
python爬虫——爬取天气后报网查询指定地点气温
天气是我们每天都会关注的话题,今天天气是否和往常一样冷或热。
因为个人对温度的差别比较敏感,所以我比较关注以往气温的变化。
所以我选择爬取天气后报网以泉州为基准的往年某一月的最高气温和最低气温。
并分析着几个月内的气温差别变化。
网页中的信息包括某某年某季度的历史天气查询
开始编写获取网页信息的函数:
1 # 打开文件 2 # a+权限追加写入 3 # newline=""用于取消自动换行 4 fp = open("data.csv", "a+", newline="") 5 # 修饰,处理成支持scv读取的文件 6 csv_fp = csv.writer(fp) 7 # 设置csv文件内标题头 8 head = ['日期', '最高气温', '最低气温'] 9 # 写入标题 10 csv_fp.writerow(head) 11 12 # UA伪装 13 headers = { 14 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0" 15 } 16 17 # 存放全部数据 18 data = []
测试输出获取的信息,分析信息内容得知该网页可以用这种方式爬取历年天气为我们想要的数据。
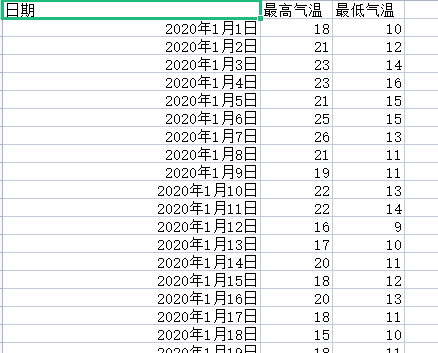

通过F12网页检查工具查找得知,2020年的泉州历史天气的信息都包含在
1 for item1 in soup.find_all('class="box pcity""): 2 # 查找符合条件的li标签,逐一分析即遍历(在输出的标签li列表中,逐一进行查找标签li中我们需要的信息,并保存于新的列表datalist中)
我们想要获取2020年第一季度的天气详情,需要点击进去获取详情信息
又因为在里页面每个月的天气都是单独的页面,所以需要多次爬取对应页面
为解决这个问题,前面我将获取网页信息的代码写为函数get()
1 # 进行url拼接,主要拼接的是年份和月份 2 # 从1月到3月 3 for j in range(1, 4): 4 # 字符串化 5 # 小于10则补0 6 if j < 10: 7 j = "0" + str(j) 8 else: 9 # 字符串化 10 j = str(j) 11 # 完成拼接 12 url = "http://www.tianqihoubao.com/lishi/quanzhou/month/" + "2020" + j + ".html" 13 14 # 获取响应 15 response = requests.get(url=url, headers=headers) 16 # 设置编码为gbk 17 response.encoding = 'gbk' 18 # 获取响应文本数据 19 page = response.text 20 # 用BeautifulSoup解析网页 21 soup = BeautifulSoup(page, 'lxml') 22 # 获取所有tr标签 23 tr_list = soup.find_all('tr') 24 25 # 解析每一个tr标签 26 for tr in tr_list: 27 # 用于存放一天的数据 28 one_day = [] 29 # 字符串化便于正则匹配 30 tr = str(tr) 31 # 去除所有空格 32 tr = tr.replace(" ", "") 33 # 取出日期 34 date = re.findall(r'title="(.*?)泉州天气预报">', tr) 35 # 如果取到则放入one——day存放 36 if date: 37 one_day.append(date[0]) 38 # 取出最高温和最低温 39 tem = re.findall(r'(.*?)℃', tr) 40 # 如果取到则放入one——day存放 41 if tem: 42 one_day.append(tem[0]) 43 one_day.append(tem[1]) 44 # 如果完整的取到一天的数据则放入data存放 45 if len(one_day) == 3: 46 data.append(one_day) 47 print(one_day) 48 # 写入csv文件 49 csv_fp.writerow(one_day) 50 # 关闭文件指针 51 sql = ''' 52 create table top50 53 ( 54 id integer primary key autoincrement, 55 date varchar, 56 tem1 numeric, 57 tem2 numeric 58 )
将数据清洗转换后

并将表格保存在本地,以便数据分析。为防止错误,用的是相对保存路径。
并且输出一个数据表db文件,进一步保存数据。为防止错误,用的是相对保存路径。
在保存输出数据表数据的过程中,需要对数据进行特别处理,比如在每个字符串类型的数据前后加上双引号。
1 ''' # 创建数据表,以上分别是"排名"类型为数字,"链接"类型为文本,"标题"类型为字符串,"播放量"类型为数字,"收藏数"类型为数字,"评分"类型为数字,"介绍"类型为文本 2 dbpath = "top50.db" 3 conn = sqlite3.connect(dbpath) 4 cursor = conn.cursor() 5 cursor.execute(sql) 6 conn.commit() 7 conn.close() 8 9 conn = sqlite3.connect(dbpath) 10 cur = conn.cursor() 11 for data_1 in data: 12 #将所有字符串类型的数据的前后都加上双引号 13 for index in range(len(data_1)): 14 15 #跳过不需要加双引号的数据 16 if index == 1 or index == 2 : 17 continue 18 data_1[index] = '"'+data_1[index]+'"' 19 sql = ''' 20 insert into top50 ( 21 date,tem1,tem2) 22 values(%s)'''%",".join(data_1) 23 print(sql) 24 cur.execute(sql) 25 conn.commit() 26 27 cur.close() 28 conn.close() 29 print('已保存数据表!')
输出结果:
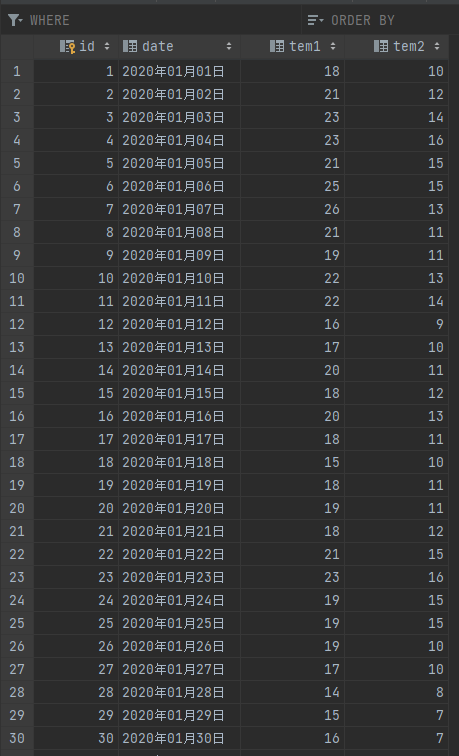
根据以上得到的数据库开始进行数据分析:
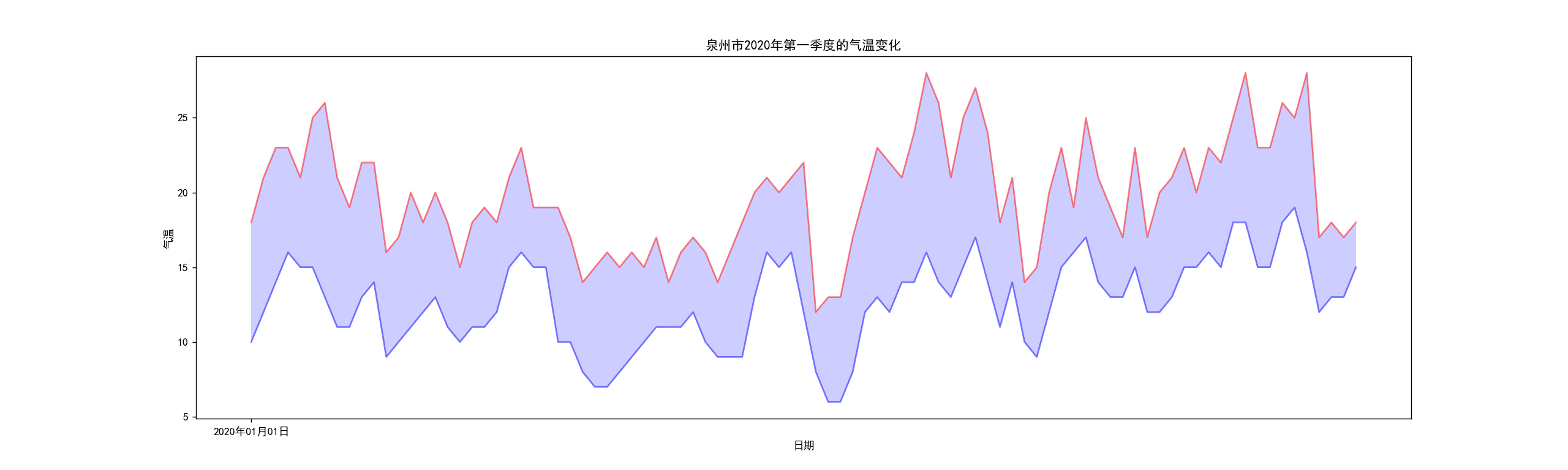
1 #数据分析 2 fp.close() 3 #折线图 4 import pandas as pd 5 import numpy as np 6 # 设置画板大小 7 fig = plt.figure(dpi=128, figsize=(20, 6)) 8 # 显示中文标签 9 plt.rcParams['font.sans-serif'] = ['SimHei'] 10 plt.rcParams['axes.unicode_minus'] = False 11 # 画最高气温 12 plt.plot(x, h, c="red", alpha=0.5) 13 # 画最低气温 14 plt.plot(x, l, c="blue", alpha=0.5) 15 # 区间渲染 16 plt.fill_between(x, h, l, facecolor="blue", alpha=0.2) 17 # 标题 18 plt.title("泉州市1月的气温变化") 19 # y轴名称 20 plt.ylabel("气温") 21 # x轴名称 22 plt.xlabel("日期") 23 plt.xticks(x[::300]) 24 plt.sho
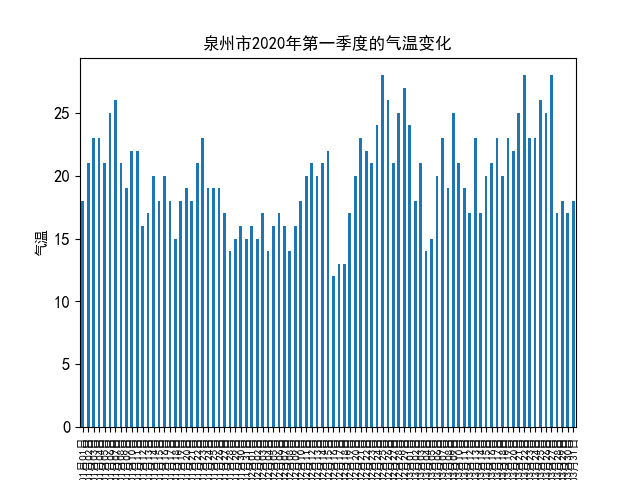
1 #柱状图 2 x1 = [] 3 for i in range(len(x)): 4 x1.append(i+1) 5 6 plt.rcParams['font.sans-serif']=['SimHei'] 7 plt.xticks(fontsize=8) 8 plt.yticks(fontsize=12) 9 s = pd.Series(h,x) 10 s.plot(kind="bar") 11 # 标题 12 plt.title("泉州市2020年第一季度的气温变化") 13 # y轴名称 14 plt.ylabel("气温") 15 # x轴名称 16 plt.xlabel("日期") 17 plt.show()
1 #散点图 2 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 3 plt.rcParams['axes.unicode_minus']=False 4 plt.xticks(fontsize=8) 5 plt.yticks(fontsize=12) 6 7 #散点 8 plt.scatter(x1,h, color='b') 9 plt.rcParams['font.sans-serif']=['SimHei'] 10 # 标题 11 plt.title("泉州市2020年第一季度的气温变化") 12 13 #x标签 14 plt.xlabel('气温') 15 16 #y标签 17 plt.ylabel('日期天数') 18 plt.show()
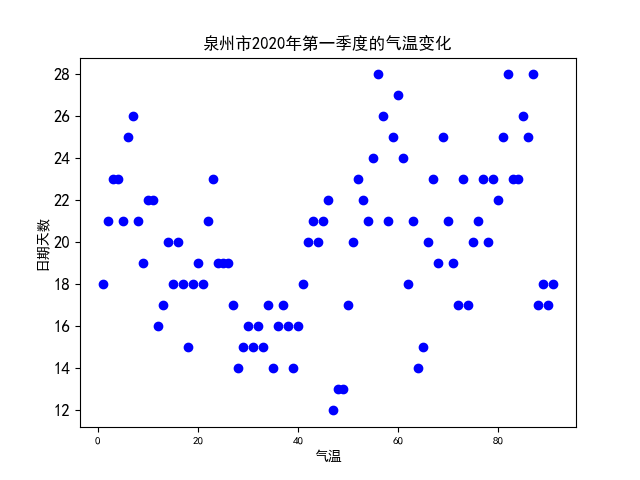
从2020年第一季度的最高气温和最低气温的数据分析图来看,泉州位于沿海地段,气温变化差距还是非常大的,根据近年来的全国各地的天气变化,这种异常的天气在全国乃至全球已经不罕见了
但是我国一直致力于环境净化保护,相信在未来气温会在改善下趋于正常。
1 #线性回归 2 import matplotlib 3 import scipy.optimize as opt 4 5 x0=np.array(x1) 6 y0=np.array(h) 7 def func(x,c0): 8 a,b,c=c0 9 return a*x**2+b*x+c 10 def errfc(c0,x,y): 11 return y-func(x,c0) 12 c0=[0,2,3] 13 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 14 a,b,c=c1 15 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 16 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 17 plt.plot(x0,y0,"ob",label="样本数据") 18 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 19 # 标题 20 plt.title("泉州市2020年第一季度的气温变化") 21 #x标签 22 plt.xlabel("日期天数") 23 #y标签 24 plt.ylabel("气温") 25 plt.legend(loc=3,prop=chinese) 26 plt.show()
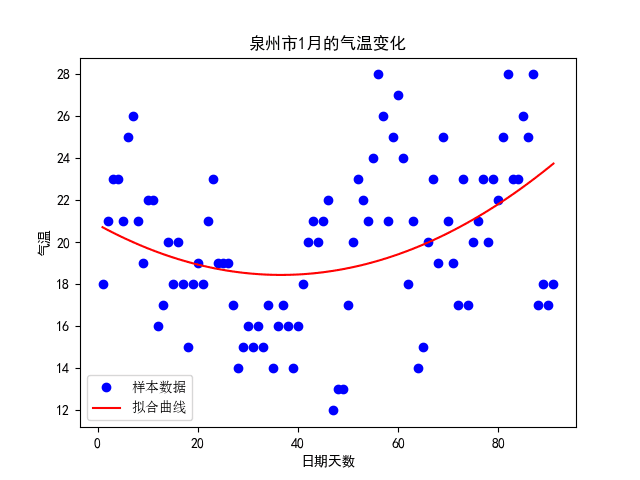

经过观察以上输出视图,我发现在冬天超过20°的也不在少数,最高气温和最低气温的分布并没有我想像的那么均匀。
完整代码:
1 # 用于爬取信息 2 3 import requests 4 # 用于解析网页 5 from bs4 import BeautifulSoup 6 # 用于正则匹配找到目标项目 7 import re 8 import sqlite3 9 # 对csv文件的操作 10 import csv 11 import pandas as pd 12 import pandas as np 13 14 # 打开文件 15 # a+权限追加写入 16 # newline=""用于取消自动换行 17 fp = open("data.csv", "a+", newline="") 18 # 修饰,处理成支持scv读取的文件 19 csv_fp = csv.writer(fp) 20 # 设置csv文件内标题头 21 head = ['日期', '最高气温', '最低气温'] 22 # 写入标题 23 csv_fp.writerow(head) 24 25 # UA伪装 26 headers = { 27 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0" 28 } 29 30 # 存放全部数据 31 data = [] 32 33 # 进行url拼接,主要拼接的是年份和月份 34 # 从1月到3月 35 for j in range(1, 4): 36 # 字符串化 37 # 小于10则补0 38 if j < 10: 39 j = "0" + str(j) 40 else: 41 # 字符串化 42 j = str(j) 43 # 完成拼接 44 url = "http://www.tianqihoubao.com/lishi/quanzhou/month/" + "2020" + j + ".html" 45 46 # 获取响应 47 response = requests.get(url=url, headers=headers) 48 # 设置编码为gbk 49 response.encoding = 'gbk' 50 # 获取响应文本数据 51 page = response.text 52 # 用BeautifulSoup解析网页 53 soup = BeautifulSoup(page, 'lxml') 54 # 获取所有tr标签 55 tr_list = soup.find_all('tr') 56 57 # 解析每一个tr标签 58 for tr in tr_list: 59 # 用于存放一天的数据 60 one_day = [] 61 # 字符串化便于正则匹配 62 tr = str(tr) 63 # 去除所有空格 64 tr = tr.replace(" ", "") 65 # 取出日期 66 date = re.findall(r'title="(.*?)泉州天气预报">', tr) 67 # 如果取到则放入one——day存放 68 if date: 69 one_day.append(date[0]) 70 # 取出最高温和最低温 71 tem = re.findall(r'(.*?)℃', tr) 72 # 如果取到则放入one——day存放 73 if tem: 74 one_day.append(tem[0]) 75 one_day.append(tem[1]) 76 # 如果完整的取到一天的数据则放入data存放 77 if len(one_day) == 3: 78 data.append(one_day) 79 print(one_day) 80 # 写入csv文件 81 csv_fp.writerow(one_day) 82 # 关闭文件指针 83 sql = ''' 84 create table top50 85 ( 86 id integer primary key autoincrement, 87 date varchar, 88 tem1 numeric, 89 tem2 numeric 90 ) 91 ''' # 创建数据表,以上分别是"排名"类型为数字,"链接"类型为文本,"标题"类型为字符串,"播放量"类型为数字,"收藏数"类型为数字,"评分"类型为数字,"介绍"类型为文本 92 dbpath = "top50.db" 93 conn = sqlite3.connect(dbpath) 94 cursor = conn.cursor() 95 cursor.execute(sql) 96 conn.commit() 97 conn.close() 98 99 conn = sqlite3.connect(dbpath) 100 cur = conn.cursor() 101 for data_1 in data: 102 #将所有字符串类型的数据的前后都加上双引号 103 for index in range(len(data_1)): 104 105 #跳过不需要加双引号的数据 106 if index == 1 or index == 2 : 107 continue 108 data_1[index] = '"'+data_1[index]+'"' 109 sql = ''' 110 insert into top50 ( 111 date,tem1,tem2) 112 values(%s)'''%",".join(data_1) 113 print(sql) 114 cur.execute(sql) 115 conn.commit() 116 117 cur.close() 118 conn.close() 119 print('已保存数据表!') 120 121 # 关闭文件指针 122 fp.close() 123 # 读取csv文件 124 import csv 125 # 作图工具 126 from matplotlib import pyplot as plt 127 128 # 存放日期 129 x = [] 130 # 存放最高气温 131 h = [] 132 # 存放最低气温 133 l = [] 134 # 读取之前爬取的数据 135 with open("data.csv") as f: 136 reader = csv.reader(f) 137 j = 1 138 for i, rows in enumerate(reader): 139 # 不要标题那一行 140 if i: 141 row = rows 142 print(row) 143 x.append(rows[0]) 144 h.append(int(rows[1])) 145 l.append(int(rows[2])) 146 #数据分析 147 fp.close() 148 #折线图 149 import pandas as pd 150 import numpy as np 151 # 设置画板大小 152 fig = plt.figure(dpi=128, figsize=(20, 6)) 153 # 显示中文标签 154 plt.rcParams['font.sans-serif'] = ['SimHei'] 155 plt.rcParams['axes.unicode_minus'] = False 156 # 画最高气温 157 plt.plot(x, h, c="red", alpha=0.5) 158 # 画最低气温 159 plt.plot(x, l, c="blue", alpha=0.5) 160 # 区间渲染 161 plt.fill_between(x, h, l, facecolor="blue", alpha=0.2) 162 # 标题 163 plt.title("泉州市2020年第一季度的气温变化") 164 # y轴名称 165 plt.ylabel("气温") 166 # x轴名称 167 plt.xlabel("日期") 168 plt.xticks(x[::300]) 169 plt.show() 170 171 #柱状图 172 x1 = [] 173 for i in range(len(x)): 174 x1.append(i+1) 175 176 plt.rcParams['font.sans-serif']=['SimHei'] 177 plt.xticks(fontsize=8) 178 plt.yticks(fontsize=12) 179 s = pd.Series(h,x) 180 s.plot(kind="bar") 181 # 标题 182 plt.title("泉州市2020年第一季度的气温变化") 183 # y轴名称 184 plt.ylabel("气温") 185 # x轴名称 186 plt.xlabel("日期") 187 plt.show() 188 189 #散点图 190 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 191 plt.rcParams['axes.unicode_minus']=False 192 plt.xticks(fontsize=8) 193 plt.yticks(fontsize=12) 194 195 #散点 196 plt.scatter(x1,h, color='b') 197 plt.rcParams['font.sans-serif']=['SimHei'] 198 # 标题 199 plt.title("泉州市2020年第一季度的气温变化") 200 201 #x标签 202 plt.xlabel('气温') 203 204 #y标签 205 plt.ylabel('日期天数') 206 plt.show() 207 208 #线性回归 209 import matplotlib 210 import scipy.optimize as opt 211 212 x0=np.array(x1) 213 y0=np.array(h) 214 def func(x,c0): 215 a,b,c=c0 216 return a*x**2+b*x+c 217 def errfc(c0,x,y): 218 return y-func(x,c0) 219 c0=[0,2,3] 220 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 221 a,b,c=c1 222 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 223 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 224 plt.plot(x0,y0,"ob",label="样本数据") 225 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 226 # 标题 227 plt.title("泉州市2020年第一季度的气温变化") 228 #x标签 229 plt.xlabel("日期天数") 230 #y标签 231 plt.ylabel("气温") 232 plt.legend(loc=3,prop=chinese) 233 plt.show()
总结:虽然这次爬取只选取的2020年的第一季度的一小部分气温分布,在进行分析后并不能以偏概全将此作为泉州市的以往气温规律图,但在处理这组数据上我任然学到了很多有用的东西,让我终生受用受益无穷。
通过这次程序设计我学会了做分析图,对网络爬虫有了更深刻的学习。在接下来的学习中我会不断改进和进修我的能力,努力提高自己。在看不过其他同学的作业后让我知道了我与他人差距。这会让我有不断挑战自我的动力,让我奋发向前。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号