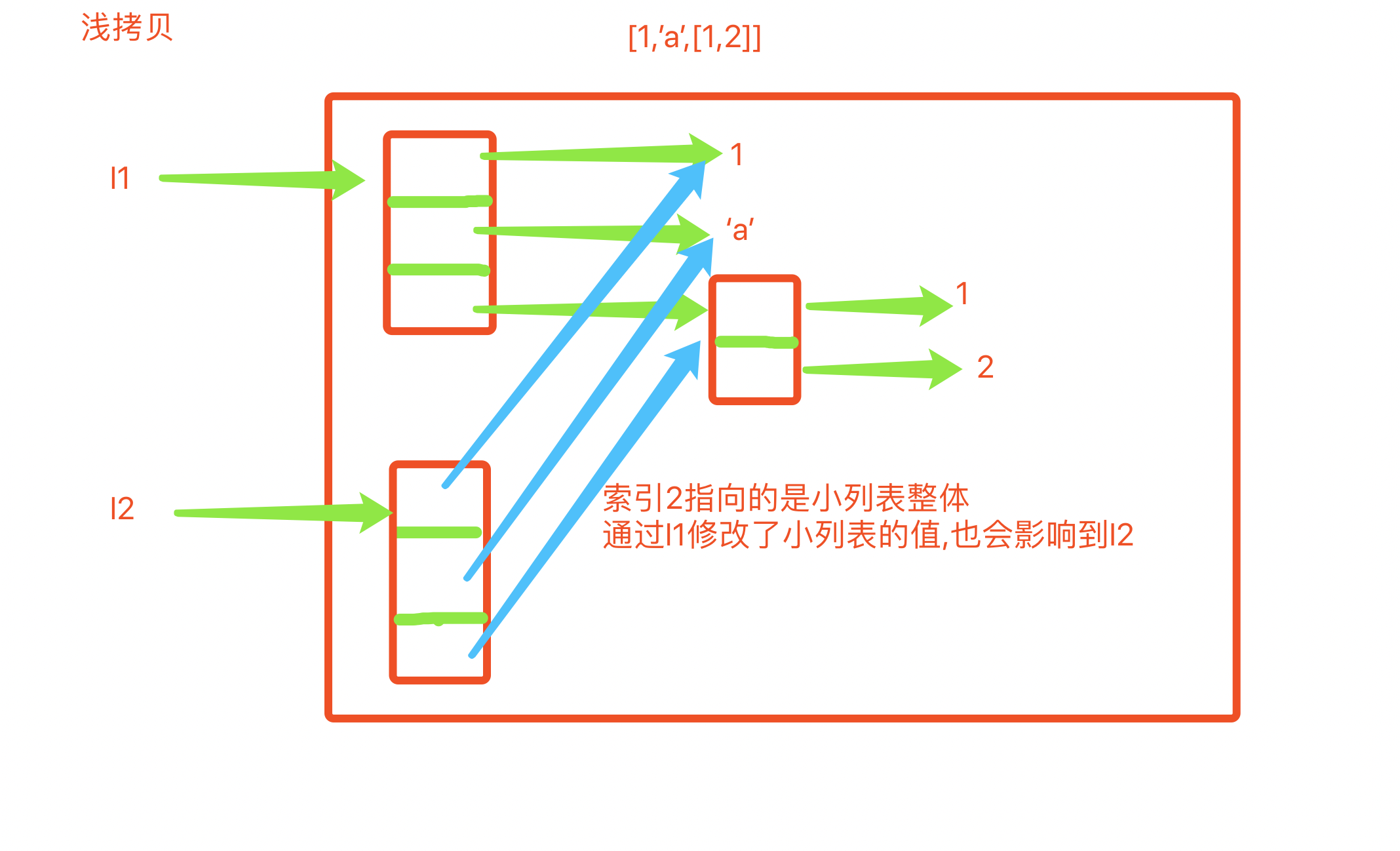
2. 浅拷贝
#同一代码块下: l1 = [1, 'jason', True, (1,2,3), [22, 33]] l2 = l1.copy() print(id(l1), id(l2)) # 2713214468360 2713214524680 print(id(l1[-2]), id(l2[-2])) # 2547618888008 2547618888008 print(id(l1[-1]),id(l2[-1])) # 2547620322952 2547620322952 # 不同代码块下: >>> l1 = [1, 'jason', True, (1, 2, 3), [22, 33]] >>> l2 = l1.copy() >>> print(id(l1), id(l2)) 1477183162120 1477183162696 >>> print(id(l1[-2]), id(l2[-2])) 1477181814032 1477181814032 >>> print(id(l1[-1]), id(l2[-1])) 1477183162504 1477183162504
对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的。
3. 深拷贝deepcopy
# 同一代码块下 import copy l1 = [1, 'jason', True, (1,2,3), [22, 33]] l2 = copy.deepcopy(l1) print(id(l1), id(l2)) # 2788324482440 2788324483016 print(id(l1[0]),id(l2[0])) # 1470562768 1470562768 print(id(l1[-1]),id(l2[-1])) # 2788324482632 2788324482696 print(id(l1[-2]),id(l2[-2])) # 2788323047752 2788323047752 # 不同代码块下 >>> import copy >>> l1 = [1, 'jason', True, (1, 2, 3), [22, 33]] >>> l2 = copy.deepcopy(l1) >>> print(id(l1), id(l2)) 1477183162824 1477183162632 >>> print(id(0), id(0)) 1470562736 1470562736 >>> print(id(-2), id(-2)) 1470562672 1470562672 >>> print(id(l1[-1]), id(l2[-1])) 1477183162120 1477183162312
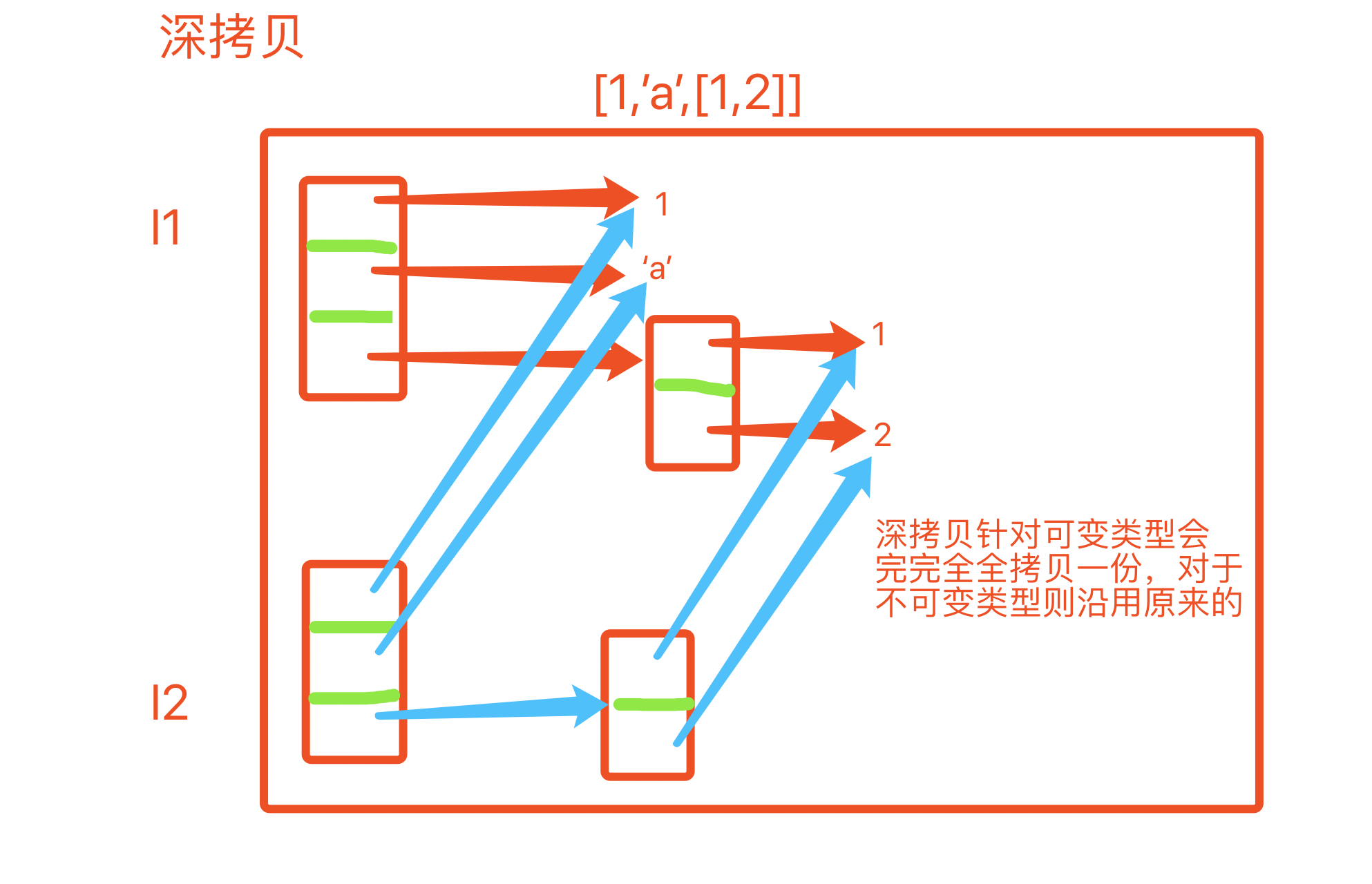
对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的。
重要示例1:
list1 = [ [ ] ] * 5 print(list1) # [[],[],[],[],[]] list1[0].append(10) print(list1) # [[10], [10], [10], [10], [10]] list1[1].append(20) print(list1) # [[10, 20], [10, 20], [10, 20], [10, 20], [10, 20]] list1.append(30) print(list1) # [[10, 20], [10, 20], [10, 20], [10, 20], [10, 20], 30]
重要示例2:
l1 = [1, 2, 3, 4, ['bitten']] l2 = l1[::] print(l2) # [1, 2, 3, 4, ['bitten']] l1[-1].append(666) print(l2) # [1, 2, 3, 4, ['bitten', 666]]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号