实验4
1. 实验任务1
#include <stdio.h>
#define N 4
void test1() {
int a[N] = {1, 9, 8, 4};
int i;
// 输出数组a占用的内存字节数
printf("sizeof(a) = %d\n", sizeof(a));
// 输出int类型数组a中每个元素的地址、值
for (i = 0; i < N; ++i)
printf("%p: %d\n", &a[i], a[i]);
// 输出数组名a对应的值
printf("a = %p\n", a);
}
void test2() {
char b[N] = {'1', '9', '8', '4'};
int i;
// 输出数组b占用的内存字节数
printf("sizeof(b) = %d\n", sizeof(b));
// 输出char类型数组b中每个元素的地址、值
for (i = 0; i < N; ++i)
printf("%p: %c\n", &b[i], b[i]);
// 输出数组名b对应的值
printf("b = %p\n", b);
}
int main() {
printf("测试1: int类型一维数组\n");
test1();
printf("\n测试2: char类型一维数组\n");
test2();
return 0;
}
截图:
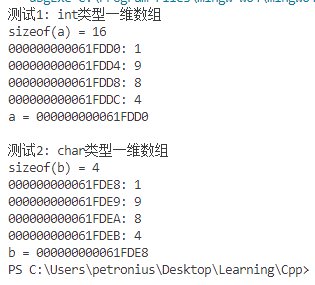
用文字回答问题:
① int型数组a,在内存中是否是连续存放的?每个元素占用几个内存字节单元? 数组名a对应
的值,和&a[0]是一样的吗?
② char型数组b,在内存中是否是连续存放的?每个元素占用几个内存字节单元? 数组名b对
应的值,和&b[0]是一样的吗?
A:(1)在内存中是连续存放的,占4字节,一样。
(2)(1)在内存中是连续存放的,占1字节,一样。
task1_2.c程序源码,
#include <stdio.h>
#define N 2
#define M 4
void test1() {
int a[N][M] = {{1, 9, 8, 4}, {2, 0, 4, 9}};
int i, j;
// 输出int类型二维数组a占用的内存字节数
printf("sizeof(a) = %d\n", sizeof(a));
// 输出int类型二维数组a中每个元素的地址、值
for (i = 0; i < N; ++i)
for (j = 0; j < M; ++j)
printf("%p: %d\n", &a[i][j], a[i][j]);
printf("\n");
// 输出int类型二维数组名a, 以及,a[0], a[1]的值
printf("a = %p\n", a);
printf("a[0] = %p\n", a[0]);
printf("a[1] = %p\n", a[1]);
printf("\n");
}
void test2() {
char b[N][M] = {{'1', '9', '8', '4'}, {'2', '0', '4', '9'}};
int i, j;
// 输出char类型二维数组b占用的内存字节数
printf("sizeof(b) = %d\n", sizeof(b));
// 输出char类型二维数组b中每个元素的地址、值
for (i = 0; i < N; ++i)
for (j = 0; j < M; ++j)
printf("%p: %c\n", &b[i][j], b[i][j]);
printf("\n");
// 输出char类型二维数组名b, 以及,b[0], b[1]的值
printf("b = %p\n", b);
printf("b[0] = %p\n", b[0]);
printf("b[1] = %p\n", b[1]);
}
int main() {
printf("测试1: int型两维数组");
test1();
printf("\n测试2: char型两维数组");
test2();
return 0;
}
截图:
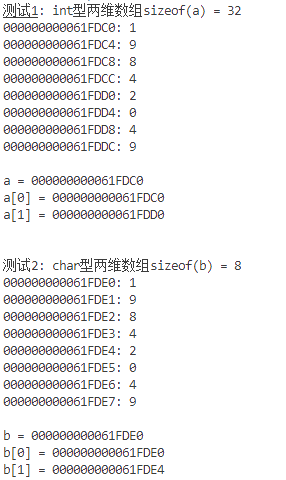
用文字回答问题:
① int型二维数组a,在内存中是否是"按行连续存放"的?每个元素占用几个内存字节单元?
数组名a的值、a[0]的值、&a[0][0]的值,在数字字面值上,是一样的吗?
② char型二维数组b,在内存中是否是"按行连续存放"的?每个元素占用几个内存字节单元?
数组名b的值、b[0]的值、&b[0][0]的值,在数字字面值上,是一样的吗?
③ 对于二维数组, 观察a[0], a[1]的值,它们之间相差多少?观察b[0]和b[1]的值,它们之间
相差多少?有什么规律吗?
A: (1)是连续存放的,4字节,不一样。
(2)是连续存放的,1字节,不一样。
(3)相差16字节,4字节,。
2. 实验任务2
#include <stdio.h>
#include <string.h>
#define N 80
void swap_str(char s1[N], char s2[N]);
void test1();
void test2();
int main() {
printf("测试1: 用两个一维char数组,实现两个字符串交换\n");
test1();
printf("\n测试2: 用二维char数组,实现两个字符串交换\n");
test2();
return 0;
}
void test1() {
char views1[N] = "hey, C, I hate u.";
char views2[N] = "hey, C, I love u.";
printf("交换前: \n");
puts(views1);
puts(views2);
swap_str(views1, views2);
printf("交换后: \n");
puts(views1);
puts(views2);
}
void test2() {
char views[2][N] = {"hey, C, I hate u.",
"hey, C, I love u."};
printf("交换前: \n");
puts(views[0]);
puts(views[1]);
swap_str(views[0], views[1]);
printf("交换后: \n");
puts(views[0]);
puts(views[1]);
}
void swap_str(char s1[N], char s2[N]) {
char tmp[N];
strcpy(tmp, s1);
strcpy(s1, s2);
strcpy(s2, tmp);
}
函数模块swap_str()的形参是一维数组。为什么test1()和test2()模块中调用时,实参的书写形
式一个不加[]、一个加[]?
类似地,test1()和test2()模块中,调用标准库函数puts()实现输出时,实参书写形式也类同。
思考并归纳、总结其用法。
A:这两种方式在大多数情况下是等效的。
3. 实验任务3
task3_1.c源码,
#include <stdio.h>
#define N 80
int count(char x[]);
int main() {
char words[N+1];
int n;
while(gets(words) != NULL) {
n = count(words);
printf("单词数: %d\n\n", n);
}
return 0;
}
int count(char x[]) {
int i;
int word_flag = 0; // 用作单词标志,一个新单词开始,值为1;单词结束,值为0
int number = 0; // 统计单词个数
for(i = 0; x[i] != '\0'; i++) {
if(x[i] == ' ')
word_flag = 0;
else if(word_flag == 0) {
word_flag = 1;
number++;
}
}
return number;
}
运行结果:

task3_2.c源码,
#include <stdio.h>
#define N 1000
int main() {
char line[N];
int word_len; // 记录当前单词长度
int max_len; // 记录最长单词长度
int end; // 记录最长单词结束位置
int i;
while(gets(line) != NULL) {
word_len = 0;
max_len = 0;
end = 0;
i = 0;
while(1) {
// 跳过连续空格
while(line[i] == ' ') {
word_len = 0; // 单词长度置0,为新单词统计做准备
i++;
}
// 在一个单词中,统计当前单词长度
while(line[i] != '\0' && line[i] != ' ') {
word_len++;
i++;
}
// 更新更长单词长度,并,记录最长单词结束位置
if(max_len < word_len) {
max_len = word_len;
end = i; // end保存的是单词结束的下一个坐标位置
}
// 遍历到文本结束时,终止循环
if(line[i] == '\0')
break;
}
// 输出最长单词
printf("最长单词: ");
for(i = end - max_len; i < end; ++i)
printf("%c", line[i]);
printf("\n\n");
}
return 0;
}
结果:

思考
统计文本中单词数,统计文本中最长单词,目前这两个代码实现都对文本形式做了简化限制
(比如要求只能以空格间隔)。统计的单词长度可能包含一些除了空格以外的标点符号。
如果想要更精确统计单词数、最长单词数,你认为可以如何处理?
A:在统计单词长度时,可以在计算单词长度之前去除标点符号。这可以通过一次遍历文本,将标点符号替换为空格或直接移除来实现。
(如果已经尝试用代码实现,请附上改进后的代码和测试样例截图)
4. 实验任务4
代码:
#define N 100
#include <stdio.h>
// 函数声明
void dec_to_n(int x, int n);
int main() {
int x;
printf("输入一个十进制整数: ");
while (scanf("%d", &x) != EOF) {
dec_to_n(x, 2); // 转换为二进制
dec_to_n(x, 8); // 转换为八进制
dec_to_n(x, 16); // 转换为十六进制
printf("\n输入一个十进制整数: ");
}
return 0;
}
// 函数定义
void dec_to_n(int x, int n) {
// 存储每一位的余数
int remainder[N];
// 初始化
int i = 0;
// 当 x 不为 0 时,进行进制转换
while (x != 0) {
remainder[i] = x % n;
x = x / n;
i++;
}
// 打印输出
printf("%d进制数为: ", n);
for (int j = i - 1; j >= 0; j--) {
if (remainder[j] < 10) {
printf("%d", remainder[j]);
} else {
printf("%c", 'A' + remainder[j] - 10);
}
}
printf("\n");
}
结果:

5. 实验任务5
代码
#define N 5
#include <stdio.h>
// 函数声明
void input(int x[], int n);
void output(int x[], int n);
double average(int x[], int n);
void bubble_sort(int x[], int n);
int main() {
int scores[N];
double ave;
printf("录入%d个分数:\n", N);
input(scores, N);
printf("\n输出课程分数: \n");
output(scores, N);
printf("\n课程分数处理: 计算均分、排序...\n");
ave = average(scores, N);
bubble_sort(scores, N);
printf("\n输出课程均分: %.2f\n", ave);
printf("\n输出课程分数(高->低):\n");
output(scores, N);
return 0;
}
// 函数定义
// 输入n个整数保存到整型数组x中
void input(int x[], int n) {
int i;
for (i = 0; i < n; ++i)
scanf("%d", &x[i]);
}
// 输出整型数组x中n个元素
void output(int x[], int n) {
int i;
for (i = 0; i < n; ++i)
printf("%d ", x[i]);
printf("\n");
}
// 计算整型数组x中n个元素均值,并返回
double average(int x[], int n) {
int i;
double sum = 0.0;
for (i = 0; i < n; ++i)
sum += x[i];
return sum / n;
}
// 对整型数组x中的n个元素降序排序
void bubble_sort(int x[], int n) {
int i, j, temp;
for (i = 0; i < n - 1; ++i) {
for (j = 0; j < n - i - 1; ++j) {
if (x[j] < x[j + 1]) {
// 交换元素
temp = x[j];
x[j] = x[j + 1];
x[j + 1] = temp;
}
}
}
}
结果:

6. 实验任务6
补充完整的task5.c源码,
#include <stdio.h>
#include <string.h>
#define N 5
#define M 20
// 函数声明
void output(char str[][20], int n);
void bubble_sort(char str[][20], int n);
int main() {
char name[][20] = {"Bob", "Bill", "Joseph", "Taylor", "George"};
printf("输出初始名单:\n");
output(name, 5);
printf("\n排序中...\n");
bubble_sort(name, 5); // 函数调用
printf("\n按字典序输出名单:\n");
output(name, 5);
return 0;
}
// 函数定义
// 功能:按行输出二维数组中的字符串
void output(char str[][20], int n) {
int i;
for (i = 0; i < n; ++i)
printf("%s\n", str[i]);
}
// 功能:使用冒泡排序算法对二维数组str中的n个字符串按字典序排序
void bubble_sort(char str[][20], int n) {
int i, j;
char temp[20];
for (i = 0; i < n - 1; ++i) {
for (j = 0; j < n - i - 1; ++j) {
if (strcmp(str[j], str[j + 1]) > 0) {
// 交换字符串
strcpy(temp, str[j]);
strcpy(str[j], str[j + 1]);
strcpy(str[j + 1], temp);
}
}
}
}
结果:

7. 实验任务7
补充完整的task7.c源码,
#include <stdio.h>
#include <stdbool.h>
// 函数声明
bool hasDuplicateDigits(int num);
int main() {
int num;
printf("从键盘上输入整数(1<= 整数数位 <=100),输入EOF结束:\n");
while (scanf("%d", &num) != EOF) {
if (hasDuplicateDigits(num)) {
printf("YES\n");
} else {
printf("NO\n");
}
}
return 0;
}
// 函数定义
// 功能:检查整数是否包含重复数字
bool hasDuplicateDigits(int num) {
// 用于标记数字是否已经出现
bool digitSeen[10] = {false};
// 逐位检查数字
while (num > 0) {
int digit = num % 10;
// 如果数字已经出现过,返回true
if (digitSeen[digit]) {
return true;
}
// 标记数字已经出现
digitSeen[digit] = true;
// 去掉最后一位
num /= 10;
}
// 所有数字都不重复,返回false
return false;
}
结果:

8. 实验任务8
补充完整的task8.c源码,
#include <stdio.h>
// 函数声明
void output(int x[][100], int n); // 函数声明
void rotate_to_right(int x[][100], int n); // 函数声明
int main() {
int t[][100] = {
{21, 12, 13, 24},
{25, 16, 47, 38},
{29, 11, 32, 54},
{42, 21, 33, 10}
};
printf("原始矩阵:\n");
output(t, 4); // 函数调用
rotate_to_right(t, 4); // 函数调用
printf("变换后矩阵:\n");
output(t, 4); // 函数调用
return 0;
}
// 函数定义
// 功能: 输出一个n*n的矩阵x
void output(int x[][100], int n) {
int i, j;
for (i = 0; i < n; ++i) {
for (j = 0; j < n; ++j)
printf("%4d", x[i][j]);
printf("\n");
}
}
// 功能: 把一个n*n的矩阵x,每一列向右移, 最右边被移出去的一列绕回左边
void rotate_to_right(int x[][100], int n) {
int i, j, temp;
// 遍历每一列
for (j = 0; j < n; ++j) {
// 保存最后一个元素
temp = x[n - 1][j];
// 向右移动每个元素
for (i = n - 1; i > 0; --i) {
x[i][j] = x[i - 1][j];
}
// 最后一个元素绕回左边
x[0][j] = temp;
}
}
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号