Day 2:Python 四大数据类型总结
基本数据类型(数值型、容器型、字符串、自定义类型)
数值型
Python 中的数据皆是对象,比如被熟知的 int 整型对象、float 双精度浮点型、bool 逻辑对象,它们都是单个元素。
容器型
希望有一个整理箱把一些东西整理起来,常用的:list 列表对象、 tuple 元组对象、dict 字典对象、set 集合对象。
- 使用一对中括号
[],创建一个 list 型变量:
lst = [1,3,5] # list 变量
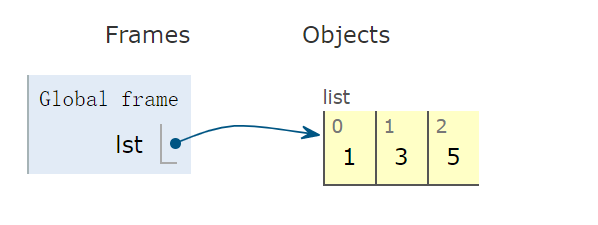
注意:list右侧容器为开环的,意味着可以向容器中增加和删除元素。
- 使用一对括号
(),创建一个 tuple 型对象:
tup = (1,3,5) # tuple 变量
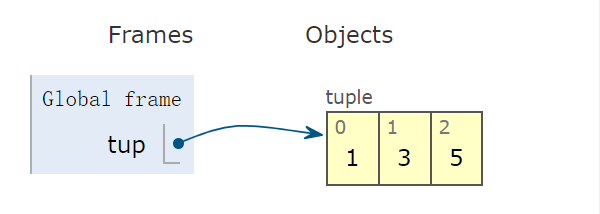
tuple右侧容器为闭合的,意味着一旦创建元组后,便不能再向容器中增删元素。
值得一提的是,如果tuple中只有单个元素,需要在后面加一个逗号,否则会被认为是元素本身:
tup = (1,) # 必须保留逗号

>>> tup = ('66666') >>> print(type(tup)) <class 'str'> >>> tup1 = ('66666, ') >>> print(type(tup1)) <class 'str'> >>> tup2 = ('66666' , ) >>> print(type(tup2)) <class 'tuple'> >>>
- 使用一对花括号
{}另使用冒号:,创建一个 dict 对象(哈希表):
{键1:值1,键2:值2,键3:值3,…}
dic = {'a':1, 'b':3, 'c':5} # dict变量
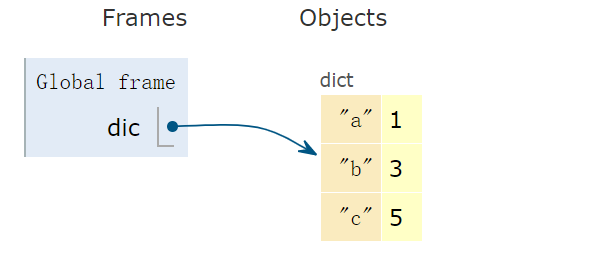
- 仅使用一对花括号
{},创建一个 set 对象:
s = {1,3,5} # 集合变量
python的数据类型很牛逼!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
几个栗子我们吃一吃,下下饭!
1.去最求平均
即去掉一个最低分去掉一个最高分,求平均:
def score_mean(lst): lst.sort() lst2=lst[1:-1] return round((sum(lst2)/len(lst2)),1) lst=[9.1, 9.0,8.1, 9.7, 19,8.2, 8.6,9.8] print(score_mean(lst)) # 9.1
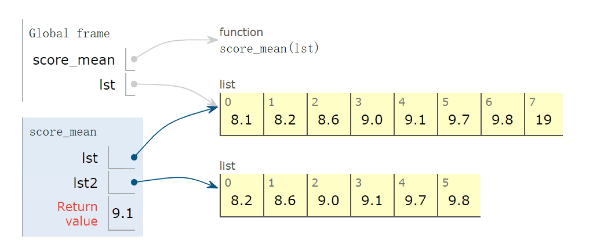
其中,说一下round用法:
round() 方法返回浮点数x的四舍五入值。
语法 : 以下是 round() 方法的语法: round( x [, n])
参数: x -- 数值表达式。 n -- 数值表达式,表示从小数点位数。
返回值: 返回浮点数x的四舍五入值。
2.打印乘法表
1*1=1 1*2=2 2*2=4 1*3=3 2*3=6 3*3=9 1*4=4 2*4=8 3*4=12 4*4=16 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
>>> for i in range(1, 10): ... for j in range(1, i+1): ... print('%d*%d=%d' % (j, i, j*i), end='\t') ... print() ... 1*1=1 1*2=2 2*2=4 1*3=3 2*3=6 3*3=9 1*4=4 2*4=8 3*4=12 4*4=16 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81 >>>
3.样本抽样
使用 sample 抽样,如下例子从 100 个样本中随机抽样 10 个:
from random import randint,sample def get_10_item_from_sample(): lst = [randint(0,50) for _ in range(100)] print(lst[:5]) lst_sample = sample(lst,10) print(lst_sample) lst_sample.sort() print(lst_sample) get_10_item_from_sample() 输出: [50, 23, 39, 26, 13] [46, 33, 49, 33, 50, 18, 2, 39, 48, 17] [2, 17, 18, 33, 33, 39, 46, 48, 49, 50]
字符串
注意 Python 中没有像 C++ 表示的字符类型(char),所有的字符或串都被统一为 str 对象。如单个字符 c 的类型也为 str。
str 类型会被经常使用,先列举 5 个被高频使用的方法。
strip 用于去除字符串前后的空格:
In [1]: ' I love python\t\n '.strip()
Out[1]: 'I love python'
replace 用于字符串的替换:
In [2]: 'i love python'.replace(' ','_')
Out[2]: 'i_love_python'
join 用于合并字符串:
In [3]: '_'.join(['book', 'store','count'])
Out[3]: 'book_store_count'
title 用于单词的首字符大写:
In [4]: 'i love python'.title()
Out[4]: 'I Love Python'
find 用于返回匹配字符串的起始位置索引:
In [5]: 'i love python'.find('python')
Out[5]: 7
小知识:字符串的匹配操作除了使用 str 封装的方法外,Python 的 re 正则模块功能更加强大,写法更为简便,广泛适用于爬虫、数据分析等。
下面这个案例实现:密码安全检查,使用正则表达式非常容易实现。
简单的密码安全要求:
- 要求密码为 6 到 20 位;
- 密码只包含英文字母和数字。
import re pat = re.compile(r'\w{6,20}') # 这是错误的,因为 \w 通配符匹配的是字母,数字和下划线,题目要求不能含有下划线 # 使用最稳的方法:\da-zA-Z 满足“密码只包含英文字母和数字” # \d匹配数字 0-9 # a-z 匹配所有小写字符;A-Z 匹配所有大写字符 pat = re.compile(r'[\da-zA-Z]{6,20}') bool1 = pat.fullmatch('qaz12') # 返回 None,长度小于 6 bool2 = pat.fullmatch('qaz12wsxedcrfvtgb67890942234343434') # None 长度大于 22 bool2 = pat.fullmatch('qaz_231') # None 含有下划线
自定义类型
Python 使用关键字 class 定制自己的类,self 表示类实例对象本身。
一个自定义类内包括属性、方法,其中有些方法是自带的。
类(对象):
class Dog(object): pass
定义一个 Dog 对象,它继承于根类 object,pass 表示没有自定义任何属性和方法。可以用Dog来创建一个实例:
wangwang = Dog()
>>> wangwang = Dog() >>> wangwang.__dir__() ['__module__',
'__dict__',
'__weakref__',
'__doc__',
'__repr__',
'__hash__',
'__str__',
'__getattribute__',
'__setattr__',
'__delattr__',
'__lt__',
'__le__',
'__eq__',
'__ne__',
'__gt__',
'__ge__',
'__init__',
'__new__',
'__reduce_ex__',
'__reduce__',
'__subclasshook__',
'__init_subclass__',
'__format__',
'__sizeof__',
'__dir__',
'__class__'] >>>
这些自带的方法,与创建类时自定义个性化行为有关。慢慢积累到这里吧!比如:
- __init__ 方法能定义一个带参数的类;
- __new__ 方法自定义实例化类的行为;
- __getattribute__ 方法自定义读取属性的行为;
- __setattr__ 自定义赋值与修改属性时的行为。
类的属性:
def __init__(self, name, dtype):
self.name = name
self.dtype = dtype
通过 __init__,定义 Dog 对象的两个属性:name、dtype。
类的实例:
wangwang = Dog('wangwang','cute_type')
wangwang 是 Dog 类的实例。
类的方法:
def shout(self):
print('I\'m %s, type: %s' % (self.name, self.dtype))
注意:
- 自定义方法的第一个参数必须是 self,它指向实例本身,如 Dog 类型的实例 dog;
- 引用属性时,必须前面添加 self,比如
self.name等。
>>> class Dog(object): ... def __init__(self,name,dtype): ... self.name=name ... self.dtype=dtype ... def shout(self): ... print('I\'m %s, type: %s' % (self.name, self.dtype)) ... >>> wangwang = Dog('wangwang','cute_type') >>> wangwang.name 'wangwang' >>> wangwang.dtype 'cute_type' >>> wangwang.shout() I'm wangwang, type: cute_type >>>
但是,出于代码的安全性,建的两个属性和一个方法都被暴露在外面,可被 wangwang 调用。这样的话,这些属性就会被任意修改:
>>> wangwang.name='wrong_name' >>> wangwang.name 'wrong_name' >>>
为了避免这样的情况出现,以将它变为私有变量。改动方法:属性前加 2 个 _ 后,变为私有属性。如:
同理,方法前加 2 个 _ 后,方法变为“私有方法”,只能在 Dog 类内被共享使用。
但是这样改动后,属性 name 不能被访问了,也就无法得知 wangwang 的名字叫啥。
那不是白整嘛?放心 ,直接新定义一个方法就行:
def get_name(self): return self.__name
综合代码:
In [52]: class Dog(object):
...: def __init__(self,name,dtype):
...: self.__name=name
...: self.__dtype=dtype
...: def shout(self):
...: print('I\'m %s, type: %s' % (self.name, self.dtype))
...: def get_name(self):
...: return self.__name
...:
In [53]: wangwang = Dog('wangwang','cute_type')
In [54]: wangwang.get_name()
Out[54]: 'wangwang'
但是,通过此机制,改变属性的可读性或可写性,怎么看都不太优雅!因为无形中增加一些冗余的方法,如 get_name。
就不能有个优雅的方法将某个属性设置为可读或者可写吗?有
栗子:
自定义一个最精简的 Book 类,它继承于系统的根类 object:
class Book(object): def __init__(self,name,sale): self.__name = name self.__sale = sale
使用 Python 自带的 property 类,就会优雅地将 name 变为只读的。
@property def name(self): return self.__name
使用 @property 装饰后 name 变为属性,意味着 .name 就会返回这本书的名字,而不是通过 .name() 这种函数调用的方法。这样变为真正的属性后,可读性更好。
>>> class Dog(object): ... def __init__(self,name,dtype): ... self.__name=name ... self.__dtype=dtype ... def shout(self): ... rint('I\'m %s, type: %s' % (self.name, self.dtype)) ... >>> wangwang = Dog('wangwang','cute_type') >>> wangwang.name Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Dog' object has no attribute 'name' >>> class Book(object): ... def __init__(self,name,sale): ... self.__name = name ... self.__sale = sale ... @property ... def name(self): ... return self.__name ... >>> a_book = Book('magic_book',100000) >>> a_book.name 'magic_book' >>>
property 是 Python 自带的类,属于装饰器!
如果使 name 既可读又可写,就再增加一个装饰器 @name.setter。
In [105]: class Book(object):
...: def __init__(self,name,sale):
...: self.__name = name
...: self.__sale = sale
...: @property
...: def name(self):
...: return self.__name
...: @name.setter
...: def name(self,new_name):
...: self.__name = new_name
In [106]: a_book = Book('magic_book',100000)
In [107]: a_book.name = 'magic_book_2.0'
In [108]: a_book.name
Out[108]: 'magic_book_2.0'
是不是很奇怪@property为啥变成了@name.setter, name 已经被包装为 property (可读)实例,调用实例上的 setter(可写) 函数再包装 name 后就会可写。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~