【学习笔记】省选动态规划类型选讲
数据结构优化DP
引言
在状态转移过程中, 我们通常需要在某个区间范围内进行择优, 选出最佳决策点.
而数据结构通常可以维护出转移的最优决策.
数据结构优化\(DP\)的实质为优化"转移".
例题
题目大意:
计算在长度为\(n\)的序列中, 严格单调递增且长度为\(m\)的子序列的数量.
答案对\(1e9+7\)取模, 多组数据.
\(1\leq m\leq n\leq10^3,1\leq a_i\leq 10^9\).
题解:
设\(f[i][j]\)表示由区间\([1,j]\)中的数构成的以\(a[j]\)结尾的子序列中,长度为\(i\)的严格递增子序列的数量.
特殊的, \(i=1\)时,则有\(f[i][j]=1\).
时间复杂度:\(O(n^2m)\).
观察所需要维护的信息:
\((1)\): 原序列中的位置\(k<j\).
\((2)\): \(a[k]<a[j]\).
\((3)\): $ \displaystyle \sum f[i-1][k]$.
解决方法:
\((1)\): 枚举顺序使得$k<j $.
\((2)+(3)\): 发现维护的是满足\(a[k]<a[j]\)的\(f[i-1][k]\)的总和.
利用数据结构进行优化:
将\(a[j]\)作为下标,\(f[i-1][j]\)作为权值建立树状数组.
对于每次进行的\(f[i][j]\)的决策, 将\(a[j]\)作为数据结构所维护的关键字,
每次计算\(f[i][j]\)时查询前面已加入的且关键字\(<a[j]\)的\(f[i-1][k]\)的总和.
最后将\(f[i-1][j]\)加入树状数组.
时间复杂度:\(O(nmlogn)\).
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 1e3 + 5, mod = 1e9 + 7;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
int T, n, m, a[N], b[N], tr[N], f[N][N];
void change(int x, int v) {
for( ; x <= n + 1; x += x & (-x)) (tr[x] += v) %= mod;
}
int query(int x) {
int res = 0;
for( ; x; x -= x & (-x)) (res += tr[x]) %= mod;
return res;
}
int main() {
T = read();
for(int t = 1; t <= T; ++ t) {
n = read(); m = read();
memset(f, 0, sizeof(f));
for(int i = 1; i <= n; ++ i) {
a[i] = b[i] = read();
f[1][i] = 1; //特殊处理长度为 1 的情况;
}
sort(b + 1, b + n + 1); //离散化;
LL cnt = unique(b + 1, b + n + 1) - b - 1;
for(int i = 1; i <= n; ++ i) {
a[i] = lower_bound(b + 1, b + cnt + 1, a[i]) - b;
}
for(int i = 2; i <= m; ++ i) { //枚举长度;
memset(tr, 0, sizeof(tr)); //清空树状数组;
for(int j = 1; j <= n; ++ j) { //枚举子序列结尾的位置(同时保证了 k < j);
f[i][j] = query(a[j] - 1); //树状数组维护满足a[k]<a[j]的 ∑f[i-1][k];
change(a[j], f[i-1][j]); //维护树状数组的信息;
}
}
int ans = 0;
for(int i = 1; i <= n; ++ i) { //统计以位置 i 为结尾长度为 m 的答案贡献;
(ans += f[m][i]) %= mod;
}
printf("Case #%d: %d\n", t, ans);
}
return 0;
}
题目大意:
给定一个长度为\(n\)的序列, 对序列进行\(k\)次操作.
每次操作可以选取区间\([l,r]\)使得此区间内每个元素\(h[i]+1\),
求\(k\)次操作后所形成的新序列中最长不下降子序列长度的最大值.
\(1<n<10^4,1<k\leq500,1\leq h_i\leq5000\).
题解:
结论: 每一次操作的区间右端点一定为\(n\).
证明: 反证法.
假设进行的某次操作为区间\([l,r]\)且\(r\neq n\).
则将此区间更改为\([l,n]\),则相对于原序列\([r+1,n]\)会被\(+1\).
所形成的新序列中最长不下降子序列长度一定不会变小.
证毕.
设\(f[i][j]\)表示区间\([1,i]\)中, \(h_i\)进行了\(j\)次操作后最长不下降子序列长度的最大值.
时间复杂度:\(O(n^2*k^2)\)
观察所需要维护的东西为二维前缀最大值.
且候选决策集合只扩大,因此可以利用二维树状数组进行维护.
然而, 发现限制条件中有\(\large h[i]+j\geq h[k]+l\), 难以用树状数组满足限制.
考虑将高度的限制加入状态.
设\(f[j][k]\)表示区间\([1,i]\)(从左到右枚举\(i\))中, 以\(h= j\)(这里的\(h\)为操作后的\(h\))被操作\(k\)次的位置结尾的答案.
可以用\(tmp\)变量代替\(f[\ ][\ ]\)数组.
利用类似背包的思想滚动掉\(i\)这一维.
时间复杂度:\(O(nlogn*klogk)\).
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1e4 + 5;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
int n, k, ans, maxl, h[N], tr[N][6505];
void change(int x, int y, int val){
for(int i = x; i <= k; i += i & (-i)) {
for(int j = y; j <= maxl; j += j & (-j)) {
tr[i][j] = Max(tr[i][j], val);
}
}
}
int query(int x, int y) {
int res = 0;
for(int i = x; i > 0; i -= i & (-i)) {
for(int j = y; j > 0; j -= j & (-j)) {
res = Max(res, tr[i][j]);
}
}
return res;
}
int main() {
freopen("a.in", "r", stdin);
freopen("a.out", "w", stdout);
n = read(); k = read();
k ++; //树状数组不能处理下标为 0 的情况, 整体位移;
for(int i = 1; i <= n; ++ i) {
h[i] = read();
maxl = Max(maxl, h[i]);
}
maxl += k;
for(int i = 1; i <= n; ++ i) { //枚举处理到的右边界;
for(int j = k; j; -- j) { //枚举操作次数;
int tmp = query(j, h[i] + j) + 1;
ans = Max(ans, tmp);
change(j, h[i] + j, tmp);
}
}
printf("%d\n", ans);
return 0;
}
题目大意:
\(n\)个村庄位于一条直线, 每个村庄有一个范围\(s_i\).
要求每个村庄的范围内有至少\(1\)个村庄被建立基站, 否则需要赔偿\(w_i\).
建立基站需要花费\(c_i\),求最小总花费.
\(1\leq n\leq 20000,1\leq k\leq100\).
题解:
设\(f[i][j]\)表示考虑前\(i\)个村庄, 第\(j\)个修建基站的村庄为\(i\)的最小花费.
\(cost[i][j]\)表示村庄\(i\)到\(j\)建立基站但\(i\)到\(j\)之间的村庄未建立基站所需的赔偿费用.
\(cost[i][j]\)预处理\(O(n^2)\)
时间复杂度:\(O(n^2k)\)
优化①:
发现对于\(f[\ ][\ ]\)数组来说, 第二维为\(x\)时, 只有第二维为\(x-1\)的数据是有用的.
且\(j<i\), 因此可以压缩第二维.
在最外层枚举\(j\).
优化②:
优化计算\(cost[i][j]\).
对于任意村庄\(i\), 记录记录它所能被覆盖的左右边界\(st[i],\ ed[i]\),
即最左端, 最右端可以覆盖到\(i\)的基站位置, 利用二分查找处理.
用邻接表记录\(ed\)值为\(i\)的村庄有哪些, 在这些村庄之后建立基站就覆盖不到\(i\)了.
这样当我们推导\(i+1\)时, 若从村庄\(1\)~\(st[k]-1(ed[k]=i)\)转移过来则必定要赔偿村庄\(k\)的费用,
我们可以考虑用线段树维护\(f[k]+cost[k][i]\)的值.
即在区间\([1,st[k]-1]\)加上村庄\(k\)的费用, 而转移即在区间\([1,i-1]\)找\(f[k]+cost[k][i]\)的最小值.
时间复杂度:\(O(nlongn*k)\).
考虑在末尾增加一个建设费用为\(0\)的基站, 因为在推导\(i\)时, 是默认在\(i\)处建立基站的.
而且对前面没有影响.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <vector>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 2e4 + 5;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
vector <int> v[N];
int n, k, ql, qr, d[N], c[N], s[N], w[N], l[N], r[N], f[N];
struct Segment_tree{ //标记永久化线段树;
int minl[N << 2], tag[N << 2];
void pushup(int x) { minl[x] = Min(minl[x<<1], minl[x<<1|1]); }
void build(int x,int l,int r) {
tag[x] = 0;
if(l == r) return (void)minl[x] = f[l];
int mid = (l + r) >> 1;
build(x<<1, l, mid);
build(x<<1|1, mid + 1, r);
pushup(x);
}
void maintain(int x, int l, int r) {
if(l != r) pushup(x);
minl[x] += tag[x];
}
void change(int x, int l, int r, int v) {
if(ql <= l && qr >= r) tag[x] += v;
else {
int mid = (l + r) >> 1;
if(ql <= mid) change(x<<1, l, mid, v);
if(qr > mid) change(x<<1|1, mid + 1, r, v);
}
maintain(x, l, r);
}
int query(int x, int l, int r, int v) {
if(ql <= l && qr >= r) return minl[x] + v;
int res = 2e9, mid = (l + r) >> 1;
if(ql <= mid) res = Min(res,query(x<<1, l, mid, v + tag[x]));
if(qr > mid) res = Min(res,query(x<<1|1,mid + 1, r , v + tag[x]));
return res;
}
} tr;
int main() {
n = read(); k = read();
for(int i = 2; i <= n; ++ i) d[i] = read();
for(int i = 1; i <= n; ++ i) c[i] = read();
for(int i = 1; i <= n; ++ i) s[i] = read();
for(int i = 1; i <= n; ++ i) w[i] = read();
n ++; k ++;
d[n] = 2e9;
for(int i = 1; i <= n; ++ i) {
l[i] = lower_bound(d + 1, d + n + 1, d[i] - s[i]) - d;
r[i] = lower_bound(d + 1, d + n + 1, d[i] + s[i]) - d;
if(d[i] + s[i] < d[r[i]]) r[i] --;
v[r[i]].push_back(i);
}
int ans = 2e9;
for(int j = 1; j <= k; ++ j) { //最外层枚举修建的基站个数;
if(j == 1) {
int tot = 0;
for(int i = 1; i <= n; ++ i) { //枚举修建位置;
f[i] = tot + c[i]; //赔偿费用 + 建造费用;
for(int tmp = 0; tmp < v[i].size(); ++ tmp) { //统计赔偿费用;
tot += w[v[i][tmp]]; //在往后的推导中就要赔偿这些村庄的费用;
}
}
ans = Min(ans, f[n]);
continue;
}
tr.build(1, 1, n); //线段树维护 f[k]+cost[k][i]的最小值;
for(int i = 1; i <= n; ++ i) { //枚举修建位置;
ql = 1, qr = i-1;
int add = qr ? tr.query(1, 1, n, 0) : 0; //i != 1 / i = 1(特判, 优化复杂度);
f[i] = add + c[i];
for(int tmp = 0; tmp < v[i].size(); ++ tmp) {
ql = 1, qr = l[v[i][tmp]] - 1;
if(qr >= 1) tr.change(1, 1, n, w[v[i][tmp]]); //保证合法的情况下增添赔偿费用;
}
}
ans = Min(ans, f[n]);
}
printf("%d\n", ans);
return 0;
}
斜率优化DP
决策单调性
数
对于\(DP\)方程
其中\(a[i],\ b[i],\ c[i],\ d[i]\)为关于$\ i\ $的函数, 且 \(b\) 函数单调递增. \(----------①\)
利用数学归纳法证明\(f\)函数具有决策单调性.
\(1.\)归纳假设:
假设 \(i\) 有两个决策点\(j,\ k(j<k)\), 且 \(k\) 的决策要比 \(j\) 好, 即满足:
\(2.\)归纳推理:
此时 \(i\) 后面的状态 \(i+1\), 为简单起见, 设\(a[i+1]=a[i]-v,\ v > 0\), 即\(a\)函数单调递减.
证明决策单调性, 即证:
代入\(a[i+1]=a[i]-v\)得
即证:
由②得:
由①得:
又\(\because v>0\)
\(\therefore v*b[k] \geq v*b[j]----------④\).
由\(③+④\)得:
证毕.
我们将由决策单调性得出的式子展开:
将式子变形得:
记斜率
从单调队列的角度分析:
1.\(-a[i] \geq slope(q[head],\ q[head+1])\).
\(q[head]\)在\(q[head+1]\)前加入, 且\(q[head]\)的决策不如\(q[head+1]\)优, 则可以将队首\(pop\).
2.\(slope(q[tail-1],\ q[tail]) > slope(q[tail],\ i)\).
假设在后面存在一个\(a[t]\)使得\(-a[t] \geq slope(q[tail-1],\ q[tail])\).
则在\(pop\)掉\(q[tail-1]\)之后, 由于\(-a[t] \geq slope(q[tail],\ i)\).
\(q[tail]\)也一定会被\(pop\).
即\(q[tail]\)实际上是无用的, 可以直接将其\(pop\).
时间复杂度:\(O(n)\).
形
对于\(DP\)方程:
方程满足: \(a\)函数单调递减, \(b\)函数单调递增.
去掉\(Min\)函数及移项得:
令\(x=b[j]\), \(y=c[j]+d[i]\)则有:
\(-a[i]\)为直线的斜率, \(f[i]\)为直线的截距, 直线过点\(P(b[j],\ c[j]+d[i])\).(\(d[i]\)相对于当决策\(i\)来说是一个常数).
将每一个可用的决策\(j\)抽象为一个点\(P(b[j],\ c[j]+d[i])\).
同线性规划的思想, 将这条斜线自下往上平移所遇到的第一个点, 即为可以使\(f[i]\)取得最小值的决策.
因此我们需要维护一个下凸壳, 将一定不会对答案产生贡献的点删除.
利用单调队列维护这个凸壳, 因为要保证凸壳的下凸性, 所以我们得到\(pop\)队尾的条件:
考虑在什么时候\(pop\)队首元素(基于\(f[i]\)取最小值):
\(1.\)斜率\(-a[i]\)单调递增(函数\(a\)单调递减).
\(-a[i]>slope(q[head],\ q[head+1])\).
\(2.\)斜率不单调.
此时无法\(pop\)队首, 应使用二分查找或三分查找队列中的最优解.
二分法:
假设要在凸包上二分查找斜率为\(k\)的切线, 取中间的\(mid\)号点.
若存在\(mid+1\)且与\(mid\)点的斜率小于\(k\), 则\(l=mid+1\);
若存在\(mid-1\)且与\(mid\)点的斜率大于\(k\), 则\(r=mid-1\);
否则\(mid\)即为切点.
总结
"形"的角度:方便理解, 对于\(cdq\)分治维护凸包可以清晰了解.
"数"的角度:决策单调性的证明, 或DP方程较为复.
在"形"的角度来求解斜率优化并不会用到决策单调性.
若满足决策单调性, 则一定会对\(a\)函数和\(b\)函数的单调性有要求.
例题
题目大意:
将\(n(n\leq5e4)\)个玩具分成若干组, 每组玩具放到一个容器中, 要求每个容器中的玩具编号连续.
将第\(j\)~\(i\)个玩具放入一个容器中, 则容器的长度为\(x=i-j+\displaystyle \sum_{k=j}^iC_k\)中.
题解:
设前缀和为\(sum[i]\), \(f[i]\)表示前\(i\)个物品放到\(1\)个容器中得最小费用.
考虑将第\(j+1\)~\(i\)个玩具放到一个容器中.
时间复杂度:\(O(n^2)\).
下面进行斜率优化(以下称两点\(AB\)所形成的直线斜率为\(slope(A,B)\)):
为简化运算,我们令\(a[i]=sum[i]+i,\ b[j]=sum[j]+j+L+1\).
去掉\(Min\)并代入\(a[i]\)和\(b[j]\)得
展开得
移项得
令\(x=b[j],y=f[j]+b[j]^2\),则有
\(x,y\)只与\(j\)有关, 其他项只与\(i\)有关.
则对于每一个可供选择的\(j\),我们可以将其抽象为一个点\(P(b[j],f[j]+b[j]^2)\).
又因为对于当前所求的\(i\)来说,\(a[i]\)是固定的.
所以每个点可以对应一条直线,此直线的截距为\(f[i]-a[i]^2\).
我们需要求\(f[i]\)的最小值,\(a[i]\)对于当前的\(i\)来说又是一个定值.
因求\(f[i]\)的最小值即可以通过求截距的最小值.
直线的斜率为\(2*a[i]=2*(sum[i]+i)\),恒为正值.
因此, 本题中的可能最优点\(P\)组成了一个下凸包.
更具体的,满足条件的最优\(P_j\)为第一个\(slope(P_j,P_{j+1})>2*a[j]\)的点.
利用单调队列维护凸包.
时间复杂度:\(O(n)\).
若\(slope(q[head],q[head+1])<2*a[i]\),则\(q[head]\)一定不是最优解.
若\(slope(i,q[tail-1])<slope(q[tail-1],q[tail])\), 说明\(P_{tail}\)在凸包内部, 一定不是最优解.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 5e4 + 5;
typedef long long LL;
typedef double DB;
LL read() {
LL x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
LL n, L, q[N];
DB sum[N], f[N];
DB a(LL i) { return sum[i] + i; }
DB b(LL i) { return a(i) + L + 1; }
DB X(LL i) { return b(i); }
DB Y(LL i) { return f[i] + b(i) * b(i); }
DB slope(LL i, LL j) { return (Y(i) - Y(j)) / (X(i) - X(j)); }
int main() {
n = read(); L = read();
for(int i = 1; i <= n; ++ i) {
sum[i] = sum[i-1] + read();
}
LL head = 1, tail = 1;
for(int i = 1; i <= n; ++ i) {
while(head < tail && slope(q[head], q[head+1]) < 2 * a(i)) head ++;
f[i] = f[q[head]] + (a(i) - b(q[head])) * (a(i) - b(q[head]));
while(head < tail && slope(i, q[tail-1]) < slope(q[tail-1], q[tail])) tail --;
q[++ tail] = i;
}
printf("%lld\n", (LL)f[n]);
return 0;
}
题目大意:
将\(n(n\leq1e6)\)名士兵分组, 要求每组中士兵编号连续.
一组士兵\((i\)~\(j)\)的初始战斗力为\(\displaystyle \sum_{k=i}^{j}x_k\), 修正战斗力为\(x'=ax^2+bx+c(a,b,c为给定常数)\).
最大化士兵修正战斗力.
题解:
设前缀和为\(sum[i]\), \(f[i]\)表示前\(i\)名士兵分成若干组的最大修正战斗力.
去掉\(Max\)得
拆开得
移项及合并同类项得
令\(x=sum[j],\ y=f[j]+a*sum[j]^2\).
则有
直线的斜率为\(2*a*sum[i]\), 截距为\(f[i]-a*sum[i]^2-b*sum[i]-c\).
对于决策\(j\), 所抽象成的为点\(P(sum[j],\ f[j]+a*sum[j]^2)\).
\(\because-5\leq a \leq -1,\ sum[i]>0\).
\(\therefore 2*a*sum[i]\in(-\infty,\ 0)\).
利用单调队列维护一个上凸包即可.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 2e6 + 5;
typedef long long LL;
typedef double DB;
LL read() {
LL x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
LL n, a, b, c, q[N];
DB sum[N], f[N];
DB X(LL i) { return sum[i]; }
DB Y(LL i) { return f[i] + a * sum[i] * sum[i]; }
DB slope(LL i, LL j) { return (Y(i) - Y(j)) / (X(i) - X(j)); }
int main() {
n = read();
a = read(); b = read(); c = read();
for(int i = 1; i <= n; ++ i) {
sum[i] = sum[i - 1] + read();
}
LL head = 1, tail = 1;
for(int i = 1; i <= n; ++ i) {
while(head < tail && slope(q[head], q[head+1]) > 2 * a * sum[i] + b) head ++;
int tmp = sum[i] - sum[q[head]];
f[i] = f[q[head]] + a * tmp * tmp + b * tmp + c;
while(head < tail && slope(i, q[tail-1]) > slope(q[tail-1], q[tail])) tail --;
q[++ tail] = i;
}
printf("%lld\n", (LL)f[n]);
return 0;
}
题目大意:
共有\(n(n\leq 1e6)\)个工厂, 每个工厂有\(p_i\)件物品.
且工厂\(i\)到工厂\(1\)的距离为\(x_i(x_1=0)\), 在工厂\(i\)建立仓库的费用为\(c_i\).
要在某些工厂建立仓库, 使总费用(建造费用+运输费用)最小.
每个工厂中的物品只能被运往编号更大的工厂.
一件产品运送\(1\)个单位距离的费用是\(1\).
使每个物品最终所在的工厂都建造了仓库.
题解:
就近原则, 一段连续的工厂中的物品一定会放在一个最近的仓库中,
设\(sum1[i]=\displaystyle \sum_{k=1}^ip[k]\), \(sum2[i]=\displaystyle \sum_{k=1}^ip[i]*x[i]\), \(f[i]\)为将前\(i\)件物品都放如某些仓库的最小费用.
则有
去掉\(Min\)得
展开得
移项及合并同类项得
令\(x=sum1[j],\ y=f[j]+sum2[j]\).
则有
直线的斜率为\(x[i]\), 截距为\(f[j]+sum2[i]-x[i]*sum1[i]-c[i]\).
对于决策\(j\), 所抽象成的为点\(P(sum1[j],\ f[j]+sum2[j])\).
利用单调队列维护凸包即可.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 2e6 + 5;
typedef long long LL;
typedef double DB;
LL read() {
LL x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
LL n, q[N];
DB x[N], p[N], c[N], sum1[N], sum2[N], f[N];
DB X(LL i) { return sum1[i]; }
DB Y(LL i) { return f[i] + sum2[i]; }
DB slope(LL i, LL j) { return (Y(i) - Y(j)) / (X(i) - X(j)); }
int main() {
n = read();
for(int i = 1; i <= n; ++ i) {
x[i] = read(); p[i] = read(); c[i] = read();
sum1[i] = sum1[i - 1] + p[i];
sum2[i] = sum2[i - 1] + p[i] * x[i];
}
LL head = 1, tail = 1;
for(int i = 1; i <= n; ++ i) {
while(head < tail && slope(q[head], q[head+1]) < x[i]) head ++;
int j = q[head];
f[i] = f[j] + x[i] * (sum1[i] - sum1[j]) - (sum2[i] - sum2[j]) + c[i];
while(head < tail && slope(i, q[tail-1]) < slope(q[tail-1], q[tail])) tail --;
q[++ tail] = i;
}
printf("%lld\n", (LL)f[n]);
return 0;
}
总结
\((1).\)写出\(DP\)方程, 判断能否使用斜率优化, 即是否存在与\(i\)和\(j\)分别相关的函数乘积.
\((2).\)根据不等式符号, \(f[i]\)的符号, \(Min/Max\)判断所维护的凸包的形状.
\((3).\)当斜率不单调时, 需要使用二分查找最优决策, 且要维护完整凸包.
当所加入点的横坐标不单调时, 需要使用\(CDQ\)分治 或 平衡树维护凸包.
\((4).\)通常采用打表的方式确定是否具有决策单调性, 但打表并不能得到确切情况.
当不具有决策单调性(斜率不单调递增)时, 必须要保留整个凸包来确定完整的选择空间.
利用二分答案进行查找, 而不能直接取队首.
\((5).\)当\(X\)非严格递增时, 求斜率时可能会出现\(X(j_1)==X(j_2)\).
此时最好不要直接\(return\ inf/-inf\), 否则可能会返回一个错误的极值(应结合图像返回极值).
而应\(return\ Y(j) \geq Y(i)\ ?\ inf\ :\ -inf\).
\((6).\)规范比较\(k_0[i]\)和\(slope(j_1,j_2)\). 应用右面的点减去左面的点计算.
若写出如下不等式:
若在继续计算过程中\(j_1\)与\(j_2\)无意写反, 则会导致符号错误(相当于乘了一个\(-1\)).
最好直接比较\(k_0\)和\(\displaystyle \frac{Y(j_2)-Y(j_1)}{X(j_2)-X(j_1)}\).
\((7).\)队列中初始化时应加入一个点\(P(0,0)\), 代表其决策点为\(0\).
\((8).\)手写队列初始化为\(head=1,tail=0\).
由于加入了初始点, 所以可以初始化\(head=tail=1\).
\((9).\)手写队列判非空为\(head \leq tail\).
由于出入队时应使用两个元素进行判断, 当队列中仅剩一个元素时, 不能进行判断.
即队列判断存在至少两个元素的方法: \(head<tail\).
\((10).\)计算斜率时, 向下取整造成精度误差.
\(slope\)函数最好设为\(long\ double\)类型(数据范围:\(1.2*10^{4932}\)).
\((11).\)在比较两个斜率时, 尽量写上\(=\), 即\(\leq,\geq\). 而非\(<,>\).
这样写可以去重(重点时斜率分母出问题).
四边形不等式
定义
设函数\(w(x,\ y)\)是定义在\(Z\)上的函数.
若对于\(\forall a,\ b,\ c,\ d \in Z\), 其中\(a \leq b \leq c \leq d\).
若满足\(w(a,\ d)+w(b,\ c) \geq w(a,\ c)+w(b,\ d)\), 则称函数\(w\)满足四边形不等式.
推论:
设函数\(w(x,\ y)\)是定义在\(Z\)上的函数.
若对于\(\forall a,\ b \in Z\), 其中\(a < b\).
若满足\(w(a,\ b+1)+w(a+1,\ b) \geq w(a,\ b)+w(a+1,\ b+1)\), 则称函数\(w\)满足四边形不等式.
证明:
对于\(a<c\), 有:
对于\(a+1<c\), 有:
①+②并消项得:
依此类推, 对于\(\forall a \leq b \leq c\), 则有(用\(b\)代替\(a+2\), \(\because a+1<c,\ \therefore b \leq c\)):
同理, 对于\(\forall a\leq b\leq c\leq d\), 则有:
一维线性DP的四边形不等式优化
定理
对于形如\(f[i]=Min(f[j]+val(j,i))(0\leq j<i)\)的式子, 若\(val(j,i)\)满足四边形不等式,
则函数\(f[i]\)具有决策单调性, 即对于函数\(f[i]\), 随着\(i\)的增加, 取到最优解的\(j\)单调不减.
证明:
设令\(f[i]\)取到最优解的\(j\)值为\(p[i]\). 满足\(i\in[1,n],p[i]\in[0,i) j\in[0,p[i]]\).
根据最优解得:
设\(i'\in[i+1,n]\), 根据函数\(val\)满足四边形不等式:
移项得
①+②得
则对于\(i'\)来说, 决策\(p[i]\)比决策\(j\)更优.
即\(f[i]\)具有决策单调性.
证毕.
例题
题解:
设\(f[i]\)为对前\(i\)句诗进行排版的最小协调度, \(a[i]\)为每句诗的长度, \(sum[i]=\displaystyle \sum_{k=1}^{i}a[i]\).
方程带有高次项, 不好进行斜率优化或单调队列优化, 考虑决策单调性.
对于\(j<i\), 设\(val(j,i)=|(sum[i]-sum[j])+(i-j-1)-L|^p\).
要证明
移项得
设\(u=(sum[i]-sum[j])+(i-j-1)-L=(sum[i]+i)-(sum[j]+j)-(L+1)\).
\(v=(sum[i]-sum[j+1]+(i-(j+1)-1))-L=(sum[i]+i)-(sum[j+1]+j+1)-(L+1)\).
即证:
\(\because u>v\).
即证对于常数\(c>0\), \(|x|^p-|x+c|^p\)单调递减.
用导数可证此函数对于常数\(c(c>0)\)满足单调递减.
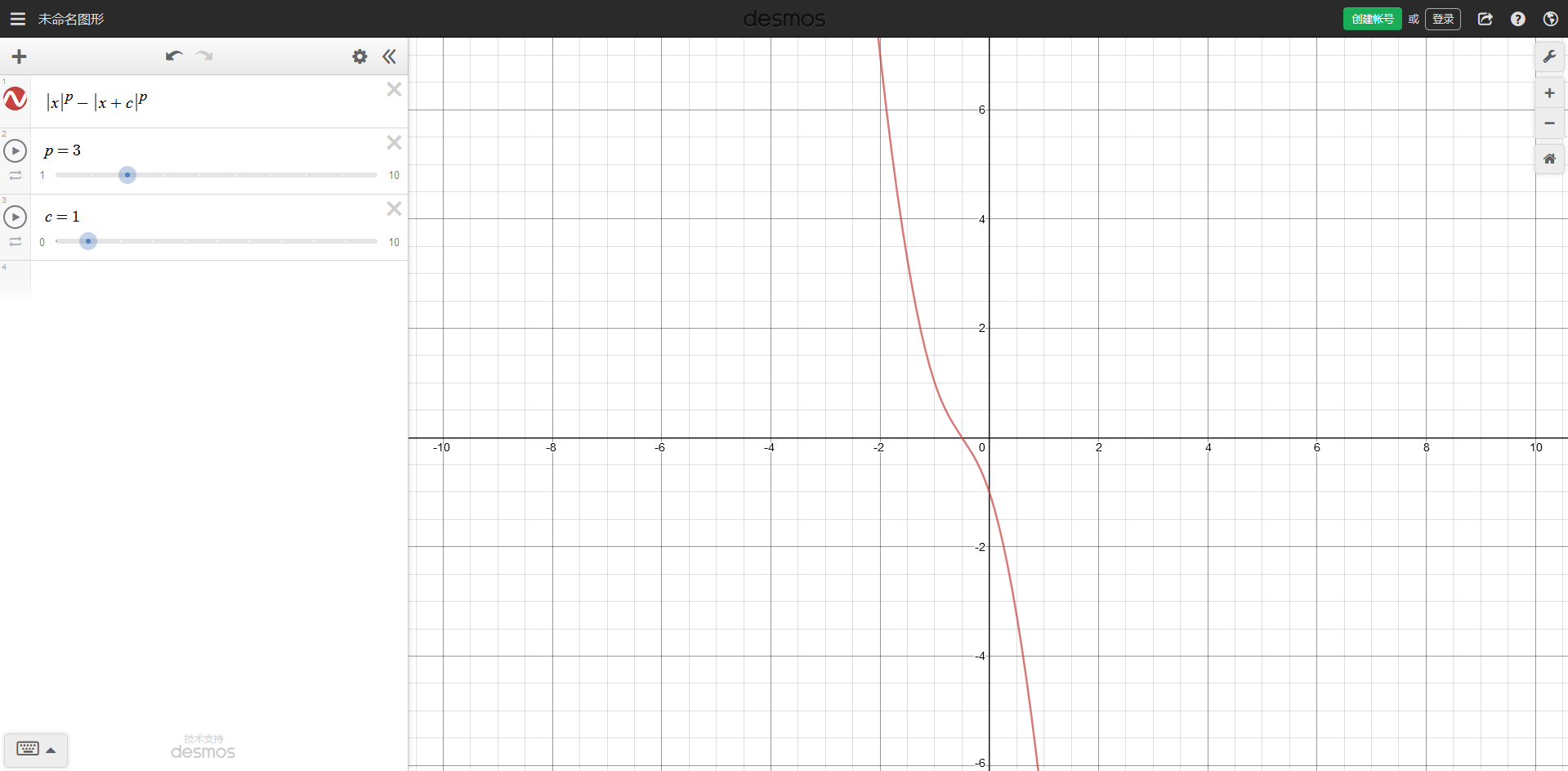
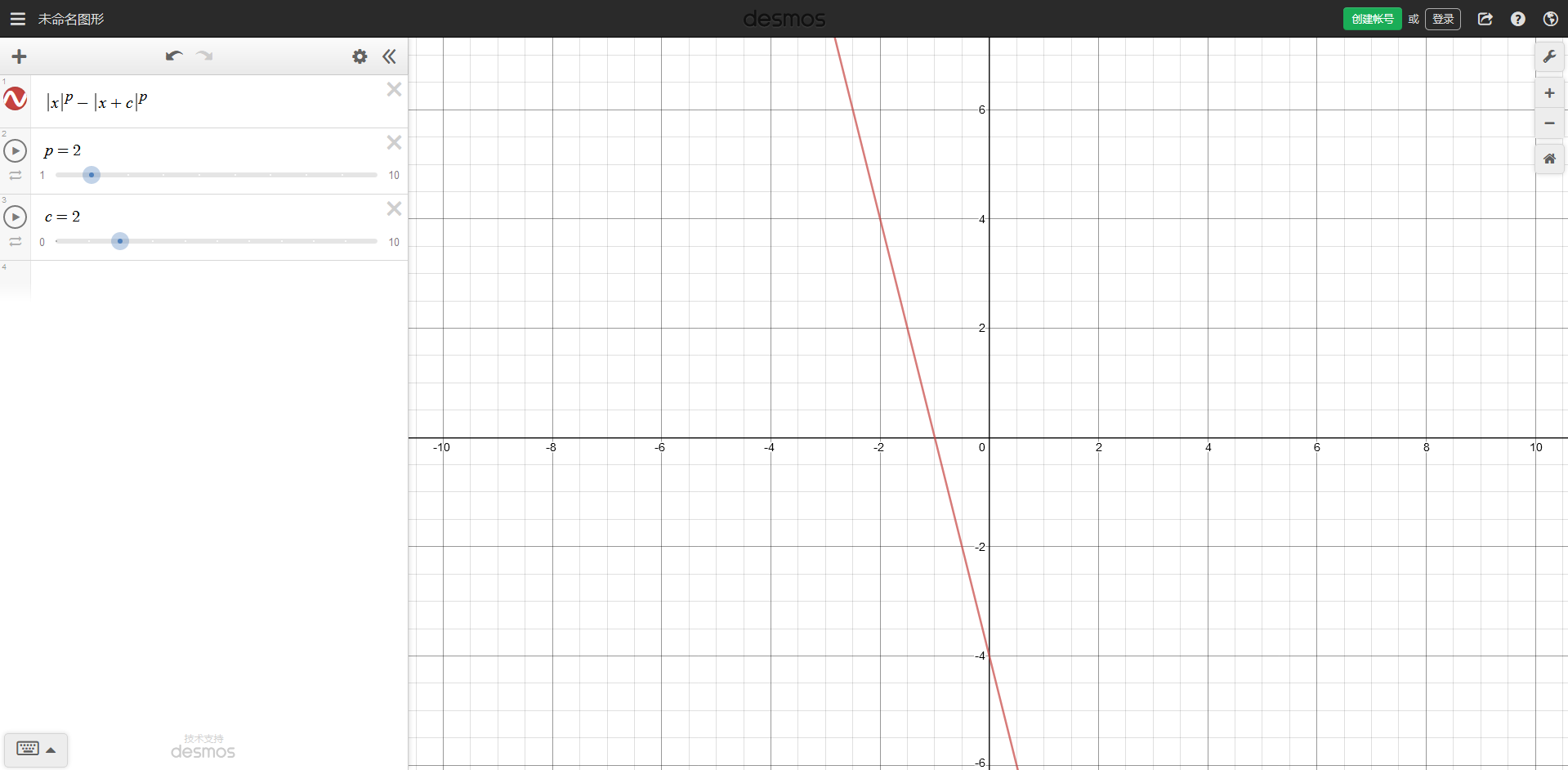
利用队列维护决策三元组即可.
code:
#include <iostream>
#include <cstdio>
#include <string>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long double LD;
const int N = 1e5 + 5;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
template <class T> T Abs(T a) { return a > 0 ? a : -a; }
int T, n, l, p, top, Last[N], Nxt[N];
LD sum[N], f[N];
string ch[N];
struct data { int l, r, p; } q[N];
LD ksm(LD x, int y) {
LD res = 1;
for( ; y; x = x * x, y >>= 1) {
if(y & 1) res = res * x;
}
return res;
}
LD val(int j, int i) {
return f[j] + ksm(Abs(sum[i] - sum[j] + (i-j-1) - l), p);
}
int find(data t, int x) { //二分决策分界点;
int l = t.l, r = t.r;
while(l <= r) {
int mid = (l + r) >> 1;
if(val(t.p, mid) < val(x, mid)) l = mid + 1;
else r = mid - 1;
}
return l;
}
void solve() {
int head = 1, tail = 0;
q[++ tail] = (data) {0, n, 0};
for(int i = 1; i <= n; ++ i) {
if(head <= tail && i > q[head].r) head ++; //去除不合法决策集合;
f[i] = val(q[head].p, i); //i为最优决策, 计算f[i];
Last[i] = q[head].p; //Last保存 i 的最优决策来源;
if(head > tail || val(i, n) <= val(q[tail].p, n)) {
//↓↓对于队尾集合左端点来说, i比 以前保存的最优决策 更优;
while(head <= tail && val(i, q[tail].l) <= val(q[tail].p, q[tail].l)) tail --;
if(head > tail) q[++ tail] = (data) {i, n, i}; //队列为空;
else {
int t = find(q[tail], i); //找到最优位置;
q[tail].r = t - 1; //插入新决策;
q[++ tail] = (data) {t, n, i};
}
}
}
}
int main() {
T = read();
while(T --> 0) {
n = read(); l = read(); p = read();
for(int i = 1; i <= n; ++ i) cin >> ch[i];
for(int i = 1; i <= n; ++ i) sum[i] = sum[i - 1] + ch[i].length(); //计算sum;
solve();
if(f[n] > (long long)1e18) puts("Too hard to arrange");
else {
printf("%lld\n", (long long)f[n]);
for(int i = n; i; i = Last[i]) Nxt[Last[i]] = i;
int now = 0;
for(int i = 1; i <= n; ++ i) {
now = Nxt[now];
for(int j = i; j < now; ++ j) cout << ch[j] << " ";
cout << ch[now] << "\n";
i = now;
}
}
puts("--------------------");
}
return 0;
}
二维区间DP的四边形不等式优化
定理1
对于\(\forall a,b,c,d\in Z\), 若函数\(w\)满足四边形不等式, 且\(w(a,d) \geq w(b,c)\).
则函数\(f\)也满足四边形不等式.
其中函数\(f\)满足:
特别的, 我们令\(f(x,y)=w(x,y)=0\).
证明:
当\(x+1=y\)时, 我们有:
若\(f(x,x+2)\)的最优决策为\(x+1\), 则有:
即
若\(f(x,x+2)\)的最优决策为\(x\), 则有:
即
又\(\because\)
\(\therefore x+1=y\)时, 我们得到:
即此时四边形不等式成立.
接下来, 我们运用数学归纳法:
假设当\(y-x<k\)时, 四边形不等式成立.
现在考虑\(y-x=k\)的情况:
令\(f(x,y+1)\)以\(a\)为最优决策, \(f(x+1,y)\)以\(b\)为最优决策.
不妨设\(x+1 \leq a < b\).
易得:
对于\(f(x,y)\)和\(f(x+1,y+1)\), 由于\(a,b\)不一定为最优决策, 所以我们有:
\(\because\)函数\(w\)满足四边形不等式,
根据归纳假设, 我们有:
于是, 我们有:
定理2
对于\(\forall a,b,c,d\in Z\), 若函数\(w\)满足四边形不等式,且函数\(f\)满足:
特别的, 我们令\(f(x,y)=w(x,y)=0\).
记\(P(x,y)\)为\(f(x,y)\)取到最小值的\(k\)值.
若函数\(f\)满足四边形不等式, 则对于\(\forall x,y\), 我们有:
即函数\(f(x,y)\)具有决策单调性.
证明:
记\(p=P(i,j)\).
对于\(\forall x<k\leq p\), 由四边形不等式得:
移项得:
由于\(p\)为最优决策, 所以我们有:
所以:
这意味着, 对于\(f(x+1,y)\)的任意决策\(k\leq p\), \(p\)都要比\(k\)更优(包括相等)
所以:
同理可证:
所以:
例题
新石子合并
题目大意:
有\(n\)堆石子围成一个圈, 每次可以选择相邻的两堆石子合并, 代价为两堆石子的总个数.
求最小代价和最大代价.
\(n\leq 5000\).
题解:
设\(f1[i][j]\)表示\(i\)到\(j\)之间石子合并的最小代价, \(f2[i][j]\)表示\(i\)到\(j\)之间石子合并的最大代价.
对于\(f1\), 我们可以列出状态转移方程:
其中, \(val(i,j)\)表示\(i\)到\(j\)之间的石子数目.
使用四边形不等式优化即可.
即对于\(f1[i][j]\), 只需在区间\([P[i][j-1],P[i+1][j]]\)枚举\(k\)即可.
时间复杂度:\(O(n^2)\).
最优决策\(P[i][j]\)打表程序见附加文件夹.
注意: 最大值并不能满足单调性, 但此时最大值满足一个性质.
对于\(f2[i][j]\), 取到最优解的\(k\)要么是\(i\), 要么是\(j-1\).
证明:
利用反证法证明.
假设最优决策\(P[i][j]=p\), 且\(i<p<j-1\).
则存在两种情况.
\((1).val(i,p)\leq val(p+1,j)\).
令\(t=P[i][p]\), 此时我们的方案为:
\([i,i+1,i+2,\dots ,t|t+1,t+2,\dots ,p]p+1,p+2,\dots j\).
得分\(F_1=(f[i][t]+f[t+1][p]+val(i, p))+f[p+1][j]+val(i,j)\).
此时我们构造一种方案:
\(i,i+1,i+2,\dots.t[t+1,t+2,\dots ,p|p+1,p+2,\dots j]\).
得分\(F_2=f[i][t]+(f[t+1][p]+f[p+1][j]+val(t+1,j))+val(i,j)\).
\(\because t<p,\ \therefore val(i,p)\leq val(p+1,j)<val(t+1,j)\).
\(\therefore F_1<F_2\), 即决策\(p\)并不是最优决策.
\((2).val(i,p)>val(p+1,j)\).
令\(t=P[p+1][j]\), 此时我们的方案为:
\(i,i+1,i+2,\dots p[p+1,p+2,\dots ,t|t+1,t+2,\dots j]\).
得分\(F_1=f[i][p]+(f[p+1][t]+f[t+1][j]+val(p+1,j))+val(i,j)\).
此时我们构造一种方案:
\([i,i+1,i+2,\dots ,p|p+1,p+2,\dots,t]t+1,t+2,\dots j\).
得分\(F_2=(f[i][p]+f[p+1][t]+val(i,t+1))+f[t+1][j]+val(i,j)\).
\(\because t+1>p,\ \therefore val(i,t+1)>val(i,p)>val(p+1,j)\).
\(\therefore F_1<F_2\), 即决策\(p\)不是最优决策.
与假设矛盾, 因此最优决策只可能是\(i\)或者\(j-1\).
证毕.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1e3 + 5;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
int n, a[N], sum[N], f1[N][N], f2[N][N], p[N][N];
int main(){
n = read();
for(int i = 1; i <= n; ++ i) a[i + n] = a[i] = read();
for(int i = 1; i <= (n << 1); ++ i) {
sum[i] = sum[i - 1] + a[i]; p[i][i] = i;
}
for(int i = (n << 1); i; -- i) {
for(int j = i + 1; j <= (n << 1); ++ j) {
f1[i][j] = 1e9;
f2[i][j] = Max(f2[i][i] + f2[i + 1][j], f2[i][j - 1] + f2[j][j]) + sum[j] - sum[i - 1];
for(int k = p[i][j - 1]; k <= p[i + 1][j]; ++ k) {
if(f1[i][k] + f1[k + 1][j] + sum[j] - sum[i - 1] < f1[i][j]) {
f1[i][j] = f1[i][k] + f1[k + 1][j] + sum[j] - sum[i - 1];
p[i][j] = k;
}
else if(f1[i][k] + f1[k + 1][j] + sum[j] - sum[i - 1] == f1[i][j]) {
p[i][j] = Max(p[i][j], k);
}
}
}
}
int ans = 1e9;
int ans2 = 0;
for(int i = 1; i <= n; ++ i) ans = Min(ans, f1[i][i + n - 1]);
for(int i = 1; i <= n; ++ i) ans2 = Max(ans2, f2[i][i + n - 1]);
printf("%d\n%d\n", ans, ans2);
return 0;
}
虚树
定义
对于一棵节点数为\(n\)的树\(T\).
构造一棵树\(T'\)使得总结点数最少, 且包含指定的某些节点和它们的\(LCA\).
树\(T'\)即为树\(T\)的虚树.
构造方法
前置知识:\(dfs\)序, \(lca\).
预处理整棵树的\(dfs\)序及\(lca\).
假设我们要构造\(k\)个指定点的虚树.
先将这\(k\)个点按照\(dfs\)序从小到大排序, 我们将把这些点逐一加入到虚树中.
为方便后面的处理, 我们可以先强行加入根节点.
用一个栈\(stack[\ ]\)保存虚树上从根出发到最后加入虚树的一条路径上所经过的点(按深度从小到大存储).
当虚树中加入点\(a[k]\)后.
满足\(sta[1]=root,sta[top]=a[k]\)(栈中保存了从根到\(a[k]\)路径上的点).
且\(sta[x]为sta[x-1](2\leq x\leq top)\)的子结点.
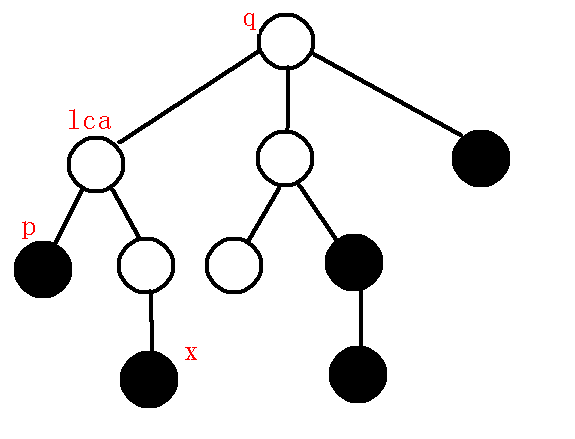
考虑新加入一个点\(x\), 设\(z=lca(x,sta[top])\), 分情况讨论.
\((1).z=sta[top]\). 即\(x\)为\(stack[top]\)子树内的点.
直接\(sta[++top]=x\)即可.
\((2).z\neq sta[top]\).
此时\(x\)一定不是\(sta[top]\)子树内的点.
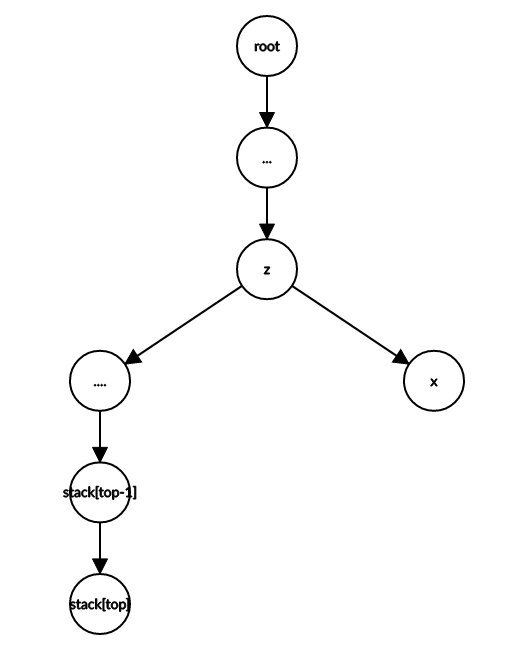
注:\(sta[top]->sta[top-1]\)和\(z->x\)在原树上不一定直接连接.
我们不断弹栈, 直到\(dep[sta[top-1]] < dep[z]\).
弹栈时在虚树上连接\(sta[top-1]->sta[top]\).
此时, \(sta[top]\)不一定为\(z\), 我们需要将\(z\)加入到虚树中维护.
当虚树构建完成后, 栈应该为空.
不断弹栈, 连接\(sta[top-1]->sta[top]\).
具体分析
先将整个树\(dfs\)一遍, 求出每个节点的\(dfs\)序 + \(dep\).
假如原树如下图:
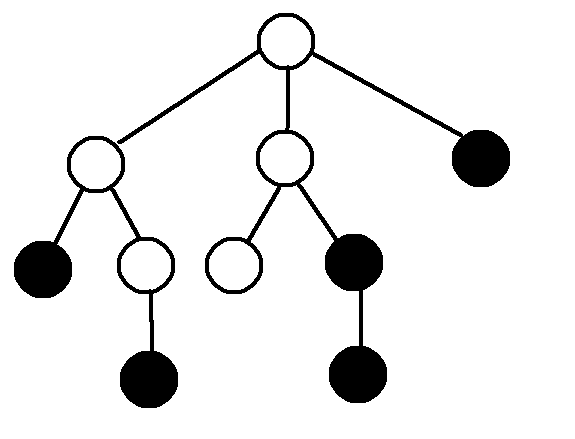
我们要建立以黑色节点为关键点的虚树.
标出\(dfs\)序, 为防止图片混乱, 未标明\(dep\), 如下图.

将关键点按照\(dfs\)序从小到大排序.
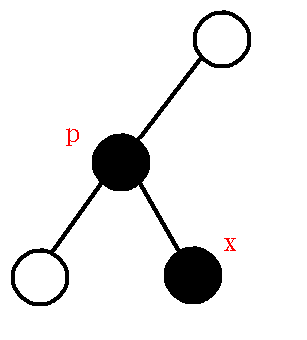
设栈顶元素为\(p\), 现在要插入的关键点为\(x\), \(lca=lca(p,x)\), 分情况讨论.
\((1).lca=p\), 如下图.
\((2).p,x\)分别位于\(lca\)的两棵子树, 如下图.
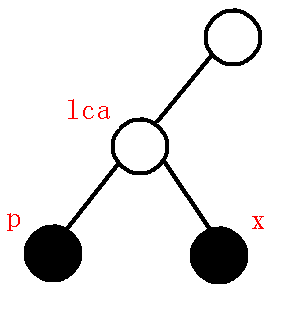
考虑为何\(lca\neq x\).
我们对关键点按照\(dfs\)序进行遍历.
根据\(dfs\)序的性质.
对于任意两个点\(x,y(dfn[x]>dfn[y])\), 都存在\(dfn[lca]\leq dfn[x],dfn[lca]\leq dfn[y]\).
若\(x=lca\), 则有\(dfn[x]\leq dfn[y]\). 情况矛盾, 不成立.
考虑上面所提到的情况\((1)\).
本来维护(下文中数字为图中\(dfs\)序)\(1-2\)链.
由于\(lca=p\),因此现在要维护\(1-2-4\)链.
直接压栈即可.
例如压栈后, 栈内(\(dfs\)序)情况, 如下图:
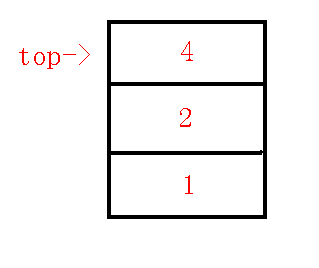
在维护下图的链(默认根节点在栈内):
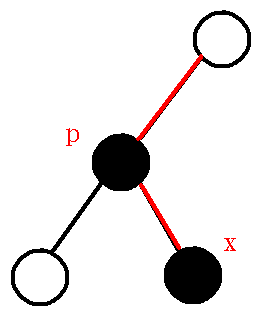
考虑较为复杂的情况\((2)\).
注意要循环处理情况\((2)\).
设栈内第二个元素\(sta[top-1]\)为\(q\), 分情况讨论:
①.\(dfn[q]>dfn[lca]\).
图中的信息:
以\(q\)为根的子树已经遍历完毕, 现在进入到以\(x\)为根的子树.
现在需要把以\(q\)为根的子树信息保存好.
当遍历到\(p\)点时, 栈中的维护情况,如下图:
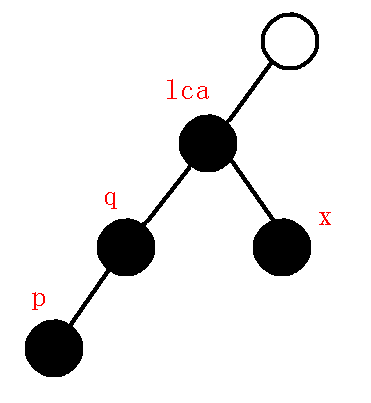
即维护了\(1-2-3-4\)的链, 如下图:
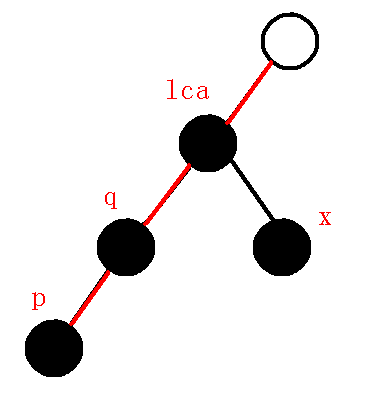
当前要维护的链, 如下图:
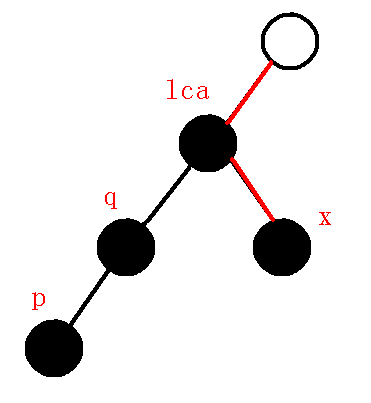
当我们弹出点\(p\)时, 等同于失去了\(q->p\)的信息.
因此在虚树上连边\(q->p\).
所以, 当\(dfn[q]>dfn[lca]\)时, 虚树上连边\(q->p\), 退栈一次.
②.\(dfn[q]=dfn[lca]\).
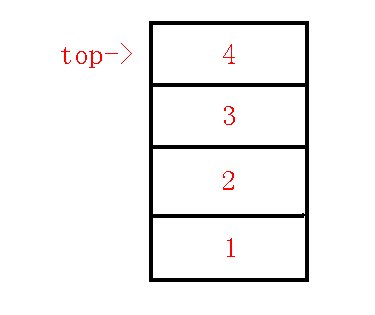
我们接着上幅图, 退栈一次后情况如下图(紫色边为虚树上的边):

我们需要连接\(lca->p\)来维护左子树, 然后要维护右子树的链.
将\(p\)弹栈后, 将\(x\)入栈, 终止循环.
所以当\(dfn[q]=dfn[lca]\)时, 由\(lca\)向\(p\)连边, 退栈后, 将点\(x\)入栈, 终止循环.
③.\(dfn[q]<dfn[lca]\), 情况如下图:
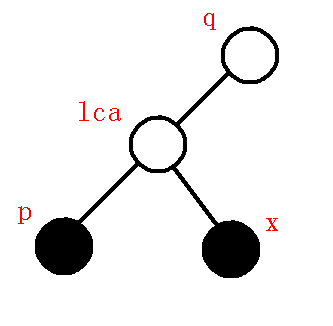
栈顶元素为\(p\), 第二个元素为\(q\)(根节点最开始就位于栈内).
当\(dfn[q]<dfn[lca]\)时, 思考其中包含的信息.
\(a.p\)与\(lca\)之间不存在关键点, 因为最近的关键点为\(q\).
所以\(lca\)的左子树需要连接\(lca->p\), 同时退栈一次.
\(b.lca\)不在栈中.即\(lca\)不是关键点, 但因为\(lca\)连接着点\(p\)和点\(x\)的关系.
因此, 我们将\(lca\)也加入栈中.
所以, 当\(dfn[q]<dfn[lca]\)时, 虚树上连接\(lca->p\), 退栈一次, 将\(lca, x\)依次入栈, 终止循环.
最后, 若栈内还有元素未弹出, 应将栈内元素依次连边.
图解虚树建立过程
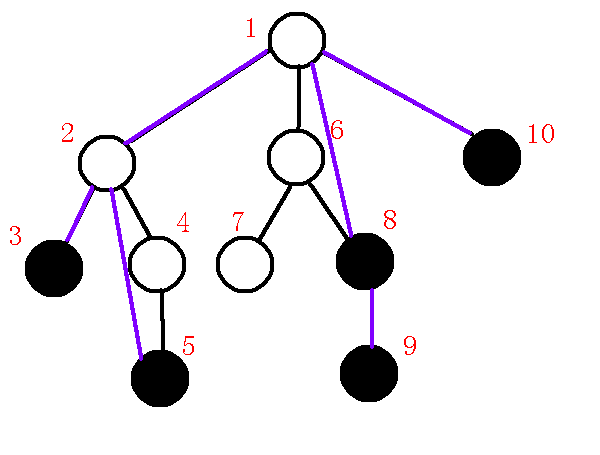
对于一开始的图, 我们模拟它的构建过程, 初始图:
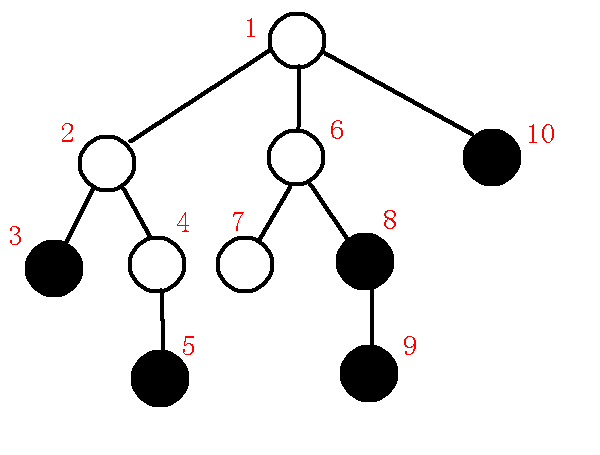
\((1).\)插入根节点, 无根树转有根树.
根节点入栈, 如下图:
\((2).\)插入\(3\)节点.
\(lca(3,1)=1\), 满足第一种情况, 直接压栈, 维护链\(1-3\).
此时栈内情况如下图:
\((3).\)插入\(5\)节点.
\(lca(3, 5)=2\), 发现\(p,x\)位于不同的子树中, 求出\(q=1\), 如下图:
我们发现\(dfn[q]<dfn[lca]\), 根据上文提到的做法.
在虚树上连边\(lca->p\), 退栈, 将\(lca,x\)依次压入栈中.
即本来维护链\(1-3\), 现在维护链\(1-2-5\).
树和栈中的情况分别如下图:

\((4).\)插入\(8\)节点.
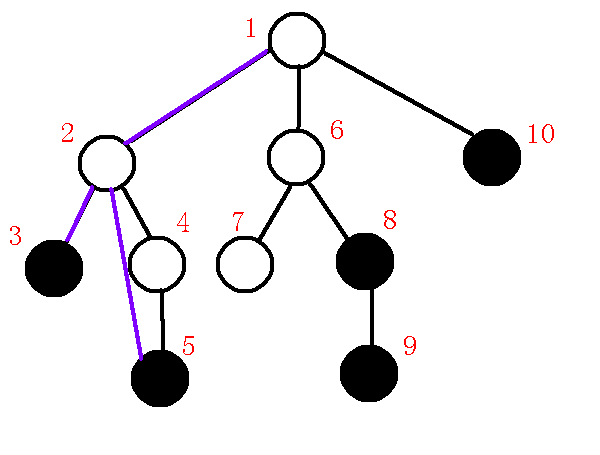
\(lca(5,8)=1\), 求出\(q=2\).发现\(dfn[q]>dfn[lca]\).
\(x\)点位于一个新的子树中, 因此我们应维护新的链, 并且要保存原来的链.
连接\(q->p\), 退栈.
此时\(p=2,q=1\),且\(dfn[q]=dfn[lca]\),满足上文第二种情况.
连接\(lca->p\), 退栈, 将\(x\)压入栈中, 维护新的链\(1-8\), 终止循环.
完成后如下图:
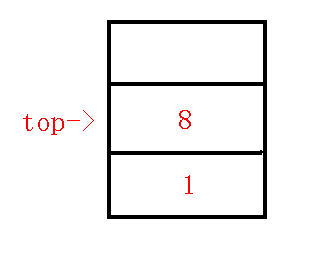
\((5).\)插入\(9\)节点
\(lca(8,9)=8\), 满足\(lca(p,x)=p\)的情况.
直接将\(9\)压栈维护, 此时维护的链为\(1-8-9\).
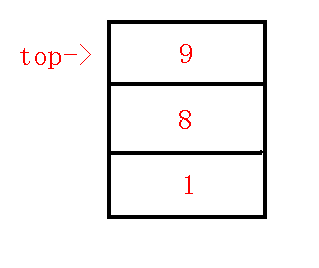
\((6).\)插入\(10\)节点.
\(lca(9,10)=1\), 两个节点位于\(lca\)的两棵不同子树中, 求出\(q=8\).
发现\(dfn[q]>dfn[lca]\), 连接\(q->p\), 退栈.
此时\(p=8,q=1,lca=1\).
发现\(dfn[q]=dfn[lca]\), 所以连接\(lca->p\), 退栈, 将\(10\)入栈, 如下图.
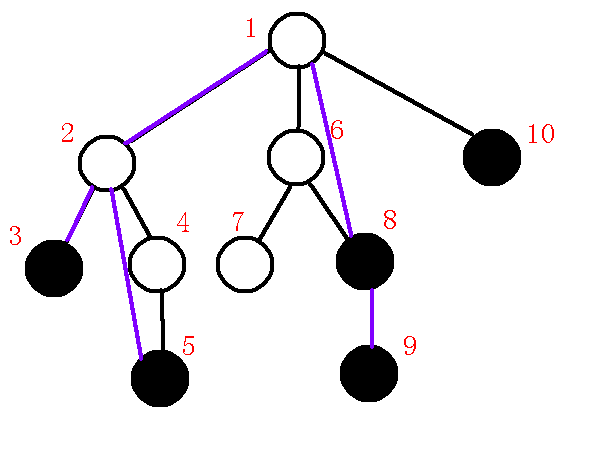
\((7).\)清空栈内剩余元素.
我们依次由\(sta[top-1]\)向\(sta[top]\)连边, 即连接\(1->10\).
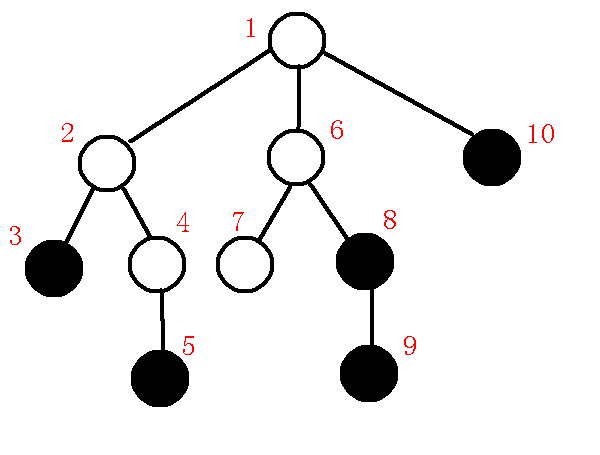
完成后如下:
将紫色的边提出后形成的树即为虚树, 如下图所示:
code:
void Build_Virtual_Tree (int k) {
sort(a + 1, a + k + 1, cop);//按 dfs 序从小到大排序;
if(a[1] != 1) sta[top = 1] = 1;//默认根节点为关键点;
for(int i = 1; i <= k; ++ i) {
int x = a[i];
//↓↓点1不会出栈(最后才会特殊处理), 因此top=1时可以直接加入点(lca(1,x)=1,一定会直接入栈).
if(top <= 1) { sta[++ top] = x; continue; }
int lca = LCA(sta[top], x);
if(lca == sta[top]) { sta[++ top] = x; continue; } //情况(1), 直接加入;
while((top > 1) && dep[sta[top - 1]] >= dep[lca]) Add(sta[top - 1], sta[top]), top --;//循环处理(2)的①;
if(lca != sta[top]) Add(lca, sta[top]), sta[top] = lca;//情况(2)的③.
sta[++ top] = x;
}
时间复杂度
每个指定点进出栈一次, \(O(k)\).
例题
题目大意:
给定一棵树, 每组询问给定\(k\)个点, 你可以删掉不同于那\(k\)个点的\(m\)个点, 使得这\(k\)个点两两不连通, 要求最小化\(m\), 如果不可能输出\(-1\).询问之间独立.多组询问.
\(n\leq 10^5,\sum k\leq 10^5\).
题解:
对于每组询问, 构建虚树, 在虚树上进行\(DP\).
特判无解: 存在某个点和它父亲都被指定.
将被指定的点\(tag\)设成\(1\), 然后\(dfs\)这颗虚树.
假设当前\(dfs\)到点\(u\).
\((1).\)点\(x\)为被指定的点.
若存在子结点\(v\)的\(tag\neq 0\), 即\(u->v\)出现连通.
此时在\(u->v\)的路径上(不包括\(u,v\))随便删除一点(\(++ans\))即可.
若所有子结点\(tag=0\), 则不用进行处理.
\((2).\)点\(x\)为未被指定的点.
统计有多少个子结点\(tag\neq 0\).
若只有一个, 则可以尽量不删除点, 但因为\(x\)是未被指定的点(\(tag=0\)), 因此将\(x\)点\(tag\)设为\(1\).
若超过一个, 此时若不删除点, 就会存在连通.
而\(x\)点是未被指定的点, 所以可以删除点\(x\)(\(++ans\)).
若对于每个询问\(memset()\), 复杂度会退化到\(nq\).
树链剖分求\(lca\), 时间复杂度:\(O(n+\sum klog_2n)\).
倍增/\(ST\)表求\(lca\), 时间复杂度:\(O(n+nlog_2n)\).
多组数据, 因此在每组数据中最后一遍\(dfs\)虚树时, 应将边清空.
方式:修改头指针, 若为\(vector\), 直接\(clear\)即可.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <vector>
#include <cstring>
#include <algorithm>
#define int long long
using namespace std;
typedef long long LL;
const int N = 3e5 + 5;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
int n, m;
struct Edge {
int to;
Edge* nxt;
Edge(int to, Edge* nxt) : to(to), nxt(nxt) {}
} *head[N];
void add(int x, int y) {
head[x] = new Edge(y, head[x]);
}
vector<int> v[N];
void Add(int x, int y) { v[x].push_back(y); }
int a[N], dfn[N], Top[N], siz[N], son[N], sta[N];
int top, dep[N], fa[N], tot, ans, tag[N];
int cop(int x, int y) { return dfn[x] < dfn[y]; }
void dfs1(int x, int f) {
dep[x] = dep[fa[x] = f] + (siz[x] = 1);
for(Edge* i = head[x]; i; i = i->nxt) {
if(i->to == f) continue;
dfs1(i->to, x);
siz[x] += siz[i->to];
if(siz[i->to] > siz[son[x]]) son[x] = i->to;
}
}
void dfs2(int x, int tp) {
Top[x] = tp; dfn[x] = ++ tot;
if(!son[x]) return;
dfs2(son[x], tp);
for(Edge* i = head[x]; i; i = i->nxt) {
if(Top[i->to] == 0) {
dfs2(i->to, i->to);
}
}
}
int LCA(int x, int y) {
while(Top[x] != Top[y]) {
if(dep[Top[x]] < dep[Top[y]]) swap(x, y);
x = fa[Top[x]];
}
return dep[x] < dep[y] ? x : y;
}
void Build_Virtual_Tree (int k) {
sort(a + 1, a + k + 1, cop);
if(a[1] != 1) sta[top = 1] = 1;
for(int i = 1; i <= k; ++ i) {
int x = a[i];
if(top <= 1) { sta[++ top] = x; continue; }
int lca = LCA(sta[top], x);
if(lca == sta[top]) { sta[++ top] = x; continue; }
while((top > 1) && dep[sta[top - 1]] >= dep[lca]) Add(sta[top - 1], sta[top]), top --;
if(lca != sta[top]) Add(lca, sta[top]), sta[top] = lca;
sta[++ top] = x;
}
while(top) Add(sta[top - 1], sta[top]), top --;
}
void DP(int x) {
if(tag[x]) { //x是关键点;
for(int i = 0; i < (int)v[x].size(); ++ i) {
int to = v[x][i]; DP(to);
if(tag[to]) tag[to] = 0, ans; //若不删边, 则会有连通;
}
}
else { //x不是关键点;
for(int i = 0; i < (int)v[x].size(); ++ i) {
int to = v[x][i]; DP(to);
tag[x] += tag[to]; //将关键点个数累加到父亲节点上;
tag[to] = 0; //清零,不能memset,否则复杂度退化;
}
if(tag[x] > 1) tag[x] = 0, ans ++; //若不删边, 则会有连通;
}
v[x].clear();
}
signed main() {
n = read();
for(int i = 1, x, y, z; i < n; ++ i) {
x = read(); y = read();
add(x, y); add(y, x);
}
dfs1(1, 0); dfs2(1, 1);
m = read();
while(m --> 0) {
int k = read();
for(int i = 1; i <= k; ++ i) tag[a[i] = read()] = 1;
int flag = 0;
for(int i = 1; i <= k; ++ i) {
if(tag[fa[a[i]]]) { puts("-1"); flag = 1; break; }
}
if(flag == 1) {
for(int i = 1; i <= k; ++ i) tag[a[i]] = 0;
continue;
}
ans = 0;
Build_Virtual_Tree(k);
DP(1);
printf("%lld\n", ans);
tag[1] = 0;
}
return 0;
}
题目大意:
给出一棵树, 每条边有边权.
有\(m\)次询问, 每次询问给出\(k\)个点, 问使得这\(k\)个点均不与1号点(根节点)相连的最小代价.
\(n\leq 250000, m\geq 1, \sum k \leq 5*10^5\).
题解:
对于每组询问, 在虚树上\(DP\).
设\(f[x]\)为\(x\)为根的子树全部与根节点断开的最小代价.
设\(minl[i]\)表示根节点到\(i\)路径上的最小边权.
特殊的, \(minl[1]=inf\).
设边\(Edge\)上的两点\(x,y(dep[x]<dep[y])\).
\(minl[y]=Min(minl[x],i->val)\).
\(f[x]=Min\Bigg (Minl[x],\displaystyle \sum_{k\in son[x]}Minl[k]\Bigg)\).
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <vector>
#include <cstring>
#include <algorithm>
#define int long long
using namespace std;
typedef long long LL;
const int N = 3e5 + 5;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
int n, m;
struct Edge {
int to, val;
Edge* nxt;
Edge(int to, int val, Edge* nxt) : to(to), val(val), nxt(nxt) {}
} *head[N];
void add(int x, int y, int z) {
head[x] = new Edge(y, z, head[x]);
}
vector<int> v[N];
void Add(int x, int y) { v[x].push_back(y); }
int a[N], dfn[N], Top[N], siz[N], son[N], sta[N];
int top, dep[N], fa[N], tot, minl[N];
int cop(int x, int y) { return dfn[x] < dfn[y]; }
void dfs1(int x, int f) {
dep[x] = dep[fa[x] = f] + (siz[x] = 1);
for(Edge* i = head[x]; i; i = i->nxt) {
if(i->to == f) continue;
minl[i->to] = min(minl[x], (LL)i->val);
dfs1(i->to, x);
siz[x] += siz[i->to];
if(siz[i->to] > siz[son[x]]) son[x] = i->to;
}
}
void dfs2(int x, int tp) {
Top[x] = tp; dfn[x] = ++ tot;
if(!son[x]) return;
dfs2(son[x], tp);
for(Edge* i = head[x]; i; i = i->nxt) {
if(Top[i->to] == 0) {
dfs2(i->to, i->to);
}
}
}
int LCA(int x, int y) {
while(Top[x] != Top[y]) {
if(dep[Top[x]] < dep[Top[y]]) swap(x, y);
x = fa[Top[x]];
}
return dep[x] < dep[y] ? x : y;
}
void Build_Virtual_Tree (int k) {
sort(a + 1, a + k + 1, cop);
if(a[1] != 1) sta[top = 1] = 1;
for(int i = 1; i <= k; ++ i) {
int x = a[i];
if(top <= 1) { sta[++ top] = x; continue; }
int lca = LCA(sta[top], x);
if(lca == sta[top]) continue; //特殊判断,关键点以下的关键点无用,若加入虚树中后,DP有误.
while((top > 1) && dep[sta[top - 1]] >= dep[lca]) Add(sta[top - 1], sta[top]), top --;
if(lca != sta[top]) Add(lca, sta[top]), sta[top] = lca;
sta[++ top] = x;
}
while(top) Add(sta[top - 1], sta[top]), top --;
}
int DP(int x) {
if(v[x].size() == 0) return minl[x];
int sum = 0;
for(int i = 0; i < v[x].size(); ++ i) {
sum += DP(v[x][i]);
}
v[x].clear();
return Min(minl[x], sum);//当点x为关键点时,返回值一定为min[x],故不用分类讨论;
}
signed main() {
freopen("1.in", "r", stdin);
freopen("a.out", "w", stdout);
n = read();
for(int i = 1, x, y, z; i <= n - 1; ++ i) {
x = read(); y = read(); z = read();
add(x, y, z); add(y, x, z);
}
minl[1] = 1e18;
dfs1(1, 0); dfs2(1, 1);
m = read();
while(m --> 0) {
int k = read();
for(int i = 1; i <= k; ++ i) a[i] = read();
Build_Virtual_Tree(k);
printf("%lld\n", DP(1));
}
return 0;
}
斯坦纳树
引言
给定一张图, 若要求某几个点的生成树, 而不强制要求其点连通(可以连通)的代价.
常见的问题有最小斯坦纳树\(Minimal\ Steiner\ Tree(MST)\)
实际上, 斯坦纳树常用于解决一类没有多项式解法的最小生成树问题.
斯坦纳树使用状压\(DP\)求解这类问题.
例题
题解:
最终形成的图一定没有环, 且一定都互相连通,
即最终形成的图为一个树.
最小斯坦纳树求解通法:
设\(f[i][sta]\)表示考虑到以\(i\)节点为根, 且与之相连的景点的状态为\(sta\)的最小代价.
\(sta\)为二进制数, \(0\)表示不连通, \(1\)表示联通.
初始化: \(f[i][1<<(i-1)]=0\).
转移有两种情况:
- 由\(sta\)的子集\(s\)转移过来
考虑合并两个连通块, 要减去一个\(i\)的权值(防止加重)
转移可以通过二进制枚举来实现.
- 由不含该点的状态转移过来
点\(i\)为新加入的点(\(i,\ k\)相邻).
该转移没有明确的转移顺序, 因为\(i,k\)相邻时, 状态可以互相转化.
即对于上文的方程, 我们还可以反过来转移:
对于这类问题的转移, 可以类比最短路\(dis[i]=Min(dis[j]+val(i,j))\),
同样都是可以反过来转移: \(dis[j]=Min(dis[i]+val(j,i))\).
但究其本质, 当最短路完成转移时, 实际上是每条边都满足三角形不等式.
即对于任意一条边\(len=val(i,j)\), 都满足\(dis[i]\leq dis[j]+len\).
若不满足三角形不等式, 则\(dis[i]\)一定不是最优状态.
因此可得, 这类问题可以利用\(SPFA\)不断松弛优化转移.
时间复杂度:\(O(n*3^k+cE*2^k)\).
\(c\)为\(SPFA\)复杂度中的常数, \(E\)为边的数量, 但几乎达不到全部边的数量, 甚至非常小,
\(3^k\)来自于子集的转移\(\displaystyle \sum_{i=1}^n C(i,n)*2^i\), 二项式展开求和.
此题中将\(i\)转化为二维的点即可.
输出方案的话直接记录路径, 记录从哪种方式的哪种状态转移过来, \(dfs\)一遍即可.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
#define fi first
#define se second
using namespace std;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
int n, m, tot = 0;
int dx[5] = {-1, 1, 0, 0};
int dy[5] = {0, 0, -1, 1};
int vis[12][12], a[12][12], f[12][12][1050];
struct node { int x, y, s; } e[12][12][1050];
queue <pair<int, int> > q;
void spfa(int cur) {
while(! q.empty()) {
pair<int, int> p = q.front(); q.pop();
vis[p.fi][p.se] = 0;
for(int i = 0; i <= 3; ++ i) {
int wx = p.fi + dx[i], wy = p.se + dy[i];
if(wx < 1 || wx > n || wy < 1 || wy > m) continue;
if(f[wx][wy][cur] > f[p.fi][p.se][cur] + a[wx][wy]) {
f[wx][wy][cur] = f[p.fi][p.se][cur] + a[wx][wy];
e[wx][wy][cur] = (node) {p.fi, p.se, cur}; //记录最优解的状态转移;
if(vis[wx][wy] == 0) {
vis[wx][wy] = 1; q.push(make_pair(wx, wy));
}
}
}
}
}
void dfs(int x, int y, int now) {
vis[x][y] = 1;
node tmp = e[x][y][now];
if(tmp.x == 0 && tmp.y == 0) return; //搜索边界;
dfs(tmp.x, tmp.y, tmp.s); //缩小搜索范围
if(tmp.x == x && tmp.y == y) { //若最优解为枚举子集转移, 还要搜索另一个子集;
dfs(tmp.x, tmp.y, now - tmp.s);
}
}
int main() {
n = read(); m = read();
memset(f, 0x3f, sizeof(f));
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= m; ++ j) {
a[i][j] = read();
if(a[i][j] == 0) f[i][j][1<<tot] = 0, tot ++; //初始化;
}
}
int sum = (1 << tot) - 1;
for(int sta = 0; sta <= sum; ++ sta) { //枚举状态;
for(int i = 1; i <= n; ++ i) { //枚举点;
for(int j = 1; j <= m; ++ j) {
for(int s = sta; s; s = (s - 1) & sta) { //枚举子集转移;
if(f[i][j][sta] > f[i][j][s] + f[i][j][sta^s] - a[i][j]) {
f[i][j][sta] = f[i][j][s] + f[i][j][sta^s] - a[i][j];
e[i][j][sta] = (node) {i, j, s}; //结构体 e 记录最优解的来源;
}
}
if(f[i][j][sta] < 2e9) { //预先加入到队列中;
q.push(make_pair(i, j)), vis[i][j] = 1;
}
}
}
spfa(sta); //对所枚举的状态松弛转移;
}
int s, t, flag = 0;
for(int i = 1; i <= n; ++ i) { //找到一个景点位置(s,t);
for(int j = 1; j <= m; ++ j) {
if(a[i][j] == 0) {
s = i; t = j;
flag = 1; break;
}
}
if(flag == 1) break;
}
printf("%d\n", f[s][t][sum]); //输出最小斯坦纳树;
memset(vis, 0, sizeof(vis));
dfs(s, t, sum);
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= m; ++ j) {
if(a[i][j] == 0) putchar('x'); //景点;
else if(vis[i][j]) putchar('o'); //选择了这条路;
else putchar('_'); //未选择这条路;
}
puts("");
}
return 0;
}
题目大意:
给出一张\(n\)个点\(m\)条边的无向图和\(p\)个特殊点, 每个特殊点有一个颜色\(c_i\).
要求选出若干条边, 使得颜色相同的特殊点在同一个连通块内. 输出最小边权和.
\(0<c_i\leq p\leq 10,0<n\leq 10^3,0\leq m\leq 3000\).
题解:
斯坦纳树 + 状压\(DP\).
先求出斯坦纳树.
对于本题, 选出的连通块不一定只有一个, 不能直接得到答案.
状压\(DP\), 设\(g[i]\)表示状态为\(i\)的颜色满足同颜色的点全部连通的最小代价.
若只存在一个连通块, 则答案为斯坦纳树的\(f[i][sta]\).
若存在多连通块, 则枚举子集进行转移即可.
时间复杂度:\(O(3^p*n+c*E*2^p)\).
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#define RI register int
using namespace std;
const int N = 1030;
inline int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
queue <int> q;
int n, m, p, c[N], d[N], g[N], vis[N][N], f[N][N];
struct Edge {
int to, val;
Edge* nxt;
Edge(int to, int val, Edge* nxt) : to(to), val(val), nxt(nxt) {};
} *head[N<<3];
void add(int x, int y, int z) { head[x] = new Edge(y, z, head[x]); }
int main() {
n = read(); m = read(); p = read();
memset(f, 0x3f, sizeof(f));
for(RI i = 1, x, y, z; i <= m; ++ i) {
x = read(); y = read(); z = read();
add(x, y, z); add(y, x, z);
}
for(RI i = 1; i <= p; ++ i) {
c[i] = read(); d[i] = read();
f[d[i]][1 << (i - 1)] = 0;
}
for(RI i = 1; i <= n; ++ i) f[i][0] = 0;
for(RI sta = 1; sta < (1<<p); ++ sta) {
for(RI s = sta; s; s = (s - 1) & sta) {
for(RI k = 1; k <= n; ++ k) {
f[k][sta] = Min(f[k][sta], f[k][s] + f[k][sta ^ s]);
}
}
for(RI j = 1; j <= n; ++ j) q.push(j), vis[j][sta] = 1;
while(! q.empty()) {
int x = q.front(); q.pop();
vis[x][sta] = 0;
for(Edge* j = head[x]; j; j = j->nxt) {
if(f[j->to][sta] > f[x][sta] + j->val) {
f[j->to][sta] = f[x][sta] + j->val;
if(vis[j->to][sta] == 0) q.push(j->to);
}
}
}
}
memset(g, 0x3f, sizeof(g));
for(int i = 1; i < (1 << p); ++ i) { //二进制枚举颜色,(颜色状态上限为(1<<p)-1);
int k = 0; //k保存二进制特殊点;
for(RI j = 1; j <= p; ++ j) { //枚举特殊点, 计算k;
if(i & (1 << (c[j] - 1))) k |= (1 << (j - 1));
}
for(RI j = 1; j <= n; ++ j) g[i] = Min(g[i], f[j][k]); //考虑全集;
for(RI j = i; j; j = (j - 1) & i) g[i] = Min(g[i], g[j] + g[i ^ j]); //考虑子集;
}
printf("%d\n", g[(1 << p) - 1]);
return 0;
}
插头DP
简介
下面是你要的插头, 至于你说的插头DP是什么?

\(呃\dots\)
插头DP为"基于连通性状态压缩的动态规划问题"的简称, 最早出现在陈丹琦的论文中.
基本概念
插头
代指两个格子之间的连通性.
若\(DP\)的某一个状态中, 某相邻的两个格子为连通的(如:处于同一条路径上, 被同一个矩形覆盖\(\dots\)), 那么我们认为这两个格子之间存在插头.

如图, 格子\((1, 1)\)与格子\((2, 1)\)连通,则称格子\((1, 1)\)有一个下插头,格子\((2, 1)\)有一个上插头.
每个格子所拥有的插头数量因题目而异.
如下图, 一条回路的插头表示:

轮廓线
轮廓线为一条分割线.
作用为分隔开\(DP\)已经覆盖的状态和暂未覆盖的状态, 轮廓线是在插头DP的棋盘模型中被定义的.
插头\(DP\)的两种\(DP\)方式: 逐行递推, 逐格递推.
逐行递推的方式在很多题目中状态过多, 因此一般会使用逐格递推.
下文的讲解都是基于逐格递推.
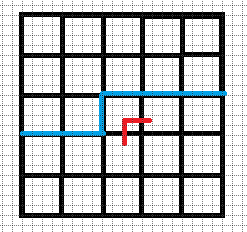
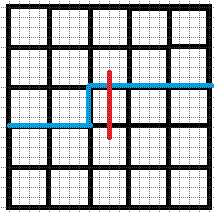
逐格递推的轮廓线:
设当前正在递推格子\((i,\ j)\).
那么轮廓线即为一条从棋盘左边界开始,沿着第i行的格子底部向右延伸至格子\((i,j)\)的左下角,
然后向上一格,再一直向右延伸到棋盘右边界的一条线.
轮廓线的长度为\(m(\mbox{列数}) + 1\).
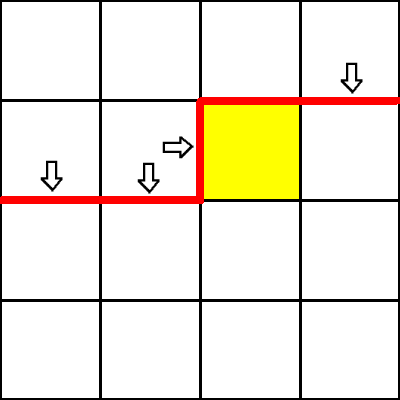
黄色格子为正在递推的格子(由黄色格子左面的格子向黄色格子转移).
红色的线为轮廓线.
轮廓线的上方有\(m\)个下插头位置和一个右插头位置.
轮廓线的实际作用:存储状态.
棋盘模型
给定一个棋盘(约为\(15*15\)), 有些格子可能为障碍.
求使用闭合路径或一些特殊形状的图案覆盖棋盘上的每一个格子的 最优回路 / 方案数.
题目中的关键点:
把轮廓线画出来以后,轮廓线上方的会是一些完备的“题目要求的形状”和一些“一头扎到”轮廓线下面,
也就是被轮廓线切割的形状,而这些被切割的形状在轮廓线上方的分布我们不清楚,
但是我们可以用轮廓线上插头的状态来表示所有情形的和.
例如:
现在有一条轮廓线, 轮廓线上面有一些插头.
我们现在可能不知道轮廓线上面的情况具体是怎么样的, 但是我们根据这些插头就能往下推下面的状态.
所以我们只要记录这种插头状态下轮廓线上方的答案, 然后往下推就好了.
即 将\(dfs\)找覆盖的问题 转化 成了\(dp\)模型.
从插头DP的棋盘模型中, 引出插头DP中棋盘模型的状态定义:
设\(f[i][j][s]\)为当前递推到格子\((i,\ j)\), 轮廓线状态为 \(s\) 的方案数.
例题
题目大意:
给定一张\(n*m\)的网格图, 求经过所有非障碍点一次的回路个数.
\(2\leq n,m\leq12\).
题解:
插头\(DP\): 我们使用逐格递推.
设\(f[i][j][s]\)表示当前递推到格子\((i,j)\), 轮廓线状态为\(s\)的方案数.
考虑我们在递推到某一个格子时, 这个格子和下一个格子所对应的轮廓线.
假设我们递推到某一个格子时的轮廓线为下图:
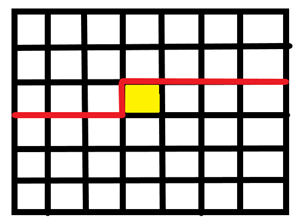
则对于下一个格子来说, 其轮廓线为:
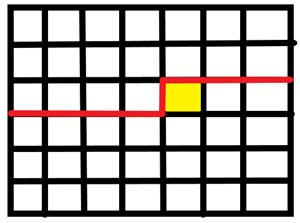
观察这两个轮廓线, 发现仅有两个位置不同.
我们从上一格的状态推到下一格的状态, 即如下图所示:
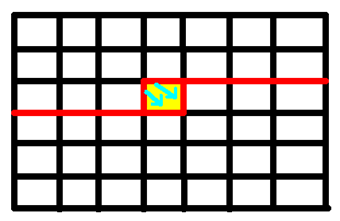
对于格子\((3,4)\)来说, 我们可以仅由这个格子推导到下一个状态.
设\(b1\)为格子\((3,4)\)的左边界状态, \(b2\)为格子\((3,4)\)的上边界状态.
考虑如何表示状态.
括号表示法
考虑用一个\(k\)进制数表示状态.
轮廓线上从左到右再到上最后到右每一个位置分别存储在这个数的第\(0,1,\dots,m\)位.
令\(0\)表示无插头, \(1\)表示左端点, \(2\)表示右端点.
举个例子:
我们用四进制数表示这个状态为: \(202101\), (图中从左往右为状态中低位到高位).
使用四进制而不使用三进制的原因: 使用四\((2^k)\)进制可以利用位移加速运算.
右端点和左端点状态分别为\(1\)和\(2\), 而不是全都是\(1\)的原因:
\(b1=2 ,b2=1\)和\(b1=1,b2=2\)的状态会产生不同的结果, 见下文分类讨论.
\(1.\)当前点为障碍点.
此时只有\(b1=0,b2=0\)才是合法的状态.
且转移后的状态与转移前的状态相同.
\(2.\)当前点不是障碍点
\((1).b1=0,b2=0\).
为确保每个点都被走过, 加入一个右插头和一个下插头.
\((2).b1=0,b2\neq0\).
则\(b2\)所表示的插头可以选择直走, 或者选择向右拐, 括号状态不变.
\((3).b1\neq0,b2=0\).
情况同\((2)\), 即\(b1\)所表示的插头可以选择直走, 或者选择向下拐, 括号状态不变.
\((4).b1=1,b2=1\).
两个左端点对接, 此时\(b2\)所对应的右端应变为新状态的左端(否则括号数量不匹配).
做法: \(O(m)\)向右扫描插头, 当右端点比左端点数量大\(1\)时, 则这个右端点才可能是\(b2\)的另一端.
将这个右端点修改为左端点即可.
\((5).b1=2,b2=2\).
情况同\((4)\), 两个右端点对接, 此时\(b1\)所对应的左端应变为新状态的右端(否则括号数量不匹配).
做法: \(O(m)\)向左扫描插头, 当左端点比右端点数量大\(1\)时, 则这个左端点才可能是\(b1\)的另一端.
将这个左端点修改为右端点即可.
\((6).b1=2,b2=1\).
此时两个不同情况的插头对接.
不同于情况\((4)\)和情况\((5)\), 我们可以直接令这两个插头对接, 所对应的另外两个插头仍然是匹配的.
\((7).b1=1,b2=2\).
此时说明这个回路闭合.
若这个点为终点(最后一个合法的格子), 更新答案.
否则情况不合法, 不计入答案.
这\(8\)种情况可以表示出所有的状态.
时间复杂度:\(O(nm*4^{m+1})\).
我们通过合法状态进行转移.
由于合法状态极少, 所以常数极小, 时间上可以通过.
空间复杂度:\(O(nm*4^{m+1})\).
考虑优化, 当前状态只会受到上一个格子状态的影响.
使用滚动数组进行优化.
空间复杂度:\(O(2*4^{m+1})=O(2^{2m+3})\).
然而还是不行, 然后这题不可做.
仍然是因为合法状态少, 因此我们将状态\(Hash\)处理.
\(Hash\)采用挂表法实现即可.
空间复杂度与合法状态数有关.
因此, 空间复杂度:\(O(\)能过\()\).
code:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#define int long long
using namespace std;
const int N = 15, hs = 299987;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
char ch[N];
int n, m, s, t, now, last, ans;
int a[N][N], bit[N];
int head[300000], nxt[2<<24], cnt[2];
struct node { int sta, val; } e[2][2<<24];
void ins(int sta, int num) {
int key = sta % hs + 1;
for(int i = head[key]; i; i = nxt[i]) {
if(e[now][i].sta == sta) return e[now][i].val += num, (void)0;
}
e[now][++ cnt[now]] = (node) {sta, num}; //挂表;
nxt[cnt[now]] = head[key];
head[key] = cnt[now];
}
signed main() {
n = read(); m = read();
for(int i = 1; i <= n; ++ i) {
cin >> (ch + 1);
for(int j = 1; j <= m; ++ j) {
if(ch[j] != '.') continue;
a[i][j] = 1; s = i; t = j; //s,t记录最后一个合法格子的位置;
}
}
bit[0] = 1;
last = 0; now = 1;
for(int i = 1; i <= 13; ++ i) { //预处理四进制每一位的权值;
bit[i] = bit[i - 1] << 2;
}
ins(0, 1); //初始化, 没有回路算一种方案;
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= cnt[now]; ++ j) { //行间转移;
e[now][j].sta <<= 2;
}
for(int j = 1; j <= m; ++ j) {
memset(head, 0, sizeof(head)); //清空哈希表;
swap(last, now); cnt[now] = 0; //滚动数组;
for(int k = 1; k <= cnt[last]; ++ k) { //枚举上一个格子和合法状态;
int sta = e[last][k].sta, num = e[last][k].val;
int b1 = (sta >> ((j - 1) * 2)) % 4; //四进制提取状态;
int b2 = (sta >> (j * 2)) % 4;
if(a[i][j] == 0) { //大力讨论...
if(b1 == 0 && b2 == 0) ins(sta, num);
}
else if(b1 == 0 && b2 == 0) {
if(a[i+1][j] && a[i][j+1]) ins(sta + bit[j-1] + bit[j] * 2, num);
}
else if(b1 == 0 && b2) {
if(a[i][j + 1]) ins(sta, num);
if(a[i + 1][j]) ins(sta - bit[j] * b2 + bit[j-1] * b2, num);
}
else if(b1 && b2 == 0) {
if(a[i+1][j]) ins(sta, num);
if(a[i][j + 1]) ins(sta - bit[j-1]*b1 + bit[j] * b1, num);
}
else if(b1 == 1 && b2 == 1) {
int k1 = 1;
for(int l = j + 1; l <= m; ++ l) {
if((sta >> (l * 2)) % 4 == 1) k1 ++;
if((sta >> (l * 2)) % 4 == 2) k1 --;
if(k1 == 0) {
ins(sta - bit[j] - bit[j-1] - bit[l], num);
break;
}
}
}
else if(b1 == 2 && b2 == 2) {
int k1 = 1;
for(int l = j - 2; ~l; -- l) {
if((sta >> (l * 2)) % 4 == 1) k1 --;
if((sta >> (l * 2)) % 4 == 2) k1 ++;
if(k1 == 0) {
ins(sta - bit[j] * 2 - bit[j-1] * 2 + bit[l], num);
break;
}
}
}
else if(b1 == 2 && b2 == 1) ins(sta - bit[j-1]*2 - bit[j], num);
if(i == s && j == t) ans += num;
}
}
}
printf("%lld\n", ans);
return 0;
}
题目大意:
给出\(n*m\)的方格,有些格子不能铺线,其它格子必须铺,形成多个闭合回路。
问有多少种铺法?
\(2\leq n,m\leq 12\).
题解:
此题中可以形成多个回路.
在上一题中, 我们使用括号表示法区分左右端点的原因是合并的端点不同时, 对状态转移的影响不同.
实际上是为了防止回路提前闭合而形成多个回路, 形成不合法状态.
而在这道题中, 虽然左右端点对方案总数有影响, 但对方案数的转移无影响.
因此我们不必区分左右端点.
使用二进制来表示即可.\(0\)表示无插头, \(1\)表示有插头.
分情况转移方案数即可.
特别的, 当整张图全部为\(0\)时, 也算一种合法方案.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
#define int long long
using namespace std;
const int N = 15, hs = 299987;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
int T, n, m, now, last, s, t, a[N][N], bit[20], vis[N];
int cnt[2], head[300000], nxt[2<<24];
struct node { int sta, val; } e[2][2<<24];
void ins(int sta, int num) {
int key = sta % hs + 1;
for(int i = head[key]; i; i = nxt[i]) {
if(e[now][i].sta == sta) return e[now][i].val += num, (void)0;
}
e[now][++ cnt[now]] = (node) {sta, num};
nxt[cnt[now]] = head[key];
head[key] = cnt[now];
}
void solve() {
memset(cnt, 0, sizeof(cnt));
memset(vis, 0, sizeof(vis));
memset(head, 0, sizeof(head));
int ans = 0;
last = 0; now = 1;
ins(0, 1);
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= cnt[now]; ++ j) {
e[now][j].sta <<= 1;
}
for(int j = 1; j <= m; ++ j) {
swap(now, last);
memset(head, 0, sizeof(head));
cnt[now] = 0;
for(int k = 1; k <= cnt[last]; ++ k) {
int sta = e[last][k].sta, num = e[last][k].val;
int b1 = (sta >> (j-1)) & 1;
int b2 = (sta >> j) & 1;
if(a[i][j] == 0) {
if(b1 == 0 && b2 == 0) ins(sta, num);
}
else if(b1 == 0 && b2 == 0) {
if(a[i][j + 1] && a[i + 1][j]) ins(sta + bit[j-1] + bit[j], num);
}
else if(b1 == 0 && b2) {
if(a[i][j + 1]) ins(sta, num);
if(a[i + 1][j]) ins(sta + bit[j-1] - bit[j], num);
}
else if(b1 && b2 == 0) {
if(a[i][j + 1]) ins(sta - bit[j-1] + bit[j], num);
if(a[i + 1][j]) ins(sta, num);
}
else {
if(i == s && j == t) ans += num;
else ins(sta - bit[j-1] - bit[j], num);
}
}
}
}
printf("%lld\n", ans);
}
signed main() {
T = read();
bit[0] = 1;
for(int i = 1; i <= 13; ++ i) {
bit[i] = bit[i - 1] << 1;
}
while(T --> 0) {
n = read(); m = read();
memset(a, 0, sizeof(a));
s = t = 0;
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= m; ++ j) {
if((a[i][j] = read()) == 1) { s = i; t = j; }
}
}
if(s == 0 && t == 0) puts("1");
else solve();
}
return 0;
}
题目大意:
\(n*n(n\leq9)\)的带权网格, 求某个联通块的最大和.
题解:
插头\(DP\). 最小表示法.
对于每个格子, 只有两种状态: 选 \(or\) 不选.
重定义轮廓线如下图所示:
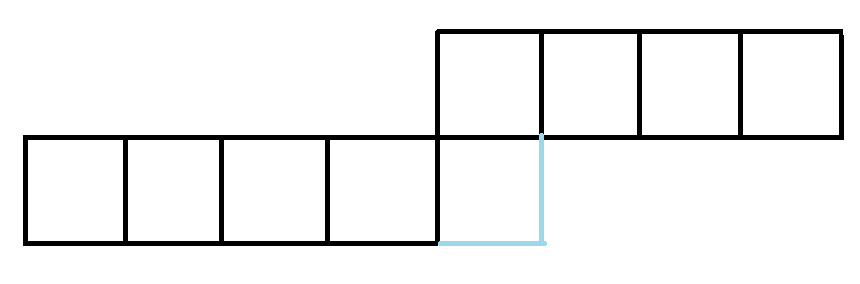
用\(8\)进制数表示轮廓线的状态.
表示方法: 最小表示法.
假设有一个序列\((5,5,3,2,4,1,3,2)\), 序列中的每一个数代表第\(i\)个格子所属的联通分量.
可以将编号等效映射成其他编号.
为了连通性表示的规范和不重不漏, 我们将这个序列整理成意义等效的前提下字典序最小的形式.
即此序列的最小表示为\((1,1,2,3,4,5,2,3)\).
方法:
从前向后遍历, 若当前编号为第一次出现, 将其换为新编号\(tot+1\).
否则将其改为已经记录下来的对应编号.
void Min_express(int num) {
int tot = 0;
for(int i = 1; i <= n; ++ i) {
if(s[i]) {
if(bel[s[i]]) s[i] = bel[s[i]];
else s[i] = bel[s[i]] = ++ tot;
}
}
}
考虑状态转移.
我们不能仅仅考虑每个格子上面的格子和左面的格子.
否则无法处理如下情况:
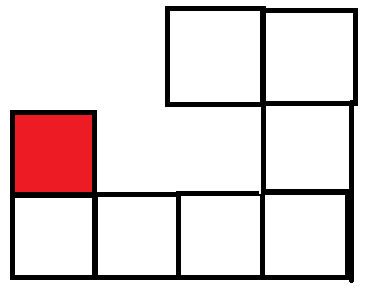
对于红色格子来说, 如果只考虑其上面和左面的格子, 就无法考虑到这种连通情况.
考虑转移:
直接考虑选不选这个格子, 不选它就判断它上面的格子会不会失去连通性.
如果选择, 看一下是合并连通块还是新建连通块.
对于每个格子有两个状态.
- 不选
为考虑状态的合理性, 且最后要保证只有一个连通块.
斯坦纳树
我们只考虑上面的格子, 对于左面的格子, 拖到下一行考虑.
- 选
\((1).b1=0,b2=0\).
这个格子单独形成一个新块, 将此块命名为\(7\).
命名为\(7\)的原因:
在最小表示法下, 连通块的标号从小到大记录, 为了防止和已有的标号冲突.
将新块的标号尽量调大, 到后面再用最小表示法整理状态序列.
\((2).b1=1||b2=1\).
这一个格子被选择后, 会与其他已存在的格子连通, 更新状态即可.
特别的, 一个格子都不选时, 价值为\(0\).
每次更新状态\(O(n)\)标号.
时间复杂度:\(O\Bigg(\left \lfloor \displaystyle \frac{n+1}{2}\right \rfloor ^nn^3 \Bigg)\).无用状态过多.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
#define int long long
using namespace std;
const int N = 15, hs = 299987;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
int n, ans = -2e9, bit[N], a[N][N], head[300000], cnt[2], s[N], nxt[1<<24];
int now = 0, last = 1;
struct node { int sta, val; } e[2][1<<24];
void ins(int sta, int num) {
int key = sta % hs + 1;
for(int i = head[key]; i; i = nxt[i]) {
if(e[now][i].sta == sta) {
return e[now][i].val = Max(e[now][i].val, num), (void)0;
}
}
e[now][++ cnt[now]] = (node) {sta, num};
nxt[cnt[now]] = head[key];
head[key] = cnt[now];
}
int upd(int num) { //将s[]数组利用最小表示法表示后, 返回一个8进制状态数, 若状态合理则更新答案;
int bel[N];
memset(bel, 0, sizeof(bel));
int tot = 0;
for(int i = 1; i <= n; ++ i) {
if(s[i]) {
if(bel[s[i]]) s[i] = bel[s[i]];
else s[i] = bel[s[i]] = ++ tot;
}
}
int res = 0;
for(int i = 1; i <= n; ++ i) {
res += (s[i] << bit[i - 1]);
}
if(tot == 1) ans = Max(ans, num);
return res;
}
void get_bitset(int sta) { //将状态存储到s[]数组中;
for(int i = 1; i <= n; ++ i) {
s[i] = (sta >> bit[i - 1]) % 8;
}
}
signed main() {
n = read();
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= n; ++ j) {
a[i][j] = read();
}
}
for(int i = 1; i <= 10; ++ i) {
bit[i] = i * 3;
}
ins(0, 0); //无连通块时价值为0;
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= n; ++ j) {
swap(now, last); cnt[now] = 0;
memset(head, 0, sizeof(head));
for(int k = 1; k <= cnt[last]; ++ k) {
get_bitset(e[last][k].sta); //得到上一个格子的状态, 考虑不选的情况;
int b1 = s[j - 1], b2 = s[j];
int num = e[last][k].val;
int sum = 0; s[j] = 0;
//↓下↓sum记录轮廓线上和b2属于同一个连通块的格子数量(不包括b2);
for(int l = 1; l <= n; ++ l) {
if(s[l] == b2) sum ++;
}
if(b2 == 0 || sum) ins(upd(num), num);
num += a[i][j]; //即选择了这个格子;
get_bitset(e[last][k].sta); //得到上一个格子的状态, 考虑选的情况;
if(b1 == 0 && b2 == 0) s[j] = 7; //形成一个新连通块;
else {
s[j] = Max(b1, b2); //连通;
for(int l = 1; l <= n; ++ l) { //表示成相同的数;
if(s[l] && s[l] == Min(b1, b2)) {
s[l] = Max(b1, b2);
}
}
}
ins(upd(num), num);
}
}
}
printf("%lld\n", ans);
return 0;
}
题目大意:
\(n*m(2\leq n\leq100,2\leq m\leq 6)\)的带权网格, 求一个最大权闭合回路.
题解:
大力插头DP即可.
由于是一个闭合回路, 因此采用括号表示法.
分类讨论:
\((1).b1=0,b2=0\).
可以不连接插头, 也可以加入一个右插头和下插头.
\((2).b1=0,b2\neq0\).
则\(b2\)所表示的插头可以选择向下走, 或者选择向右拐, 括号状态不变.
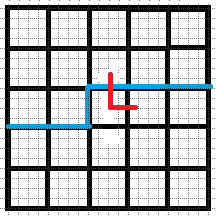
\((3).b1\neq0,b2=0\).
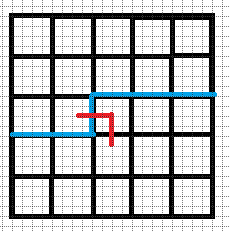
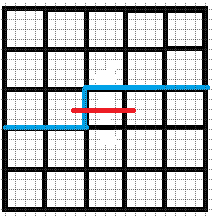
情况同(\(2\)), 即\(b1\)所表示的插头可以选择向右走, 或者选择向下拐, 括号状态不变.
\((4).b1=1,b2=1\).
两个左端点对接, 此时\(b2\)所对应的右端应变为新状态的左端(否则括号数量不匹配).
做法: \(O(m)\)向右扫描插头, 当右端点比左端点数量大\(1\)时, 则这个右端点才可能是\(b2\)的另一端.
将这个右端点修改为左端点即可.

\((5).b1=2,b2=2\).
情况同\((4)\), 两个右端点对接, 此时\(b1\)所对应的左端应变为新状态的右端(否则括号数量不匹配).
做法: \(O(m)\)向左扫描插头, 当左端点比右端点数量大\(1\)时, 则这个左端点才可能是\(b1\)的另一端.
将这个左端点修改为右端点即可.
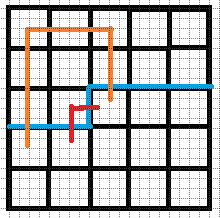
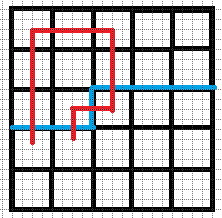
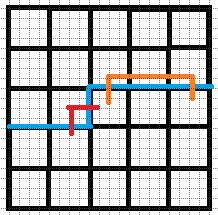
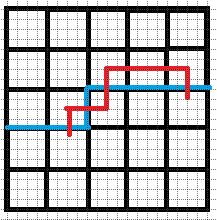
\((6).b1=2,b2=1\).
此时两个不同情况的插头对接.
不同于情况(\(4\))和情况(\(5\)), 我们可以直接令这两个插头对接, 所对应的另外两个插头仍然是匹配的.
\((7).b1=1,b2=2\).
此时说明这个回路闭合.
若其他地方没有插头则更新答案.
否则情况不合法, 不计入答案.
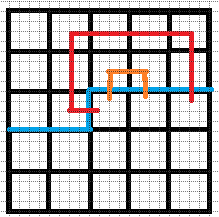
下图分别表示合法状态和不合法状态.
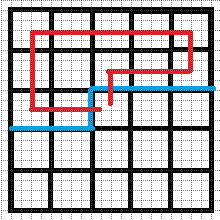
滚动数组 + 哈希表 优化.
时间复杂度:\(O(nm*4^{m+1})\).
code:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#define int long long
using namespace std;
const int N = 15, hs = 299987;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
char ch[N];
int n, m, s, t, now, last, ans = -2e9;
int a[105][105], bit[N];
int head[300000], nxt[2<<24], cnt[2];
struct node { int sta, val; } e[2][2<<24];
int cur, pre;
void ins(int sta, int val) {
int key = sta % hs + 1;
for(int i = head[key]; i; i = nxt[i]) {
if(e[cur][i].sta == sta) {
e[cur][i].val = Max(e[cur][i].val, val);
return;
}
}
e[cur][++ cnt[cur]] = (node) {sta, val};
nxt[cnt[cur]] = head[key];
head[key] = cnt[cur];
}
signed main() {
n = read(); m = read();
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= m; ++ j) {
a[i][j] = read();
}
}
for(int i = 1; i <= 10; ++ i) {
bit[i] = i << 1;
}
cur = 1, pre = 0;
cnt[cur] = 1;
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= cnt[cur]; ++ j) {
e[cur][j].sta <<= 2;
}
for(int j = 1; j <= m; ++ j) {
swap(cur, pre);
cnt[cur] = 0;
memset(head, 0, sizeof(head));
for(int k = 1; k <= cnt[pre]; ++ k) {
int now = e[pre][k].sta, val = e[pre][k].val;
int b1 = (now >> bit[j-1]) % 4;
int b2 = (now >> bit[j]) % 4;
if(b2 == 0 && b1 == 0) {
ins(now, val);
if(j != m) ins(now + (1<<bit[j-1]) + ((1<<bit[j])<<1), val + a[i][j]);
}
if(b2 && b1 == 0) {
ins(now - b2*(1<<bit[j]) + b2*(1<<bit[j-1]), val + a[i][j]);
if(j != m) ins(now, val + a[i][j]);
}
if(b2 == 0 && b1) {
ins(now, val + a[i][j]);
if(j != m) ins(now - b1*(1<<bit[j-1]) + b1*(1<<bit[j]), val + a[i][j]);
}
if(b2 == 1&&b1 == 1) {
int cnt = 1;
for(int l = j + 1; l <= m; ++ l) {
if((now >> bit[l]) % 4 == 1) cnt ++;
if((now >> bit[l]) % 4 == 2) cnt --;
if(cnt == 0) {
ins(now - (1<<bit[l]) - (1<<bit[j-1]) - (1<<bit[j]), val + a[i][j]);
break;
}
}
}
if(b2 == 2 && b1 == 2) {
int cnt = 1;
for(int l = j - 2; ~l; -- l) {
if((now >> bit[l]) % 4 == 1) cnt --;
if((now >> bit[l]) % 4 == 2) cnt ++;
if(cnt == 0) {
ins(now + (1<<bit[l]) - ((1<<bit[j-1])<<1) - ((1<<bit[j])<<1), val + a[i][j]);
break;
}
}
}
if(b2 == 1 && b1 == 2) {
ins(now - ((1<<bit[j-1])<<1) - (1<<bit[j]), val + a[i][j]);
}
if(b2 == 2 && b1 == 1) {
if(now == ((1<<bit[j])<<1) + (1<<bit[j-1])) {
ans = Max(ans, val + a[i][j]);
}
}
}
}
}
printf("%lld\n", ans);
return 0;
}
题目大意:
给定一张\(R*C(R*C\leq100)\)大小的网格图, 求用\(L\)型地板铺满所有非障碍点的方案数.
题解:
插头\(DP\).
发现对于存在的插头, 有两种状态: 拐过弯和未拐过弯.
因此我们这样定义插头: \(0\)表示没有插头, \(1\)表示未拐过弯的插头, \(2\)表示拐过弯的插头.
分类讨论:
\((1).b1=0,b2=0\).
可以选择加入一个未拐弯的下插头 或 一个未拐弯的右插头 或 一个地板的拐弯处.
\((2).b1=0,b2=1\).
\(b2\)可以选择向下延伸直走, 或者 选择向右拐.
\((3).b1=1,b2=0\).
情况同\((2)\), \(b1\)可以选择向右延伸直走, 或者 选择向下拐.
\((4).b1=0,b2=2\).
\(b2\)可以选择向下延伸直走.
或者选择结束延伸, 去掉插头即可. 若此格子为终点, 可以更新答案.
\((5).b1=2,b2=0\).
情况同\((4)\),\(b1\)可以选择向右延伸直走.
或者选择结束延伸, 去掉插头即可. 若此格子为终点, 可以更新答案.
\((6).b1=1,b2=1\).
两个未拐过弯的插头形成一个拐过弯的插头.
滚动数组 + 哈希表 优化即可.
code:
#include <iostream>
#include <cstdio>
#include <queue>
#include <cstring>
#include <algorithm>
#define int long long
using namespace std;
const int hs = 299987, mod = 20110520;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
char ch;
int n, m, s, t, ans, bit[25], a[105][105], b[105][105];
int cnt[2], cur, pre, head[300000], nxt[2<<20];
struct node { int sta, val; } e[2][2<<20];
void ins(int sta, int num) {
int key = sta % hs + 1;
for(int i = head[key]; i; i = nxt[i]) {
if(e[cur][i].sta == sta) {
(e[cur][i].val += num) %= mod;
return;
}
}
e[cur][++ cnt[cur]] = (node) {sta, num % mod};
nxt[cnt[cur]] = head[key];
head[key] = cnt[cur];
}
signed main() {
n = read(); m = read();
for(int i = 1; i <= 20; ++ i) { //预处理 i * 2;
bit[i] = i << 1;
}
if(n > m) { //(s,t)记录最后一个合法点位置;
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= m; ++ j) {
ch = getchar();
while(ch != '*' && ch != '_') ch = getchar();
a[i][j] = (ch == '_');
if(a[i][j]) s = i, t = j;
}
}
}
else { //将图向右躺下;
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= m; ++ j) {
ch = getchar();
while(ch != '*' && ch != '_') ch = getchar();
b[i][j] = (ch == '_');
}
}
for(int i = 1; i <= m; ++ i) {
for(int j = 1; j <= n; ++ j) {
a[i][j] = b[j][i];
if(a[i][j]) s = i, t = j;
}
}
swap(n, m);
}
cur = 1;
ins(0, 1); //初始化;
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= cnt[cur]; ++ j) { //行间转化;
e[cur][j].sta <<= 2;
}
for(int j = 1; j <= m; ++ j) {
swap(cur, pre); cnt[cur] = 0; //滚动数组;
memset(head, 0, sizeof(head));
for(int k = 1; k <= cnt[pre]; ++ k) {
int sta = e[pre][k].sta, num = e[pre][k].val;
int b1 = (sta >> bit[j - 1]) % 4; //取出状态;
int b2 = (sta >> bit[j]) % 4;
if(a[i][j] == 0) {
if(b1 == 0 && b2 == 0) { ins(sta, num); continue; }
}
if(b1 == 0 && b2 == 0) {
if(a[i+1][j] && a[i][j+1]) { //拐弯处;
ins(sta + ((1<<bit[j-1])<<1) + ((1<<bit[j])<<1), num);
}
if(a[i+1][j]) ins(sta + (1<<bit[j-1]), num); //开始向下铺;
if(a[i][j+1]) ins(sta + (1<<bit[j]), num); //开始向右铺;
}
if(b1 == 1 && b2 == 0) {
if(a[i][j+1]) ins(sta - (1<<bit[j-1]) + (1<<bit[j]),num); //b1直走;
if(a[i+1][j]) ins(sta + (1<<bit[j-1]), num); //b1向下拐;
}
if(b2 == 1 && b1 == 0){
if(a[i+1][j]) ins(sta - (1<<bit[j]) + (1<<bit[j-1]), num); //b2直走;
if(a[i][j+1]) ins(sta + (1<<bit[j]), num); //b2右拐;
}
if(b1 == 2 && b2 == 0){
if(i == s && j == t) (ans += num) %= mod;
if(a[i][j+1]) ins(sta - ((1<<bit[j-1])<<1) + ((1<<bit[j])<<1), num);
ins(sta - ((1<<bit[j-1])<<1), num);
}
if(b2 == 2 && b1 == 0){
if(i == s && j == t) (ans += num) %= mod;
if(a[i+1][j]) ins(sta - ((1<<bit[j])<<1) + ((1<<bit[j-1])<<1), num);
ins(sta - ((1<<bit[j])<<1), num); //切断;
}
if(b2 == 1 && b1 == 1) {
if(i == s && j == t) (ans += num) %= mod;
ins(sta - (1<<bit[j-1]) - (1<<bit[j]), num); //合并;
}
}
}
}
printf("%lld\n", ans);
return 0;
}
题目大意:
给定一张\(n*m\)的网格图, 求经过所有非障碍点一次的回路个数.
\((1\leq n\leq 20,1\leq m\leq 10)\)
题解:
双倍经验, 同\(P5056\)【模板】插头\(dp\)
强化型模板题, 然而需要 高精 / __\(int128\)...
code:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 25, hs = 2501;
int read() {
int x = 0, f = 1; char ch;
while(! isdigit(ch = getchar())) (ch == '-') && (f = -f);
for(x = ch^48; isdigit(ch = getchar()); x = (x<<3) + (x<<1) + (ch^48));
return x * f;
}
template <class T> T Max(T a, T b) { return a > b ? a : b; }
template <class T> T Min(T a, T b) { return a < b ? a : b; }
__int128 n, m, s, t, now, last, ans;
__int128 a[N][N], bit[N];
__int128 head[2505], nxt[2<<20], cnt[2];
struct node { __int128 sta, val; } e[2][2<<20];
inline void ins(__int128 sta, __int128 num) {
__int128 key = sta % hs + 1;
for(__int128 i = head[key]; i; i = nxt[i]) {
if(e[now][i].sta == sta) return e[now][i].val += num, (void)0;
}
e[now][++ cnt[now]] = (node) {sta, num};
nxt[cnt[now]] = head[key];
head[key] = cnt[now];
}
inline void write(__int128 x) {
if(x < 0) putchar('-'), x=-x;
if(x > 9) write(x / 10);
putchar(x % 10 + '0');
}
signed main() {
m = read(); n = read();
if(n == 1 || m == 1) return puts("1"), 0;
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= m; ++ j) {
a[i][j] = 1;
}
}
s = n, t = m;
bit[0] = 1;
last = 0; now = 1;
for(int i = 1; i <= m; ++ i) {
bit[i] = bit[i - 1] << 2;
}
ins(0, 1);
for(int i = 1; i <= n; ++ i) {
for(int j = 1; j <= cnt[now]; ++ j) {
e[now][j].sta <<= 2;
}
for(int j = 1; j <= m; ++ j) {
memset(head, 0, sizeof(head));
swap(last, now);
cnt[now] = 0;
for(int k = 1; k <= cnt[last]; ++ k) {
__int128 sta = e[last][k].sta, num = e[last][k].val;
__int128 b1 = (sta >> ((j - 1) * 2)) % 4;
__int128 b2 = (sta >> (j * 2)) % 4;
if(a[i][j] == 0) {
if(b1 == 0 && b2 == 0) ins(sta, num);
}
else if(b1 == 0 && b2 == 0) {
if(a[i+1][j] && a[i][j+1]) ins(sta + bit[j-1] + bit[j] * 2, num);
}
else if(b1 == 0 && b2) {
if(a[i][j + 1]) ins(sta, num);
if(a[i + 1][j]) ins(sta - bit[j] * b2 + bit[j-1] * b2, num);
}
else if(b1 && b2 == 0) {
if(a[i+1][j]) ins(sta, num);
if(a[i][j + 1]) ins(sta - bit[j-1]*b1 + bit[j] * b1, num);
}
else if(b1 == 1 && b2 == 1) {
__int128 k1 = 1;
for(int l = j + 1; l <= m; ++ l) {
if((sta >> (l * 2)) % 4 == 1) k1 ++;
if((sta >> (l * 2)) % 4 == 2) k1 --;
if(k1 == 0) {
ins(sta - bit[j] - bit[j-1] - bit[l], num);
break;
}
}
}
else if(b1 == 2 && b2 == 2) {
__int128 k1 = 1;
for(int l = j - 2; ~l; -- l) {
if((sta >> (l * 2)) % 4 == 1) k1 --;
if((sta >> (l * 2)) % 4 == 2) k1 ++;
if(k1 == 0) {
ins(sta - bit[j] * 2 - bit[j-1] * 2 + bit[l], num);
break;
}
}
}
else if(b1 == 2 && b2 == 1) ins(sta - bit[j-1]*2 - bit[j], num);
if(i == s && j == t) ans += num;
}
}
}
write(ans * 2);
return 0;
}
参考文章:
【学习笔记】动态规划—各种 DP 优化 - 晨星凌
https://www.cnblogs.com/Xing-Ling/p/11317315.html
【学习笔记】动态规划—斜率优化DP(超详细)- 晨星凌
https://www.cnblogs.com/Xing-Ling/p/11210179.html
斜率优化学习笔记 - MashiroSky
https://www.cnblogs.com/MashiroSky/p/6009685.html
动态规划之四边形不等式优化 - ybwowen
https://www.cnblogs.com/ybwowen/p/11116654.html
斯坦纳树小结 - 自为风月马前卒
https://www.cnblogs.com/zwfymqz/p/8977295.html
虚树入门 - 自为风月马前卒
https://www.cnblogs.com/zwfymqz/p/9175152.html
洛谷日报[#185]浅谈虚树 - SSerxhs
https://sserxhs.blog.luogu.org/qian-tan-xu-shu
插头dp小结 - y2823774827y
https://www.cnblogs.com/y2823774827y/p/10140757.html
省选算法学习-插头dp - dedicatus545
https://www.cnblogs.com/dedicatus545/p/8638869.html
P3190 [HNOI2007]神奇游乐园
https://www.cnblogs.com/LLTYYC/p/11456786.htm
斜率优化dp总结 - _zjz
https://www.luogu.com.cn/blog/zjz-123-qaq/xie-shuai-you-hua-dp-zong-jie
P3886 [JLOI2009]神秘的生物 - GNAQ
https://www.luogu.com.cn/blog/GNAQ/solution-p3886
浅谈"fake树"——虚树 - 模拟退火

 浙公网安备 33010602011771号
浙公网安备 33010602011771号