DP专题-学习笔记:Slope Trick
1. 前言
Slope Trick,是一种优化 DP 的方式,这个方式目前好像并不盛行,但是以前好像还挺流行的(?),网上讲 Slope Trick 的博客好像也不多(?)。
- (?) 表示笔者持怀疑态度,也就是说这句话可能是错的。
现在笔者得知的能够使用 Slope Trick 的题目并不多,这里主要讲 CF 的一道题,好像是已知的 Slope Trick 最早出现的时间(2016 年)(?)。
注意 Slope Trick 不是斜率优化 dp,这两个是不同的算法。
2. 详解
先放例题:CF713C Sonya and Problem Wihtout a Legend。
简要题意:给定 个正整数 ,每次操作可以将任意一个元素加一或减一,问使得原序列严格递增的最小操作次数。
当然我们需要加强到 ,否则这个能用 DP 暴力解决。
首先发现严格递增这个东西我们有一个套路的方式就是令 ,于是这样就变成了严格不降。
然后我们有一个简略的 DP 方程:
设 表示将 变成 ,使得 的数列不降所需要的最小操作次数,那么有:
这个 DP 方程还是比较简单的吧~
这样,我们就能够在 的复杂度内赛时解决这道题,当然在 的情况下是过不了的。
此时 Slope Trick 就可以派上用场了。
首先我们需要知道 Slope Trick 能够优化什么问题:通常情况下,Slope Trick 能够解决的是一类凸函数问题。
啥意思呢?
比如说这道题的 DP 方程,我们首先转变一下式子:记 为 ,定义 。
那么式子就是 。
然后仔细研究这个函数,我们会发现这个函数有下凸性质,画出来大概是这个样子:
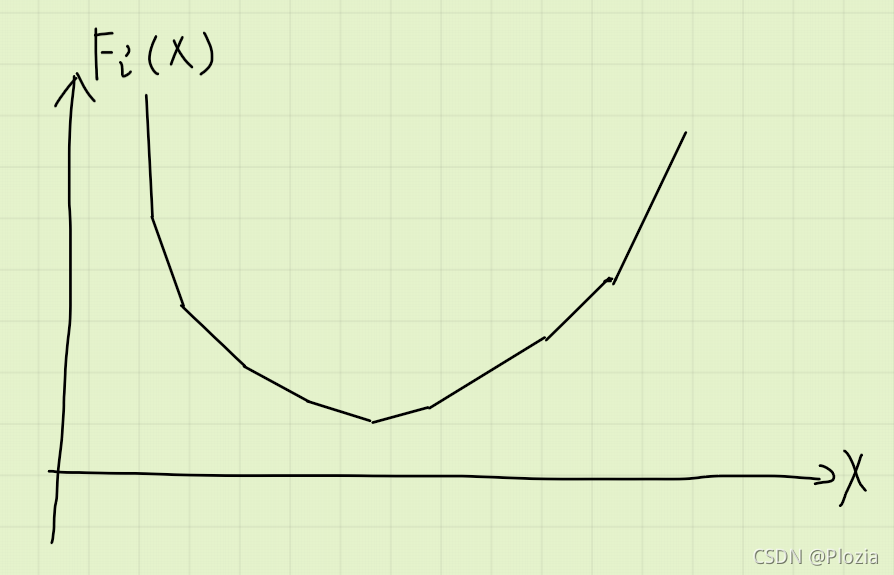
需要注意的是,前面 递减部分确实是个下凸包,但是后半部分不一定。
我们记 表示当 时 ,也就是函数 取到最小值的地方。
然后我们重新看一下这个方程:。
我们发现这个式子很有意思:我们只需要快速维护 就可以了。
具体怎么维护呢?
其实对于这种分段函数且各函数都是一次函数的情况下,有一种快速的方法维护最小值:维护所有分段点以及最右端一次函数即可。
比如说还是上图,可以发现我们只需要维护下图的红点和红线即可:
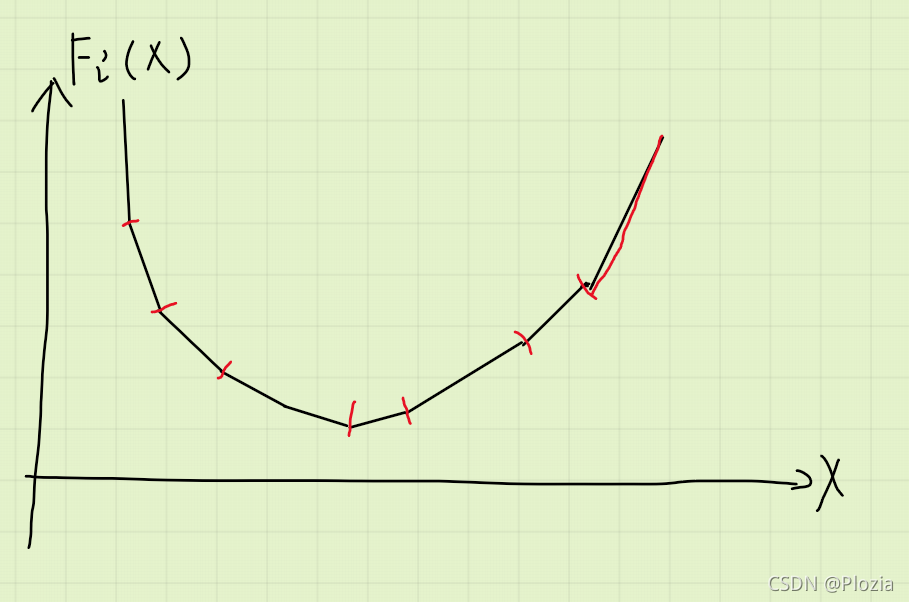
特别需要注意的是如果两个相邻段的斜率之差大于 1,那么这个关键点是要存两遍的。
那么现在我们来讨论如何通过所有已知的 和 来快速维护 。
有几个关键点:
- 我们画出 的大致图像后,结合状态转移方程,发现在 前的所有函数斜率递减,在 之后的所有函数斜率递增。
- 其实 是在 上的叠加。
- 处这个点左右两个函数的斜率一个是正的,一个是负的。
- 实际上所有斜率为正的点在计算的时候是无用的,因为我们的转移是从 转移到 ,所以我们需要 数据的时候完全可以直接从 推过来。
根据上面的第四点,我们只需要维护所有左边的函数斜率小于 0 的关键点即可,也就是下面这些蓝色的点:
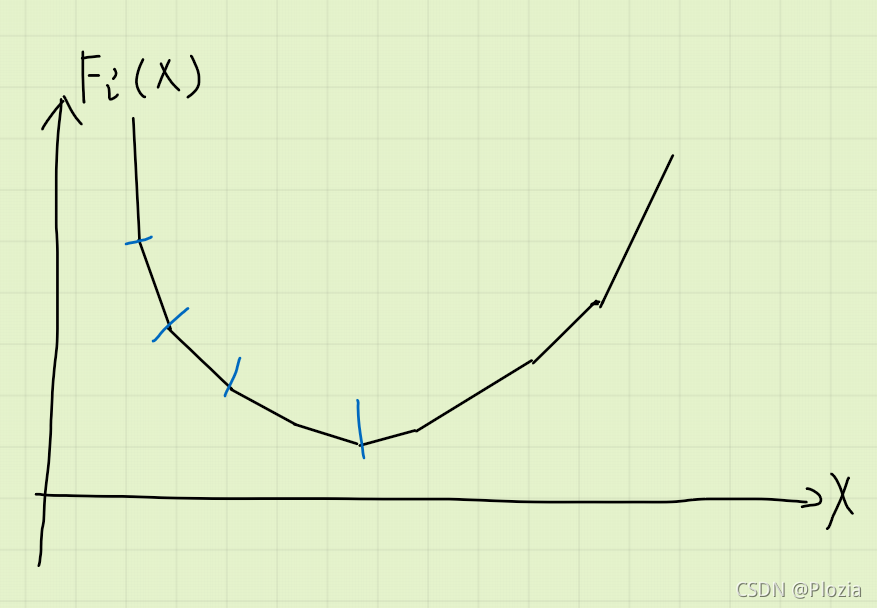
然后我们讨论一下 和 的关系:
这个情况下你会发现,我们在函数叠加的时候,所有 的点其纵坐标之差加一,用式子表达就是所有 都降低了 1,从斜率角度来看就是斜率全部递减 1。
从贪心的角度来理解,此时此刻你没必要将 减小到 ,因为这个时候 ,肯定是当前最优的解。
至于如果后面的 远小于 ,那就是另外一个情况要讨论的事情了。
于是我们只需要将 这个点丢进我们的关键点里面,然后这个点就做完了。
这个时候我们发现我们需要将 提升到 才能够做到序列单调不降,因此这一块的贡献是 。
然后我们发现对于所有 ,所有 都降低了 1,而对于所有 ,,所有 都升高了 1,这个同样也能从斜率角度来理解。
此时我们发现在 这个关键点出现了问题,因为这个时候整个函数已经被改变了,由于 ,此时 这个地方左右斜率相差大于 1 了,因此我们需要将 两次丢进我们的关键点里面。
最后将 丢出队列,因为这个时候在 这个地方因为 的影响使得最后的位置斜率升高了,这个点不再是我们的最小值点了(),所以我们需要将 丢出队列。
有人可能会问:会不会存在在一个同样的值 出现 4 个或者更多的关键点都是 呢?
这个情况吗……emm……确实是存在的,但是我们需要知道这道题的一个显然结论:
- 将 改到 和将 改到 的贡献是一样的。
据此,实际上我们会发现将 改成两者较小一定是更优的,因为这样后面的一些小数就可以花费较少的花费达到严格不降得目的。
↑上述问题其实也是我在学习的时候遇到的一个问题。
现在讨论完了两种情况,我们发现实际上我们只需要维护一个优先队列就可以完成快速维护关键点的工作。
而快速维护关键点实质上就是快速维护 ,也就是快速得到 。
那么最后答案当然就是 啦~
实际操作的时候我们不需要另外开一个 f[] 来存下所有的 (对的,是这玩意),只需要一个 ans 算贡献就好,因为我们的全部过程只需要利用到 的相关信息。
代码如下:
/*
========= Plozia =========
Author:Plozia
Problem:CF713C Sonya and Problem Wihtout a Legend
Date:2021/9/22
========= Plozia =========
*/
#include <bits/stdc++.h>
using std::priority_queue;
typedef long long LL;
const int MAXN = 3000 + 5;
int n, a[MAXN];
LL ans = 0;
priority_queue <LL> q;
int Read()
{
int sum = 0, fh = 1; char ch = getchar();
for (; ch < '0' || ch > '9'; ch = getchar()) fh -= (ch == '-') << 1;
for (; ch >= '0' && ch <= '9'; ch = getchar()) sum = (sum * 10) + (ch ^ 48);
return sum * fh;
}
int Max(int fir, int sec) { return (fir > sec) ? fir : sec; }
int Min(int fir, int sec) { return (fir < sec) ? fir : sec; }
int main()
{
n = Read();
for (int i = 1; i <= n; ++i) a[i] = Read() - i;
for (int i = 1; i <= n; ++i)
{
q.push(a[i]);
if (q.top() > a[i])
{
ans += q.top() - a[i];
q.pop(); q.push(a[i]);
}
}
printf("%lld\n", ans);
return 0;
}
3. 总结
Slope Trick 通常解决的是这样一类问题:
- DP 中维护的 数据具有凸性。
- 可以通过维护关键点和最右端的一次函数来快速处理最大/最小值。
推荐练习题:P3642 [APIO2016]烟火表演。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析