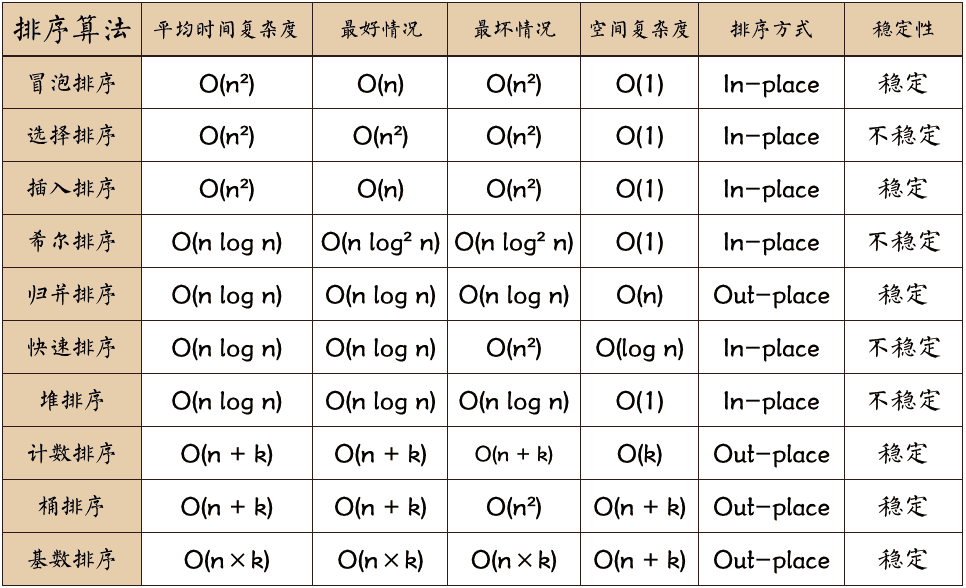
排序算法
排序算法
学了几年算法了,回头看几种排序算法居然不会。。。。
偷了菜鸟驿站的图
不会很认真的分析时间复杂度、空间复杂度,重在实现。
冒泡排序
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
每一轮都会找到一个最大的值,所以可以保证算法正确性。
时间复杂度是稳定的\(n^2\)不会有改变
void bubbleSort(int arr[]){
for (int i = 0; i < len - 1; i++)
for (int j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1])swap(arr[j], arr[j + 1]);
}
选择排序
每一轮找一个最小的或者最大的元素出来。很好理解。
void selection_sort(int arr[]) {
for (int i = 0; i < len - 1; i++) {
int Min = i;
for (int j = i + 1; j < len; j++)
if (arr[j] < arr[min]) Min = j;
swap(arr[i], arr[min]);
}
}
插入排序
对于第i个数,把他插入到前i-1个数中,这样每一轮可以保证前i个数有序。
void insertSort(int arr[]){
for(int i=1;i<len;i++){
int key=arr[i];
int j=i-1;
while((j>=0) && (key<arr[j])){
arr[j+1]=arr[j];
j--;
}
arr[j+1]=key;
}
}
希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
插入排序有一个很低效的过程,在有序序列中找到一个对应的的位置,暴力枚举是一个非常低效的过程,优化的方式有很多比如说二分,但是二分只是可以找到这个位置,那么插入呢?在数组中插入是O(n)的,但是链表是不好做二分的,在链表做二分差不多就是跳表了。
希尔排序是这个过程:
选择一个增量序列 \(t_1,t_2,……,t_k\),其中 \(t_i > t_j\), \(t_k = 1\);
按增量序列个数 \(k\),对序列进行 \(k\) 趟排序;
每趟排序,根据对应的增量 \(t_i\),将待排序列分割成若干长度为 \(m\) 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
void shellSort(int arr[], int len) {
int h = 1;
while (h < len / 3) {
h = 3 * h + 1;
}
while (h >= 1) {
for (int i = h; i < len; i++) {
for (int j = i; j >= h && arr[j] < arr[j - h]; j -= h) {
swap(arr[j], arr[j - h]);
}
}
h = h / 3;
}
}
看代码可以粗略得到时间复杂度是 \(O(nlog^2n)\)的,但实际上希尔排序的时间复杂度的是取决于增量的选择。不过很少看到有人使用这个算法,所以我也不算特别了解。
归并排序
归并排序是基于分治的算法,至于分治是什么就不说了。
对于分解的过程,每次都分为等长的两部分,一共\(logn\)次。
对于合并的过程,每次都是\(O(n)\)的遍历。
可以知道时间复杂度为\(O(nlogn)\)的。
注意它在任何时候都是这个时间复杂度,而需要付出的代价就是O(n)的额外空间。它还有一个优势就是它既可以在数组中实现也可以在链表中实现。
数组的实现:
主函数调用mergeSort(1,len);
void mergeSort(ll l,ll r){
if(l == r)return ;
ll mid = l+r>>1,i = l,j = mid+1;
m_sort(l,mid);
m_sort(mid+1,r);
ll k = l;
while(i <= mid && j <= r){
if(a[i] <= a[j])c[k++] = a[i++];
else c[k++] = a[j++],ans += mid-i+1;
}
while(i <= mid)c[k++] = a[i++];
while(j <= r)c[k++] = a[j++];
for(ll o = l;o <= r;o++)a[o] = c[o];
}
链表的实现:
ListNode* merge(ListNode* head1,ListNode* head2){
if(head1 == nullptr) return head2;
if(head2 == nullptr) return head1;
ListNode* head = new ListNode(-1);
ListNode* cur = head;
while(head1 && head2){
if(head1->val <= head2->val){
cur->next = head1;
head1 = head1->next;
}else{
cur->next = head2;
head2 = head2->next;
}
cur = cur->next;
}
if(head1)cur->next = head1;
else cur->next = head2;
return head->next;
}
ListNode* Sort(ListNode* head){
if(head == nullptr || head->next == nullptr) return head;
ListNode* left = head;
ListNode* mid = head->next;
ListNode* right = head->next->next;
while(right != NULL && right->next != NULL){
left = left->next;
mid = mid->next;
right = right->next->next;
}
left->next = nullptr;
return merge(Sort(head),Sort(mid));
}
ListNode* sortInList(ListNode* head) {
return Sort(head);
}
快速排序
又是一种分支的排序算法,相比于归并排序稳定的时间复杂度,快速排序存在时间复杂度退化到\(O(n^2)\)的情况,当然在多数情况下快速排序仍然是优秀的,而且快速排序的常数比归并排序要小,所以在实际运行时间上快速排序仍然有不小的优势。
快速排序是这样的:
- 从数列中挑出一个元素,称为 "基准"(pivot);
- 把比基准小的放在一起成为一个子序列,比基准大的放在一起成为一个子序列
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
这里的基准选择的是中间的数,实际上可以选择一个随机的数这是无所谓的
void qsort(int l, int r, int a[]) {
int i = l, j = r, mid = a[(i + j) >> 1];
do {
while (a[i] < mid) i++;
while (mid < a[j]) j--;
if (i <= j) {
swap(a[i], a[j]);
i++;
j--;
}
} while (i <= j);
if (l < j) qsort(l, j, a);
if (i < r) qsort(i, r, a);
}
从代码中可以看到每次分治每个点只会遍历一次,而归并排序会遍历3次。常数上还是有差距的,不过快速排序无法在链表上实现。
堆排序
堆排序是另外一种nlogn的排序,它基于一种名为堆(Heap)的数据结构,这种数据结构可以O(1)的找到最小值,但是弹出最小值之后需要logn的时间维护。在C++中有priority_que也就是优先队列,这就是堆,但需要注意这个的性能比手写堆要差。
写一个堆
//a就是堆,sz是堆的范围
void up(int i)//往上与父亲比较
{
while(i>1&&a[i]<a[i/2])//上面还有父亲,而且父亲比自己大
{
swap(a[i], a[i/2]);//父子交换
i/=2;//父亲迭代
}
}
//小根堆
void down(int i)//往下与左右孩子比较
{
while(i*2<=sz)
{
int j=i*2;//2*t为左孩子,2*t+1为右孩子
if(j+1<=sz&&a[j+1]<a[j]) j++;//有左孩子,而且左孩子比右孩子小
if(a[j]>=a[i]) break;//孩子不小,终止向下
swap(a[i], a[j]);//父子交换
i=j;//儿子迭代
}
}
void push(int x)
{
sz++;//堆大小递增
a[sz]=x;
up(sz);
}
void pop()
{
swap(a[1], a[sz]);
sz--;//堆大小递减
down(1);
}
计数排序
一组数a[]最大的是H,如果H是一个不大的数,我们可以使用一个新的数组Base[],大小为H,Base[i]表示在a中i出现的次数。在这种情况下时间复杂度为\(O(n+H)\),当然也有局限性就是你无法
void countSort(int a[]) {
int Max = -1;
for(auto x:a) {
Base[x]++;
Max = max(x,Max);
}
vector<int> ans;
for(int i = 0;i <= Max;i++) {
while(Base[i]){
ans.push_back(i);
Base[i]--;
}
}
}
桶排序
桶排序实际上是计数排序的拓展,或者说计数排序是桶排序的特例。
不难发现计数排序在值域太大的时候是无法实现的,桶排序提出把一组数据全部放在一个桶里面,对于一个桶的数据我们再使用其他的方法好了。
比如下面这个例子
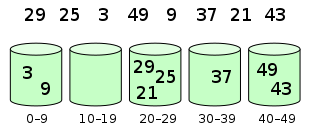
桶排序的时间复杂度决定了你是如何实现桶的,
第一,你需要保证桶和桶之间有大小关系,即第二个桶中的元素完全大于第一个桶;
第二,桶内部元素的多少

 浙公网安备 33010602011771号
浙公网安备 33010602011771号