山鸣谷应,相得益彰——杰对项目-第二阶段总结
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2021春季计算机学院软件工程(罗杰 任健) |
| 这个作业的要求在哪里 | 结对作业-第二阶段 |
| 我在这个课程的目标是 | 提升工程能力和团队意识,熟悉软件开发的流程 |
| 这个作业在哪个具体方面帮助我实现目标 | 实践结对编程 |
项目概要
| 内容 | |
|---|---|
| 项目地址 | 2021_奥利给_作业/结对项目 gitlab 地址 |
| 学号后四位 | 3019 3293 |
结对纪实
由于之前的结对方法比较合适,故没有改变结对方式,仍在线下进行大部分的结对活动,在指导书修改后线上讨论并进行编写和检查。
至于结对的证据,我们都很熟悉新北二楼的各个有电插座的位置了算一个证据吗。
3019:不同的感受倒是没有,不过结对确实可以让自己全身心投入思考和编码测试,很难想象自己一个人半天的时间能够将本次作业写完。效率的提升是很高的,避免了大量的摸鱼无效时间,还规范了作息,两人商量时间也更加具有默契。有时候编码走神写 bug,也会被队友及时发现并指出,比如对于异常的抛出,exists 和 invalid 搞混;information 测试中 size 判断错误等。另外,还一个好处就是在本地 ubuntu 上跑不出来软链接的一些命令(如 cd 等)队友可以使用自己的电脑进行实验。在一些指导书描述不是很清晰的地方,两人相互讨论理解也极大促进了编码实现的过程,避免了编码者当局者迷的情况。
3293:本次结对最大的感受就是,看指导书很痛苦。原因在于指导书中大量出现“xx指令也是如此”、“以下不再赘述”,而且充斥着很多需要抛异常的情况。要是个人作业来做,我肯定过不了弱测,这次结对还是得益于队友清晰的思路以及不断地梳理,使得复杂的异常情况、指令行为得到了妥善的处理以及测试。希望自己能在下一次作业上不被指导书绕晕,handle各种细节。
设计实现思路
需求分析和设计
需求分析
需要实现用户和用户组,因此分别添加两个类:User 和 Group。
考虑到文件、目录、链接都需要支持大量相似的方法,抽象出一个 AbstractFile 。
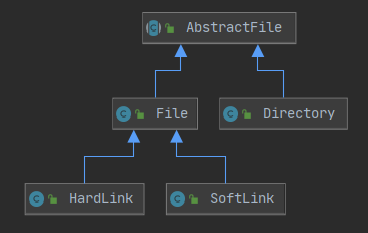
设计
用户系统相对更易设计,因此先考虑这一部分。由于用户和组是多对多的关系,需要使用字符串为索引的 HashMap 分别存储用户所在的组和组所包含的用户。另外,用户具有主组,因此用户还需要支持对于主组的设置。由于对于权限的检查较多,对于异常的抛出可以实现为 assertIsRoot 等断言,增加代码可读性。UserSystem 中也对用户和用户组分别存储两个 HashMap 。
对于文件系统,需要支持更改父亲(move),拷贝(copy);对于软链接,需要分别支持进入所链接目录以及删除文件本身,需要存储指向抽象文件的绝对路径;对于硬链接,需要引用一个常规文件。需要区分何时应当重定向的问题。
实现思路
大致思路
在用户系统中,由于需要支持和文件系统的交互,将当前用户和根用户都设置为 static 变量,并提供 getter。
由于所有文件和目录都需要支持 getInfo,故直接在抽象类 AbstractFile 中实现。
正常情况的具体实现其实比较容易,根据指导书一步一步来即可。不过最开始链接的描述令人迷惑,好在后来也改的比较正常可以理解了。关于链接的情况,在 HardLink 中重写关于文件的操作;在 findDirectory 中遇到链接到目录的软链接就进入即可;关于移动和复制,严格按照指导书上的顺序进行判断即可。
代码实现完成后,进行审核和测试设计。由于需要记录的问题较多,在我们的项目 issue 区对于各种待实现情况发布 issue,之后逐条解决。
有关异常顺序
一个难点在于异常的抛出。代码实现完成后,发现有大量异常顺序、内容是不同的,而且具有一定顺序要求。比如:move 指令中,根据异常情况 srcpath 先行的规则(指导书第二条),抛出异常的顺序为:
srcpath不存在;srcpath为当前工作目录或其上层目录;srcpath dstpath指向路径一样;srcpath是dstpath上层目录(ln -s部分提到);src为文件,目录dst下存在名为srcname的子目录;src为目录,目录dst下存在名为srcname的子文件或非空子目录;src为目录,dst为文件。
对于每一种异常情况的优先级进行异常 message 内容都需要进行完备的测试。
完整的,包含指导书 3.30 修订版后对于各种异常情况顺序的测试文档:
ln -s:
src
src 不存在
dst
dst 为文件 (exists)
src=dst
src->dst
dst/srcname 为文件或子目录 (exists) (dst/srcname)
ln:
src
src 不存在或不为文件
dst
src=dst
src dst 均为文件 (exists)
dst/srcname 为文件或子目录 (exists) (dst/srcname)
mv:
src
src 不存在
src 是工作目录或其上层目录
dst
src=dst
src->dst
src 文件 dst/srcname 目录 (exists) (dst/srcname)
src 目录 dst/srcname 文件或非空目录 (exists) (dst/srcname)
src 目录 dst 文件 (exists)
cp:
src
src 不存在
dst
src=dst
src->dst
src 文件 dst/srcname 目录 (exists) (dst/srcname)
src 目录 dst/srcname 文件或非空目录 (exists) (dst/srcname)
src 目录 dst 文件 (exists)
其中,着重注意的一点是对失效软链接抛的异常,根据指导书所写应当抛出的路径为软链接所指路径,因此需要在 findDirectory 内层捕获异常重新抛出。需要注意的是,如果捕获到了 Too many levels of symbolic links 则不进行新异常的重新抛出。
测试时,需要对大量异常情况的内容进行测试,我们最开始用的形式如下:
boolean ok = false;
try {
fs.copy("src", "dst");
} catch (FileSystemException e) {
assert (e.getMessage().equals("Path src is invalid"));
ok = true;
}
assert (ok);
但大量这样的测试堆起来,无论是可读性还是修改难度都不好。改为了如下形式进行测试。
private String copy(String src, String dst) {
String ret = "";
try {
fs.copy(src, dst);
} catch (FileSystemException e) {
ret = e.getMessage();
}
return ret;
}
assertEquals (copy("src", "dst"), "Path src is invalid");
大大增加了可读性。
有关创建和修改
对于指导书中大片的信息,总结出表格更容易让自己和队友判断和理解。对于单独的创建修改信息,可以列出以下表格:
src 为文件
move
| 情况 | create | modify |
|---|---|---|
| dst = null | src | yes |
| dst = file | src | yes |
| dst/srcname = null | src | yes |
| dst/srcname = file | src | yes |
copy(只考虑文件树根,子树都被视为新创建了)
| 情况 | create | modify |
|---|---|---|
| dst = null | new | yes |
| dst = file | dst | yes |
| dst/srcname = null | new | yes |
| dst/srcname = file | dst/srcname | yes |
src 为目录
move
| 情况 | create | modify |
|---|---|---|
| dst = null | src | yes |
| dst/srcname = null | src | yes |
| dst/srcname = directory count=0 | dst/srcname | yes |
copy(只考虑文件树根,子树都被视为新创建了)
| 情况 | create | modify |
|---|---|---|
| dst = null | new | yes |
| dst/srcname = null | new | yes |
| dst/srcname = directory count=0 | dst/srcname | yes |
可以更加清晰地设置测试、修改实现。
有关调试
为调试方便,对 tree 进行了进一步的内容输出(包括软链接的指向路径、各个抽象文件的 size、个文件的大小等)。通过 tree ,我们发现了更改父亲时重命名为哪个名字的问题、复制文件时对于祖先节点的 size 过度更新的问题等一系列 bug。从最后的实现时间也可看出,本次对于 tree 的输出调试直观化大大缩短了编码、测试和 debug 的时间。
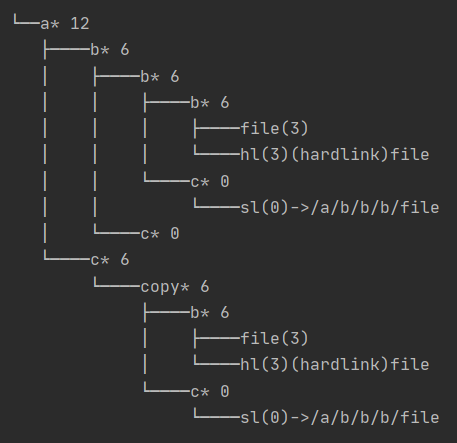
优化设计
copy on use
由于本次需要支持 copy,所以无论是目录还是文件都是可以达到指数级。如果能实现“不访问则不新建”,即每次操作都是线性,可以做到数据范围内通过所有的极限数据。
当进行从 src 到 dst.fa/dst 的 copy 时,只记录这一次 copy 操作,并不真的进行拷贝。如果 src 不发生改变,当访问 dst 时,我可以通过模拟访问 src 来得到所需结果。重点在于 src 发生了改变。
列出来现在支持的创建删除修改指令,并分一下类:
创建:mkdir mkdir -p touch fwrite
删除:rm rm -r
修改:fwrite fappend
改父亲:mv cp
将创建删除视作单元操作,即每次创建删除一个文件或目录,可以将指令分解如下:
创建:mkdir touch
删除:rm rmdir
修改:fwrite fappend
mkdir -p: 一路mkdir rm -r: 对根rmdir
如果想要做出 copy on use 的效果,需要通过修改后的 src 目录以及存储下来的信息复原出原有的 src 目录,这是一个类似于可持久化的过程。按照事件发生先后,需要在 src->dst.fa 的信息通道上记录下来这一些操作。
这里,信息通道独立出来 updateInfo 类,其中包含使用 ArrayList 组织的操作类 updateLog,表示信息通道上按时间顺序记录的操作。
考虑模拟从根目录向下走的过程。假设现在走到一个目录 dir,考虑当前目录下的是否存在某个子目录或文件是从 src copy 过来的。如果存在,那么存在一个从 src 到 dir 的信息通道,故只需在向下走的过程中记录所有信息通道上存在的操作,在每一个到达的目录都逆向推出拷贝之前文件或目录的存在形式(包括创建信息、修改信息、文件内容等),并进行真实拷贝。这样单次询问最高进行 \(2048\) 次拷贝,复杂度是可以保证的。
可惜由于各种(时间分配、指导书修改和实现复杂度等)原因,这样的优化最终仅仅成为了纸上的兵法图。
lazy tag
由于 mv 指令中,要求对全部子目录和文件的 modifyTime 进行修改,而暴力递归目录进行修改的复杂度是很高的,故考虑使用懒标记对此指令进行优化。
当目录 dir 被移动到 dst 时,对移动文件树根标记为“待下传”,并存储。当进行正常的询问 findDirectory 时,对懒标签进行下放(pushdown),和线段树中的懒标记是一个思路。这样可以省去不少没有询问 modifyTime 的时间。下面压力测试里也证明了这一点。
压力测试
NBData(极限数据)
原计划对优化后的代码进行大压力测试,生成了一份 nbdata,没优化的疯狂 GC,半小时 30 条都跑不完。最后也没优化成,只扔一份数据生成器在这里了。大致思路就是,生成一份长链 cd 进去,然后链尾加一个文件和 693 个目录,然后不停向父目录 cd 并拷贝子目录,最后目录个数在 \(694\times 2^{250}\) 个的数量级,需要实现 copy on use 才有可能通过本测试。
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<algorithm>
#include<queue>
#include<map>
#include<set>
#include<cmath>
#include<vector>
typedef long long ll;
using namespace std;
#define pii pair<int,int>
#define fi first
#define se second
#define mp make_pair
#define pb push_back
char a[100]={};
int main(){
int i,j;
freopen("nbdata.txt","w",stdout);
for(i=0;i<26;i++)a[i]='a'+i;
for(;i<26+26;i++)a[i]='A'+i-26;
for(;i<52+10;i++)a[i]='0'+i-52;
a[i++]='_';
printf("mkdir -p ");
for(i=0;i<2048;i++)printf("a/");
puts("");
printf("cd ");
for(i=0;i<2048;i++)printf("a/");
puts("");
printf("fwrite 123 file.txt\n");
printf("mkdir -p ");
for(i=0;i<63;i++)if(a[i]<'0'||a[i]>'9')printf("%c/../",a[i]);
for(i=0;i<10;i++)
for(j=0;j<63;j++)
printf("%c%c/../",a[i],a[j]);
puts("");
for(i=0;i<250;i++){
printf("cp ../a ../../a/b\n");
printf("cd ..\n");
}
printf("info /\n");
printf("fappend \"append\" b/a/file.txt\n");
printf("info /\n");
printf("info b/a/G\n");
printf("info ");
for(i=0;i<100;i++){
printf("a/");
}
printf("b/a/_\n");
printf("mkdir -p ");
for(i=0;i<150;i++){
printf("a/");
}
printf("b/a/_/_\n");
printf("mv /a /b\n");
printf("cp /b /c\n");
printf("ls /\n");
return 0;
}
大量 Move 测试
测试懒标签的性能优化效果。
数据生成器:类似上面,先生成指数级别(这里是 12 次,即 \(694\times 2^{12},3e6\))的目录和文件,然后对根目录下的目录进行 300 次重命名;最后使用 info 指令验证正确性。
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<algorithm>
#include<queue>
#include<map>
#include<set>
#include<cmath>
#include<vector>
typedef long long ll;
using namespace std;
#define pii pair<int,int>
#define fi first
#define se second
#define mp make_pair
#define pb push_back
char a[100];
int main(){
int i,j;
freopen("nbdata2.txt","w",stdout);
for(i=0;i<26;i++)a[i]='a'+i;
for(;i<26+26;i++)a[i]='A'+i-26;
for(;i<52+10;i++)a[i]='0'+i-52;
a[i++]='_';
printf("mkdir -p ");
for(i=0;i<2048;i++)printf("a/");
puts("");
printf("cd ");
for(i=0;i<2048;i++)printf("a/");
puts("");
printf("fwrite \"2\" file.txt\n");
printf("mkdir -p ");
for(i=0;i<63;i++)if(a[i]<'0'||a[i]>'9')printf("%c/../",a[i]);
for(i=0;i<10;i++)
for(j=0;j<63;j++)
printf("%c%c/../",a[i],a[j]);
puts("");
for(i=0;i<12;i++){
printf("cp ../a ../../a/b\n");
printf("cd ..\n");
}
printf("cd /\n");
for(i=0;i<150;i++){
printf("mv a b\n");
printf("mv b a\n");
}
printf("cd ");
for(i=0;i<2048-12;i++){
printf("a/");
}
puts("");
printf("info /\n");
printf("info .\n");
printf("info a/a/a/a/a/a/a/a/a/a/a/b/file.txt\n");
printf("info a/a/a/a/a/a/a/a/a/a/a/a/_\n");
return 0;
}
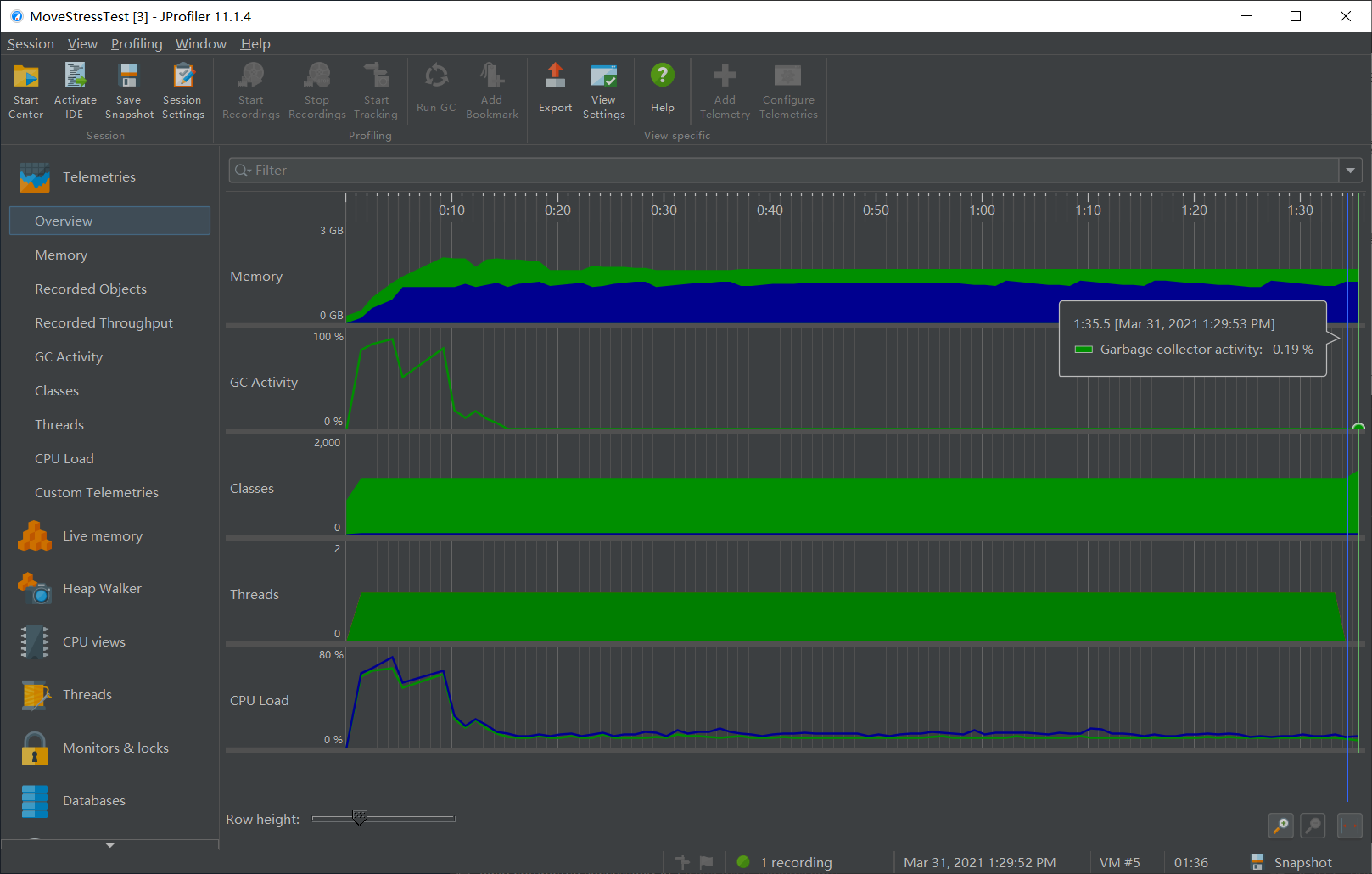
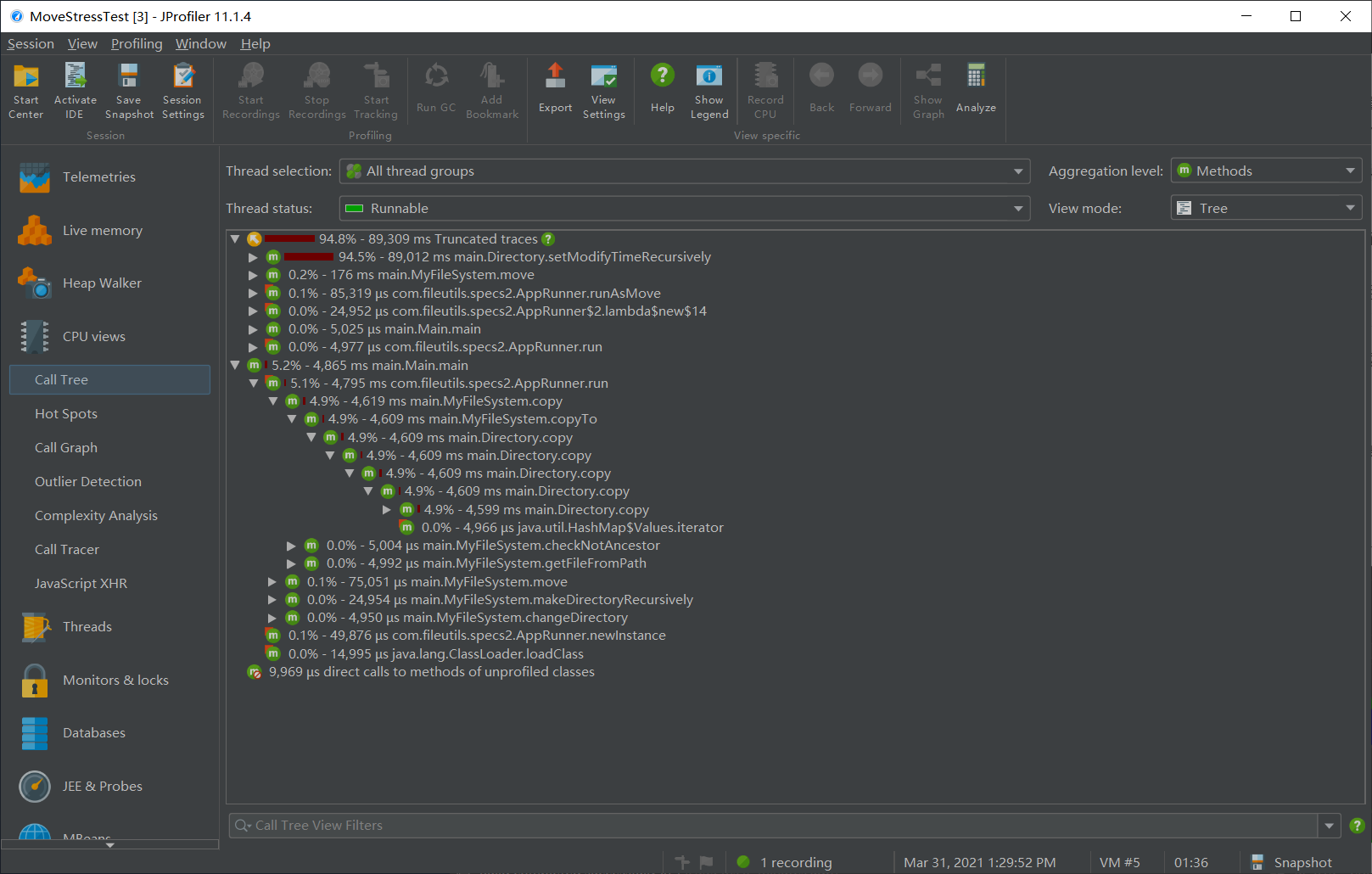
优化前:花费 95.5s,且从 CPU 调用树中明显的看出递归修改占用巨大。
 |
 |
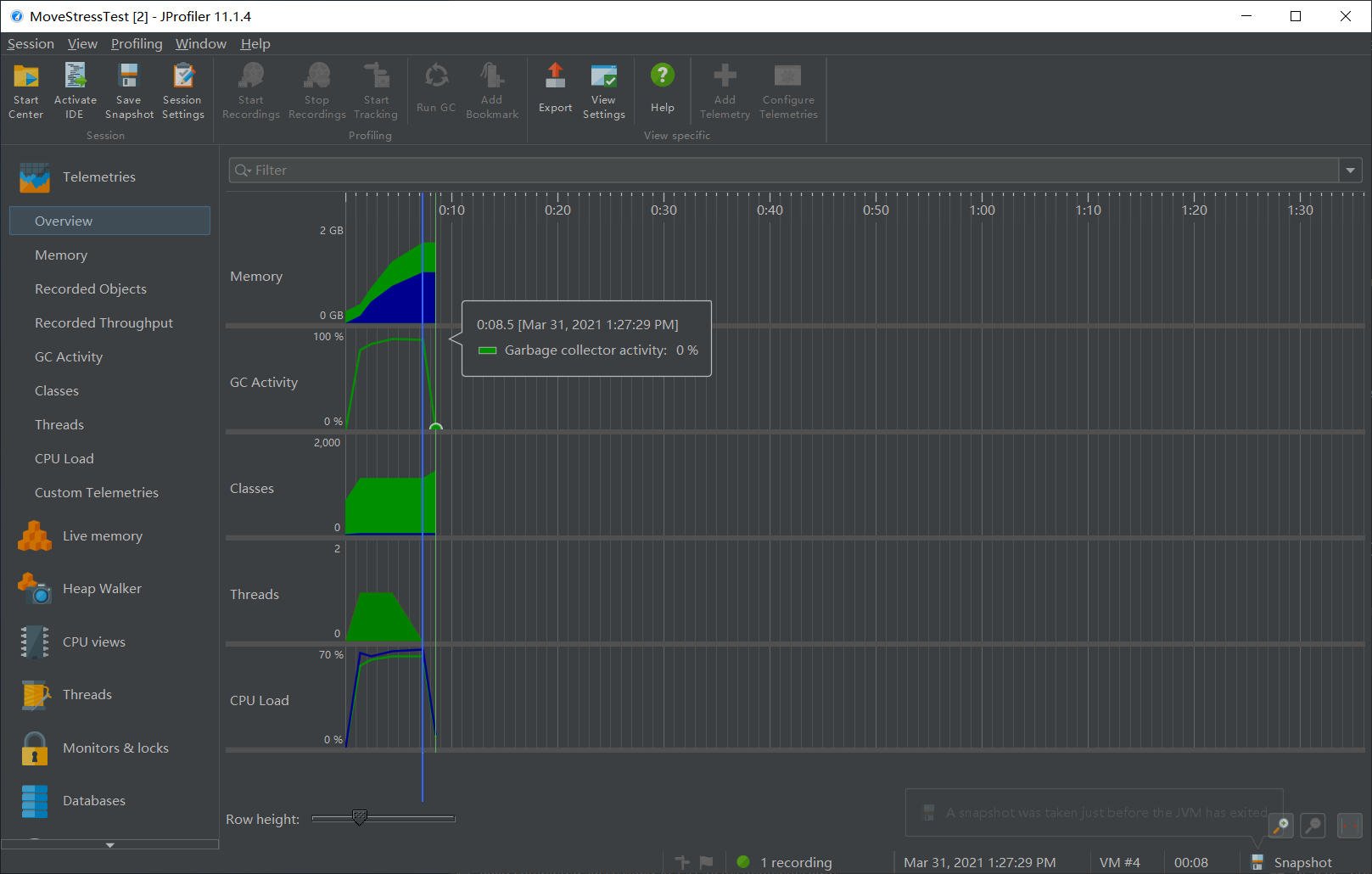
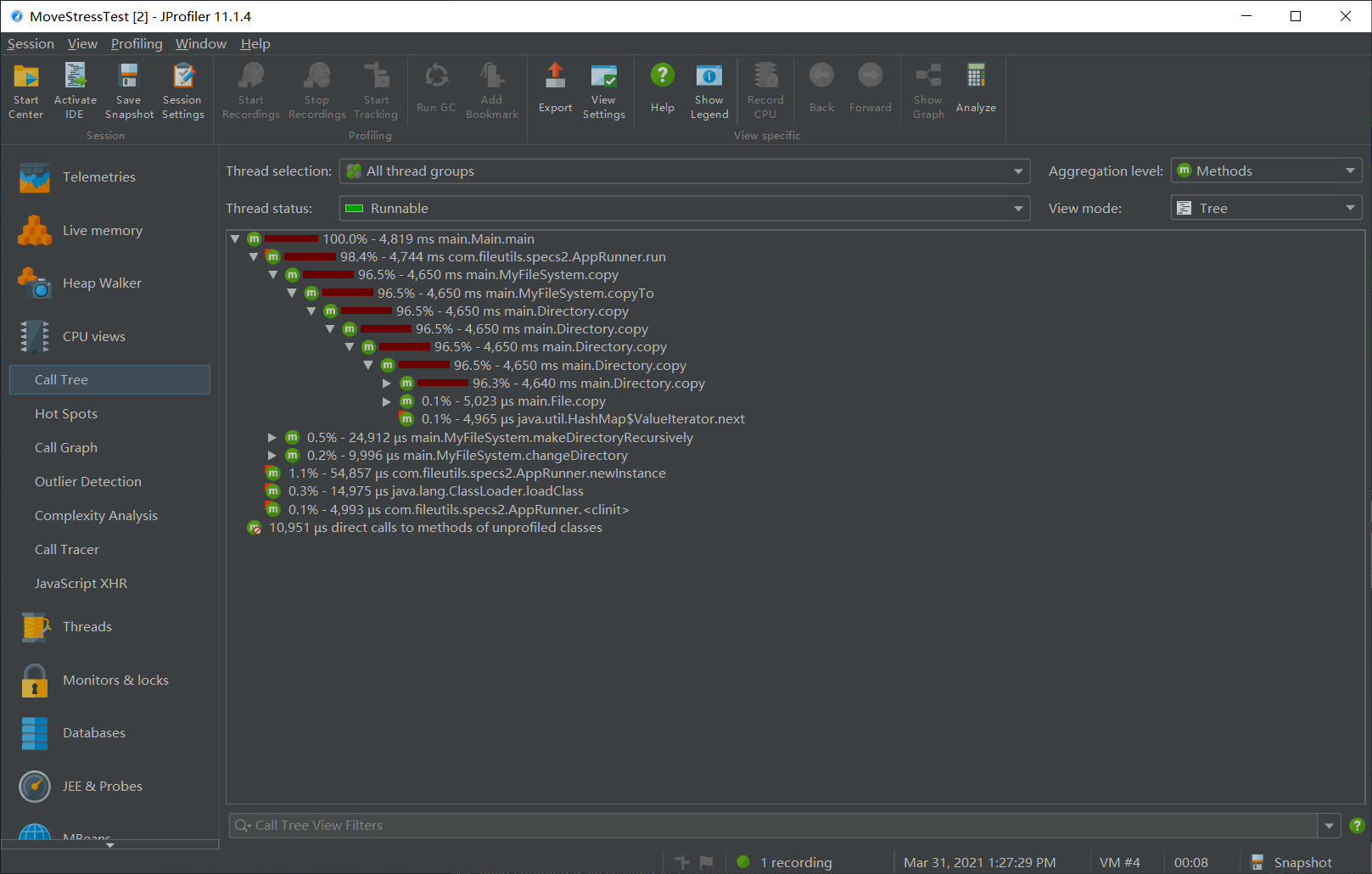
优化后:花费 8.5s,其中几乎全部时间和 CPU 占用都是在 copy 阶段使用的,mv 的占用部分甚至不到 0.1%。可见优化效果较为明显。
 |
 |
预估和实际耗时
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 5 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 22 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 10 | 20 |
| · Coding | · 具体编码 | 400 | 420 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改 | 250 | 230 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 10 | 5 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 100 |
| 合计 | 840 | 872 |
和上一次作业一样,根据指导书的修改也进行了大量的增量测试和开发,就不计入表格中了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号