

数据采集与融合技术实践作业一
102102136 陈耕
作业1:
(1)作业内容
实验要求:
用requests和BeautifulSoup库方法定向爬取给定网址(此处网址为:http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | ...... | ...... | ...... | ...... |
代码内容:
# 导入
import requests
from bs4 import BeautifulSoup
import bs4
from selenium import webdriver # 导入selenium库,用于模拟浏览器操作
from selenium.webdriver.common.by import By # 导入By类,用于指定元素定位方式
def getHTMLText(url):
#发送HTTP请求,获取网页内容。
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
#解析HTML内容并将学校信息存入ulist列表。
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
a = tr('a', 'name-cn')
ulist.append([tds[0].string.strip(), a[0].string.strip(), tds[2].text.strip(), tds[4].string.strip()])
# 将学校排名、学校名称、总分分别存入ulist列表
def printUnivList(ulist, num):
#打印学校信息
print("{:^20}\t{:^20}\t{:^20}".format("排名", "学校名称", "总分")) # 打印表头
for i in range(num):
u = ulist[i]
print("{:^20}\t{:^20}\t{:^20}".format(u[0], u[1], u[3])) # 打印学校排名、学校名称、总分
def main():
uinfo = [] # 创建一个空列表存储学校信息
url = "https://www.shanghairanking.cn/rankings/bcur/2021" # 目标网页的URL
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 30) # 打印(未能翻页,实现前30个)
main()
具体实现:
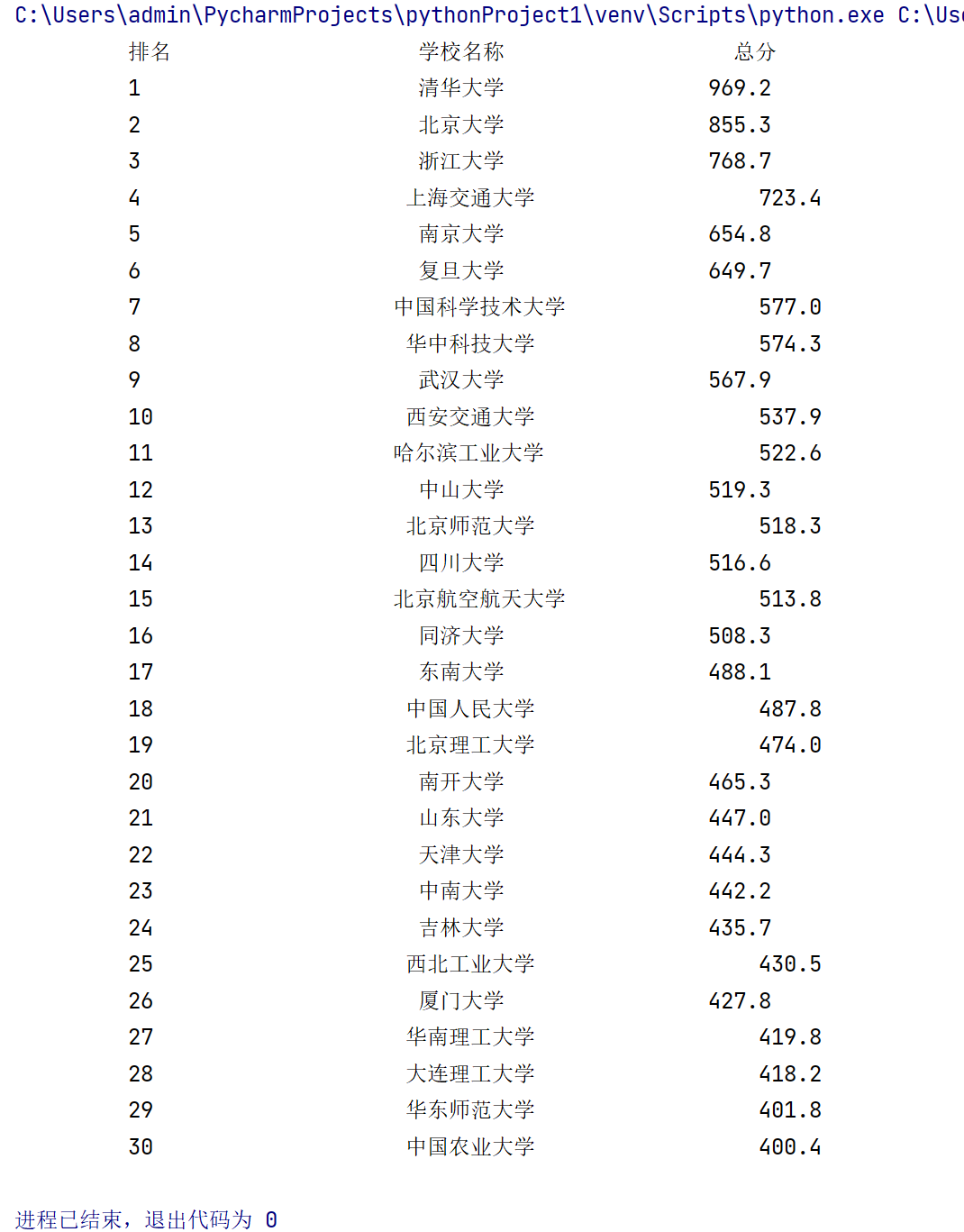
(2)心得体会:
使用urllib.request和BeautifulSoup库方法进行定向爬取,具体内容是大学排名信息TOP N、学校名称、省市、学校类型、总分,查找标签等内容较为简单。
作业2:
(1)作业内容
实验要求:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| 序号 | 价格 | 商品名 |
| 1 | 65.00 | xxx |
| 2 | ...... | ...... |
代码内容:
# 导入
import re
import time
import urllib.parse
import urllib.request
from selenium import webdriver # 导入selenium库,用于模拟浏览器操作
Lname = [] # 创建一个空列表,用于存储商品名称
Lprince = [] # 创建一个空列表,用于存储商品价格
print('正在爬取 ...')
browser.get('https://www.guangshop.com/?r=/l&kw=%25E4%25B9%25A6%25E5%258C%2585&origin_id=&sort=0')#将商城网站设置为:逛商城
time.sleep(15) # 等待页面加载完成
browser.refresh() # 刷新
ab = browser.page_source # 获取页面源代码
# 使用正则表达式匹配商品名称和价格(关键就是正则表达式的表示)
name = re.findall('<span data-v-f62188ba="">[\u4e00-\u9fa50-9a-zA-Z【】\-!]*包[\u4e00-\u9fa50-9a-zA-Z【】\-!]*</span>', ab)
prince = re.findall('<span data-v-f62188ba="" class="price">\d*\.*\d*', ab)
# 遍历匹配结果,将商品名称和价格存入对应的列表
for item in name:
item = item.replace('<span data-v-f62188ba="">', '')
item = item.replace('</span>', '')
Lname.append(item)
for item in prince:
item = item.replace('<span data-v-f62188ba="" class="price">', '')
Lprince.append(item)
# 打印商品名称和价格
for i in range(1, 61):
print(str(i) + '. ' + Lname[i] + ' ' + Lprince[i])
具体实现:

(2)心得体会:
在同学推荐下了解到了selenium库,体验到使用webdriver进行网页爬取的便捷,对定向爬虫更加了解。
淘宝网作为一个大型电商平台,为了保护自身的利益和数据安全,采取了一系列反爬机制如IP限制、验证码、用户行为分析等来防止恶意爬虫对其网站进行大量访问和数据抓取。所以再一开始并没有顺利爬取。在更换商城网站之后成功运行。
作业3:
(1)作业内容
实验要求:
要求:
爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)
或者自选网页的所有JPEG和JPG格式文件
输出信息:
将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
代码内容:
#导入
from bs4 import BeautifulSoup
import re
import urllib.request
import time
from selenium import webdriver
browser = webdriver.Edge() # 创建browser对象
#打开网站
browser.get('https://xcb.fzu.edu.cn/info/1071/4481.htm')
i = 1
time.sleep(15)# 等待页面加载完成
html = browser.page_source# 获取页面源代码
soup = BeautifulSoup(html, "lxml") # 解析HTML
list = []# 创建一个空列表list,用于存储图片链接
lis = soup.select("img")# 使用CSS选择器获取所有img标签
x = 1
for ls in lis:
image_name = "C:/Users/admin/PycharmProjects/pythonProject1/爬虫/实践/" + str(x) + ".jpg"# 图片保存路径
x = x +1
image_url = "https://xcb.fzu.edu.cn" + str(ls["src"])# 图片链接
print(image_url)
try:
urllib.request.urlretrieve(image_url, filename=image_name) # 下载图片并保存到本地
except urllib.error.URLError as error:
print(error)
具体实现:
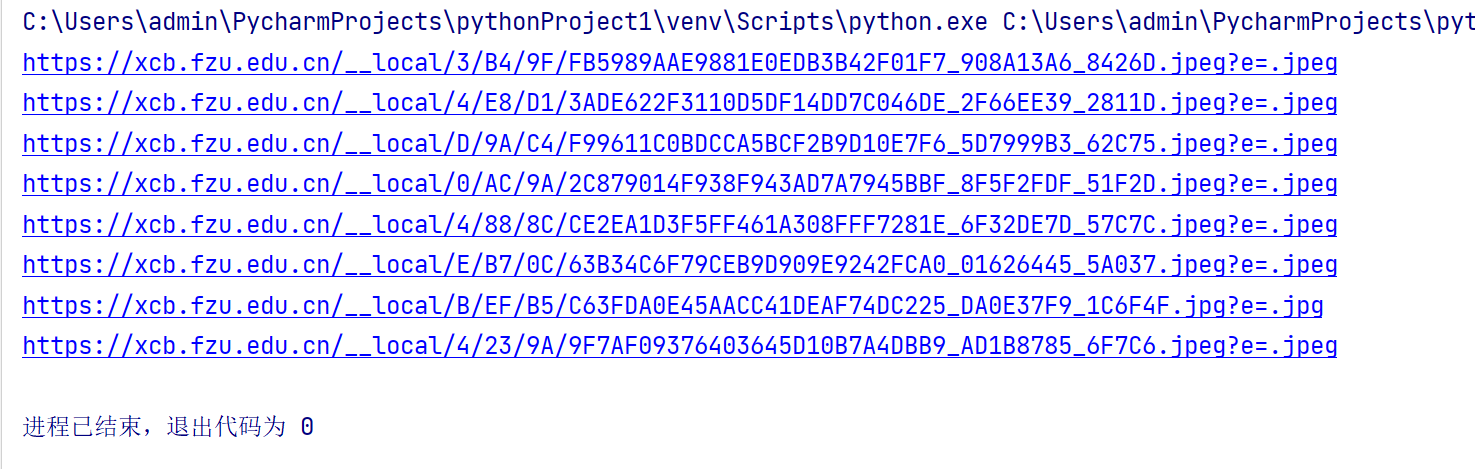
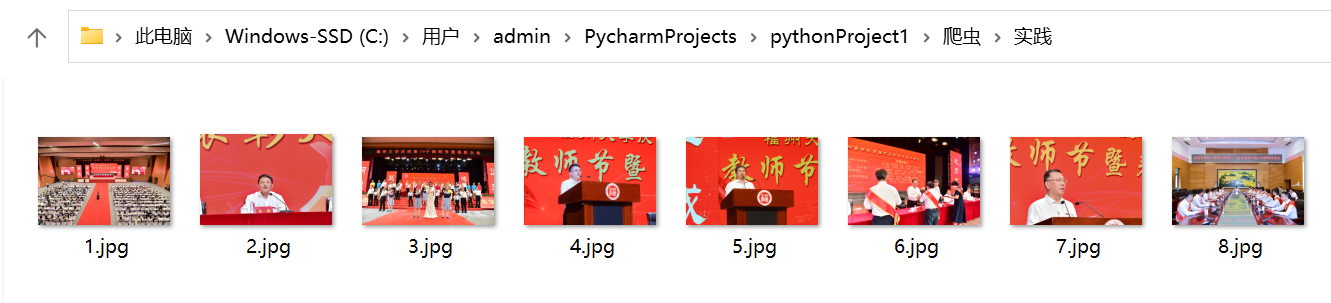
(2)心得体会:
1.图片下载的过程是较为缓慢的,可能是因为校园内网;
2.学会了使用webdriver来爬取动态网页;
3.在正则表达式的表达中初次表达不成功,完成后也有了更深的印象。
