数据采集与融合技术实践(爬虫)——作业1
作业①
o 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
o 输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | ..... | ..... | ..... | ..... |
(1)实验代码
第一版代码如下:
点击查看代码
import urllib.request # 获取URL信息
from bs4 import BeautifulSoup
import bs4
# 获取网页内容
def fetchWebContent(url): # 获取URL信息,输出内容
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
req = urllib.request.Request(url,headers=headers)
# 打开URL网站的网址,读出二进制数据,二进制数据转为字符串
data = urllib.request.urlopen(req).read().decode()
return data
except Exception as err:
print(err)
# 提取网页内容中信息到合适的数据结构,解析网页数据
def parseUniversityData(ulist, html): # 将html页面放到ulist列表中(核心)
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag): # 如果tr标签的类型不是bs4库中定义的tag类型,则过滤掉
a = tr('a') # 把所用的a标签存为一个列表类型
tds = tr('td') # 将所有的td标签存为一个列表类型
ulist.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(),
tds[3].text.strip(), tds[4].text.strip()])
# 利用数据结构展示并输出结果:定义函数,打印大学排名数据
def printUnivList(ulist1, num): # 打印出ulist列表的信息,num表示希望将列表中的多少个元素打印出来
tplt = "{0:^10}\t{1:{5}^10}\t{2:^12}\t{3:^12}\t{4:^10}"
print(tplt.format("排名", "学校名称", "省份", "学校类型", "总分",chr(12288)))
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4],chr(12288)))
def main():
uinfo = [] # 将大学信息放到列表中
url = "http://www.shanghairanking.cn/rankings/bcur/202311"
html = fetchWebContent(url)
parseUniversityData(uinfo, html)
#这边仅爬取排名前100的学校做展示
num = 30
printUnivList(uinfo, num)
if __name__ == '__main__':
main()
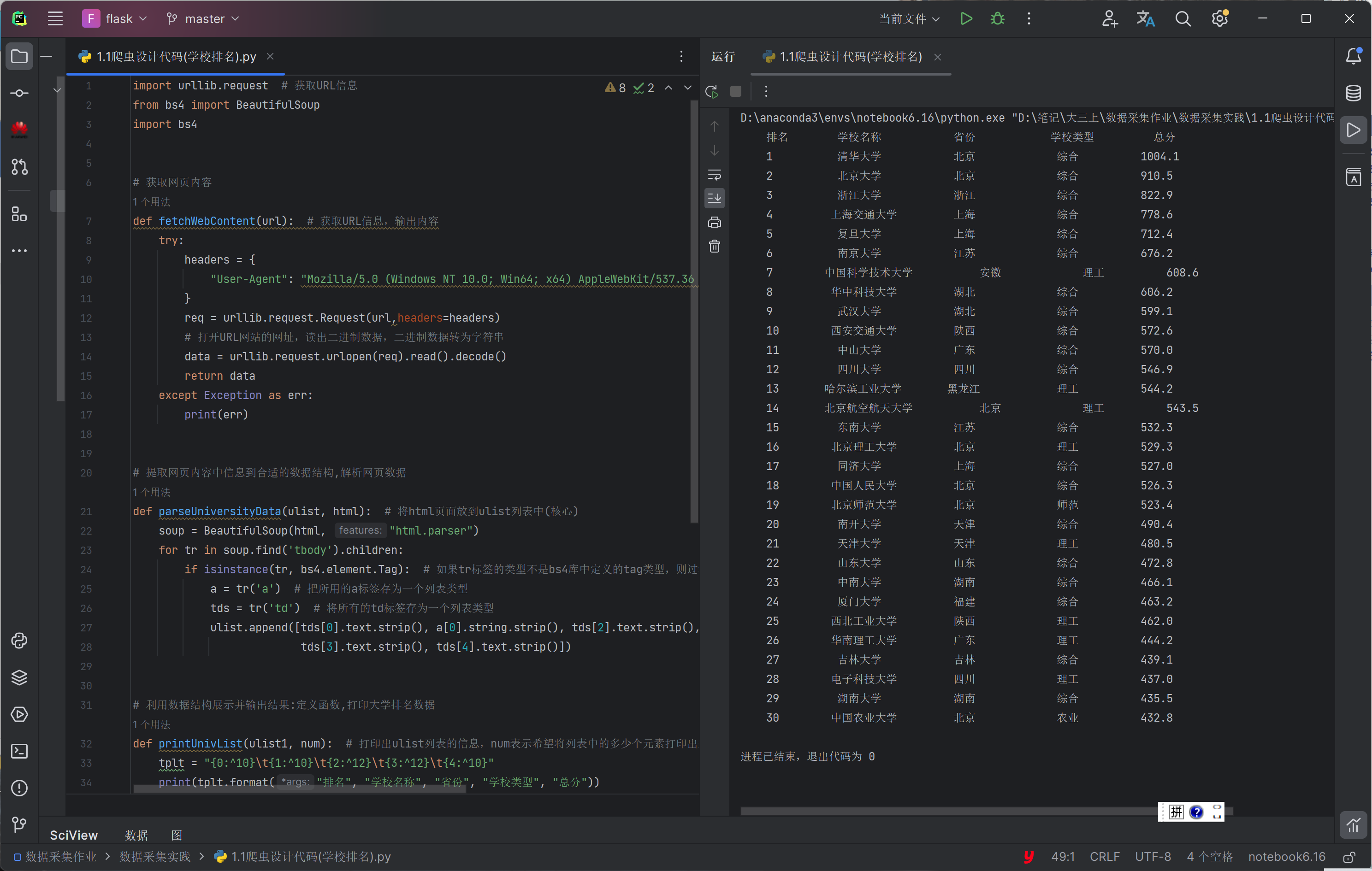
但是发现有几处问题:
- urlib库与request库
对比了二者,发现urllib库构造请求头和发起请求需要分别需要req=urllib.request.Request(url,headers)、urllib.request.urlopen(req),而request库只要requset.get(url,headers)一行,于是我光速投入request库的怀抱。 - 某几行输出不规范
改进后的代码如下:
点击查看代码
import requests # 获取URL信息
from bs4 import BeautifulSoup
import bs4
# 获取网页内容
def fetchWebContent(url): # 获取URL信息,输出内容
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
r = requests.get(url, headers=headers, timeout=30) # 设置超时为30秒,30秒返回响应,否则就抛出异常
r.raise_for_status() # 如果发送了一个错误请求,就可以通过r.raise_for_status()来抛出异常
r.encoding = r.apparent_encoding
return r.text
except Exception as err:
print(err)
# 提取网页内容中信息到合适的数据结构,解析网页数据
def parseUniversityData(ulist, html): # 将html页面放到ulist列表中(核心)
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag): # 如果tr标签的类型不是bs4库中定义的tag类型,则过滤掉
a = tr('a') # 把所用的a标签存为一个列表类型
tds = tr('td') # 将所有的td标签存为一个列表类型
ulist.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(),
tds[3].text.strip(), tds[4].text.strip()])
# 利用数据结构展示并输出结果:定义函数,打印大学排名数据
def printUnivList(ulist1, num): # 打印出ulist列表的信息,num表示希望将列表中的多少个元素打印出来
tplt = "{0:^10}\t{1:{5}^10}\t{2:^12}\t{3:^12}\t{4:^10}"
print(tplt.format("排名", "学校名称", "省份", "学校类型", "总分", chr(12288)))
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4], chr(12288)))
def main():
uinfo = [] # 将大学信息放到列表中
url = "http://www.shanghairanking.cn/rankings/bcur/202311"
html = fetchWebContent(url)
parseUniversityData(uinfo, html)
# 这边仅爬取排名前30的学校做展示
num = 30
printUnivList(uinfo, num)
if __name__ == '__main__':
main()
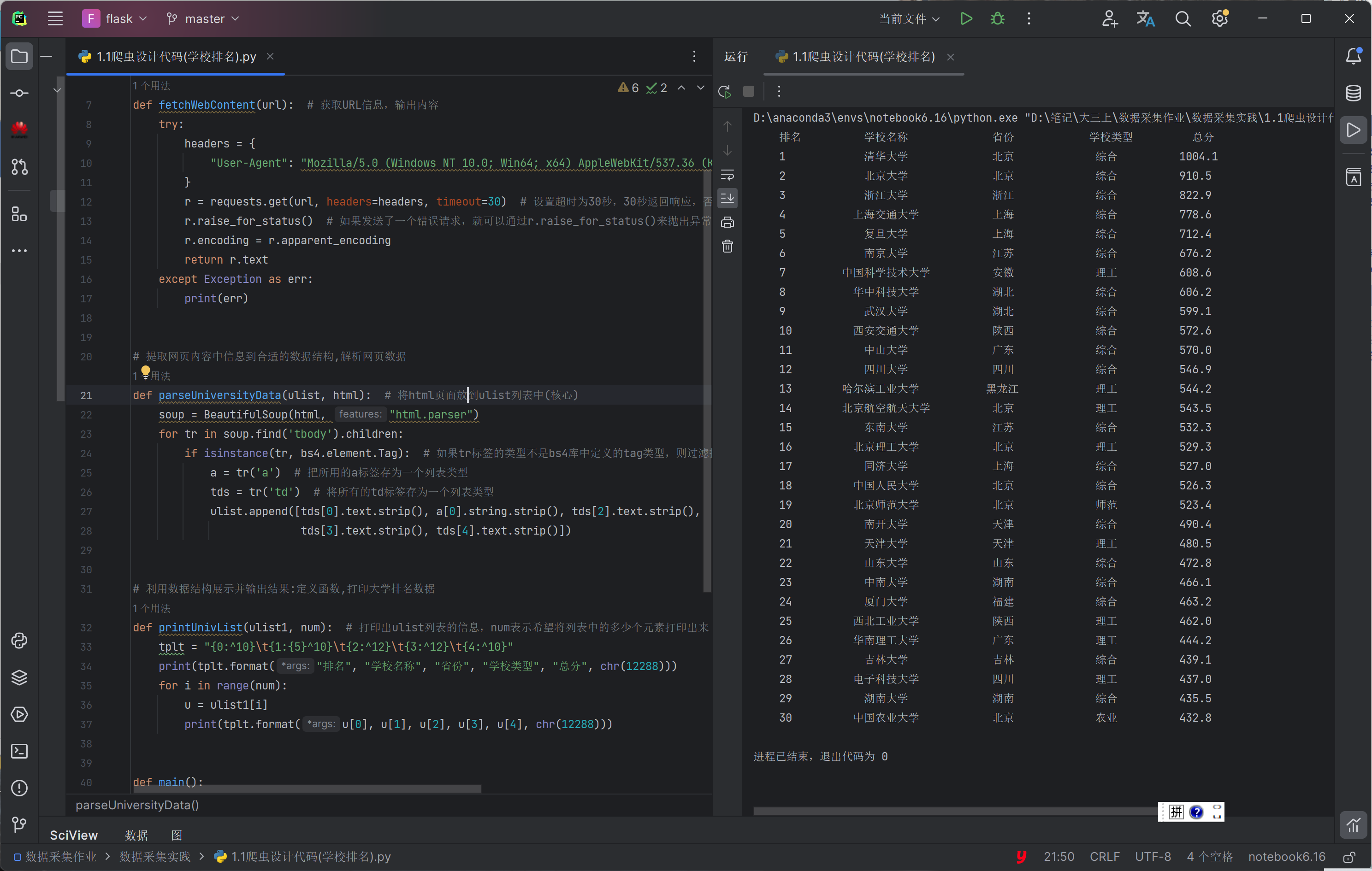
(2)心得体会
- request库相较urllib库更为方便。
- chr(12288)用于对齐真好用!
- 原来以为爬完了要关掉,不然多运行几个爬虫程序且都没关之后,爬取的速度会变得很慢。使用的 requests 库自身会处理连接的关闭,所以通常不需要手动关闭。
作业②
o 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
o 输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 | ..... | ..... |
(1)实验代码
- 定位到我们想要获取的图片元素的所在位置(巧用F12)。
首先输入关键词“书包”,刷新页面请求,观察页面结构。
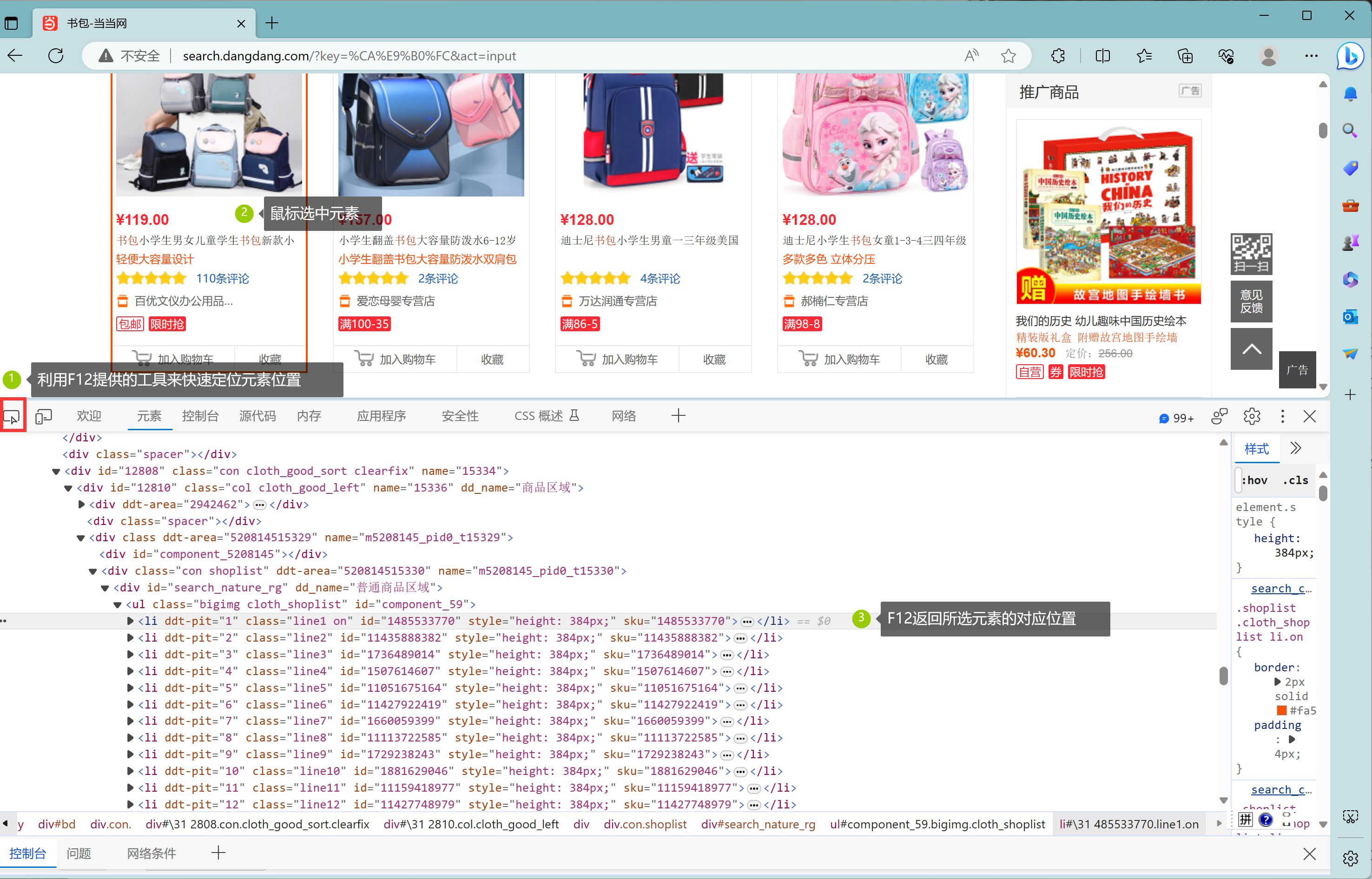
多观察几个后发现,<ul class="bigimg cloth_shoplist" id="component_lixia59>下的<li>分别对应一个单品,而我们想要获取的商品名称元素位于<li>的<a>标签里的'title'属性中,价格元素位于<li>下<p>下<span>的文本值中。
至此,每个单品的名称和价格已能够获取到。
2. 翻页处理
现在我们能够拿到一整张页面的图片,但是怎么获取第2页、第3页、或者说更多页后面的数据呢?
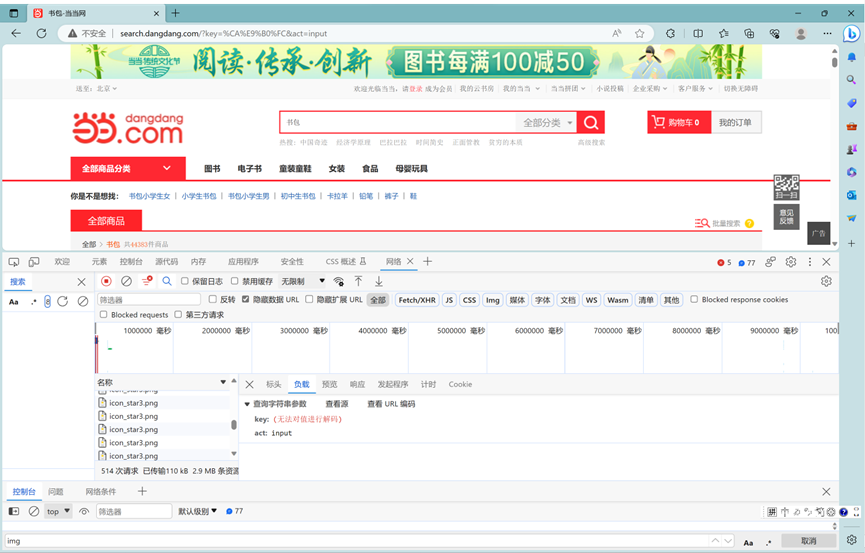
第一下观察页面毫无头绪,请求根本没有携带和页数有关的参数。只能继续往下看第二页:
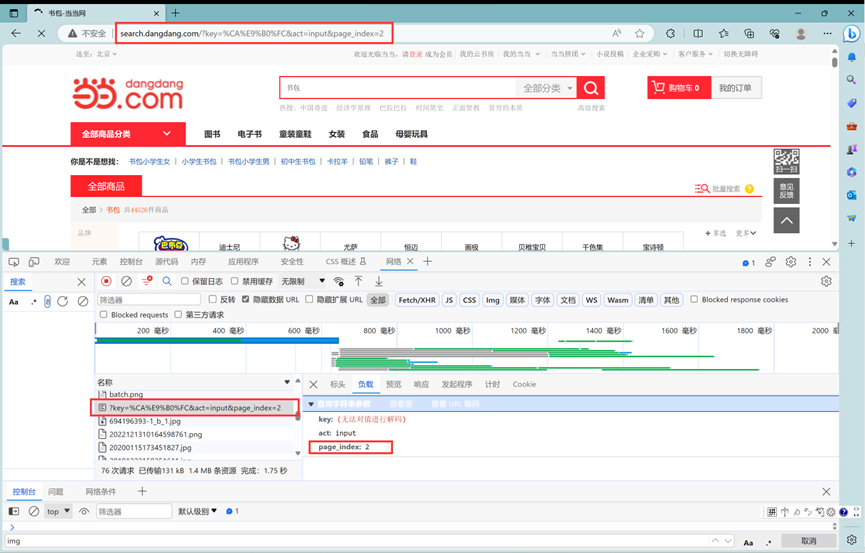
这时候发现了和页面有关的参数page_index,现在再尝试回到第一页。
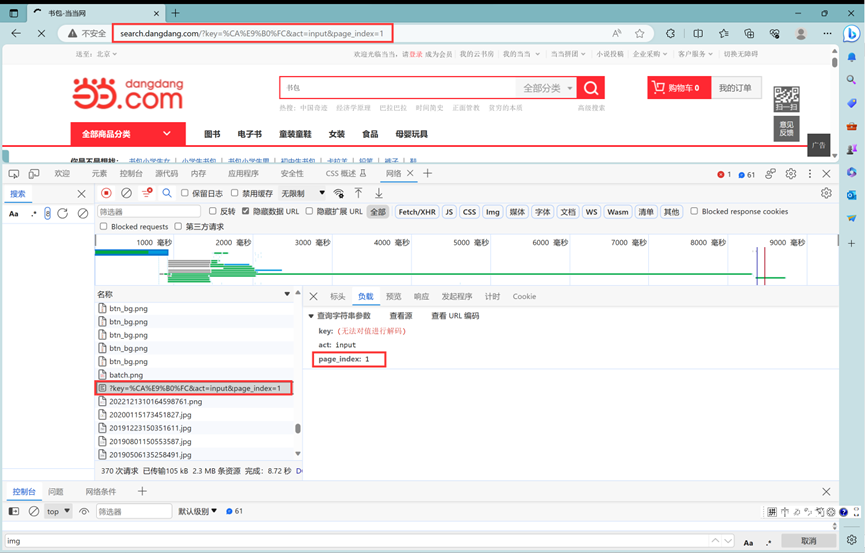
发现原来search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=1和search.dangdang.com/?key=%CA%E9%B0%FC&act=input都是指向第一页,那现在实现翻页只需要修改url中的page_index即可。
(2)心得体会
1.随着爬虫技术的发展,反爬手段也在跟进。其实第一下想爬的是淘宝,发现刷新页面返回的响应数据全是动态加密后的,于是转去了当当哈哈。
2.学会了巧用F12来观察页面结构,定位元素位置。
作业③:
o 要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
o 输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
(1)实验代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
url = r'https://xcb.fzu.edu.cn/info/1071/4481.htm'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(response, 'lxml')
img_list = soup.select("p[class='vsbcontent_img'] img")
for img in img_list:
url_ = img.attrs['src']
img_url_ = 'https://xcb.fzu.edu.cn{}'.format(url_)
response_ = requests.get(url=img_url_, headers=headers).content
# 使用os.path.basename获取URL的最后一部分,并替换不合法字符
filename = os.path.basename(url_).split('?')[0]
imgPath = './' + filename
with open(imgPath, 'wb') as fp:
fp.write(response_)
print(filename, '下载成功!!!')
(2)心得体会
在第二题的基础上,本题稍作改变就能拿下!努力努力冲冲冲

 浙公网安备 33010602011771号
浙公网安备 33010602011771号