
BP神经网络算法程序实现鸢尾花(iris)数据集分类
作者有话说
最近学习了一下BP神经网络,写篇随笔记录一下得到的一些结果和代码,该随笔会比较简略,对一些简单的细节不加以说明。
目录
- BP算法简要推导
- 应用实例
- PYTHON代码
BP算法简要推导
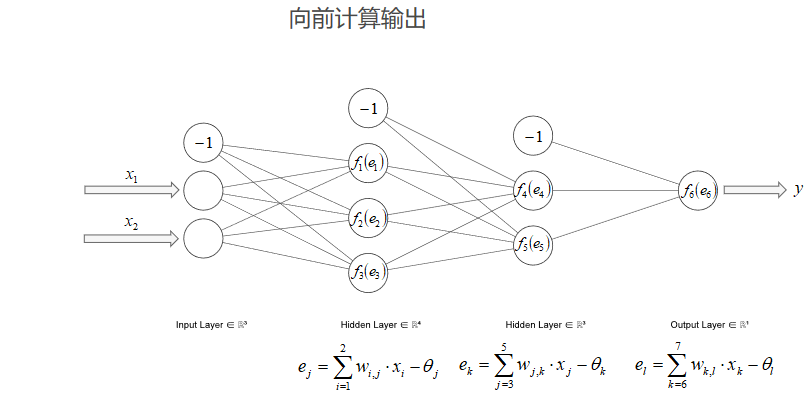
该部分用一个$2\times3\times 2\times1$的神经网络为例简要说明BP算法的步骤。
- 向前计算输出
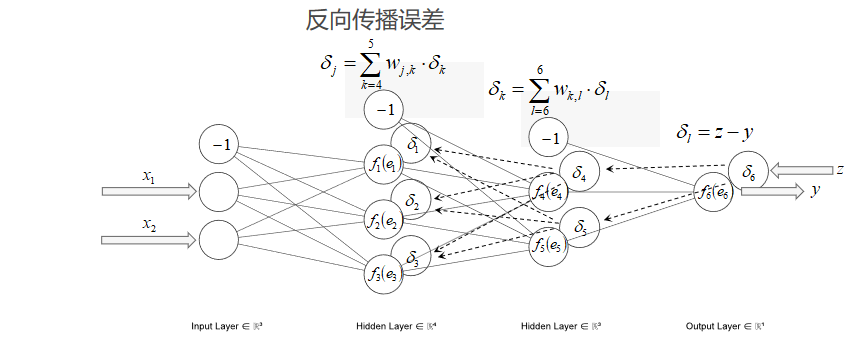
- 反向传播误差
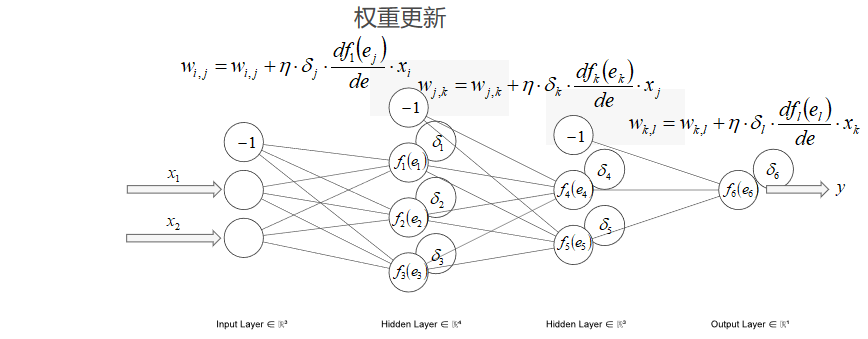
- 权重更新
应用实例
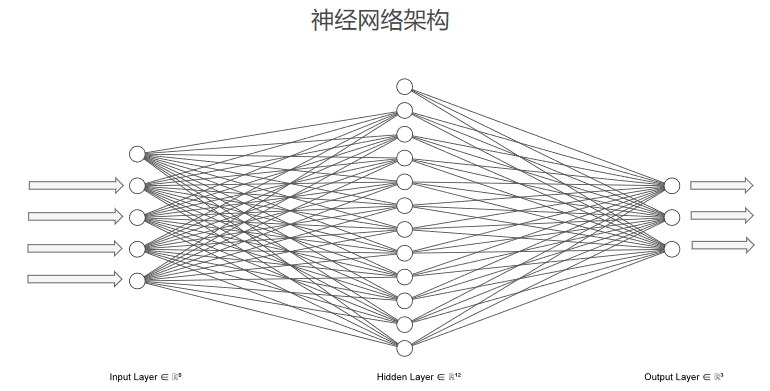
鸢尾花数据集一共有150个样本,分为3个类别,每个样本有4个特征,(数据集链接:http://archive.ics.uci.edu/ml/datasets/Iris)。针对该数据集,选取如下神经网络结构和激活函数
- 神经网络组成
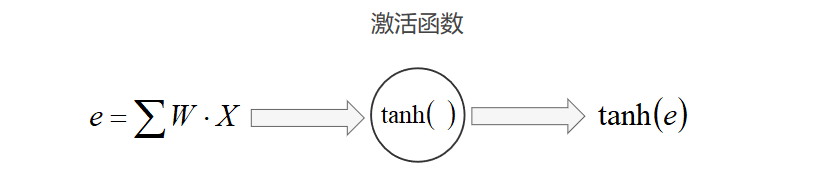
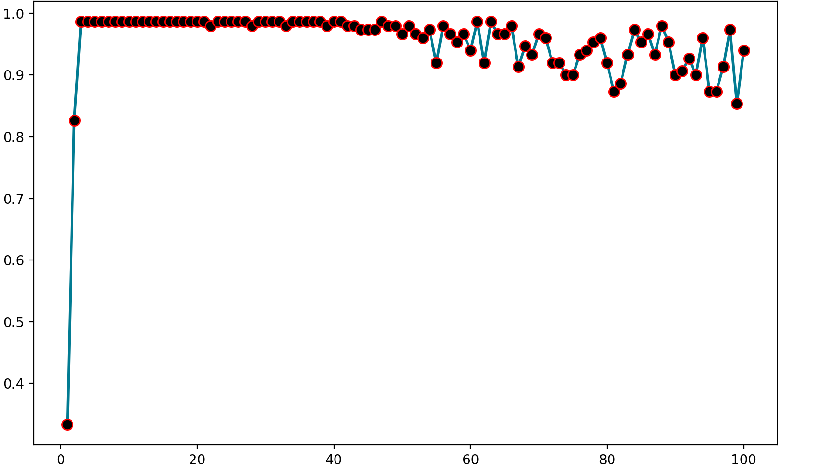
- 隐含层神经元个数对准确率的影响
调节隐含层神经元的个数,得到模型分类准确率的变化图像如下:
- 梯度更新步长对准确率的影响
调节梯度更新步长(学习率)的大小,得到模型分类准确率的变化图像如下:
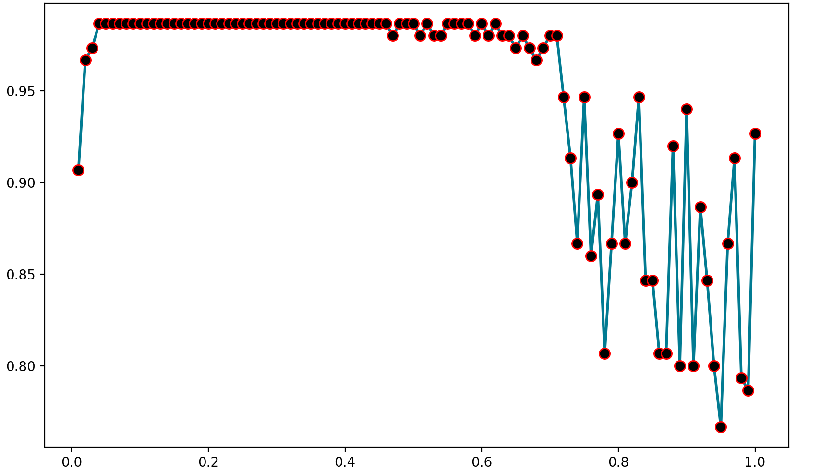
可见准确率最高可达98.6666666666667%
PYTHON代码
BPNeuralNetwork.py
# coding=utf-8
import numpy as np
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)
def logistic(x):
return 1.0 / (1.0 + np.exp(-x))
def logistic_derivative(x):
return logistic(x) * (1.0 - logistic(x))
class NeuralNetwork:
def __init__(self, layers, activation='tanh'):
"""
"""
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
self.weights.append((2 * np.random.random((layers[0] + 1, layers[1] - 1)) - 1) * 0.25)
for i in range(2, len(layers)):
self.weights.append((2 * np.random.random((layers[i - 1], layers[i])) - 1) * 0.25)
# self.weights.append((2*np.random.random((layers[i]+1,layers[i+1]))-1)*0.25)
def fit(self, X, y, learning_rate=0.2, epochs=10000):
X = np.atleast_2d(X)
# atlest_2d函数:确认X至少二位的矩阵
temp = np.ones([X.shape[0], X.shape[1] + 1])
# 初始化矩阵全是1(行数,列数+1是为了有B这个偏向)
temp[:, 0:-1] = X
# 行全选,第一列到倒数第二列
X = temp
y = np.array(y)
# 数据结构转换
for k in range(epochs):
# 抽样梯度下降epochs抽样
i = np.random.randint(X.shape[0])
a = [X[i]]
# print(self.weights)
for l in range(len(self.weights) - 1):
b = self.activation(np.dot(a[l], self.weights[l]))
b = b.tolist()
b.append(1)
b = np.array(b)
a.append(b)
a.append(self.activation(np.dot(a[-1], self.weights[-1])))
# 向前传播,得到每个节点的输出结果
error = y[i] - a[-1]
# 最后一层错误率
deltas = [error * self.activation_deriv(a[-1])]
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(self.weights[l].T) * self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights) - 1):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
delta = delta[:, : -1]
self.weights[i] += learning_rate * layer.T.dot(delta)
layer = np.atleast_2d(a[-2])
delta = np.atleast_2d(deltas[-1])
# print('w=',self.weights[-1])
# print('l=',layer)
# print('d=',delta)
self.weights[-1] += learning_rate * layer.T.dot(delta)
def predict(self, x):
x = np.atleast_2d(x)
# atlest_2d函数:确认X至少二位的矩阵
temp = np.ones(x.shape[1] + 1)
# 初始化矩阵全是1(行数,列数+1是为了有B这个偏向)
temp[:4] = x[0, :]
a = temp
# print(self.weights)
for l in range(len(self.weights) - 1):
b = self.activation(np.dot(a, self.weights[l]))
b = b.tolist()
b.append(1)
b = np.array(b)
a = b
a = self.activation(np.dot(a, self.weights[-1]))
return (a)
Text.py
from BPNeuralNetwork import NeuralNetwork
import numpy as np
from openpyxl import load_workbook
import xlrd
nn = NeuralNetwork([4, 12, 3], 'tanh')
x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
import openpyxl
# 打开excel文件,获取工作簿对象
data = xlrd.open_workbook('BbezdekIris.xlsx')
table = data.sheets()[0]
nrows = table.nrows # 行数
ncols = table.ncols # 列数
datamatrix = np.zeros((nrows, ncols - 1))
for k in range(ncols - 1):
cols = table.col_values(k)
minVals = min(cols)
maxVals = max(cols)
cols1 = np.matrix(cols) # 把list转换为矩阵进行矩阵操作
ranges = maxVals - minVals
b = cols1 - minVals
normcols = b / ranges # 数据进行归一化处理
datamatrix[:, k] = normcols # 把数据进行存储
# print(datamatrix)
datalabel = table.col_values(ncols - 1)
for i in range(nrows):
if datalabel[i] == 'Iris-setosa':
datalabel[i] = [1, 0, 0]
if datalabel[i] == 'Iris-versicolor':
datalabel[i] = [0, 1, 0]
if datalabel[i] == 'Iris-virginica':
datalabel[i] = [0, 0, 1]
datamatrix1 = table.col_values(0)
for i in range(nrows):
datamatrix1[i] = datamatrix[i]
x = datamatrix1
y = datalabel
nn.fit(x, y)
CategorySet = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
P = np.zeros((1, len(y)))
P = y
a = [0, 1, 3, 5, 4, 7, 8, 1, 5, 1, 5, 5, 1]
print(a.index(max(a)))
b = nn.predict(x[1])
b = b.tolist()
print(b.index(max(b)))
for i in range(len(y)):
Predict = nn.predict(x[i])
Predict = Predict.tolist()
Index = Predict.index(max(Predict, key=abs))
Real = y[i]
Category = Real.index(max(Real, key=abs))
if Index == Category:
P[i] = 1
print('样本', i + 1, ':', x[i], ' ', '实际类别', ':', CategorySet[Category], ' ', '预测类别', ':', CategorySet[Index],
' ', '预测正确')
else:
P[i] = 0
print('样本', i + 1, ':', x[i], ' ', '实际类别', ':', CategorySet[Category], ' ', '预测类别', ':', CategorySet[Index],
' ', '预测错误')
print('准确率', ':', sum(P) / len(P))
