Deep Learning 阅读笔记:Convolutional Auto-Encoders 卷积神经网络的自编码表达
需要搭建一个比较复杂的CNN网络,希望通过预训练来提高CNN的表现。
上网找了一下,关于CAE(Convolutional Auto-Encoders)的文章还真是少,勉强只能找到一篇瑞士的文章、
Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction
干货少,不过好歹有对模型的描述,拿来看看。

概述:
本文提出了一种卷积神经网络的自编码表达,用于对卷积神经网络进行预训练。
具体内容:
原文废话挺多,我只关心模型——CAE:
卷积层的获得: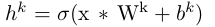
再表达: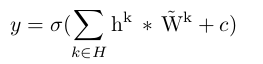
其中“ * ”表示卷积;再表达的系数矩阵![]() 是卷积矩阵
是卷积矩阵![]() 在两个维度上的翻转(rot180)。
在两个维度上的翻转(rot180)。
关于CAE的具体结构论文讲得不清不楚(果真是水),这里有两个明显的问题:一是两次用同样大小卷积核做的卷积如何恢复原来图像的大小,论文中提到full convolution和valid convolution,大概是指两次卷积的卷积方法不同;另一个就是用卷积核的反转卷积隐藏层的意义和作用何在,这个实在是无端端冒出来的计算方法;
输出的误差使用均方误差MSE:
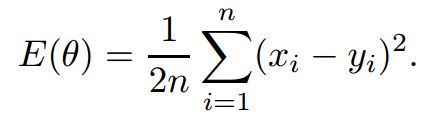
偏导的求法:
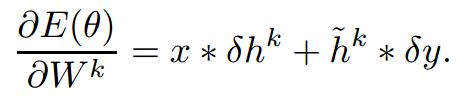
deltaH和deltaY分别是隐藏层和输出层的敏感度。这里又有问题:只有一个隐藏层怎么来敏感度?如果是反向传播怎么传播过去?论文此处的“ * ”还是代表的是卷积吗?如果是的话用的是full还是valid?为什么用隐藏层和敏感度做运算而不是卷积核?这个公式到底怎么来的?(天到底是我太水还是论文太渣)
接着论文提到了在非监督学习下的non-overlapping maxpooling。说这东西真是厉害,maxpooling抹去了区域非最大值,因此引入稀疏性。强大到甚至连稀疏性惩罚项都不用就可以获得好结果。(你给我讲清楚为什么啊喂!)
试验结果:
论文使用MNIST和CIFAR10数据库各做了4组实验,每组训练20个features,结果如下:
MNIST:

CIFAR10:

其中a)是简单的CAE,b)引入了30%噪声,C)引入maxpooling,D)引入maxpooling和30%噪声。
单从这两组结果来看有maxpooling的CAE,通过训练获得较好特征。
与其他方法对比:
文中最后利用CAE做pretraining训练一个6层隐藏层的CNN,与无pretraining的CNN相比,其实提高不明显。
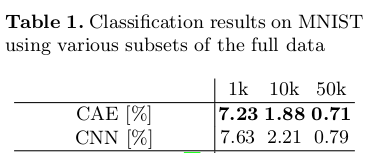

感想:看完这篇文章对我想构建的CAE貌似没有太大的帮助,因为此文章在实践方面的细节和数学过程的推导都是一笔带过,没有详尽描述。(到底是我水还是文章水)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号