

hive基本概念
Hive
一 Hive基本概念
1 Hive简介 
1.1 什么是 Hive
- Hive 由 Facebook 实现并开源,是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能,底层数据是存储在 HDFS 上。
- Hive 本质: 将 SQL 语句转换为 MapReduce 任务运行,使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,是一款基于 HDFS 的 MapReduce 计算框架
- 主要用途:用来做离线数据分析,比直接用 MapReduce 开发效率更高。
2 Hive 架构
2.1 Hive 架构图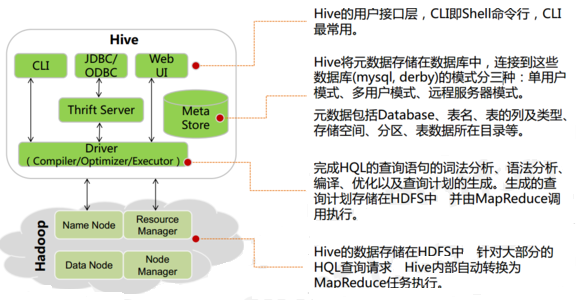
2.2 Hive 组件
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- CLI(command line interface)为 shell 命令行
- JDBC/ODBC 是 Hive 的 JAVA 实现,与传统数据库JDBC 类似
- WebGUI 是通过浏览器访问 Hive。
- HiveServer2基于Thrift, 允许远程客户端使用多种编程语言如Java、Python向Hive提交请求
- 元数据存储:通常是存储在关系数据库如 mysql/derby 中。
- Hive 将元数据存储在数据库中。
- Hive 中的元数据包括
- 表的名字
- 表的列
- 分区及其属性
- 表的属性(是否为外部表等)
- 表的数据所在目录等。
- 解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行
2.3 Hive 与 Hadoop 的关系
Hive 利用 HDFS 存储数据,利用 MapReduce 查询分析数据。
Hive是数据仓库工具,没有集群的概念,如果想提交Hive作业只需要在hadoop集群 Master节点上装Hive就可以了
3 Hive 与传统数据库对比
- hive 用于海量数据的离线数据分析。
| Hive | 关系型数据库 | |
|---|---|---|
| ANSI SQL | 不完全支持 | 支持 |
| 更新 | INSERT OVERWRITE\INTO TABLE(默认) | UPDATE\INSERT\DELETE |
| 事务 | 不支持(默认) | 支持 |
| 模式 | 读模式 | 写模式 |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 子查询 | 只能用在From子句中 | 完全支持 |
| 处理数据规模 | 大 | 小 |
| 可扩展性 | 高 | 低 |
| 索引 | 0.8版本后加入位图索引 | 有复杂的索引 |
- hive支持的数据类型
- 原子数据类型
- TINYINT SMALLINT INT BIGINT BOOLEAN FLOAT DOUBLE STRING BINARY TIMESTAMP DECIMAL CHAR VARCHAR DATE
- 复杂数据类型
- ARRAY
- MAP
- STRUCT
- 原子数据类型
- hive中表的类型
- 托管表 (managed table) (内部表)
- 外部表
4 Hive 数据模型
- Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式
- 在创建表时指定数据中的分隔符,Hive 就可以映射成功,解析数据。
- Hive 中包含以下数据模型:
- db:在 hdfs 中表现为 hive.metastore.warehouse.dir 目录下一个文件夹
- table:在 hdfs 中表现所属 db 目录下一个文件夹
- external table:数据存放位置可以在 HDFS 任意指定路径
- partition:在 hdfs 中表现为 table 目录下的子目录
- bucket:在 hdfs 中表现为同一个表目录下根据 hash 散列之后的多个文件
5 Hive 安装部署
-
Hive 安装前需要安装好 JDK 和 Hadoop。配置好环境变量。
-
下载Hive的安装包 http://archive.cloudera.com/cdh5/cdh/5/ 并解压
tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app/ -
进入到 解压后的hive目录 找到 conf目录, 修改配置文件
cp hive-env.sh.template hive-env.sh vi hive-env.sh在hive-env.sh中指定hadoop的路径
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0 -
配置环境变量
-
vi ~/.bash_profile -
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0 export PATH=$HIVE_HOME/bin:$PATH -
source ~/.bash_profile
-
二 Hive 基本操作
2.1 Hive HQL操作初体验
-
创建数据库
CREATE DATABASE test; -
显示所有数据库
SHOW DATABASES; -
创建表
CREATE TABLE student(classNo string, stuNo string, score int) row format delimited fields terminated by ',';- row format delimited fields terminated by ',' 指定了字段的分隔符为逗号,所以load数据的时候,load的文本也要为逗号,否则加载后为NULL。hive只支持单个字符的分隔符,hive默认的分隔符是\001
-
将数据load到表中
-
在本地文件系统创建一个如下的文本文件:/home/hadoop/tmp/student.txt
C01,N0101,82 C01,N0102,59 C01,N0103,65 C02,N0201,81 C02,N0202,82 C02,N0203,79 C03,N0301,56 C03,N0302,92 C03,N0306,72 -
load data local inpath '/home/hadoop/tmp/student.txt'overwrite into table student; -
这个命令将student.txt文件复制到hive的warehouse目录中,这个目录由hive.metastore.warehouse.dir配置项设置,默认值为/user/hive/warehouse。Overwrite选项将导致Hive事先删除student目录下所有的文件, 并将文件内容映射到表中。
Hive不会对student.txt做任何格式处理,因为Hive本身并不强调数据的存储格式。
-
-
查询表中的数据 跟SQL类似
hive>select * from student; -
分组查询group by和统计 count
hive>select classNo,count(score) from student where score>=60 group by classNo;从执行结果可以看出 hive把查询的结果变成了MapReduce作业通过hadoop执行
2.2 Hive的内部表和外部表
| 内部表(managed table) | 外部表(external table) | |
|---|---|---|
| 概念 | 创建表时无external修饰 | 创建表时被external修饰 |
| 数据管理 | 由Hive自身管理 | 由HDFS管理 |
| 数据保存位置 | hive.metastore.warehouse.dir (默认:/user/hive/warehouse) | hdfs中任意位置 |
| 删除时影响 | 直接删除元数据(metadata)及存储数据 | 仅会删除元数据,HDFS上的文件并不会被删除 |
| 表结构修改时影响 | 修改会将修改直接同步给元数据 | 表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;) |
-
案例
- 创建一个外部表student2
CREATE EXTERNAL TABLE student2 (classNo string, stuNo string, score int) row format delimited fields terminated by ',' location '/tmp/student';-
装载数据
load data local inpath '/home/hadoop/tmp/student.txt' overwrite into table student2;
-
显示表信息
desc formatted table_name; -
删除表查看结果
drop table student; -
再次创建外部表 student2
-
不插入数据直接查询查看结果
select * from student2;
2.3 分区表
-
什么是分区表
- 随着表的不断增大,对于新纪录的增加,查找,删除等(DML)的维护也更加困难。对于数据库中的超大型表,可以通过把它的数据分成若干个小表,从而简化数据库的管理活动,对于每一个简化后的小表,我们称为一个单个的分区。
- hive中分区表实际就是对应hdfs文件系统上独立的文件夹,该文件夹内的文件是该分区所有数据文件。
- 分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。
- 分类的标准就是分区字段,可以一个,也可以多个。
- 分区表的意义在于优化查询。查询时尽量利用分区字段。如果不使用分区字段,就会全部扫描。
-
创建分区表
tom,4300 jerry,12000 mike,13000 jake,11000 rob,10000create table employee (name string,salary bigint) partitioned by (date1 string) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile; -
查看表的分区
show partitions employee; -
添加分区
alter table employee add if not exists partition(date1='2018-12-01'); -
加载数据到分区
load data local inpath '/home/hadoop/tmp/employee.txt' into table employee partition(date1='2018-12-01'); -
如果重复加载同名文件,不会报错,会自动创建一个*_copy_1.txt
-
外部分区表即使有分区的目录结构, 也必须要通过hql添加分区, 才能看到相应的数据
hadoop fs -mkdir /user/hive/warehouse/emp/dt=2018-12-04 hadoop fs -copyFromLocal /tmp/employee.txt /user/hive/warehouse/test.db/emp/dt=2018-12-04/employee.txt-
此时查看表中数据发现数据并没有变化, 需要通过hql添加分区
alter table emp add if not exists partition(dt='2018-12-04'); -
此时再次查看才能看到新加入的数据
-
-
总结
- 利用分区表方式减少查询时需要扫描的数据量
- 分区字段不是表中的列, 数据文件中没有对应的列
- 分区仅仅是一个目录名
- 查看数据时, hive会自动添加分区列
- 支持多级分区, 多级子目录
- 利用分区表方式减少查询时需要扫描的数据量
2.4 动态分区
-
在写入数据时自动创建分区(包括目录结构)
-
创建表
create table employee2 (name string,salary bigint) partitioned by (date1 string) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile; -
导入数据
insert into table employee2 partition(date1) select name,salary,date1 from employee; -
使用动态分区需要设置参数
set hive.exec.dynamic.partition.mode=nonstrict;







