


深度学习_梯度
1.梯度裁剪
在BP过程中会产生梯度消失(就是偏导无限接近0,导致长时记忆无法更新)(特别是RNN,LSTM,Transformer),那么最简单粗暴的方法,设定阈值,当梯度小于阈值时,更新的梯度为阈值,如下图所示:
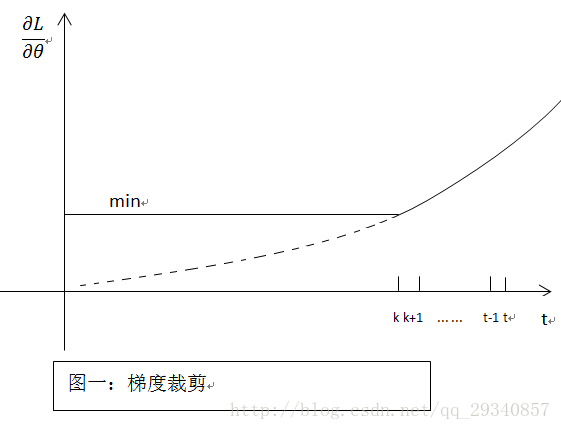
优点:简单粗暴
缺点:很难找到满意的阈值
2.nn.utils.clip_grad_norm(parameters, max_norm, norm_type=2)
这个函数是根据参数的范数来衡量的 . 通过梯度范数,来实现裁剪
所有梯度上范数在一起计算,就好像它们被连接成一个向量。 梯度内置就地修改。
Parameters:
- parameters (Iterable[Variable]) – 一个基于变量的迭代器,会进行归一化(原文:an iterable of Variables that will have gradients normalized)
- max_norm (float or int) – 梯度的最大范数(原文:max norm of the gradients)
- norm_type(float or int) – 规定范数的类型,默认为L2(原文:type of the used p-norm. Can be
'inf'for infinity norm) - error_if_nonfinite (bool) – 如果真,如果来自 :attr:
parametersisnan,inf, or-inf. 的梯度的总范数,则会引发错误 。默认是False(将来会改为True)
Returns:参数的总体范数(作为单个向量来看)(原文:Total norm of the parameters (viewed as a single vector).)

