JDBC基础学习
JDBC
JDBC(Java DataBase Connectivity)是Java和数据库之间的一个桥梁,是一个规范而不是一个实现,能够执行SQL语句。它由一组用Java语言编写的类和接口组成。各种不同类型的数据库都有相应的实现,
JDBC准备#
mysql-connector-java#
去网上下载Mysql的第三方类,一个jar包,放至在项目中的lib文件夹下,然后add as library执行导包
初始化驱动#
Class.forName("com.mysql.jdbc.Driver");
建立JDBC和数据库的连接#
Connection c = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/exam?characterEncoding=UTF-8", "root", "admin");
String url = "jdbc:mysql://127.0.0.1:3306/mysql_study"; String username = "root"; String password = "020304"; Connection conn = DriverManager.getConnection(url, username, password);
将JDBC数据库连接封装为一个类,使用时调用
public static Connection getConnection() throw Exception { //1.注册驱动 Class.forName("com.mysql.jdbc.Driver"); //2.获取连接 String url = "jdbc:mysql://127.0.0.1:3306/mysql_study"; String username = "root"; String password = "020304"; Connection conn = DriverManager.getConnection(url, username, password); }
JDBC的架构#
JDBC 的 API 支持两层和三层处理模式进行数据库访问,但一般的 JDBC 架构由两层处理模式组成:
- JDBC API: 提供了应用程序对 JDBC 管理器的连接。
- JDBC Driver API: 提供了 JDBC 管理器对驱动程序连接。
JDBC API 使用驱动程序管理器和数据库特定的驱动程序来提供异构(heterogeneous)数据库的透明连接。
JDBC 驱动程序管理器可确保正确的驱动程序来访问每个数据源。该驱动程序管理器能够支持连接到多个异构数据库的多个并发的驱动程序。
tips:在信息技术中异构一次通常用来形容一个包含或者组成“异构网络”的产品,所谓的“异构网络”通常是指由不同厂家的产品所组成的网络,且各个厂家产品具有互操作性。互操作性(Interoperability )又称互用性,是指不同的计算机系统、网络、操作系统和应用程序一起工作并共享信息的能力。
数据库有很多种,Oracle Database、SQL Server Database、 ODBC Data Source……不同的数据库需要不同的JDBC驱动程序(JDBC Driver),这些驱动程序又都归JDBC驱动程序管理器管理,JDBC API承担Java应用程序和JDBC驱动程序管理器的连接。
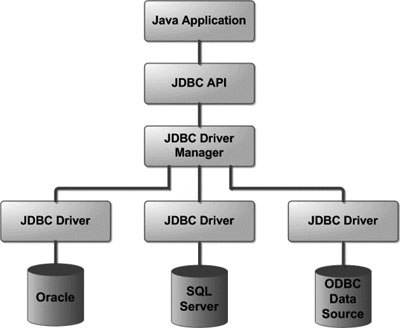
常见的JDBC组件:#
DriverManager :这个类管理一系列数据库驱动程序。匹配连接使用通信子协议从 JAVA 应用程序中请求合适的数据库驱动程序。识别 JDBC 下某个子协议的第一驱动程序将被用于建立数据库连接。通信协议是指双方实体完成通信或服务所必须遵循的规则和约定。
Driver : 这个接口处理与数据库服务器的通信。你将很少直接与驱动程序互动。相反,你使用 DriverManager 中的对象,它管理此类型的对象。它也抽象与驱动程序对象工作相关的详细信息。
Connection : 此接口具有接触数据库的所有方法。该连接对象表示通信上下文,即,所有与数据库的通信仅通过这个连接对象进行。
Statement : 使用创建于这个接口的对象将 SQL 语句提交到数据库。除了执行存储过程以外,一些派生的接口也接受参数。
ResultSet : 在你使用语句对象执行 SQL 查询后,这些对象保存从数据获得的数据。它作为一个迭代器,让您可以通过它的数据来移动。
SQLException : 这个类处理发生在数据库应用程序的任何错误。
如此看来,JDBC的执行流程就是:Connection提供与数据库的连接对象,Statement将SQL语句通过Connection提交(或者通过派生的接口进行预处理后提交,像是PreparedStatement),最后通过ResultSet进行结果信息的获取,期间类处理的异常抛出给SQLException来处理。
JDBC应用程序的创建#
构建一个 JDBC 应用程序包括以下六个步骤-
- 导入数据包:需要你导入含有需要进行数据库编程的 JDBC 类的包。大多数情况下,使用 import java.sql. * 就足够了。
- 注册 JDBC 驱动器:需要你初始化一个驱动器,以便于你打开一个与数据库的通信通道。
- 打开连接:需要使用 DriverManager.getConnection() 方法创建一个 Connection 对象,它代表与数据库的物理连接。
- 执行查询:需要使用类型声明的对象建立并提交一个 SQL 语句到数据库。
- 提取结果数据:要求使用适当的 ResultSet.getXXX() 方法从结果集中检索数据。
- 清理环境:依靠 JVM 的垃圾收集来关闭所有需要明确关闭的数据库资源。
实例代码如下:#
//第一步:引入JDBC数据包 import java.sql.*; public class FirstExample { //此为JDBC驱动器的名称和数据库的地址 static final String JDBC_DRIVER = "com.mysql.jdbc.Driver"; static final String DB_URL = "jdbc:mysql://localhost/mybook"; //此为数据库的通过信息,用户名和密码 static final String USER = "haozhi"; static final String PASS = "020304"; public static void main(String[] args) { Connection conn = null; Statement stmt = null; try { //第二步:注册JDBC驱动程序 Class.forName("com.mysql.jdbc.Driver"); //第三步:通过JDBC驱动管理器打开一个连接 System.out.println("Connecting to database..."); conn = DriverManager.getConnection(DB_URL, USER, PASS); //第四步:创建Statement接口,存储并提交SQL语句 System.out.println("Creating statement"); stmt = conn.createStatement(); String sql = "select * from book"; //第五步:创建ResultSet接口用于查询信息的接受 ResultSet rs = stmt.executeQuery(sql); while (rs.next()) { //通过列名获取每一行的数据 int id = rs.getInt("id"); int typeId = rs.getInt("typeId"); int stock = rs.getInt("stock"); String name = rs.getString("name"); double price = rs.getDouble("price"); String desc = rs.getString("desc"); String publish = rs.getString("publish"); String author = rs.getString("author"); String address = rs.getString("address"); //打印结果 System.out.println(id + "||" + typeId + "||" + stock + "||" + name + "||" + price + "||" + desc + "||" + publish + "||" + author + "||" + address); } //第六步:清除掉我们所创建的环境 rs.close(); stmt.close(); conn.close(); } catch (SQLException se) { //处理JDBC的异常 se.printStackTrace(); } catch (Exception e) { //处理Class.forName的异常 e.printStackTrace(); } finally { //最终用于关闭所以已开资源 try { if (stmt != null) stmt.close(); } catch (SQLException se2) { } try { if (conn != null) conn.close(); } catch (SQLException se) { se.printStackTrace(); } } System.out.println("GoodBye!"); } }
JDBC驱动#
JDBC驱动分类#
Java特性:平台无关性,Sun公司为了JDBC驱动的实现,要因为各种各样的操作系统和Java运行在硬件平台的不同而不同。Sun公司将实现类型分为四类。
JDBC-ODBC桥驱动程序#
ODBC
ODBC是微软公司开放的服务结构(OpenDatabaseConnectivity)它建立了一组规范,并提供了一组对数据库访问的标准API。
也就是微软公司用于建立对各类数据库的连接的工具。ODBC的最大优点是能以统一的方式处理所有的数据库。
在Windows系统中,你可以在控制面板——》windows工具中找到ODBC Data Sources(ODBC数据源),通常32位和64位都存在。
自带 JDK 1.2 中的 JDBC-ODBC 桥
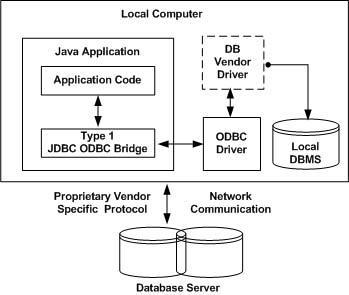
JDBC-Native API#
在类型2驱动程序中,JDBC API 调用转换成原生的 C/C++ API 调用,这对于数据库来说具有唯一性。这些驱动程序通常由数据库供应商提供,并和 JDBC-ODBC 桥驱动程序同样的方式使用。该供应商的驱动程序必须安装在每台客户机上。
如果我们改变了当前数据库,我们必须改变原生 API ,因为它是具体到某一个数据库,并且他们大多已经失效了。即使这样用类型2驱动程序也能提高一些速度,因为他消除了 ODBC 的开销。
Oracle 调用接口(OCI)驱动程序
JDBC-Net 纯Java#
在类型3驱动程序中,一般用三层方法来访问数据库。JDBC 客户端使用标准的网络套接字与中间件应用服务器进行通信。套接字的相关信息被中间件应用服务器转换为数据库管理系统所要求的的调用格式,并转发到数据库服务器。
这种驱动程序是非常灵活的,因为它不需要在客户端上安装代码,而且单个驱动程序能提供访问多个数据库。这得益于Middleware Server的职能。
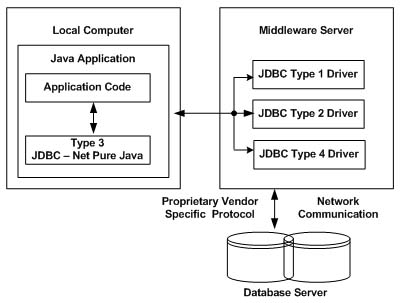
Middleware Server相当于JDBC的代理,其会调用客户端应用程序。
100%纯Java#
在类型4驱动程序中,一个纯粹的基于 Java 的驱动程序通过 socket 连接与供应商的数据库进行通信。这是可用于数据库的最高性能的驱动程序,并且通常由供应商自身提供。
这种驱动器是非常灵活的,你不需要在客户端或服务端上安装特殊的软件。此外,这些驱动程序是可以动态下载的。

MySQL Connector/J 的驱动程序是一个类型4驱动程序。因为它们的网络协议的专有属性,数据库供应商通常提供类型4的驱动程序。
JDBC驱动注册#
Class.forName()#
使用Java的Class.forName()方法可以动态加载驱动程序的类文件到内存之中,它会自动将其注册。
实例:
try { Class.forName("oracle.jdbc.driver.OracleDriver"); } catch(ClassNotFoundException ex) { System.out.println("Error: unable to load driver class!"); System.exit(1); }
你可以使用 getInstance() 方法来解决不兼容的 JVM,但你必须编写如下所示的两个额外的异常-
try { Class.forName("oracle.jdbc.driver.OracleDriver").newInstance(); } catch(ClassNotFoundException ex) { System.out.println("Error: unable to load driver class!"); System.exit(1); catch(IllegalAccessException ex) { System.out.println("Error: access problem while loading!"); System.exit(2); catch(InstantiationException ex) { System.out.println("Error: unable to instantiate driver!"); System.exit(3); }
DriverManager.registerDriver()#
你注册一个驱动程序的第二种方法是使用静态 staticDriverManager.registerDriver() 方法。
如果你使用的是不兼容 JVM 的非 JDK,比如微软提供的,你必须使用 registerDriver() 方法。
下面是使用 registerDriver() 来注册 Oracle 驱动程序的示例:
try { Driver myDriver = new oracle.jdbc.driver.OracleDriver(); DriverManager.registerDriver( myDriver ); } catch(ClassNotFoundException ex) { System.out.println("Error: unable to load driver class!"); System.exit(1); }
JDBC连接对象#
可以通过DriverManager.getConnection()方法建立一个连接,这个方法有三个重载
- getConnection(String url);
- getConnection(String url, Propetries prop);
- getConnection(String url, String user, String password);
无论哪个方法都需要一个数据库URL,不同的JDBC驱动器所对应的数据库URL不相同
| RDBMS | JDBC 驱动程序名称 | URL 格式 |
|---|---|---|
| MySQL | com.mysql.jdbc.Driver | jdbc:mysql://hostname/ databaseName |
| ORACLE | oracle.jdbc.driver.OracleDriver | jdbc:oracle:thin:@hostname:port Number:databaseName |
| DB2 | COM.ibm.db2.jdbc.net.DB2Driver | jdbc:db2:hostname:port Number/databaseName |
| Sybase | com.sybase.jdbc.SybDriver | jdbc:sybase:Tds:hostname: port Number/databaseName |
JDBC Statement对象#
JDBC 的 Statement,CallableStatement 和 PreparedStatement 接口定义的方法和属性,可以让你发送 SQL 命令或 PL/SQL 命令到数据库,并从你的数据库接收数据。在之前谈到JDBC常用组件时说到过Statement除了执行存储过程以外,一些派生的接口也接受参数。
| 接口 | 推荐使用 |
|---|---|
| Statement | 可以正常访问数据库,适用于运行静态 SQL 语句。 Statement 接口不接受参数。 |
| PreparedStatement | 计划多次使用 SQL 语句, PreparedStatement 接口运行时接受输入的参数。 |
| CallableStatement | 适用于当你要访问数据库存储过程的时候, CallableStatement 接口运行时也接受输入的参数。 |
Statement对象#
创建及关闭#
Statement stmt = null; try { stmt = conn.createStatement( ); . . . } catch (SQLException e) { . . . } finally { stmt.close(); }
创建Statement对象之后,执行SQL的返回值有三,对应三个执行方法:
- boolean execute(String SQL) : 如果 ResultSet 对象可以被检索,则返回的布尔值为 true ,否则返回 false 。当你需要使用真正的动态 SQL 时,可以使用这个方法来执行 SQL DDL 语句。
- int executeUpdate(String SQL) : 返回执行 SQL 语句影响的行的数目。使用该方法来执行 SQL 语句,是希望得到一些受影响的行的数目,例如,INSERT,UPDATE 或 DELETE 语句。
- ResultSet executeQuery(String SQL) : 返回一个 ResultSet 对象。当你希望得到一个结果集时使用该方法,就像你使用一个 SELECT 语句。
PreparedStatement对象#
PreparedStatement拓展了Statement接口,使得Statement对象可以提供灵活多变的动态参数
创建及关闭#
PreparedStatement pstmt = null; try { String SQL = "Update Employees SET age = ? WHERE id = ?"; pstmt = conn.prepareStatement(SQL); . . . } catch (SQLException e) { . . . } finally { pstmt.close(); }
CallableStatement 对象#
CallableStatement对象为所有的DBMS 提供了一种以标准形式调用已储存过程的方法。如同PreparedStatement,CallableStatement也会用到占位符。
创建及关闭#
CallableStatement cstmt = null; try { String SQL = "{call getEmpName (?, ?)}"; cstmt = conn.prepareCall (SQL); . . . } catch (SQLException e) { . . . } finally { cstmt.close(); }
JDBC参数#
JDBC 中所有的参数都被用 ? 符号表示,这是已知的参数标记。在执行 SQL 语句之前,你必须赋予每一个参数确切的数值。
setXXX() 方法将值绑定到参数,其中 XXX 表示你希望绑定到输入参数的 Java 数据类型。如果你忘了赋予值,你将收到一个 SQLException。
每个参数标记映射它的序号位置。第一标记表示位置 1 ,下一个位置为 2 等等。这种方法不同于 Java 数组索引,它是从 0 开始的。
三种类型的参数有:IN,OUT 和 INOUT。PreparedStatement 对象只使用 IN 参数。CallableStatement 对象可以使用所有的三个参数。
| 参数 | 描述 |
|---|---|
| IN | 在 SQL 语句创建的时候该参数是未知的。你可以用 setXXX() 方法将值绑定到IN参数中。 |
| OUT | 该参数由 SQL 语句的返回值提供。你可以用 getXXX() 方法获取 OUT 参数的值。 |
| INOUT | 该参数同时提供输入输出的值。你可以用 setXXX() 方法将值绑定参数,并且用 getXXX() 方法获取值。 |
JDBC ResultSet结果集#
结果集用于存储从数据库查询中获取的数据,java.sql.ResultSet 接口表示一个数据库查询的结果集。
ResultSet 接口的方法可细分为三类-
- 导航方法:用于移动光标。
- 获取方法:用于查看当前行被光标所指向的列中的数据。
- 更新方法:用于更新当前行的列中的数据。这些更新也会更新数据库中的数据。
JDBC提供了三种连接方法用于创建不同要求的ResultSet对象:
- createStatement(int RSType, int RSConcurrency);
- prepareStatement(String SQL, int RSType, int RSConcurrency);
- prepareCall(String sql, int RSType, int RSConcurrency);
RSType表示ResultSet对象的类型,控制光标的移动方式。其类型有:(未指定默认是TYPE_FORWARD_ONLY)
| 类型 | 描述 |
|---|---|
| ResultSet.TYPE_FORWARD_ONLY | 光标只能在结果集中向前移动。 |
| ResultSet.TYPE_SCROLL_INSENSITIVE | 光标可以向前和向后移动。当结果集创建后,其他人对数据库的操作不会影响结果集的数据。 |
| ResultSet.TYPE_SCROLL_SENSITIVE. | 光标可以向前和向后移动。当结果集创建后,其他人对数据库的操作会影响结果集的数据。 |
RSConcurrency表示ResultSet常量之一,判断返回的结果集是只读还是可修改的。其并发性:(未指定默认是CONCUR_READ_ONLY)
| 并发性 | 描述 |
|---|---|
| ResultSet.CONCUR_READ_ONLY | 创建一个只读结果集,这是默认的值。 |
| ResultSet.CONCUR_UPDATABLE | 创建一个可修改的结果集。 |
JDBC事务#
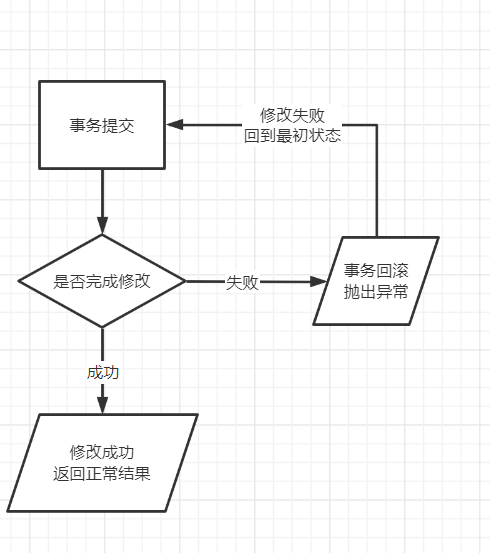
默认情况下,JDBC的连接是处于自动提交模式下,每句SQL语句都是在其完成时提交到数据库。
可以通过setAutoCommit()方法,传递false即为关闭自动提交模式。
JDBC的事务流程为:
还原点#
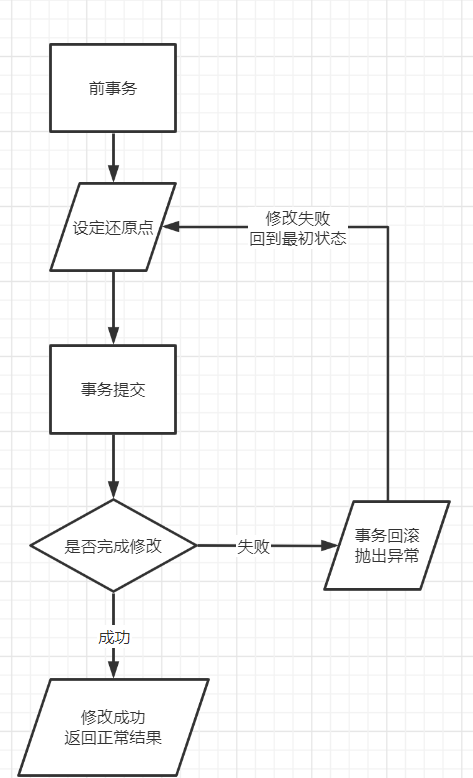
JDBC3.0中还原点的出现提供了额外的事务控制。
当你在事务中设置一个还原点来定义一个逻辑回滚点。如果在一个还原点之后发生错误,那么可以使用 rollback 方法来撤消所有的修改或在该还原点之后所做的修改。
Connection 对象有两个新的方法来管理还原点-
- setSavepoint(String savepointName): 定义了一个新的还原点。它也返回一个 Savepoint 对象。
- releaseSavepoint(Savepoint savepointName): 删除一个还原点。请注意,它需要一个作为参数的 Savepoint 对象。这个对象通常是由 setSavepoint() 方法生成的一个还原点。
拥有还原点的事务大致流程如下:
JDBC批处理#
当你需要一次性提交多个SQL语句时,可以使用批处理将他们当成一个调用提交给数据库;
- 使用DatabaseMetaData.supportsBatchUpdates()方法来确定目标数据库是否支持批处理更新
- Statement及派生的addBatch()方法用于添加单个SQL语句到批处理中
- executeBatch()方法用于启动执行所有组合在一起的语句,返回一个整数数组,表示每个语句更新数目
- clearBatch()方法清空批处理内的SQL语句
批处理和 PrepareStatement 对象实例:#
// Create SQL statement String SQL = "INSERT INTO Employees (id, first, last, age) " + "VALUES(?, ?, ?, ?)"; // Create PrepareStatement object PreparedStatemen pstmt = conn.prepareStatement(SQL); //Set auto-commit to false conn.setAutoCommit(false); // Set the variables pstmt.setInt( 1, 400 ); pstmt.setString( 2, "Pappu" ); pstmt.setString( 3, "Singh" ); pstmt.setInt( 4, 33 ); // Add it to the batch pstmt.addBatch(); // Set the variables pstmt.setInt( 1, 401 ); pstmt.setString( 2, "Pawan" ); pstmt.setString( 3, "Singh" ); pstmt.setInt( 4, 31 ); // Add it to the batch pstmt.addBatch(); //add more batches . . . . //Create an int[] to hold returned values int[] count = stmt.executeBatch(); //Explicitly commit statements to apply changes conn.commit();
JDBC流数据#
当要将整个文件存储到数据库列中,一个一个添加在数据量大时会撑爆内存,通过流数据使得数据库能够存储大型数据。常见的有CLOB和BLOB,前者使用CHAR保存数据——比如XML文档,后者使用二进制保存数据——比如位图。
CLOB#
CLOB是一个内置类型,如同C中的int、double等等。默认情况下,驱动程序使用SQL locate实现CLOB对象,所以CLOB对象包含一个指向SQL CLOB数据的逻辑指针,而不是数据本身,避免了内存占用。CLOB对象在它被创建的事务处理期间有效。
数据相对较小的情况下,可以将CLOB看作字符串类型
如果比较大,可以用 getAsciiStream 或者 getUnicodeStream 以及对应的 setAsciiStream 和 setUnicodeStream 即可
BLOB#
BLOB是一个二进制大对象,用于存储二进制文件的容器。可存储的最大大小为4G字节。
JDBC基本使用快速入门#
创建接口,执行SQL语句#
Statement#
Statement stmt = conn.createStatement(); String sql = "insert into brand values(brandName,companyName,ordered);"; stmt.execute(sql); stmt.close(); conn.close();
使用Statement接口是以拼接字符串的方式来执行,有sql注入的弊端,为了防止sql注入,使用PreparedStatement预编译
PreparedStatement#
String brandName = "Java"; String companyName = "Oracle"; String sql = "select * from brand where brandName = ? and companyName = ?;"; PreparedStatement ppstt = conn.prepareStatement(sql); ppstt.setString(1,brandName); ppstt.setString(2,companyName);
使用PreparedStatement时,sql语句将不再采用字符串拼接的方式,而是使用占位符的方式,"?"在此起到占位符的作用
结果展示#
ResultSet rs = stmt.executeQuery(sql); List<Student> list = new ArrayList<>(); while (rs.next()) { Brand newBrand = new Brand(); int id = rs.getInt("id"); String brandName = rs.getString("brand_name"); String companyName = rs.getString("company_name"); System.out.println(" | " + id + " | " + brandName + " | " + companyName + " | "); newBrand.setId(id); newBrand.setbrandName(name); newBrand.setcompanyName(birthday); list.add(newBrand); }
资源释放#
rs.close(); stmt.close(); conn.close();
Statement和PreparedStatement的异同及优缺点#
同:两者都是用来执SQL语句的
异:PreparedStatement需要根据SQL语句来创建,它能够通过设置参数,指定相应的值,不是像Statement那样使用字符串拼接的方式。
PreparedStatement的优点:
1、其使用参数设置,可读性好,不易记错。在statement中使用字符串拼接,可读性和维护性比较差。
2、其具有预编译机制,性能比statement更快。
3、其能够有效防止SQL注入攻击。
execute和executeUpdate的区别#
相同点:二者都能够执行增加、删除、修改等操作。
不同点:
1、execute可以执行查询语句,然后通过getResult把结果取出来。executeUpdate不能执行查询语句。
2、execute返回Boolean类型,true表示执行的是查询语句,false表示执行的insert、delete、update等。executeUpdate的返回值是int,表示有多少条数据受到了影响。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通