
Python全栈工程师(迭代器、字节串)

Python人工智能从入门到精通
迭代器 Iterator:
用<>括号表示的一定是对象
什么是迭代器?
迭代器是访问可迭代对象的工具
迭代器是指用iter(obj) 函数返回的对象(实例)
迭代器可以用next(it) 函数获取可迭代对象的数据
迭代器函数iter和next
iter(iterable) 从可迭代对象中返回一个迭代器,iterable 必须是能提供一个迭代器的对象
next(iterator) 从迭代器iterator中获取下一个记录,如果无法获取下一条记录,则触发StopIteration异常
说明:
迭代器只能向前取值,不会后退
用iter函数可以返回一个可迭代对象的迭代器
作用:
迭代器对象能用next函数获取下一个元素.
示例:
L = [2, 3, 5, 7]
it = iter(L) # 用L对象返回能访问L的迭代器, it绑定迭代器
next(it) # 2
next(it) # 3
next(it) # 5
next(it) # 7
next(it) # StopIteration 通知(没有数据)
it = iter(range(1, 10, 30))
next(it) # 1
next(it) # 4
next(it) # 7
next(it) # StopIteration
用迭代器访问可迭代对象:
L = [2, 3, 5, 7] for x in L: print(x) else: print('循环结束') it = iter(L) # 从L中获取一个迭代器 while True: try: x = next(it) print(x) except StopIteration: print("循环结束") break
生成器 Generator (python 2.5及之后)
什么是生成器?
生成器是能够动态提供数据的对象,生成器对象也是可迭代对象(实例)
动态就是现用现生成数据
生成器有两种:
1. 生成器函数
2. 生成器表达式
生成器函数的定义
含有yield语句的函数是生成器函数,此函数被调用将返回一个生成器对象
yield 翻译为(产生或生成)
yield 语句
语法:
yield 表达式
说明:
yield 用于 def 函数中,目的是将此函数作用生成器函数使用
yield 用来生成数据,供迭代器的next(it) 函数使用
yield 单步生成数据 在函数内可以一个或多少
实例:
# 此示例示意用生成器函数生成一定范围内的自然数 def myinteger(n): i = 0 # 自然数从0开始 while i < n: yield i i += 1 for x in myinteger(3): print(x)
生成器函数说明:
生成器函数的调用将返回一个生成器对象,生成器对象是一个可迭代对象
在生成器函数调用return 会触发一个StopIteration异常
生成器表达式:
语法:
(表达式 for 变量 in 可迭代对象 [if 真值表达式 ])
说明:
if 子句可以省略
作用:
用推导式的形式创建一个新的生成器
示例:
gen = (x ** 2 for x in range(1, 5))
it = iter(gen)
next(it) # 1
next(it) # 4
next(it) # 9
next(it) # 16
next(it) # StopIteration
迭代工具函数
迭代工具函数的作用是生成一个个性化的可迭代对象
函数:
zip(iter1[, iter2[, ...]]) 返回一个zip对象,此对象用于生成元组,此元组的个数由最小的可迭代对象决定
enumerate(iterable[, start]) 生成带索引的枚举对象,返回迭代类型为索引-值对(index-value对),默认索引从零开始,也可以用start指定
示例: numbers = [10086, 10000, 10010, 9558] names = ['中国移动', '中国电信', '中国联通'] for t in zip(numbers, names): print(t) for x, y in zip(numbers, names): print(y, '的客服电话是:', x) x, y = (10086, '中国移动') # 序列赋值
zip函数的实现示例2: def myzip(iter1, iter2): it1 = iter(iter1) # 拿出一个迭代器 it2 = iter(iter2) while True: a = next(it1) b = next(it2) yield (a, b) for t in myzip(numbers, names): #能实现与zip同样的功能 print(t)
enumerate 示例: names = ['中国移动', '中国电信', '中国联通'] for t in enumerate(names): print(t) enumerate 实现方法示意: def myenum(iterable): it = iter(iterable) i = 0 while True: a = next(it) yield (i, a) i += 1
字节串和字节数组
字节串bytes (也叫字节序列)
作用:
存储以字节为单位的数据
字节串是不可变的字节序列
字节:
字节是由8个位(bit)组成的数据单位,是计算机进行数据管理的单位
字节是用 0 ~ 255 范围内的整数表示的
创建空字节串的字面值
B = b''
B = b""
B = b''''''
B = b""""""
创建非空字节串的字面值
B = b'ABCD'
B = b"ABCD"
B = b'\x41\x42'
字节串的构造函数 bytes
bytes() 生成一个空的字节串 等同于 b''
bytes(整数可迭代对象) # 用可迭代对象初始化一个字节串
bytes(整数n) 生成n个值为0的字节串
bytes(字符串, encoding='utf-8') 用字符串转为编码生成一个字节串
示例:
b = bytes() # b = b''
b = bytes(range(65, 69)) # b = b'ABCD'
b = bytes(5) # b = b'\x00\x00\x00\x00\x00'
b = bytes('abc中文') # b=b'ABC\xe4\xb8\xad\xe6\x96\x87'
bytes 的运算:
+ += * *=
< <= > >= == !=
in / not in
索引和切片
len(x)
max(x)
min(x)
sum(x)
any(x)
all(x)
bytes 和 str 的区别:
bytes 存储字节( 通常值在 range(0, 256))
str 存储unicode字符( 通常值在0~65535)
bytes 与 str 的转换
编码(encode)
str ------------> bytes
b = s.encode(encoding='utf-8')
解码(decode)
bytes ----------> str
s = b.decode(encoding='utf-8')
字节数组 bytearray
可变的字节序列
字节数组的构造函数: bytearray
bytearray() 创建空的字节数组
bytearray(整数) 用可迭代对象初始化一个字节数组
bytearray(整型可迭代对象) 生成n个值为0的字节数组
bytearray(字符串, encoding='utf-8') 用字符串的转换编码生成一个字节数组
bytearray 的运算:
+ += * *=
< <= > >= == !=
in / not in
索引和切片
(字节数组支持索引和切片的赋值操作,规则同列表的索引和切片赋值规则)
例:
ba = bytearray(b'aBCDEfG')
ba[0] = 65
ba[-2] = 70
bytearray的方法:
BA.clear() 清空
BA.append(n) 追加一个字节(n为0~255的整数)
BA.remove(value) 删除第一个出现的字节,如果没有出现,则触发ValueError错误
BA.reverse() 字节顺序反转
BA.decode(encoding='utf-8') # 解码为字符串
BA.find(sub[, start[,end]]) # 查找 sub
练习:
有一个集合:
s = {'唐僧', '悟空', '八戒', '沙僧'}
用 for语句来遍历所有元素如下:
for x in s:
print(x)
else:
print('遍历结束')
请将上面的for语句改写为 用while语句和迭代器实现
练习:
写一个生成器函数 myeven(start, stop)
此函数用来生成从 start开始到stop结束(不包含)区间内的一系列偶数
def myeven(start, stop):
....
evens = list(myeven(10, 20))
print(evens) # [10, 12, 14, 16, 18]
for x in myeven(21, 30):
print(x) # 22, 24, 26, 28
L = [x**2 for x in myeven(3, 10)]
print(L) # 16 36 64
练习:
已知有一个列表L
L = [2, 3, 5, 7]
用生成器表达式从此列表中拿到数,生成 列表中数据的平方
gen = ...... # 此处用生成器表达式实现
L2 = list(gen) # L2 = [4, 9, 25, 49]
练习:
写一个程序,读入任意行的文字,当输入空行时结束输入
打印带有行号的输入结果:
如:
请输入: hello<回车>
请输入: world<回车>
请输入: tarena<回车>
请输入: <回车> # 直接回车结束输入
输出如下:
第1行: hello
第2行: world
第3行: tarena
练习:
写一个程序,从键盘输入一段字符串存入s变量
1. 将此字符串转为字节串用变量b绑定,并打印出b
2. 打印字符串s的长度和字节串b的长度
3. 将b字节串再转换为字符串用变量s2 绑定,判断 s2 和 s是否相同?
s = input("please input string:") b = s.encode("utf-8") print(s) print(b) print(len(s)) print(len(b)) s2 = b.decode("utf-8") if s2 == s: print("相等")

练习:
1. 写一个生成器函数primes生成素数,
此生成器函数为 primes(begin, end)
如: [x for x in primes(10, 20)] 将得到列表
[11, 13, 17, 19]
答案:
def get_ss(x): if x <= 0: return False for i in range(2, x): if x % i == 0: return False return True def primes(begin, end): if begin <= 2or end <= 2: pass for x in range(begin, end): if get_ss(x): yield x L = [x for x in primes(10, 20)] print(L)

2. 写一个生成器函数,生成斐波那契数列的前n个数
1 1 2 3 5 8 13
def fibonacci(n):
...
yield...
1) 输出前20个数:
for x in fibonacci(20):
print(x)
2) 打印前40个数的和:
print(sum(fibonacci(40)))
答案:
def fibonacci(n): L = [1, 1] for x in range(n): s = L[x] + L[x + 1] L.append(s) return L print(fibonacci(20)) print(sum(fibonacci(40)))

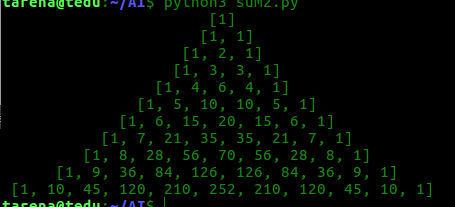
3. 写 程序打印杨辉三角(只打印6层)
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
答案:
def yh_sj(): L = [1] while True: yield L L.append(0) L = [L[x - 1] + L[x] for x in range(len(L))] def lst(): i = 0 for x in yh_sj(): print(str(x).center(50)) if i == 10: break i += 1
思考:
L = [2, 3, 5, 7]
L2 = [x ** 2 for x in L] # 列表推导式
it = iter(L2)
print(next(it)) # 4
L[1] = 10
print(next(it)) # 9
L = [2, 3, 5, 7]
G3 = (x ** 2 for x in L) # 生成器表达式
it = iter(G3)
print(next(it)) # 4
L[1] = 10
print(next(it)) # 100
生成器是动态的现用现去 跟着数据变化所变化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号