Day 27:Python小知识+logging 日志管理模块
列表与 * 操作(浅拷贝)
深浅拷贝的操作还可以看:https://www.cnblogs.com/PiaYie/p/13722263.html#_label1
a = [[]]*7 # [[], [], [], [], [], [], []] id(a[0]) == id(a[1]) # True
由 * 操作复制出来的list,内存中的标识符是相等的,也就是说仅仅是浅复制,
在这种场景下,希望实现 id[0]、id[1] 不相等,修改 a[1] 不会影响 a[0]。
不使用 * 来生成其他列表,改用列表生成式即可:
b = [[] for _ in range(7)] # [[], [], [], [], [], [], []] id(b[0]) == id(b[1]) # False
删除列表元素

# 删除列表中的某个元素 # del_item_f_list([],del) def del_item_from_list(lst:list,e): for i in lst: if i == e: lst.remove(i) return lst del_item_from_list([1,3,3,3,5],3) output: [1, 3, 5]
可以看到,3并没有完全被remove,是因为在remove第一个三的之后,索引还在往前,但是remove操作又把第一个三之后的元素一起往前移动了一格.
解决办法:找到被删除元素后,删除,同时下次遍历索引不加一;若未找到,遍历索引加一。
# 删除列表中的某个元素 # del_item_f_list([],del) def del_item_from_list(lst:list,e): i = 0 while i < len(lst): if lst[i] == e: lst.remove(lst[i]) else: i += 1 return lst del_item_from_list([1,3,3,3,3,5],3) output: [1, 5]
函数默认参数为空
Python 函数的参数可设为默认值。如果一个默认参数类型为 list,默认值为设置为 []。
这种默认赋值,会有问题吗?
# 默认参数为空 # 函数功能,把volume的内容替换为步长加初始值 如果为空则返回空list def delta_val(val, volume=[]): if volume is None: volume = [] size = len(volume) for i in range(size): volume[i] = i + val return volume ret = delta_val(10)# [] ret.append(1) # [1] ret.append(2) # [1,2] ret = delta_val(10)# [10,11]
问题出在为什么第二次调用ret = delta_val(10)的时候是返回[10,11]???!
调用函数 delta_val 时,默认参数 volume 取值为默认值时,并且 volume 作为函数的返回值。再在函数外面做一些操作,再次按照默认值调用,并返回。整个过程,默认参数 volume 的 id 始终未变。
所以第二次调用时,volumn的取值是[1,2]而不是[].
为了避免这个问题,一是希望不要用默认参数返回,接受处理再调用,二是函数的默认参数不要设置为[],而是设置为None.
def delta_val(val, volume= None): if volume is None: volume = [] size = len(volume) for i in range(size): volume[i] = i + val return volume ret = delta_val(10) ret.append(1) ret.append(2) ret = delta_val(10) ret output: []
None对象,具有唯一、不变的标识号(当前环境下)
{} 和 ()
之前一直疑惑为什么经常看到(1.1,)这种跟了一个逗号的情况:
() 在python中用来表征元组,
mytuple = (1.1,1.2) print(type(mytuple)) output: <class 'tuple'>
然🦢,
a = (1.1) print(type(a)) output: <class 'float'>
创建元组的时候,如果只有一个对象,那么仅有一个()时,python会把整个对象去括号处理,所以需要在后面加一逗号,这样对象才会被python解释成元组
这个问题经常在函数传参的时候体现,如果一不注意,就会改变参数类型
栗子:
def fix_points(pts): for i in range(len(pts)): t = pts[i] if isinstance(t,tuple): t = t if len(t) == 2 else (t[0],0.0) pts[i] = t else: raise TypeError('pts 的元素类型要求为元组') return pts fix_points([(1.0,3.0),(2.0),(5.0,4.0)]) output: --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-27-f57f6c888e07> in <module>() 9 return pts 10 ---> 11 fix_points([(1.0,3.0),(2.0),(5.0,4.0)]) <ipython-input-27-f57f6c888e07> in fix_points(pts) 6 pts[i] = t 7 else: ----> 8 raise TypeError('pts 的元素类型要求为元组') 9 return pts 10 TypeError: pts 的元素类型要求为元组
正确的调用是在第二个参数(2.0)后面加上逗号(2.0,)
- 还要注意的是集合和字典,他们都用{},创建空集合和空字典:
# 创建空字典 mydict = {} print(type(mydict)) # 创建空集合 myset = set() print(type(myset)) output: <class 'dict'> <class 'set'>
解包
Python 中,支持多值赋值给多变量的操作。
弄清计算顺序是很重要的,多值赋值,(在基础不变的情况下)先计算出等号右侧的所有变量值后,再赋值给等号左侧变量。
# 多值赋值 a, b = 5, 7 a, b = b+7, a*2+b print(a,b) output: 14 17
多值赋值,是一种解包(unpack)操作。
那么打包是由何而来?等号右侧的多个变量,会被打包(pack)为一个可迭代对象。
这样说有点迷糊,那么只要只要可以用 = 操作方便地赋值。
比如说,getvalue 函数返回一个 list,如下:
def getvalue(): result = [1234568,'xiaoming','address','telephone',['','','...']] return result
但是我们只要前两项,而不关心其他的返回。那么只需要把其他不想要的项放到 others 变量中,并在前加一个 *,如下所示:
id, name,*others = getvalue() print(id) print(name) print(others) output: 1 xiaoming ['address', 'telephone', ['', '', '...']] # 把之后的打成了一个包,还是可迭代啊
- 如果不用*,那么参数个数就会不匹配,报ValueError错误。
*others会被单独解析为一个 list
访问控制
Python 是一门动态语言,支持属性的动态添加和删除。
而 Python 面向对象编程(OOP)中,提供很多双划线开头和结尾的函数,它们是系统内置方法,被称为魔法方法。
- __getattr__ 和 __setattr__ 是关于控制属性访问的方法。(新知识)
如下,访问类不存在属性时,程序默认会抛出 AttributeError 异常。
# 访问控制 class Student(): def __init__(self,idt,name): self.id = idt self.name = name piayie = Student(1234568,'piayie') print(piayie.age ) output: --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-45-1ad34eedc7a4> in <module>() ----> 1 print(piayie.age ) AttributeError: 'Student' object has no attribute 'age'
上面是默认访问某种不存在属性时的返回,现在想要自己定义,那么就重写 __getattr__ 方法,会定义如果不存在某种属性时的行为。
class Student(): def __init__(self, idt, name): self.id = idt self.name = name def __getattr__(self, prop_name): print('property %s not existed, would be set to None automatically' % (prop_name,)) self.prop_name = None piayie = Student(1234568,'piayie') print(piayie.age ) output: property age not existed, would be set to None automatically None
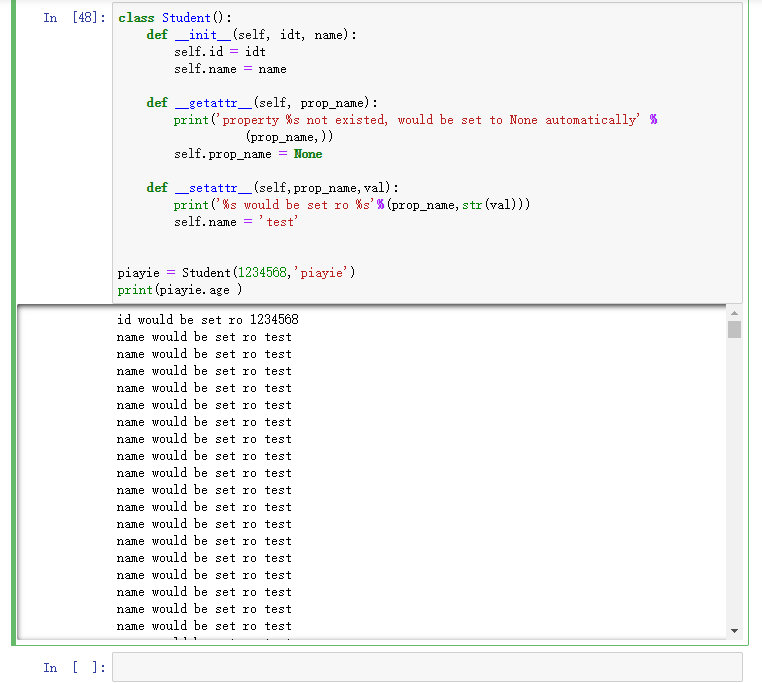
__setattr__,不管属性是否存在,属性赋值前都会调用此函数。(默认的__setattr__好像是啥都不做)
class Student(): def __init__(self, idt, name): self.id = idt self.name = name def __getattr__(self, prop_name): print('property %s not existed, would be set to None automatically' % (prop_name,)) self.prop_name = None def __setattr__(self,prop_name,val): print('%s would be set ro %s'%(prop_name,str(val))) piayie = Student(1234568,'piayie') print(piayie.age ) output: id would be set ro 1234568 name would be set ro piayie property age not existed, would be set to None automatically prop_name would be set ro None None
但是,这里有一个坑,如果在 __setattr__ 方法中再做属性赋值,那么就会陷入循环。。。
师傅,使不得!
谨记,不要在 __setattr__ 方法中再做属性赋值。
中括号访问
我们经常使用中括号加索引的方法[index]来访问对象某个元素的值,有没有想过为什么可以这样?没有。
其实是对象正确定义了魔法方法 __getitem__,就能实现 [index] 功能。
class Table(object): def __init__(self,df:dict): self.df = df def __getitem__(self,column_name): return self.df[column_name] t = Table({'ids':list(range(5)),'names':'piayie ori atta bawbaw'.split()}) print(t['names']) print(t['ids']) output: ['piayie', 'ori', 'atta', 'bawbaw'] [0, 1, 2, 3, 4]
鸭子类型
# 鸭子类型 class Plane(): def run(self): print('plane is flying...') class Clock(): def run(self): print('clock is rotating...') def using_run(duck): print(duck.run())
Plane和Clock都有方法run, 不像其他静态语言中duck.run(),函数体内使用此类型的方法或属性时,参数类型就必须为此类型或子类。
在python中不用,个个都是大哥
因都有 run 方法,Python 认为它们看起来就是 duck 类型,因此,Plane 对象和 Clock 对象就被看作 duck 类型。
元类type
Python 界的领袖 Tim Peters 说过:“元类就是深度的魔法,99% 的用户应该根本不必为此操心。”

使用type创建的类和使用class 关键字创建的Student 类一模一样。
对象序列化
对象序列化,是指将内存中的对象转化为可存储或传输的过程。很多场景,直接一个类对象,传输不方便。但是,当对象序列化后,就会更加方便,因为约定俗成的,接口间的调用或者发起的 Web 请求,一般使用 JSON 串传输(JSON模块)。
class Student(): def __init__(self,**args): self.ids = args['ids'] self.name = args['name'] self.address = args['address'] # 创建两个实例 dabai = Student(ids = 111,name = 'dabai',address = '北京') liuedan = Student(ids = 2222,name = 'liuedan',address = '南京') import json with open('json.txt','w') as f: json.dump([dabai,liuedan], f, default=lambda obj: obj.__dict__, ensure_ascii=False, indent=2, sort_keys=True)
生成的json格式的文件为:


[ { "address": "北京", "ids": 111, "name": "dabai" }, { "address": "南京", "ids": 2222, "name": "liuedan" } ]
- 中括号 + 字典(每一个实例)
- 双引号
- 写法,按上面的生成写法就挺好的
logging日志模块的使用
-------------------------------------------------------随便说说-------------------------------------------------------
说起来,因为只学代码,也没有真正接受过上线的项目,对于日志的接触少之又少。
调试代码由最开始的print方法
到后面在IDE上可以直接看变量或是什么
不得不说都是好方法。
但是当程序上线后一般运行在linux服务器上,调试并不是那么容易。
一般的解决方案,在代码中想 print 的信息,也要写入到日志文件中,在磁盘上保存起来。此时,遇到问题后,找到并分析对应的日志文件就行,这种解决问题的方法更可取,效率也会更高。
那也不能一直写日志啊,总有一天磁盘会满,文件太大也没有看的欲望,
但是只要有一套合理的管理体系,涉及方方面面的考量,那么就会是强大的工具。
像大名鼎鼎的、适用于 Java 开发的 log4j,便是一套设计优秀的日志管理包。
Python 中,也有一个模块 logging,也能做到高效的日志管理。
-------------------------------------------------------华丽的分割线-------------------------------------------------------
logging 库,和它的四大组件:记录器、处理器、过滤器和格式化器。
logging 模块能按照指定周期切分日志文件,下面是一个基本的日志类,同时将日志显示在控制台和写入文件中,同时按天为周期 切分 日志文件。
import logging from logging import handlers class Logger(object): kv = { 'debug': logging.DEBUG, 'info': logging.INFO, 'warning': logging.WARNING, 'error': logging.ERROR, 'crit': logging.CRITICAL } # 日志级别关系映射 def __init__(self, filename, level='info', when='D', backCount=3, fmt='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'): self.logger = logging.getLogger(filename) format_str = logging.Formatter(fmt) # 设置日志格式 self.logger.setLevel(self.kv.get(level)) # 设置日志级别 sh = logging.StreamHandler() # 往屏幕上输出 sh.setFormatter(format_str) # 设置屏幕上显示的格式 th = handlers.TimedRotatingFileHandler( filename=filename, when=when, backupCount=backCount, encoding='utf-8') th.setFormatter(format_str) # 设置文件里写入的格式 self.logger.addHandler(sh) # 把对象加到 logger 里 self.logger.addHandler(th)
实例化Logger为log对象,日志级别为 debug 及按以上设置写入日志文件:
log = Logger('all.log', level='debug').logger
决定往这个日志文件(log对象)中写入什么:
class Student: def __init__(self, id, name): self.id = id self.name = name log.info('学生 id: %s, name: %s' % (str(id), str(name))) @property def score(self): return self.__score @score.setter def score(self, score): if isinstance(score, int): self.__score = score log.info('%s得分:%d' % (self.name, self.score)) else: log.error('学生分数类型为 %s,不是整型' % (str(type(score)))) raise TypeError('学生分数类型为 %s,不是整型' % (str(type(score)))) xiaoming = Student(10010, 'xiaoming') xiaoming.score = 88 xiaohong = Student('001', 'xiaohong') xiaohong.score = 90.6 output: 2021-07-19 13:17:56,553 - <ipython-input-73-b70ed4c5ceeb>[line:5] - INFO: 学生 id: 10010, name: xiaoming 2021-07-19 13:17:56,567 - <ipython-input-73-b70ed4c5ceeb>[line:15] - INFO: xiaoming得分:88 2021-07-19 13:17:56,568 - <ipython-input-73-b70ed4c5ceeb>[line:5] - INFO: 学生 id: 001, name: xiaohong 2021-07-19 13:17:56,569 - <ipython-input-73-b70ed4c5ceeb>[line:17] - ERROR: 学生分数类型为 <class 'float'>,不是整型 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-77-d5cb24f28de5> in <module>() 2 xiaoming.score = 88 3 xiaohong = Student('001', 'xiaohong') ----> 4 xiaohong.score = 90.6 <ipython-input-73-b70ed4c5ceeb> in score(self, score) 16 else: 17 log.error('学生分数类型为 %s,不是整型' % (str(type(score)))) ---> 18 raise TypeError('学生分数类型为 %s,不是整型' % (str(type(score)))) TypeError: 学生分数类型为 <class 'float'>,不是整型
日志文件:
2021-07-19 13:22:50,168 - <ipython-input-81-b70ed4c5ceeb>[line:5] - INFO: 学生 id: 10010, name: xiaoming 2021-07-19 13:22:50,185 - <ipython-input-81-b70ed4c5ceeb>[line:15] - INFO: xiaoming得分:88 2021-07-19 13:22:50,186 - <ipython-input-81-b70ed4c5ceeb>[line:5] - INFO: 学生 id: 001, name: xiaohong 2021-07-19 13:22:50,187 - <ipython-input-81-b70ed4c5ceeb>[line:17] - ERROR: 学生分数类型为 <class 'float'>,不是整型
大概记住这个过程即可,具体的使用以后再详细学习。
- 设置Logger -> 生成log对象 -> 往log里面写入内容


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~