机器学习--DIY笔记与感悟--①K-临近算法
##“计算机出身要紧跟潮流”
机器学习作为如今发展的趋势需要被我们所掌握。而今我也需要开始learn机器学习,并将之后的所作所想记录在此。
今天我开始第一课--K临近算法。
一、k-临近的基础概念理解
学习开始前,我将用最简单的话来解释k-临近算法的思想。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
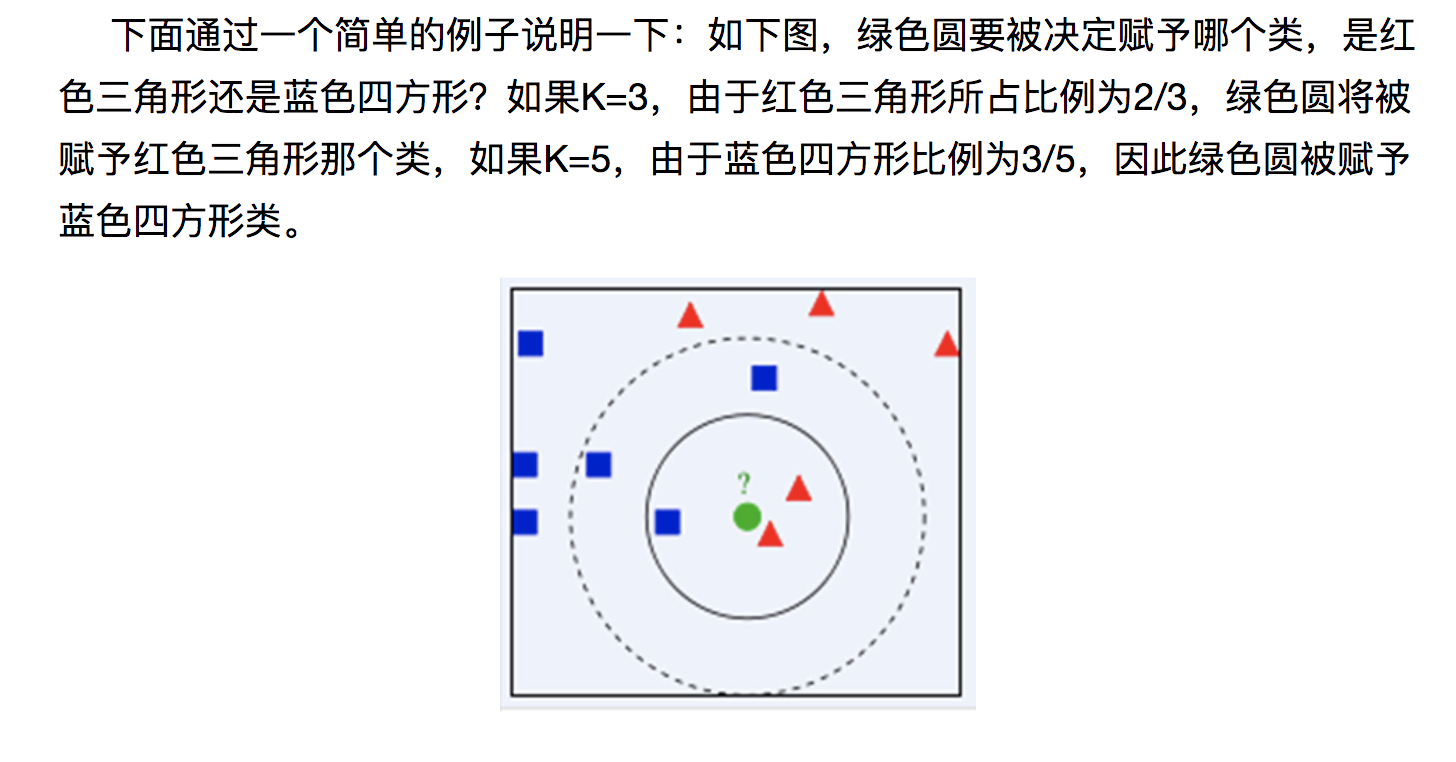
简单来说,当我们有一定数量的训练值后(例如 Y1(a,b),Y2(c,d),Y3(e,f).....这些数据属于不同的类型)我们就可以把这些点画到二维坐标系中,然后当你拿到一个新的未知数据类型的数据时,你可以把X(x1,x2)放到坐标系上,并测出未知量X与坐标系中所有点的距离,取最近的k个点(这个k是你自己设置的)。之后取这K个值中类型占比最大的那一个作为未知X的类型。
下面是算法的流程总结:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
二、KNN算法设计
这里首先将这个基础的knn算法用python写出来,我这里使用了python-2.7.10的版本。
这里是用了knn算法,测试样例是四个电影,共有两种类型,每种电影均有两个参数(电影中打斗次数与亲吻次数---二维的数据)。
最终实现给出某一部电影的打斗次数+亲吻次数来预测这是什么类型的电影。
#coding:utf-8 import operator import numpy as np def createData(): group = np.array([[1,101],[5,89],[108,5],[115,8]]) labels = ['爱情片','爱情片','动作片','动作片'] return group, labels #----------------------------- def classfy(X,dataArray,labels,k): dataSize = dataArray.shape[0] #传入dataArray二维数组的行数 diffMat = np.tile(X,(dataSize,1)) - dataArray #tile函数是将X这个数组以在二维里重复datasize次:https://docs.scipy.org/doc/numpy/reference/generated/numpy.tile.html squareMat = diffMat**2 #将diffMat平方(为了算距离) square_add_Mat = squareMat.sum(axis=1) #axis=1就是将一个矩阵的每一行向量相加,例如a = np.array([[0, 2, 1]]),print a.sum(axis=1)得到[3](0+1+2) distances = square_add_Mat**0.5 #这样就得到了X点与坐标中所有点的距离数组----((X1-X2)^2+(Y1-Y2)^2)^0.5 sortDistances = distances.argsort() #将distances从小到大排列出来,返回索引值 arrayLength = len(sortDistances) #数据量的个数 classCount = {} for i in range(k): currentLabel = labels[sortDistances[i]] classCount[currentLabel] = classCount.get(currentLabel,0) + 1 #classCount中放的是键值对,键(为label),值(为出现的次数),get为得到当前classcount数组中为currentLabel这个键的值。 sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True) #http://www.runoob.com/python/python-func-sorted.html 这是sorted的具体用法。 #classCount.iteritems()为将classCount变为字典;key=operator.itemgetter(1)为以第二个参数为基准进行排序(这里指的就是键值对里的值,既按照出现的次数进行排序)。 return sortedClassCount[0][0] #返回结果 #------------------------------------- if __name__ == '__main__': group, labels = createData() #创建数据 test = [101,20] k = 3 #knn的k值,可以自行设计 test_process = classfy(test,group,labels,k) print test_process
结果得到
三、具体实战(由现有数据预测约会成功率)
背景:
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。
海伦收集的样本数据主要包含以下3种特征:
- 每年获得的飞行常客里程数
- 玩视频游戏所消耗时间百分比
- 每周消费的冰淇淋公升数
数据具体样子:

所以我们要根据前三列数据与最后一列的结果来预测女主对一个全新数据的态度。
①第一步,我们要将这个txt文档处理为我们能使用的格式:
def fileToUseful(filename): f = open(filename) fLines = f.readlines() fLinesRows = len(fLines) Arrays = np.zeros((fLinesRows,3)) #zeros是用来创建fLinesRows行3列的全0矩阵 classLabel = [] #从来储存第三列的“喜欢与否”的标签 index = 0 for line in fLines: line = line.strip() line = line.split('\t') #将line中的'\n'、空格均去掉 Arrays[index,:] = line[0:3] #将line中前3个数保存到Array的第index行中 if line[-1] == 'didntLike': classLabel.append(1) if line[-1] == 'smallDoses': classLabel.append(2) if line[-1] == 'largeDoses': classLabel.append(3) index += 1 return Arrays,classLabel #----将txt文档中数据处理为可利用----
得到了结果

。。。是中间省略了其他的许多组数据
下面是将喜欢与否的三种结果抽象化为数字:
[3, 2, 1, 1, 1, 1, 3, 3, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1, 2, 3, 2, 1, 2, 3, 2, 3, 2, 3, 2, 1, 3, 1, 3, 1, 2, 1, 1, 2, 3, 3, 1, 2, 3, 3, 3, 1, 1, 1, 1, 2, 2, 1, 3, 2, 2, 2, 2, 3, 1, 2, 1, 2, 2, 2, 2, 2, 3, 2, 3, 1, 2, 3, 2, 2, 1, 3, 1, 1, 3, 3, 1, 2, 3, 1, 3, 1, 2, 2, 1, 1, 3, 3, 1, 2, 1, 3, 3, 2, 1, 1, 3, 1, 2, 3, 3, 2, 3, 3, 1, 2, 3, 2, 1, 3, 1, 2, 1, 1, 2, 3, 2, 3, 2, 3, 2, 1, 3, 3, 3, 1, 3, 2, 2, 3, 1, 3, 3, 3, 1, 3, 1, 1, 3, 3, 2, 3, 3, 1, 2, 3, 2, 2, 3, 3, 3, 1, 2, 2, 1, 1, 3, 2, 3, 3, 1, 2, 1, 3, 1, 2, 3, 2, 3, 1, 1, 1, 3, 2, 3, 1, 3, 2, 1, 3, 2, 2, 3, 2, 3, 2, 1, 1, 3, 1, 3, 2, 2, 2, 3, 2, 2, 1, 2, 2, 3, 1, 3, 3, 2, 1, 1, 1, 2, 1, 3, 3, 3, 3, 2, 1, 1, 1, 2, 3, 2, 1, 3, 1, 3, 2, 2, 3, 1, 3, 1, 1, 2, 1, 2, 2, 1, 3, 1, 3, 2, 3, 1, 2, 3, 1, 1, 1, 1, 2, 3, 2, 2, 3, 1, 2, 1, 1, 1, 3, 3, 2, 1, 1, 1, 2, 2, 3, 1, 1, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2, 3, 2, 3, 3, 3, 3, 1, 2, 3, 1, 1, 1, 3, 1, 3, 2, 2, 1, 3, 1, 3, 2, 2, 1, 2, 2, 3, 1, 3, 2, 1, 1, 3, 3, 2, 3, 3, 2, 3, 1, 3, 1, 3, 3, 1, 3, 2, 1, 3, 1, 3, 2, 1, 2, 2, 1, 3, 1, 1, 3, 3, 2, 2, 3, 1, 2, 3, 3, 2, 2, 1, 1, 1, 1, 3, 2, 1, 1, 3, 2, 1, 1, 3, 3, 3, 2, 3, 2, 1, 1, 1, 1, 1, 3, 2, 2, 1, 2, 1, 3, 2, 1, 3, 2, 1, 3, 1, 1, 3, 3, 3, 3, 2, 1, 1, 2, 1, 3, 3, 2, 1, 2, 3, 2, 1, 2, 2, 2, 1, 1, 3, 1, 1, 2, 3, 1, 1, 2, 3, 1, 3, 1, 1, 2, 2, 1, 2, 2, 2, 3, 1, 1, 1, 3, 1, 3, 1, 3, 3, 1, 1, 1, 3, 2, 3, 3, 2, 2, 1, 1, 1, 2, 1, 2, 2, 3, 3, 3, 1, 1, 3, 3, 2, 3, 3, 2, 3, 3, 3, 2, 3, 3, 1, 2, 3, 2, 1, 1, 1, 1, 3, 3, 3, 3, 2, 1, 1, 1, 1, 3, 1, 1, 2, 1, 1, 2, 3, 2, 1, 2, 2, 2, 3, 2, 1, 3, 2, 3, 2, 3, 2, 1, 1, 2, 3, 1, 3, 3, 3, 1, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 3, 2, 1, 3, 3, 2, 2, 2, 3, 1, 2, 1, 1, 3, 2, 3, 2, 3, 2, 3, 3, 2, 2, 1, 3, 1, 2, 1, 3, 1, 1, 1, 3, 1, 1, 3, 3, 2, 2, 1, 3, 1, 1, 3, 2, 3, 1, 1, 3, 1, 3, 3, 1, 2, 3, 1, 3, 1, 1, 2, 1, 3, 1, 1, 1, 1, 2, 1, 3, 1, 2, 1, 3, 1, 3, 1, 1, 2, 2, 2, 3, 2, 2, 1, 2, 3, 3, 2, 3, 3, 3, 2, 3, 3, 1, 3, 2, 3, 2, 1, 2, 1, 1, 1, 2, 3, 2, 2, 1, 2, 2, 1, 3, 1, 3, 3, 3, 2, 2, 3, 3, 1, 2, 2, 2, 3, 1, 2, 1, 3, 1, 2, 3, 1, 1, 1, 2, 2, 3, 1, 3, 1, 1, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 2, 2, 2, 3, 1, 3, 1, 2, 3, 2, 2, 3, 1, 2, 3, 2, 3, 1, 2, 2, 3, 1, 1, 1, 2, 2, 1, 1, 2, 1, 2, 1, 2, 3, 2, 1, 3, 3, 3, 1, 1, 3, 1, 2, 3, 3, 2, 2, 2, 1, 2, 3, 2, 2, 3, 2, 2, 2, 3, 3, 2, 1, 3, 2, 1, 3, 3, 1, 2, 3, 2, 1, 3, 3, 3, 1, 2, 2, 2, 3, 2, 3, 3, 1, 2, 1, 1, 2, 1, 3, 1, 2, 2, 1, 3, 2, 1, 3, 3, 2, 2, 2, 1, 2, 2, 1, 3, 1, 3, 1, 3, 3, 1, 1, 2, 3, 2, 2, 3, 1, 1, 1, 1, 3, 2, 2, 1, 3, 1, 2, 3, 1, 3, 1, 3, 1, 1, 3, 2, 3, 1, 1, 3, 3, 3, 3, 1, 3, 2, 2, 1, 1, 3, 3, 2, 2, 2, 1, 2, 1, 2, 1, 3, 2, 1, 2, 2, 3, 1, 2, 2, 2, 3, 2, 1, 2, 1, 2, 3, 3, 2, 3, 1, 1, 3, 3, 1, 2, 2, 2, 2, 2, 2, 1, 3, 3, 3, 3, 3, 1, 1, 3, 2, 1, 2, 1, 2, 2, 3, 2, 2, 2, 3, 1, 2, 1, 2, 2, 1, 1, 2, 3, 3, 1, 1, 1, 1, 3, 3, 3, 3, 3, 3, 1, 3, 3, 2, 3, 2, 3, 3, 2, 2, 1, 1, 1, 3, 3, 1, 1, 1, 3, 3, 2, 1, 2, 1, 1, 2, 2, 1, 1, 1, 3, 1, 1, 2, 3, 2, 2, 1, 3, 1, 2, 3, 1, 2, 2, 2, 2, 3, 2, 3, 3, 1, 2, 1, 2, 3, 1, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 1, 3, 3, 3]
②第二步,我们要将这三行数据归一化处理(就是将其归一到0~1内)
def numProcess(data): minData = data.min(0) #.min(0)为返回传入数据每列的最小值,.min(1)为每行的最小,不加参数为所有数的最小值 maxData = data.max(0) ranges = maxData - minData dataArray = np.zeros(np.shape(data)) #shape(data)---->(1000,3) 所以zeros为创建1000行3列的全0二维矩阵 rows = np.shape(data)[0] #rows是data数据的总行数 dataArray = data - np.tile(minData,(rows,1)) #所有数据-当前列中最小的(为了之后的归一),这里的1时mindata的数据在行上重复一次 dataArray = dataArray / np.tile(ranges,(rows,1)) #得到归一化数组 return dataArray,ranges,minData,rows #----将txt数据归一化----
③ 将上述测试数据与KNN算法相结合进行预测。
if __name__ == '__main__': fliePath = "/Users/c-pinging/Desktop/ML-Test/KNN-约会分析/datingTestSet.txt" data,label = fileToUseful(fliePath) #data为前三列数据,label为结果的标签值 data,ranges,mindata,rows = numProcess(data) #得到归一处理后的数据,每一列值的范围,最小值,行数 testDataCount = int(0.1 * rows) #测试数据的个数(因为机器学习要分为training—data与testing-data,所以取百分之十作为测试使用) errorCount = 0 #用来保存错误率 #print data[2:1000] for i in range(testDataCount): classfiedConsequence = KNN_1.classfy(data[i,:],data[testDataCount:],label[testDataCount:],4) print "分类结果为:",classfiedConsequence print "真实结果为:",label[i],'\n' if classfiedConsequence != label[i]: errorCount += 1 print "此Model的正确率为: %",float(testDataCount-errorCount)/float(testDataCount)*100
之后我们计算得到结果:

在实验中我将KNN算法与实战代码分为了两个py文件。下面放出全部代码:
#coding:utf-8 import numpy as np import KNN_1 def fileToUseful(filename): f = open(filename) fLines = f.readlines() fLinesRows = len(fLines) Arrays = np.zeros((fLinesRows,3)) #zeros是用来创建fLinesRows行3列的全0矩阵 classLabel = [] #从来储存第三列的“喜欢与否”的标签 index = 0 for line in fLines: line = line.strip() line = line.split('\t') #将line中的'\n'、空格均去掉 Arrays[index,:] = line[0:3] #将line中前3个数保存到Array的第index行中 if line[-1] == 'didntLike': classLabel.append(1) if line[-1] == 'smallDoses': classLabel.append(2) if line[-1] == 'largeDoses': classLabel.append(3) index += 1 print Arrays,classLabel return Arrays,classLabel #----将txt文档中数据处理为可利用---- def numProcess(data): minData = data.min(0) #.min(0)为返回传入数据每列的最小值,.min(1)为每行的最小,不加参数为所有数的最小值 maxData = data.max(0) ranges = maxData - minData dataArray = np.zeros(np.shape(data)) #shape(data)---->(1000,3) 所以zeros为创建1000行3列的全0二维矩阵 rows = np.shape(data)[0] #rows是data数据的总行数 dataArray = data - np.tile(minData,(rows,1)) #所有数据-当前列中最小的(为了之后的归一),这里的1时mindata的数据在行上重复一次 dataArray = dataArray / np.tile(ranges,(rows,1)) #得到归一化数组 return dataArray,ranges,minData,rows #----将txt数据归一化---- if __name__ == '__main__': fliePath = "/Users/c-pinging/Desktop/ML-Test/KNN-约会分析/datingTestSet.txt" data,label = fileToUseful(fliePath) #data为前三列数据,label为结果的标签值 data,ranges,mindata,rows = numProcess(data) #得到归一处理后的数据,每一列值的范围,最小值,行数 testDataCount = int(0.1 * rows) #测试数据的个数(因为机器学习要分为training—data与testing-data,所以取百分之十作为测试使用) errorCount = 0 #用来保存错误率 #print data[2:1000] for i in range(testDataCount): classfiedConsequence = KNN_1.classfy(data[i,:],data[testDataCount:],label[testDataCount:],4) print "分类结果为:",classfiedConsequence print "真实结果为:",label[i],'\n' if classfiedConsequence != label[i]: errorCount += 1 print "此Model的正确率为: %",float(testDataCount-errorCount)/float(testDataCount)*100

 浙公网安备 33010602011771号
浙公网安备 33010602011771号