2023数据采集与融合技术实践作业2
2023数据采集与融合技术实践作业2
作业①:
-
要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7
日天气预报,并保存在数据库。 -
输出信息:
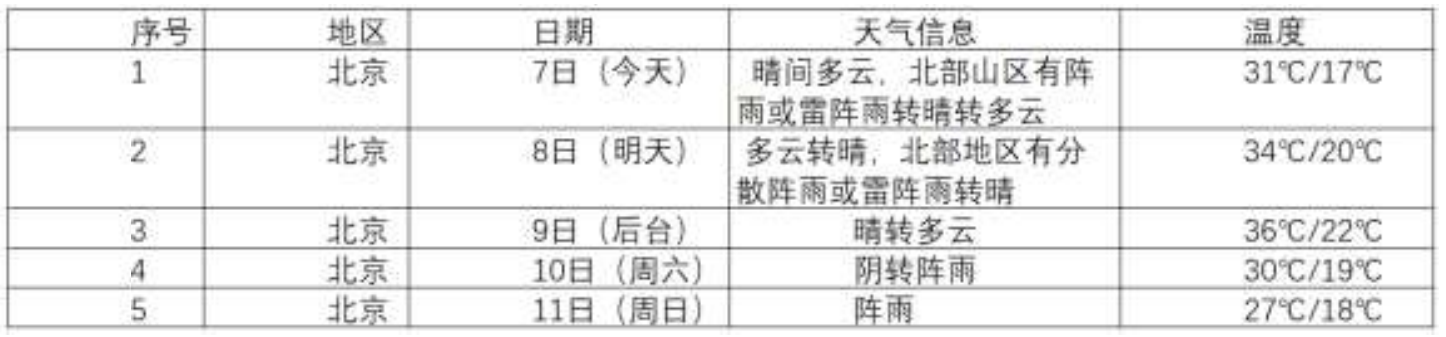
-
Gitee 文件夹链接为:作业2gitee链接
1.1 作业过程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"CREATE TABLE weathers (wCity VARCHAR(16), wDate VARCHAR(16), wWeather VARCHAR(64), wTemp VARCHAR(32), CONSTRAINT pk_weather PRIMARY KEY(wCity, wDate))")
except:
self.cursor.execute("DELETE FROM weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
sql = "INSERT INTO weathers (wCity, wDate, wWeather, wTemp) VALUES (?, ?, ?, ?)"
try:
self.cursor.execute(sql, (city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("SELECT * FROM weathers")
rows = self.cursor.fetchall()
print("{0:^18}{1:{4}^18}{2:{4}^21}{3:{4}^13}".format("城市", "日期", "天气信息", "温度", chr(12288)))
for row in rows:
print("{0:^18}{1:{4}^20}{2:{4}^18}{3:{4}^18}".format(row[0], row[1], row[2], row[3], chr(12288)))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101","深圳": "101280601", }
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"]')[0].text.strip()
# print(city,date,weather,temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")
结果:
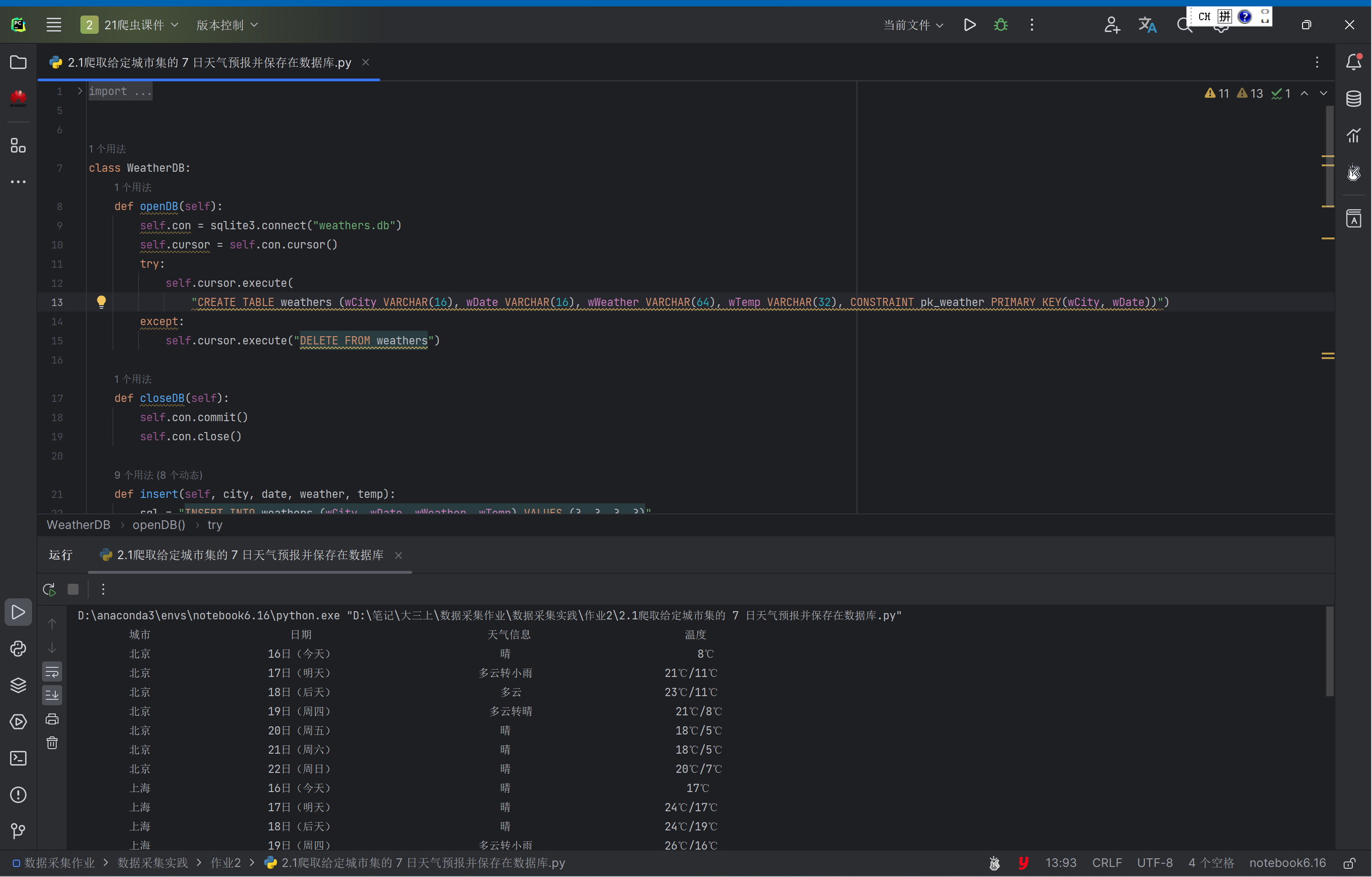
1.2. 心得体会
复现之前的代码,难度不大
作业②:
-
要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
-
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/ -
技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数值,根据情况可删减请求的参数。
-
输出信息:
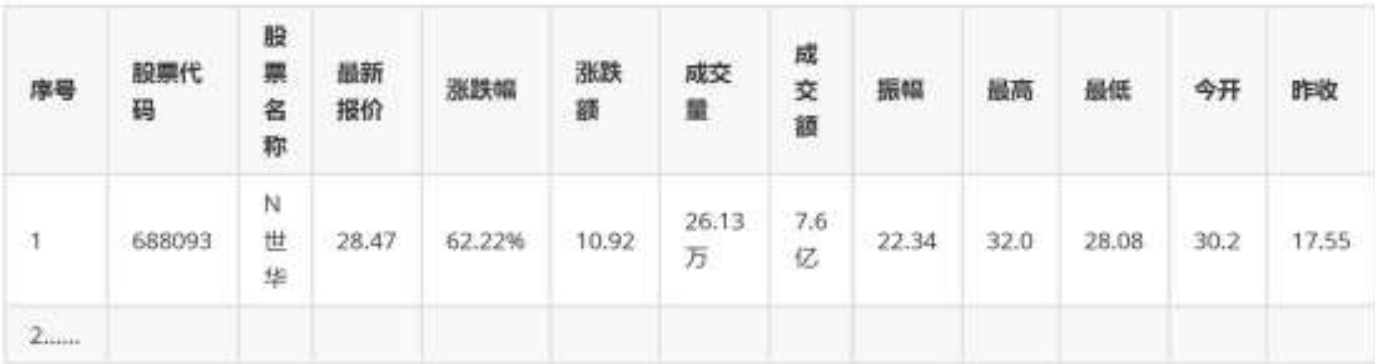
-
Gitee 文件夹链接:作业2gitee链接
2.1 作业过程
观察页面结构
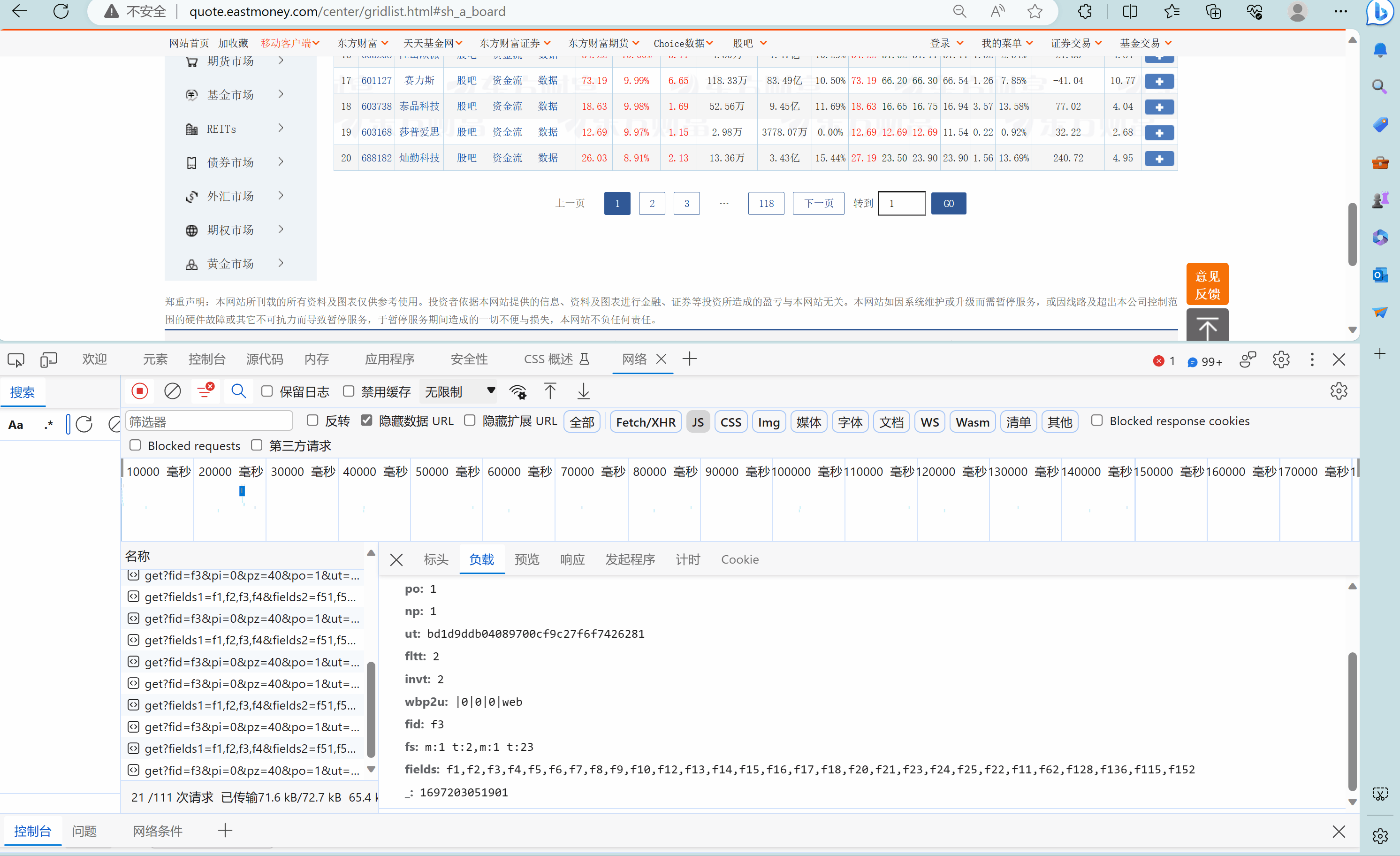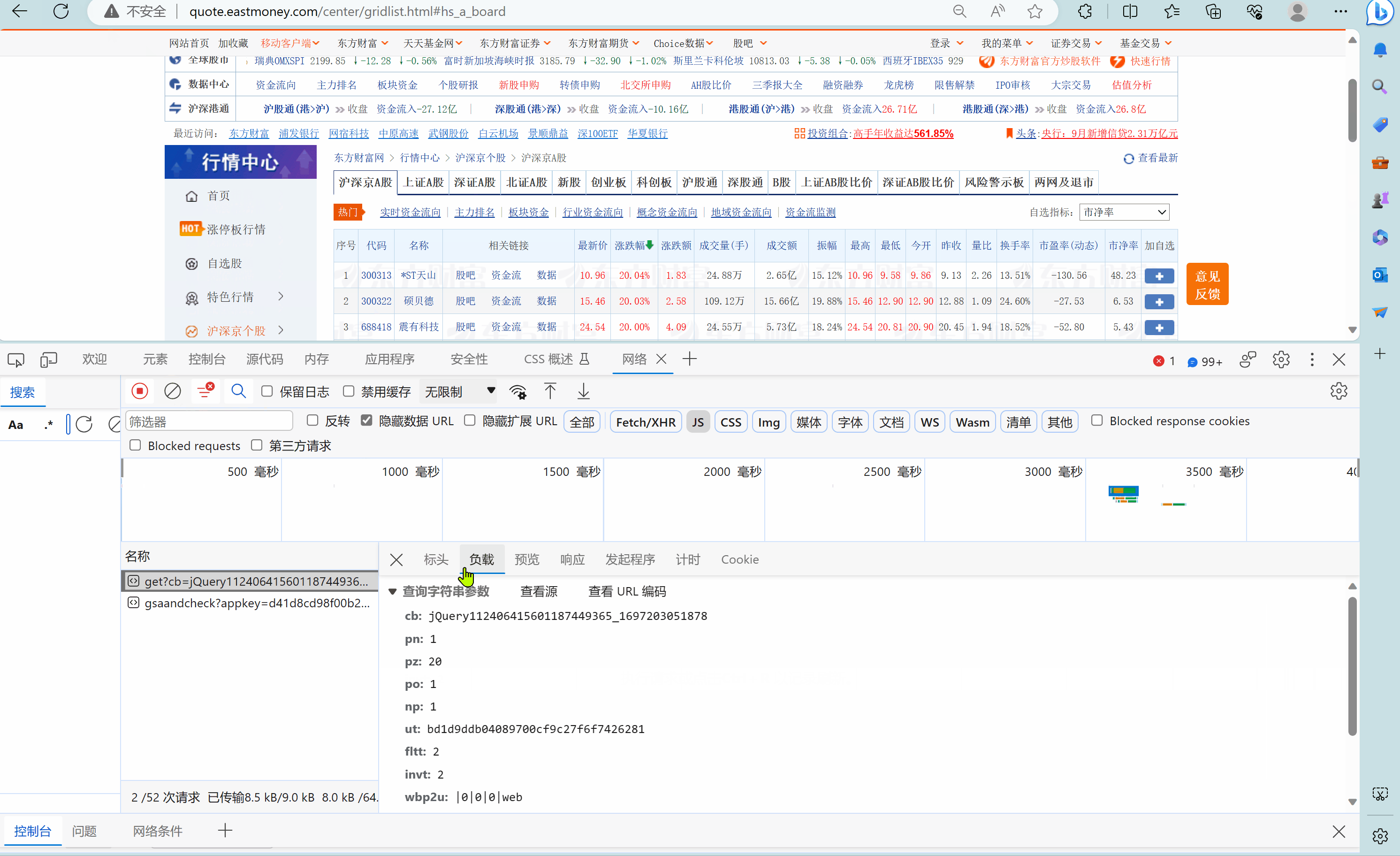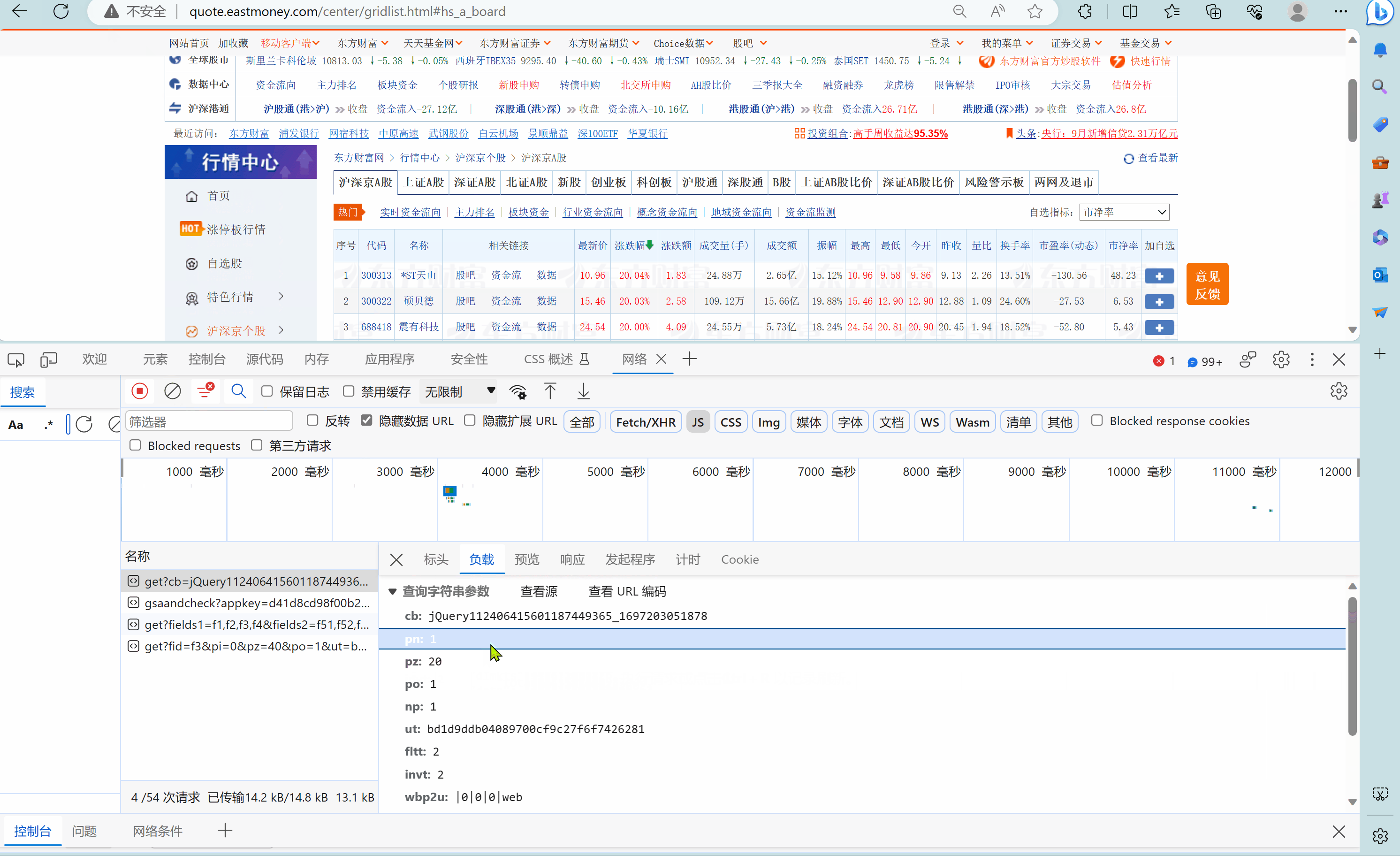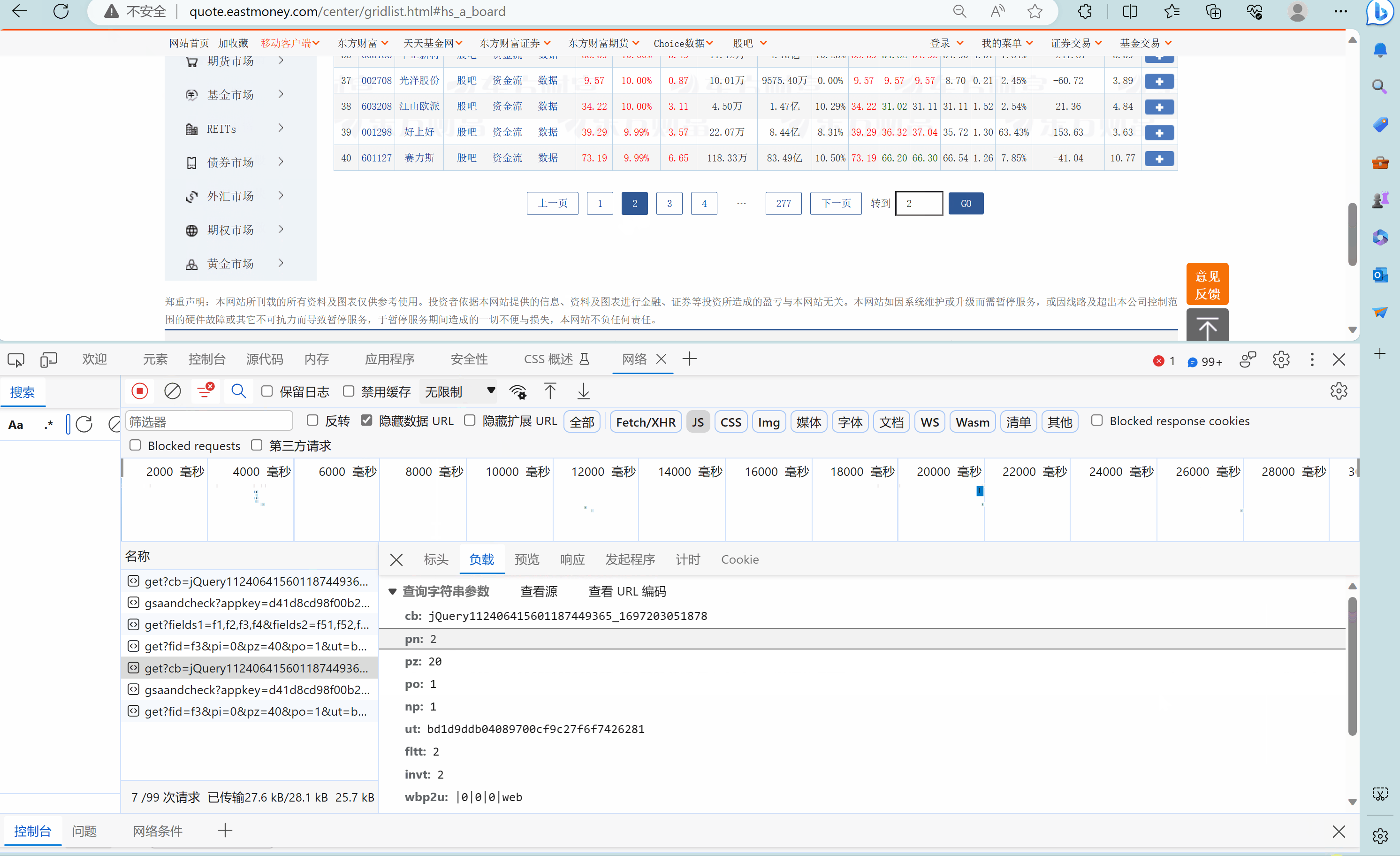
分别观察了沪深京A股第1页、第2页,上证A股第1页的请求url,发现(为了便于比较,我把这三个页面的url放在一个ppt中):
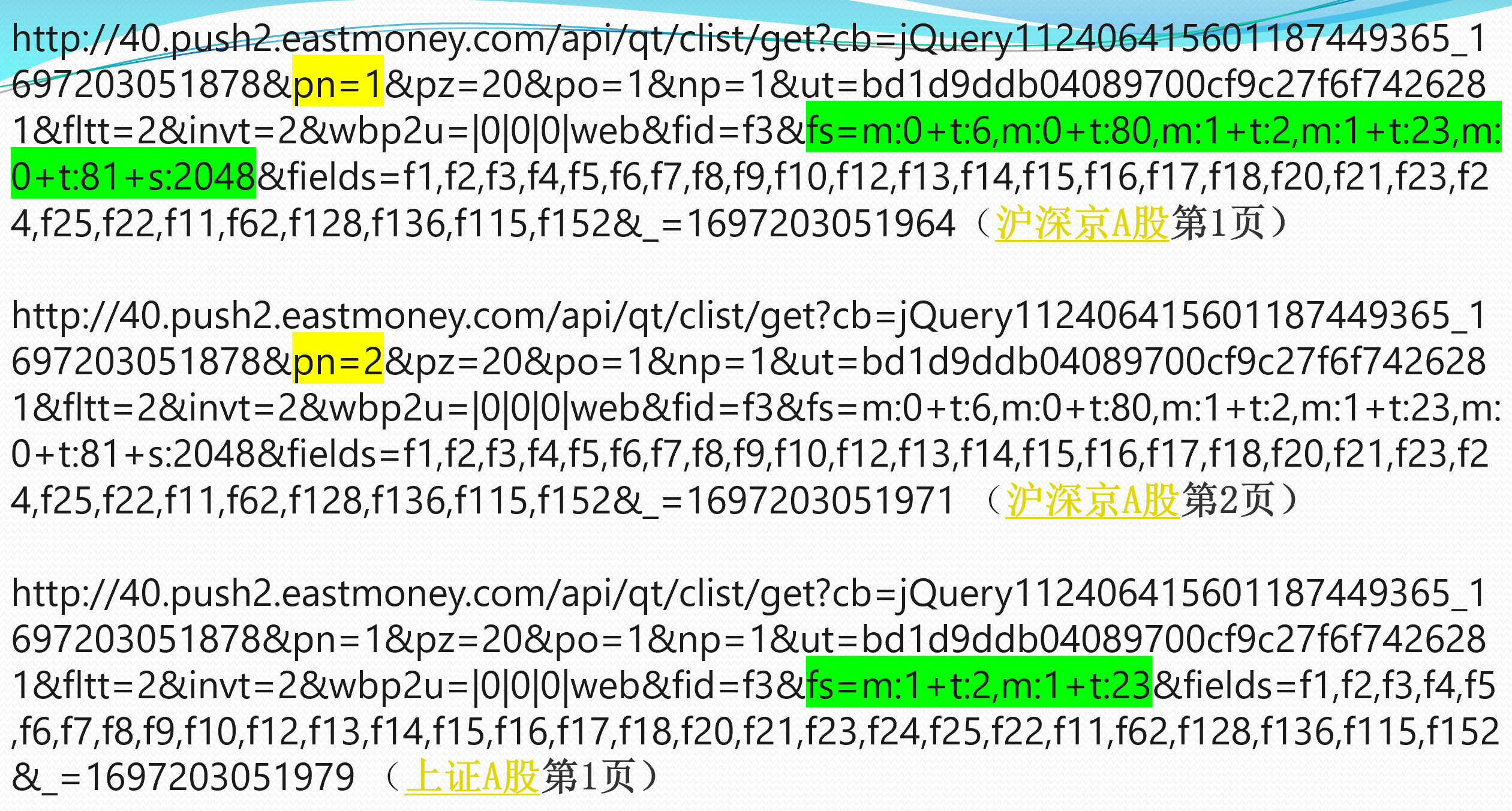
可以看到
- pn参数控制这是第几页
- fs参数控制这是哪一只股票。
再多观察几个页面,还可以发现:
- fs参数的对应情况
fs = {
"沪深京A股": "m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:80",
"北证A股": "m:0+t:81+s:2048",
"新股": "m:0+t:81+s:2048",
"创业板": "m:0+t:80"
}
- pz参数控制一页显示多少只股票,如果要获取100只股票的数据,不用for循环来进行翻页处理,直接pz=100就可以。
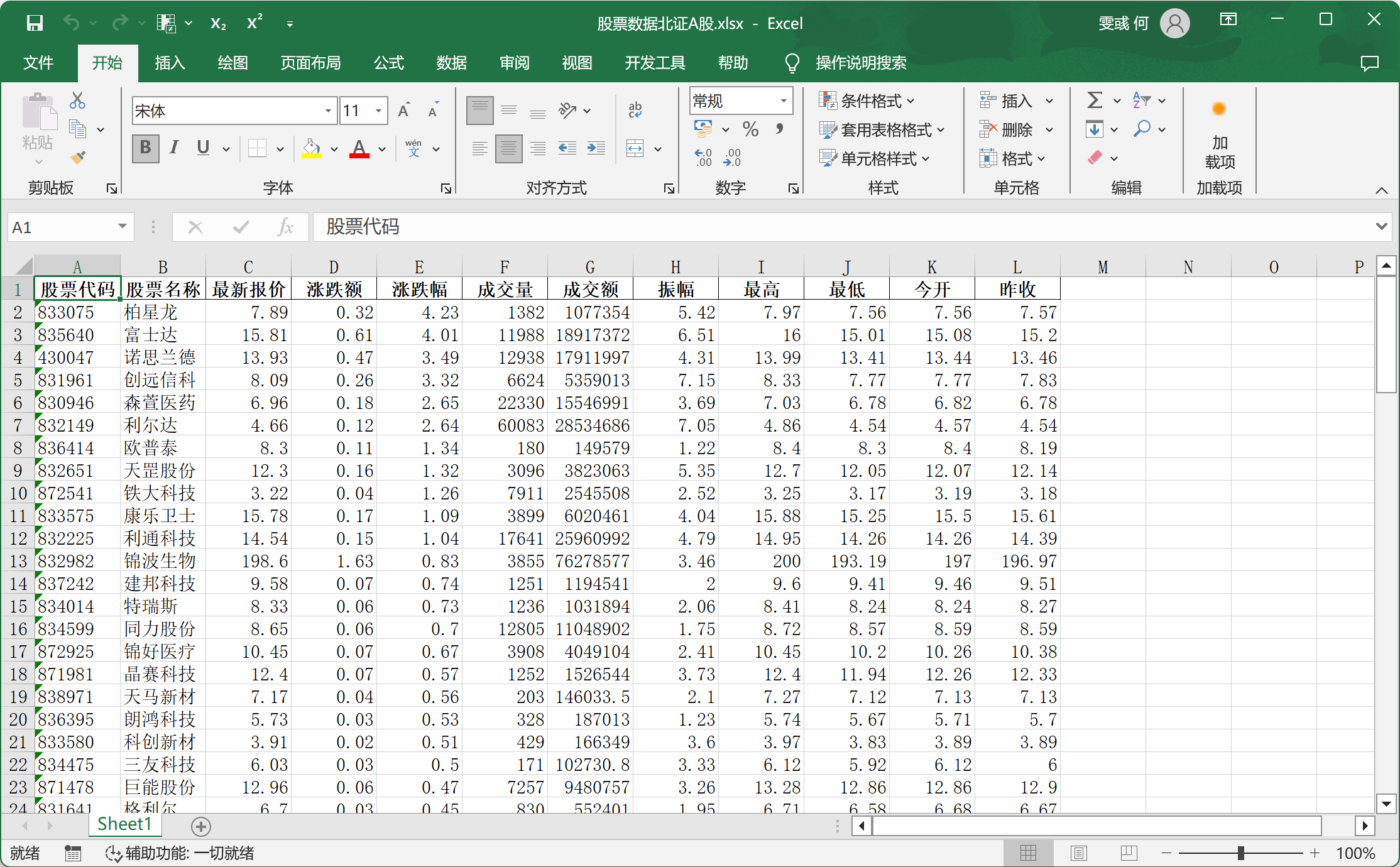
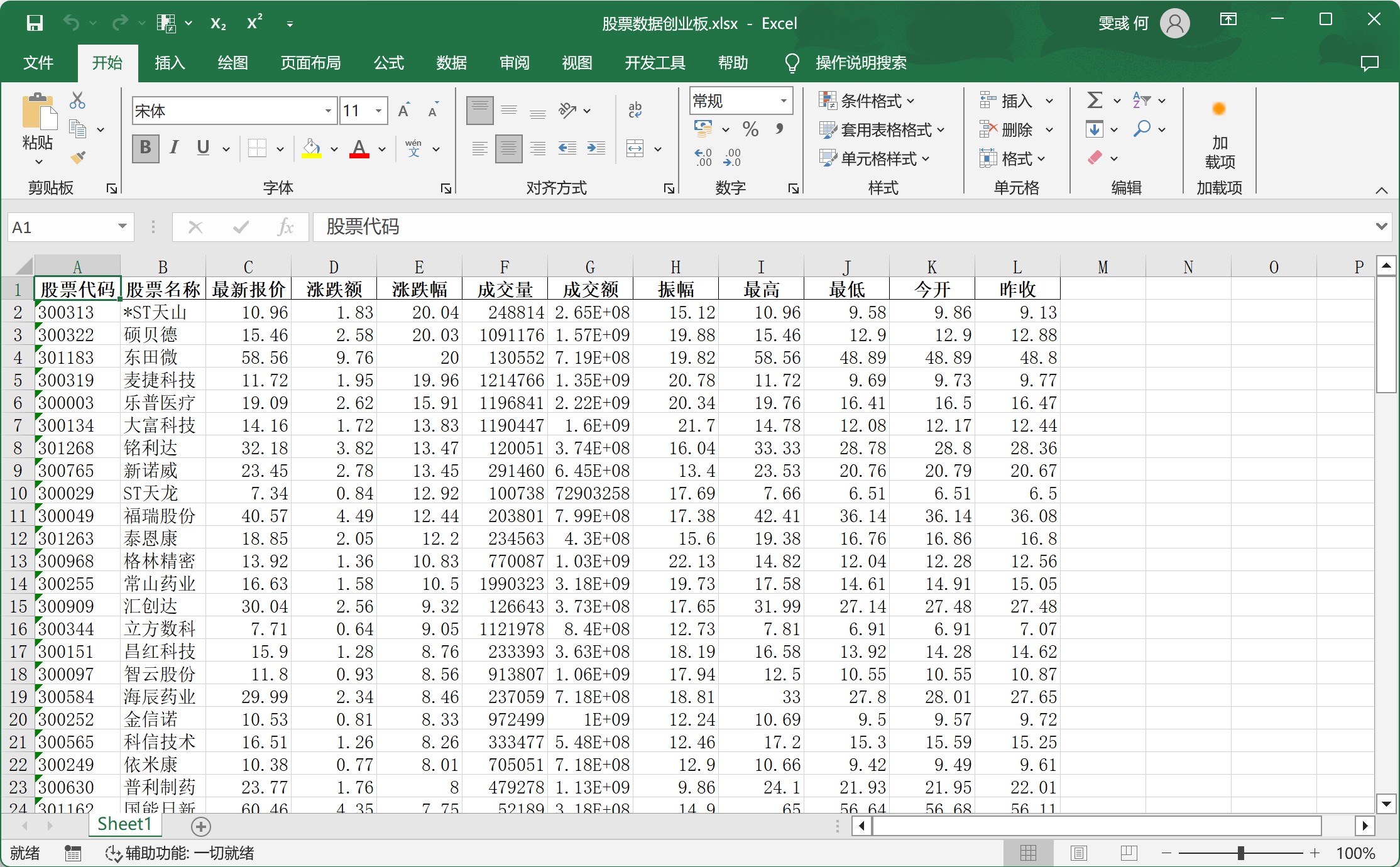
- fields参数对应列信息,我们只需要请求'f2': "最新报价",'f4': "涨跌额",'f3': "涨跌幅",'f5': "成交量",'f6': "成交额",'f7': "振幅",'f12': "股票代码",'f14': "股票名称",'f15': "最高",'f16': "最低",'f17': "今开",'f18': "昨收"这几列就好了。
获取数据
观察完结构之后,我们就可以对相应链接发起js请求来获取数据
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'http://21.push2delay.eastmoney.com/api/qt/clist/get?cb=jQuery112408395754169788474_1696658950571&pn=1&pz=100&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs='+fs+'&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1696658950639'
jsonp_response = requests.get(url=url,headers=headers).text
数据处理
现在获取到的数据并不是纯json格式(头尾都有别的内容),不利于后续提取,所以需要去头去尾
json_str = jsonp_response[len("jQuery112406415601187449365_1697203051878("):len(jsonp_response)-2]
为了确保获取到的数据已经是json格式的,可以借助在线json校验网站。
获取所需要的数据
我们要的数据位于上一步获取到的json串中键"data"下'diff'所对应的值
# 解析JSON字符串(蒋json格式的字符串转化为python对象)
data = json.loads(json_str)
# 提取data的值
data_value = data['data']['diff']
完整代码
'''
数据来源:东方财富网-行情中心
http://quote.eastmoney.com/center/hgtstock.html#_12
'''
import requests
import re
import pandas as pd
import json
# 用get方法访问服务器并提取页面数据
def getHtml(fs):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'http://21.push2delay.eastmoney.com/api/qt/clist/get?cb=jQuery112408395754169788474_1696658950571&pn=1&pz=100&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs='+fs+'&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1696658950639'
jsonp_response = requests.get(url=url,headers=headers).text
# 从JSONP响应中提取JSON字符串(去头去尾操作)
json_str = jsonp_response[len("jQuery112406415601187449365_1697203051878("):len(jsonp_response)-2]
# 解析JSON字符串(蒋json格式的字符串转化为python对象)
data = json.loads(json_str)
# 提取data的值
data_value = data['data']['diff']
# print(data_value['diff'])
return data_value
def main():
fs = {
"沪深京A股": "m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:80",
"北证A股": "m:0+t:81+s:2048",
"新股": "m:0+t:81+s:2048",
"创业板": "m:0+t:80"
}
for i in fs.keys():
# 字典数据
stocks = getHtml(fs[i])
# 转换为DataFrame
df = pd.DataFrame(stocks)
# 列名对应关系
columns_mapping = {
'f2': "最新报价",
'f4': "涨跌额",
'f3': "涨跌幅",
'f5': "成交量",
'f6': "成交额",
'f7': "振幅",
'f12': "股票代码",
'f14': "股票名称",
'f15': "最高",
'f16': "最低",
'f17': "今开",
'f18': "昨收"
}
# 重命名列
df.rename(columns=columns_mapping, inplace=True)
# 按照指定的顺序排列列
ordered_columns = ["股票代码", "股票名称", "最新报价", "涨跌额", "涨跌幅", "成交量", "成交额", "振幅", "最高",
"最低", "今开","昨收"]
df = df[ordered_columns]
# 保存为Excel文件
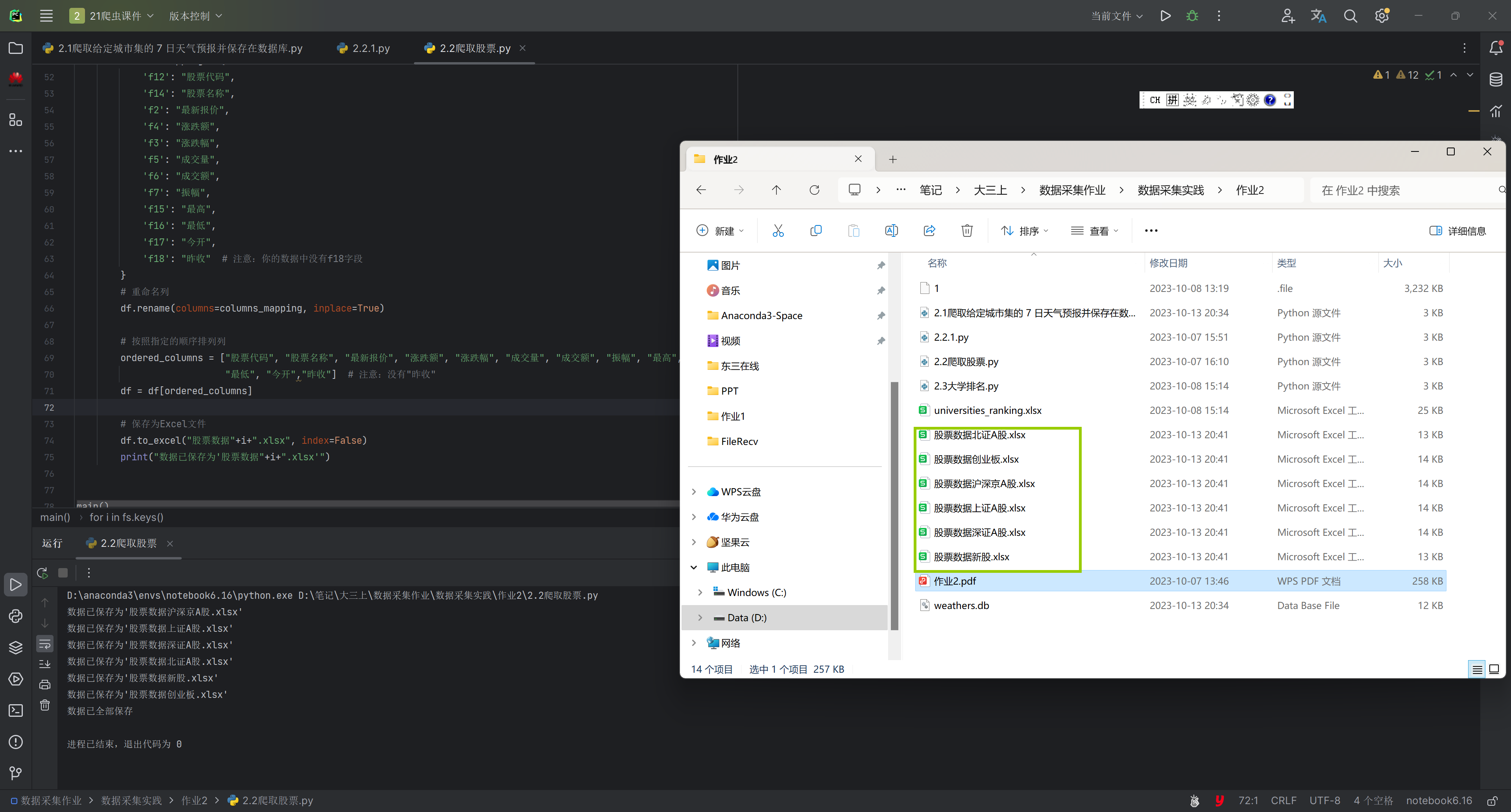
df.to_excel("股票数据"+i+".xlsx", index=False)
print("数据已保存为'股票数据"+i+".xlsx'")
main()
print("数据已全部保存")
结果:
2.2 心得体会
这个作业比较有意思,发现数据库里存着所有的数据,只要在请求参数里面修改请求参数就可以获得自己所需要的数据。
作业③:
-
要求:爬取中国大学 2021 主榜( https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
-
技巧:分析该网站的发包情况,分析获取数据的 api
-
输出信息:

-
Gitee 文件夹链接:作业2gitee链接
3.1 作业过程
用抓包的方式去获得请求url
解析数据
最初没发现规律,有点儿懵逼,然后观察网页结构发现这个网站的程序员就是头尾是键值对对应的,很神奇的结构!所以我对头尾元素进行了映射:

# 创建省份和大学类别的字母映射字典
province_mapping = {
'k': '江苏','n': '山东', 'o': '河南','p': '河北','q': '北京','r': '辽宁','s': '陕西','t': '四川','u': '广东',
'v': '湖北','w': '湖南','x': '浙江','y': '安徽','z': '江西','A': '黑龙江','B': '吉林','C': '上海','D': '福建','E': '山西',
'F': '云南','G': '广西','I': '贵州','J': '甘肃','K': '内蒙古','L': '重庆','M': '天津','N': '新疆','Y': '海南'
}
univ_category_mapping = {
'f': '综合',
'e': '理工',
'h': '师范',
'm': '农业',
'T': '林业',
}
完整代码如下:
import re
import requests
import pandas as pd
# 创建省份和大学类别的字母映射字典
province_mapping = {
'k': '江苏','n': '山东', 'o': '河南','p': '河北','q': '北京','r': '辽宁','s': '陕西','t': '四川','u': '广东',
'v': '湖北','w': '湖南','x': '浙江','y': '安徽','z': '江西','A': '黑龙江','B': '吉林','C': '上海','D': '福建','E': '山西',
'F': '云南','G': '广西','I': '贵州','J': '甘肃','K': '内蒙古','L': '重庆','M': '天津','N': '新疆','Y': '海南'
}
univ_category_mapping = {
'f': '综合',
'e': '理工',
'h': '师范',
'm': '农业',
'T': '林业',
}
url = 'https://www.shanghairanking.cn/_nuxt/static/1695811954/rankings/bcur/2021/payload.js'
header = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
resp = requests.get(url, headers=header)
resp.raise_for_status()
resp.encoding = resp.apparent_encoding
# (?P<分组名字>正则) 可以单独从正则匹配的内容中进一步提取内容
obj = re.compile(
r'univNameCn:"(?P<univNameCn>.*?)",.*?'
r'univCategory:(?P<univCategory>.*?),.*?'
r'province:(?P<province>.*?),'
r'score:(?P<score>.*?),'
, re.S) # re.S 让点匹配换行符
#print(resp.text)
result1 = obj.finditer(resp.text)
# 创建一个空列表来保存结果
results = []
# 遍历正则匹配的结果
for idx, it in enumerate(result1, start=1):
univNameCn = it.group('univNameCn')
univCategory = it.group('univCategory')
province = it.group('province')
score = it.group('score')
# 使用字典进行映射转换
mapped_province = province_mapping.get(province, province) # 如果找不到映射,则使用原始值
mapped_category = univ_category_mapping.get(univCategory, univCategory) # 如果找不到映射,则使用原始值
results.append((idx, univNameCn, mapped_province, mapped_category, score))
# 使用pandas创建DataFrame
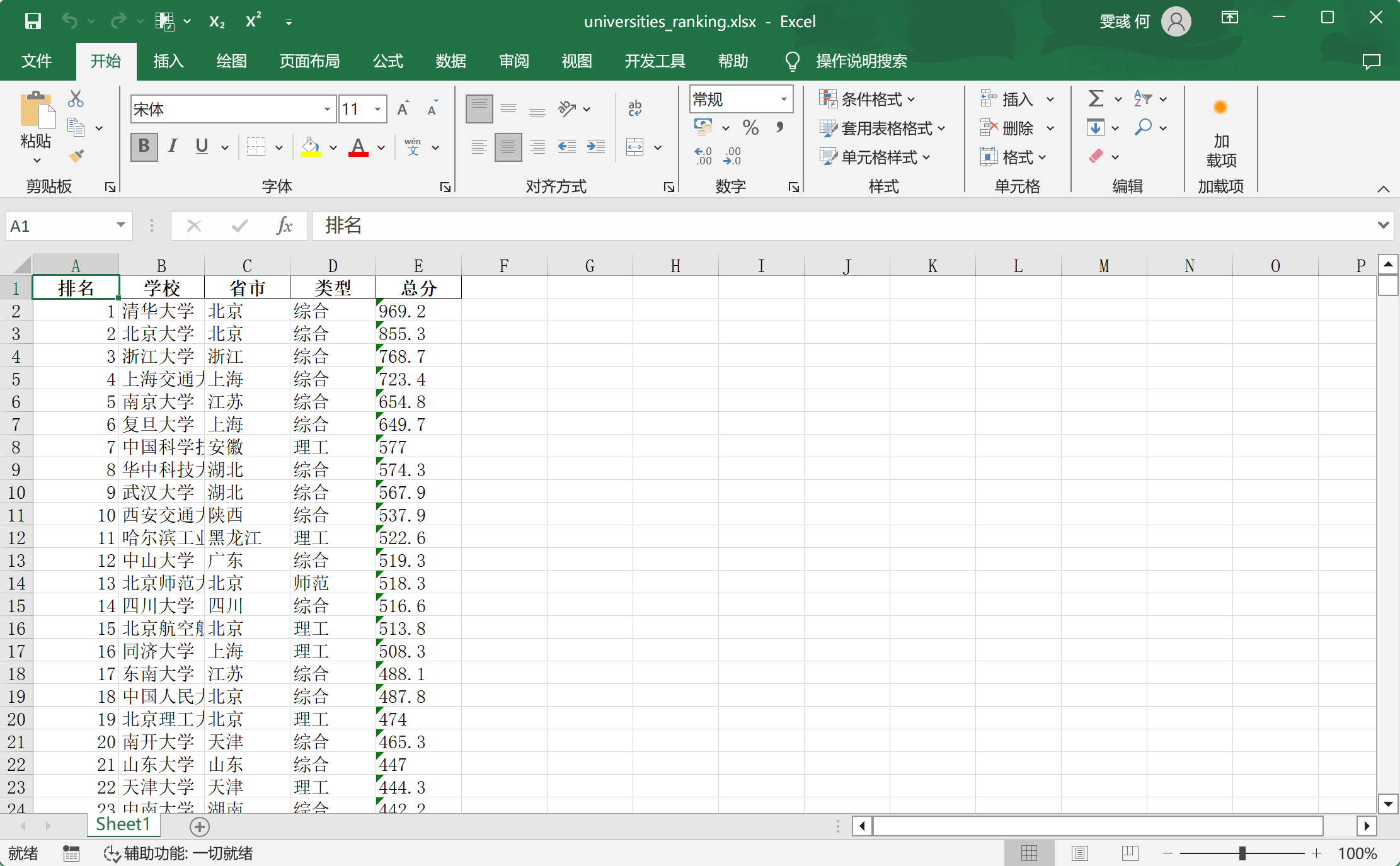
df = pd.DataFrame(results, columns=['排名', '学校', '省市', '类型', '总分'])
# 将DataFrame保存到Excel文件中
df.to_excel('universities_ranking.xlsx', index=False)
结果:
3.2 心得体会
1.学习到用抓包的方式去获得url;
2.进一步体会了正则的好用(对于这种不按常理出牌的页面源代码——前面是字典,后面居然有一些键没有加引号),更学习了怎么匹配的正则表达式里面进一步提取内容(用括号把需要进一步获取的内容括起来)。
