山鸣谷应,相得益彰——杰对项目-第一阶段总结
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2021春季计算机学院软件工程(罗杰 任健) |
| 这个作业的要求在哪里 | 结对作业-第一阶段 |
| 我在这个课程的目标是 | 提升工程能力和团队意识,熟悉软件开发的流程 |
| 这个作业在哪个具体方面帮助我实现目标 | 实践结对编程 |
项目概要
| 内容 | |
|---|---|
| 项目地址 | 2021_奥利给_作业/结对项目一 gitlab 地址 |
| 学号后四位 | 3019 3293 |
结对纪实

3019:感受就是,很多情况自己没注意写的 bug 会被队友发现;同时两个人交流思路,实现起来也更加迅速,稳而快;同时在有人监督的情况下避免了摸鱼,时间利用率大大提高;不过效率远远低于一个人写的两倍。不过代码提交基本都是我来进行,故熟练掌握了 git rebase -i HEAD~xx 以保证 commit 记录没那么冗杂。
队友发现的 bug:
- 对于
root为父亲的路径,不能按照简单的 父节点absPath + "/" + name的方式实现; - 异常抛出的字符串不正确,应当为输入字符串。
其他的忘记了,下次一定做好 bug 记录[狗头]
3293:这次结对印证了那句话,结对项目的质量取决于两人中水平较高的。队友的水平高于我,思维较快,有时候我会跟不上,因此整体架构按照队友的思路走,我的作用主要是在队友编码时指出错误或者不合理之处。总的来说,结对过程中,两人全身心投入编码,不会被别的事情干扰,另外,队友敏捷的思维促使我思考,良好的编码习惯使我豁然开朗,收获颇多。
队友良好的编程习惯:
- 面对过长的方法会积极思考代码抽取;
- 对于作出复杂处理,例如多分支的方法,会先进行单元测试,尽量避免低级逻辑错误;
- 对于需求不清晰的地方、有特殊功用的方法等地方会附带注释,利于代码复审;
设计实现思路
环境选择
由于要进行计算覆盖率的单元测试,使用 maven 和 cobertura 进行开发和测试。
需求分析和设计
需求分析
由于一共要实现两种内容的管理(目录管理,文件管理),因此需要构建两个类:文件类和目录类。
设计
对需求进行简要分析后,列出了每个类所需支持的属性和方法:
属性:
File 类:创建和更新时间,内容,绝对路径;
Directory 类:创建和更新时间,子文件,子目录,父目录,绝对路径,是否为根目录
方法:
File 类:getSize,cat,getInfo,getAbsPath,write,append,touch
Directory 类:createFile,createDirectory,removeFile,removeDirectory,getSonFile,getSonDirectory,getSize,list,getInfo,getAbsPath,getIsRoot
后记:后来实现的时候考虑到扩展性发现可能要支持 mv cp 之类的操作,而且单存绝对路径占空间过大,于是改成了保存文件、目录名;为了不爆栈,使用循环而非递归求绝对路径。另外,文件、目录大小也设置了相应的缓存。
实现思路
由于大部分指令都是需要解析路径的,所以需要使用一个函数 findDirectory 根据一个 <dirpath> 路径获取对应目录,由于可能中途需要创建新目录,添加一个 create 的布尔值表示中途遇到不存在的目录名是否要尝试创建。
要对路径进行合理的划分,首先文件名后面一定不可以跟分隔符(/),所以当处理 filepath 时可以取出最后一个分隔符后面(或如果没有分隔符的全部)作为文件名,前面的就是一个 dirpath 了。
有一个细节需要注意,就是仅传入字符串的 split 函数对于 a/b/ 会分割为 ["a","b"],即最后一个分隔符后的空串没有被处理。这就导致 a/b/ 被识别为 a/b ,而“指导书没说清就去找 Ubuntu”,根据 Ubuntu 的特性,如果 b 这时是个文件的话就无法报错。因此需要自行实现 split,或者使用 split(s, -1)。官方包也不小心掉进这个坑了不过据说第二次就不会有问题了
实现了对于路径的分割,其他函数的实现也就是一本道的了。
实现一个从路径中提取最终文件/目录名、以及其父节点目录的函数 getFatherDirectoryAndName,以及带布尔值 create 表示是否创建的 getFileOrCreate 函数,将整个任务进行划分。四个文件相关的调用 getFileOrCreate;增删目录的 mkdir 和 rm -r ,以及不确定文件还是目录的 info 三个指令调用 getFatherDirectoryAndName,得到有关信息,就可以愉快的处理了。
关于异常的抛出,我们作出约定:保证了 File 和 Directory 类中不抛异常,所有异常在 MyFileSystem 抛出。
后来因为 issue 区突然不符合基本法说 mkdir -p 要支持原子性,于是添加了一个 checkDirectoryPathValid 函数特判 mkdir -p 这个路径是否能够成功。实现方式比较简单,但是凭空添加这么个函数就非常不优雅。不过毕竟甲方爸爸的啥需求都得做,不优雅就不优雅吧。
另外,为了方便调试,我们还实现了简易的 tree -a 功能(目前调试时接口为 ls,还在想有没有办法不改变官方包本身并且支持这个指令):

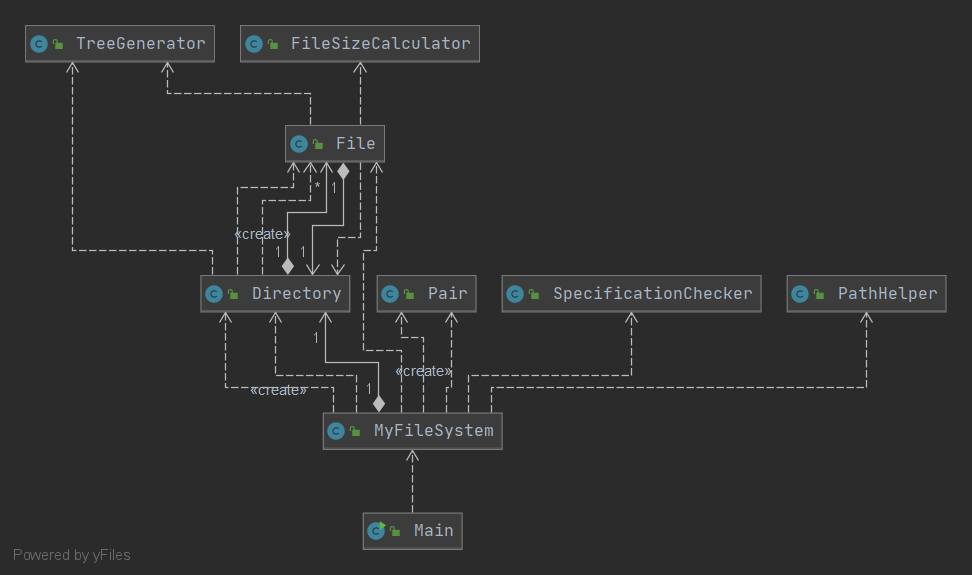
最终的文件 UML 图如下:(其中,除 File、Directory、MyFileSystem、Main 之外的类均为 utils 包中的辅助类)
压力测试
根据本次作业的数据范围(路径最大合法长度 4096;指令最多条数 500),对于可能出现的极端数据,使用 JProfiler (分享自 yls)进行了压力测试。
第一份数据
大量 mkdir -p 和 cd
第 \(i\) 次 mkdir cd 通过名字获取绝对路径需要进行 \(4096i\) 次长度为 \(2\) ("/a")的 append、两次长度为 \(4096i\) 的字符串输出,共 \(\sum_{i=1}^{248}12288i=O(12288n^2)\approx 3.8e8\) ,且输出的常数很大。
for(j=0;j<248;j++){
printf("mkdir -p ");
for(i=0;i<2048;i++)printf("a/");
puts("");
printf("cd ");
for(i=0;i<2048;i++)printf("a/");
puts("");
}
printf("fwrite \"a\" file\n");
printf("cd /\n");
printf("info .\n");
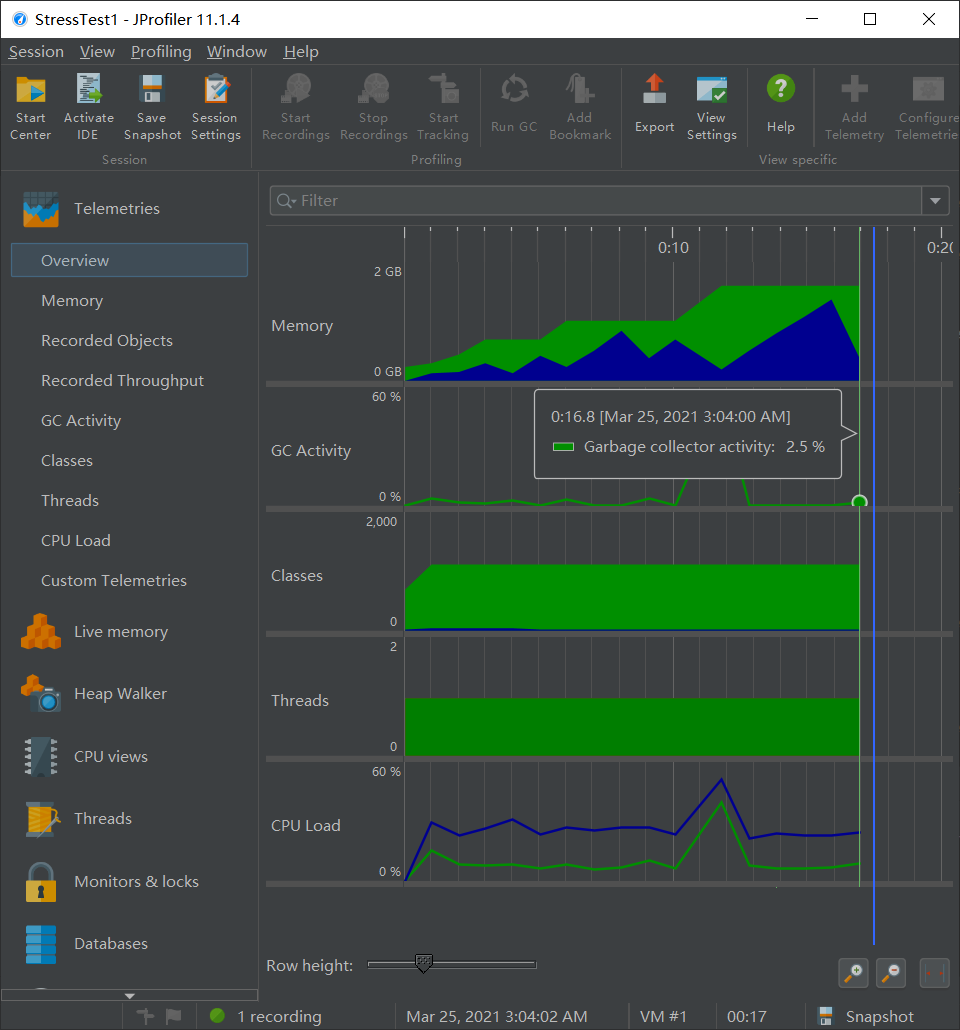
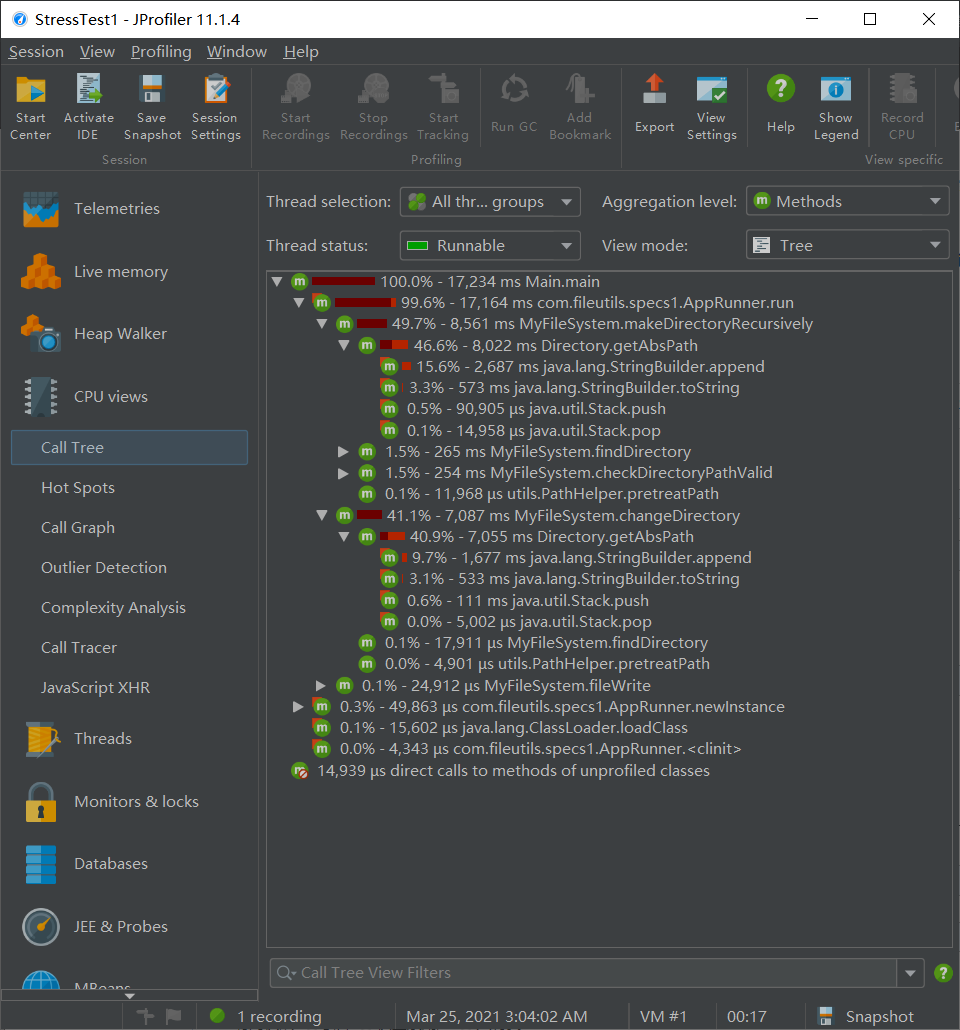
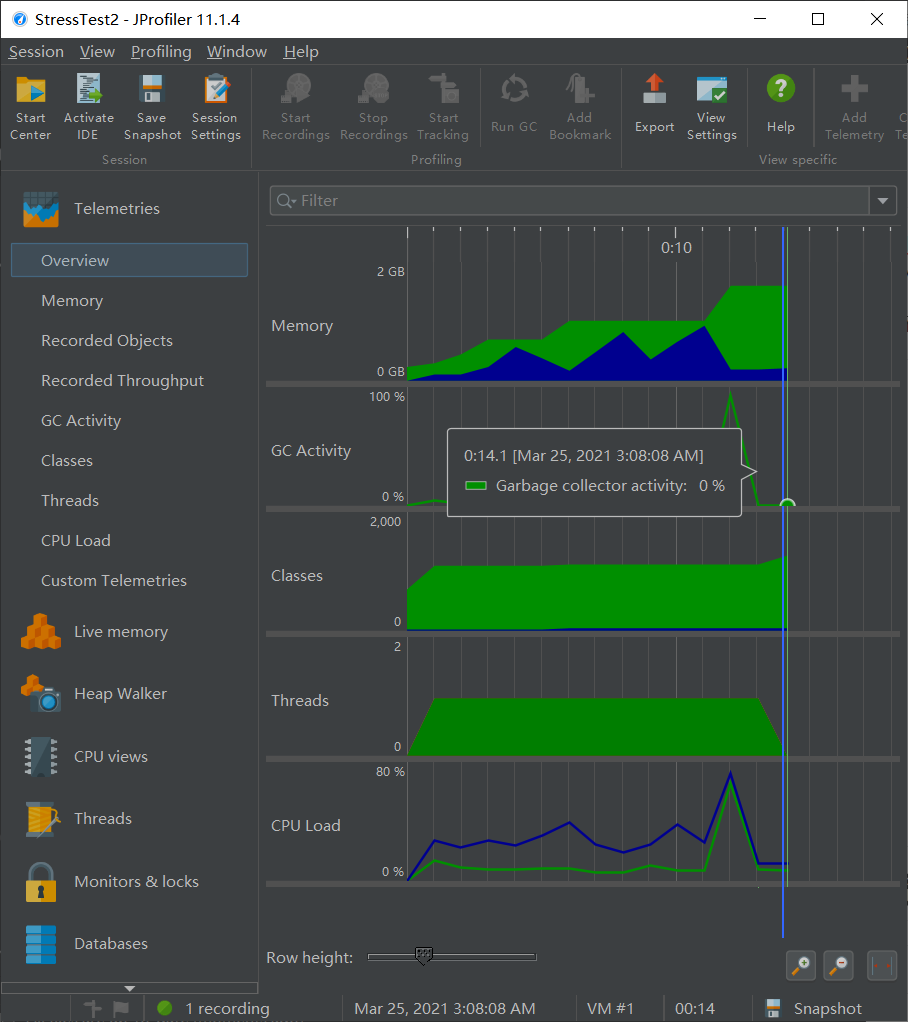
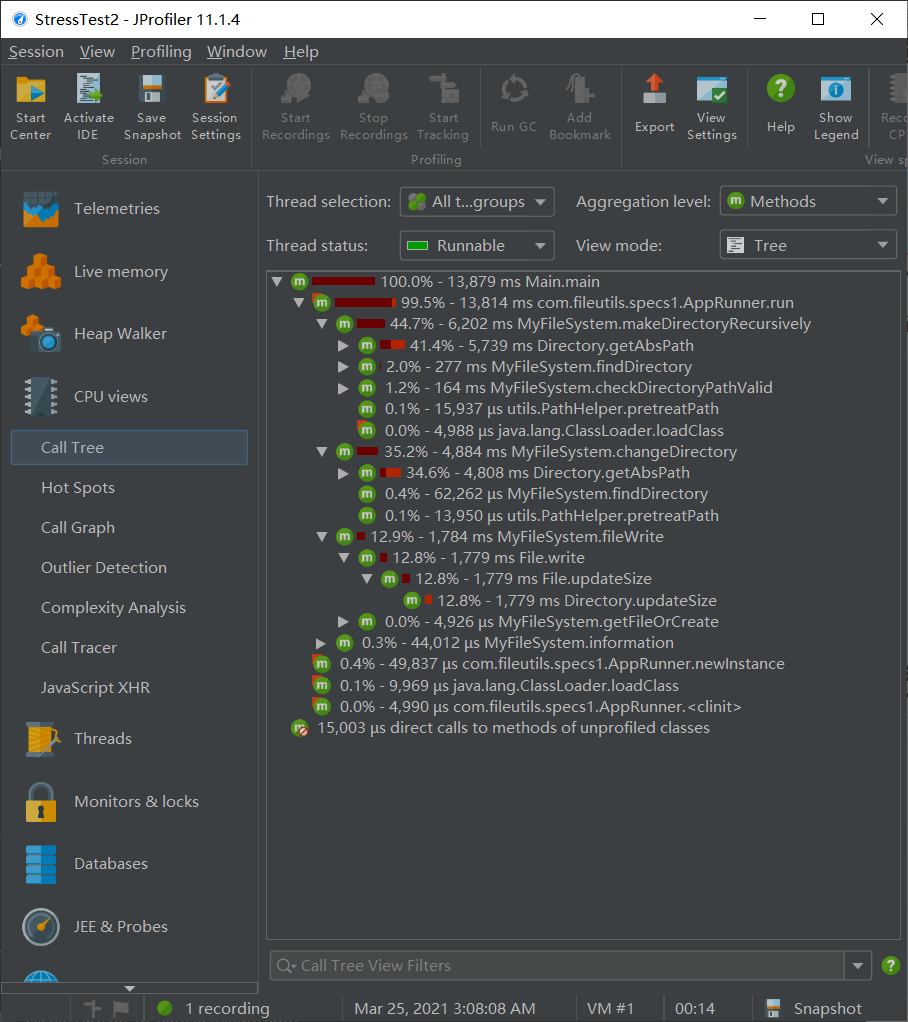
JProfiler 测试:程序正常运行结束,16.8s 执行完毕,CPU Time 几乎全部来源于 getAbsPath。
在最初的设计中,其中的字符串拼接使用了 StringBuilder 的 insert 功能(每次 \(O(m+n)\)),导致 30min 才跑完本测试;修改拼接顺序之后使用 append(每次 \(O(n)\)),得到了明显的效率提升。
 |
 |
第二份数据
大量 mkdir -p 和 cd;同时利用 size 缓存的特性,在最深处创建文件,使得递归调用更新文件大小而获得较高的时间复杂度。
设一共 mkdir cd P 组,则剩余 Q=500-2P 次指令进行 fwrite。
两部分理论复杂度都是 \(O(Tn)\),总复杂度为 \(C_1\times6144P(P+1)+C_2\times 2048P\)。
在此分别取 P=125 Q=247,P=200 Q=97 进行试验:
for(j=0;j<P;j++){
printf("mkdir -p ");
for(i=0;i<2048;i++)printf("a/");
puts("");
printf("cd ");
for(i=0;i<2048;i++)printf("a/");
puts("");
}
for(j=0;j<Q;j++){
printf("fwrite \"");
printf("a"); // length limit?
printf("\" file%d\n",j);
}
printf("info .\n");
printf("cd /\n");
printf("info .\n");
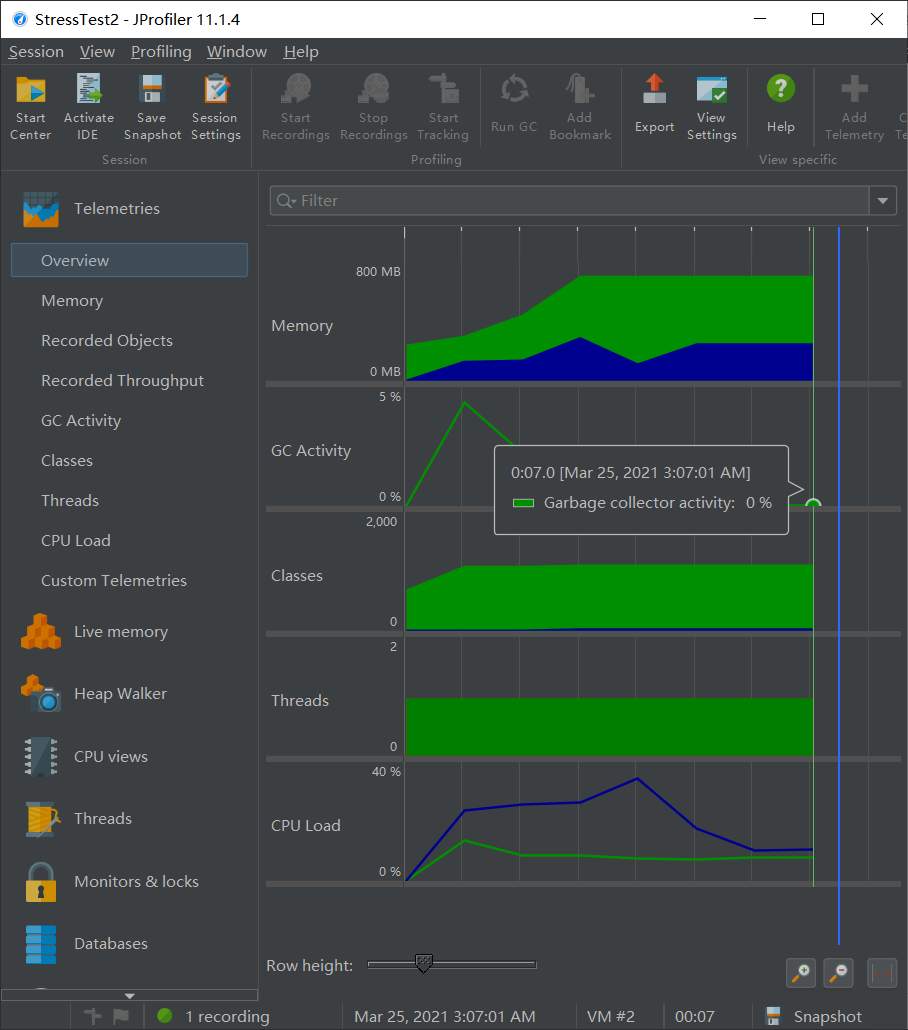
JProfiler 测试:分别 7.0s,14.1s 执行完毕,前者的 CPU 和内存消耗均较小,说明更新 size 部分常数比较小,从 CPU 调用树分析也能看出这一点。
在最初的设计中,getSize 是递归实现的,测试进行到一半就触发爆栈,故改为了循环,修复了问题。
 |
 |
 |
预估和实际耗时
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 50 |
| · Design Spec | · 生成设计文档 | 10 | 9 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 9 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 10 | 12 |
| · Coding | · 具体编码 | 400 | 480 |
| · Code Review | · 代码复审 | 30 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 220 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 10 | 10 |
| · Size Measurement | · 计算工作量 | 20 | 12 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 765 | 852 |
其中,对于代码具体编码时间的估计误差较大,主要原因是低估了细节的实现难度;但编码时对于代码充足的约定和清晰的思路使得代码复审花费几乎不费时间。
需求分析做的时间大概半小时,但学习新技术(包括如何下载解压、装载到 maven 上使用 CI 测试覆盖率)占用时间较多,因此也比预期时间更多一些。
实际上,在所有问题做完之后,还根据指导书的更新和 issue 区的需求、以及对下一次可能需求的发展方向进行了大量的分析、开发和测试,但是没有每次进行计时,故没有计入到表格中。大概估计一下可能也有 500 分钟左右。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号