

[数据结构1.3-线性表] 链表与 LinkedList<T>(.NET 源码学习)
[数据结构1.3-线性表] 链表与 LinkedList<T>
【注:本篇文章源码内容较少,分析度较浅,请酌情选择阅读】
关键词:链表(数据结构) C#中的链表(源码) 可空类型与特性(底层原理 源码) 迭代器的实现(底层原理) 接口IEqualityCompare<T>(源码) 相等判断(底层原理)
链表,一种元素彼此之间具有相关性的数据结构,主要可分为三大类:单向链表、双向链表、循环链表。其由“链”和“表”组成,“链”指当前元素到其他元素之间的路径(指针);“表”指当前单元存储的内容(数据)。本文主要对 C# 中 LinkedList 的源码进行简要分析。
【# 请先阅读注意事项】
【注:
(1) 文章篇幅较长,可直接转跳至想阅读的部分。
(2) 以下提到的复杂度仅为算法本身,不计入算法之外的部分(如,待排序数组的空间占用)且时间复杂度为平均时间复杂度。
(3) 除特殊标识外,测试环境与代码均为 .NET 6/C# 10。
(4) 默认情况下,所有解释与用例的目标数据均为升序。
(5) 默认情况下,图片与文字的关系:图片下方,是该幅图片的解释。
(6) 文末“ [ # … ] ”的部分仅作补充说明,非主题(算法)内容,该部分属于 .NET 底层运行逻辑,有兴趣可自行参阅。
(7) 本文内容基本为本人理解所得,可能存在较多错误,欢迎指出并提出意见,谢谢。】
一、链表概述及常见类型
【注:该部分在网络上已有很多资料,故不作为重点】
数组作为一个最初的顺序储存方式的数据结构,其可通过索引访问的灵活性,使用为我们 的程序设计带来了大量的便利。但是,数组最大的缺点就是:为了保证在存储空间上的连续性,在插入和删除时需要移动大量的元素,造成大量的消耗时间,以及高冗余度。为了避免这样的问题,因此引入了另一种数据结构链表。
链表通过不连续的储存方式、动态内存大小,以及灵活的指针使用(此处的指针是广义上的指针,不仅仅只代表 C/C++ 中的指针,还包括一些标记等),巧妙的简化了上述的缺点。其基本思维是,利用结构体或类的设置,额外开辟出一份内存空间去作“表”本身,其内部包含本身的值,以及指向下一个结点的指针,一个个结点通过指针相互串联,就形成了链表。但优化了插入与删除的额外时间消耗,随之而来的缺点就是:链表不支持索引访问。
(一) 单向链表
以下仅简单写一下基本构成和方法。

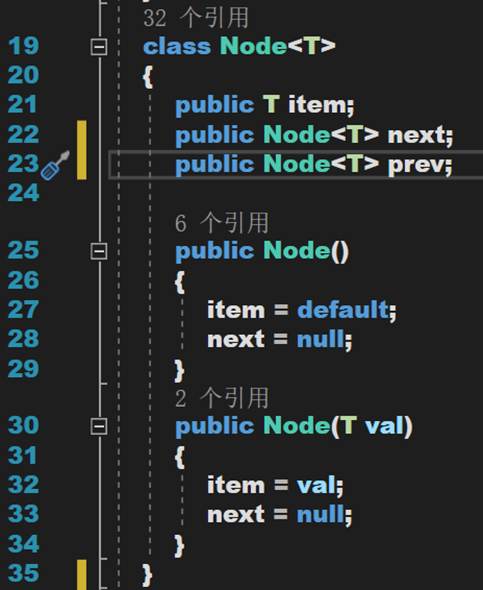
首先定义“表”,即每个结点。其包含自身数据与指向下一个表的指针。其中一个默认构造方法,一个带参构造方法用于两种不同形式的初始化。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
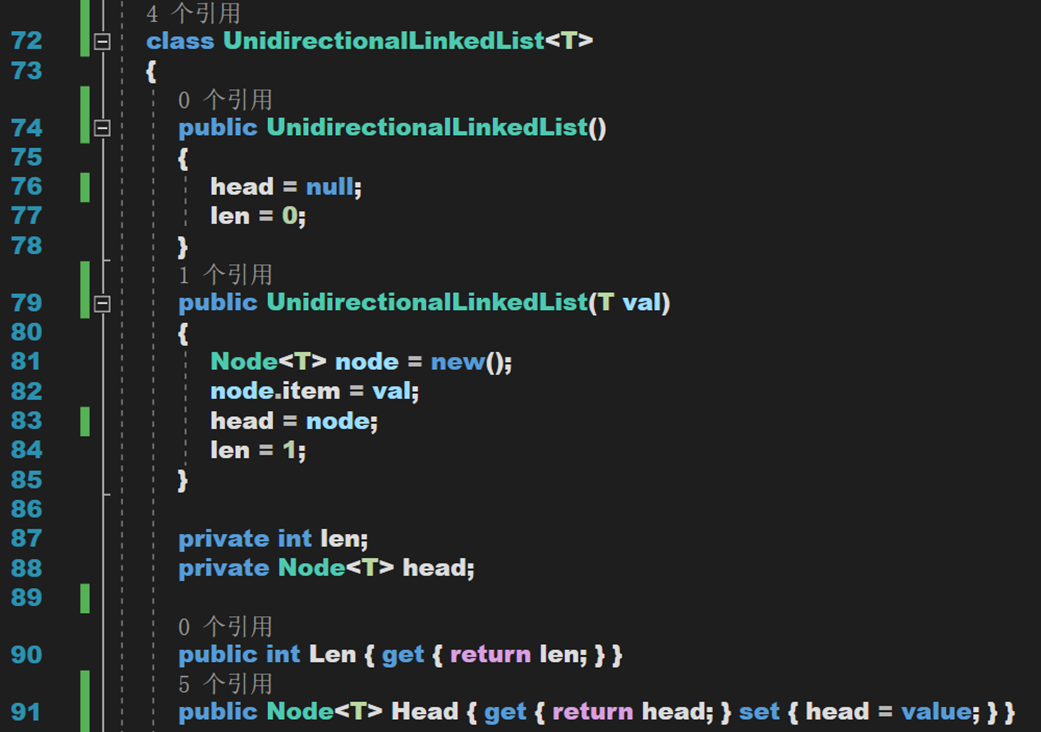
再定义一下“链“
- Line 74~85:构造方法,默认方法初始化头结点为空;链表长度为零;带参方法用处初始化单个结点。
- Line 87~88:定义私有字段,包括链表长度、头节点。
- Line 90~91:公共属性,用于外部访问私有字段。通过公共属性访问私有字段,符合面向对象的设计原则,体现了对字段的封装,增强了代码在运行时的安全性。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
接下来定义常用方法
1. 首尾添加
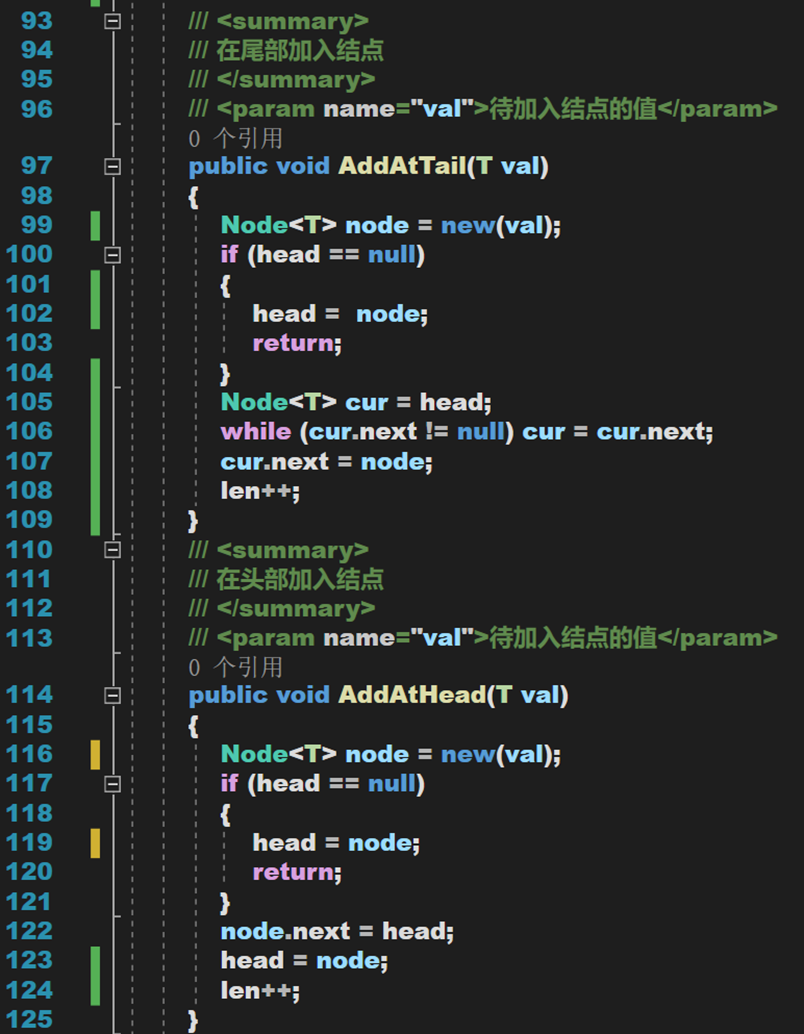
2. 插入

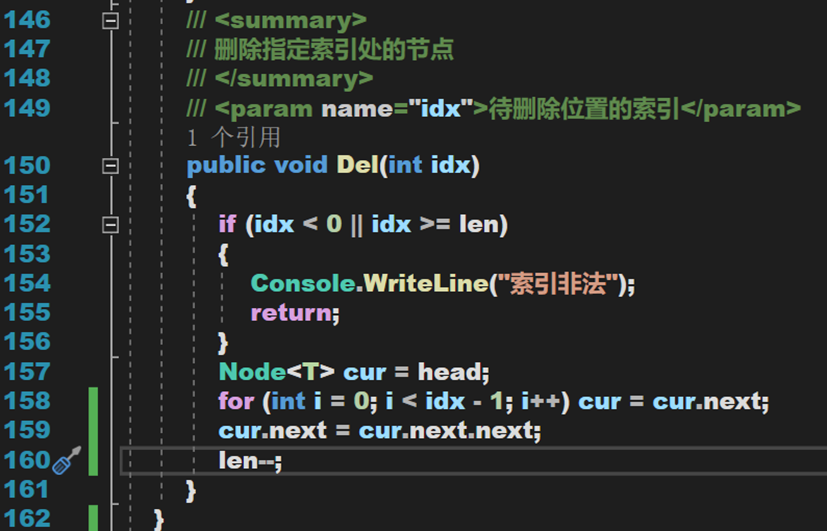
- Line 140:关于这个循环条件,循环到 idx – 1 ,使 cur 停在执行位置的前一个位置。若停在操作位置,则无法设定前一个结点的 next 属性。
3. 删除
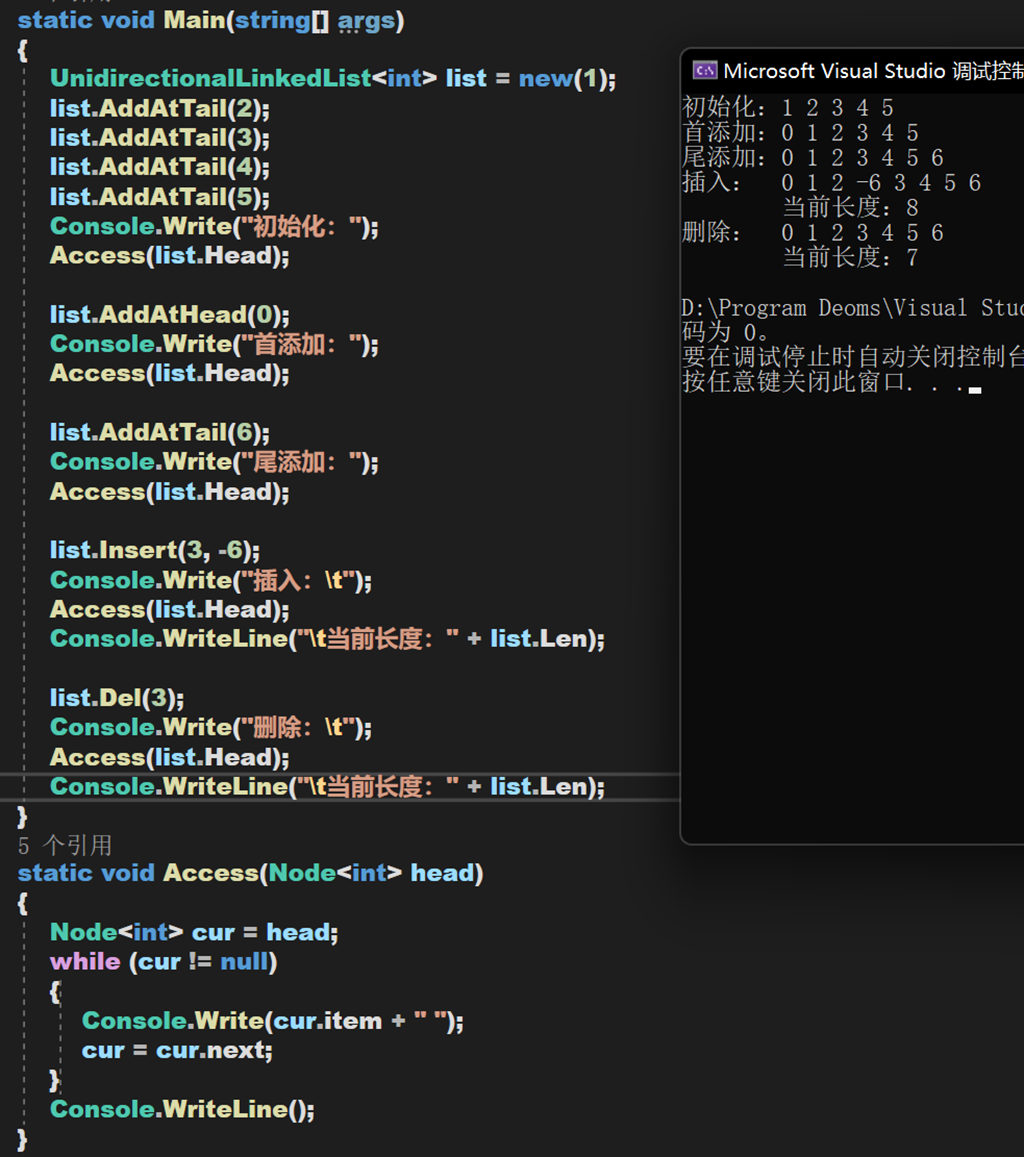
实现效果
(二) 双向链表
双向链表在单向的基础上增加了指向前的指针
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
“链“的构造方法及相关字段和属性不变,只是在方法的实现时,需要增加对 prev 的赋值
1. 首尾添加
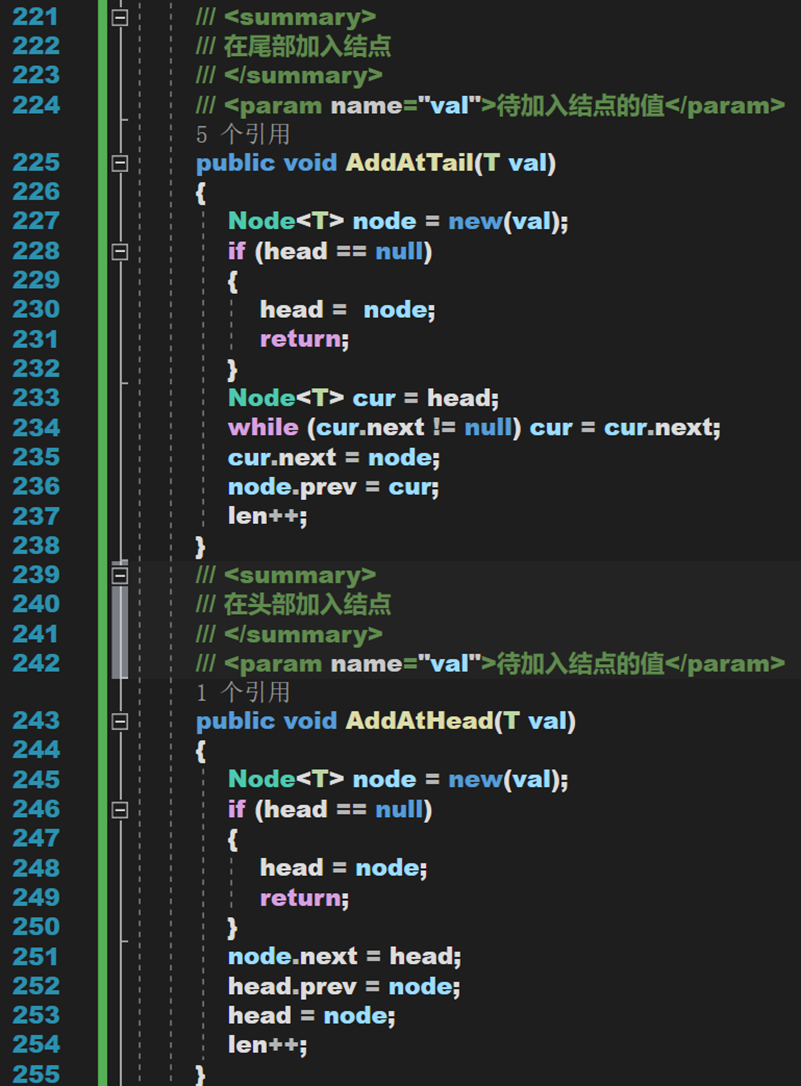
- Line 168、185:注意,应当先对原 head 的 prev 指针赋值,再修改 head 的指向。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
2. 插入

一般地,先修改新结点的信息,再修改原结点的信息。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
3. 删除
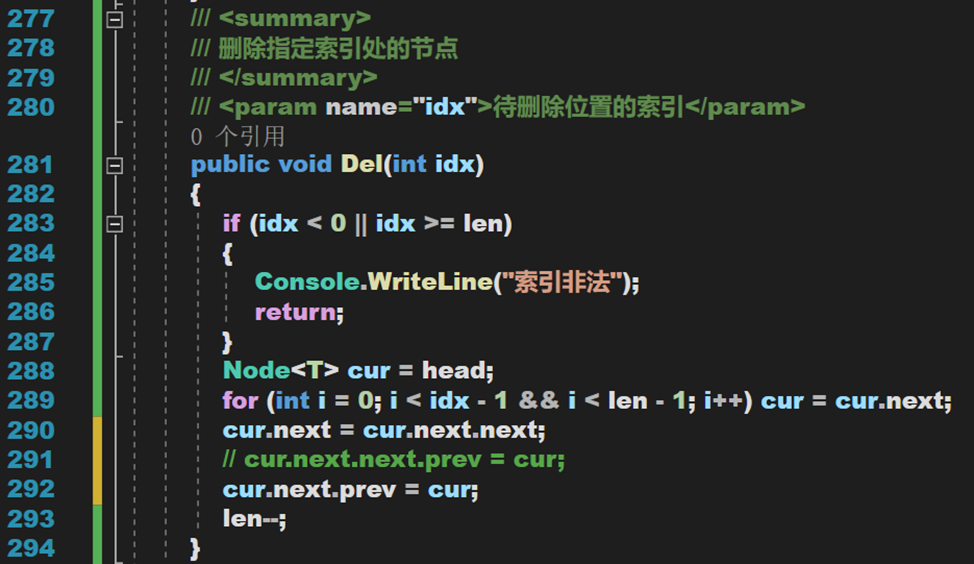
- Line 292:此处已经更新了 cur.next 的指向,所以并不是 Line 291 的语句。
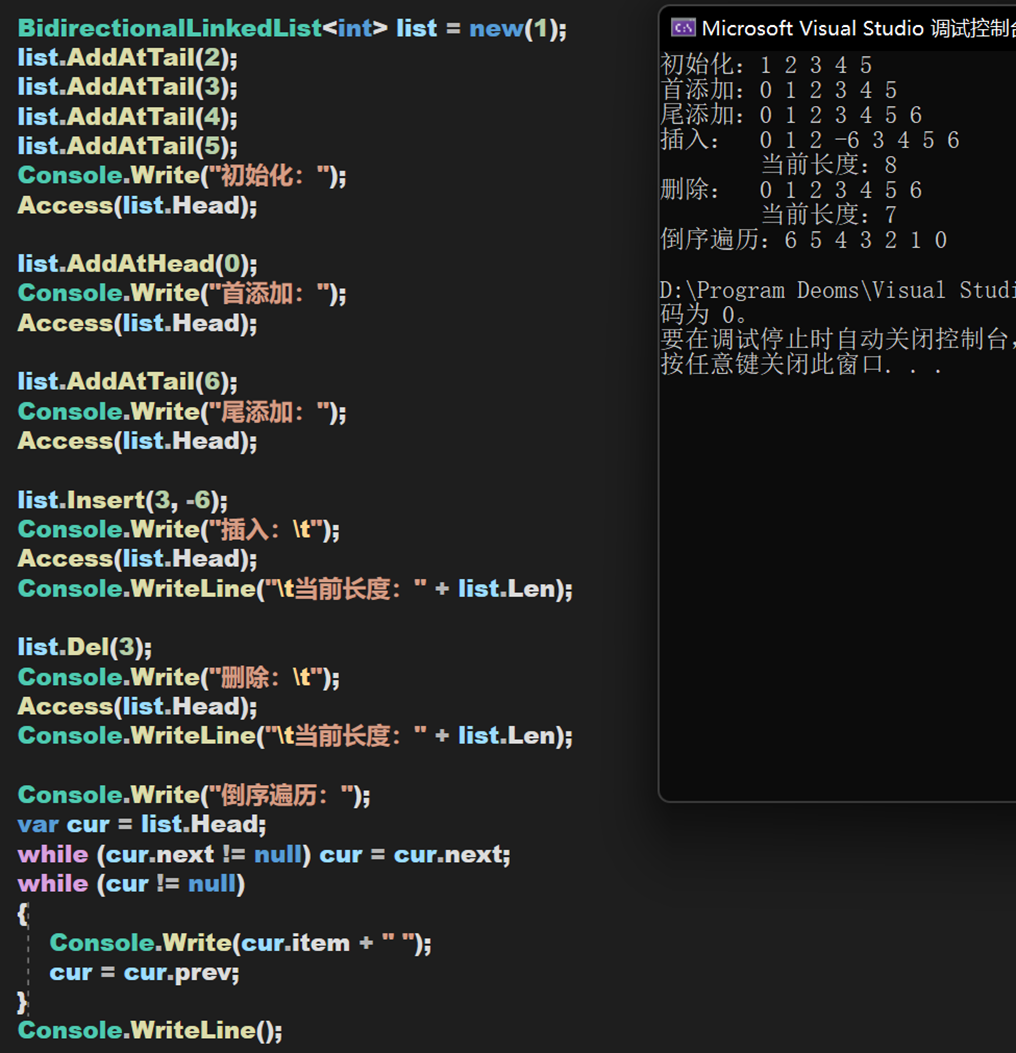
实现效果
(三) 循环链表
循环,就是把尾部结点的 next 指针继续指向下,指向 head。大同小异,本节内容在此不作演示,详细请参阅:(理论基础 —— 线性表 —— 循环链表 - 老程序员111 - 博客园 (cnblogs.com))
总结一
1. 对比一下数组、集合与链表
(1) 对于数组:
- 长度固定,初始化后长度不可变。
- 在内存中的存储单元是连续分配的。
- 可存储基本数据类型、引用数据类型。
- 每个数组只能存储类型相同的元素。
- 可通过下标与迭代器访问。
(2) 对于集合:
- 长度(容量)可变,一般初始容量为 4,满后在现有容量基础上 *2 作为新的容量。
- 在内存中的存储单元是随机分配的,可能连续也可能分散。
- 可存储基本数据类型、引用数据类型。
- 对于同一个 ArrayList 可以存储不同类型的数据;对于泛型集合,每个只能存储类型相同的数据。
- 可通过下标与迭代器访问。
(3) 对于链表:
- 长度可变,随结点数量变化而变化。
- 在内存中的存储单元是随机分配的,可能连续也可能分散。
- 结点可存储基本数据类型、引用数据类型。
- 每个链表只能存储类型相同的元素。
- 不可通过下标或迭代器访问,只能遍历访问。
2. 三者的优缺点
(1) 数组:
- 优点:可在 O( 1 ) 时间复杂度内完成查找。
- 缺点:不能扩容;对于元素的插入与删除需 O( n ) 才能完成。其中,插入的这个动作为 O( 1 ),移动元素的动作为 O( n )。
(2) 集合:
- 优点:长度可变;内存易分配;可在O( 1 )内完成查找。(一般地,集合底层结构为数组或链表)
- 缺点:因为底层与数组、链表相同,因此对于插入与删除较慢。
(3) 链表:
- 优点:可以任意加减元素,在添加或者删除元素时只需要改变前后两个元素结点的指针域指向地址即可,所以添加、删除很快, O( 1 );
- 缺点:因为含有大量的指针域,占用空间较大;不支持下标与迭代器访问,因此查找元素需要遍历,非常耗时。
二、C# 中的链表 LinkedList<T>
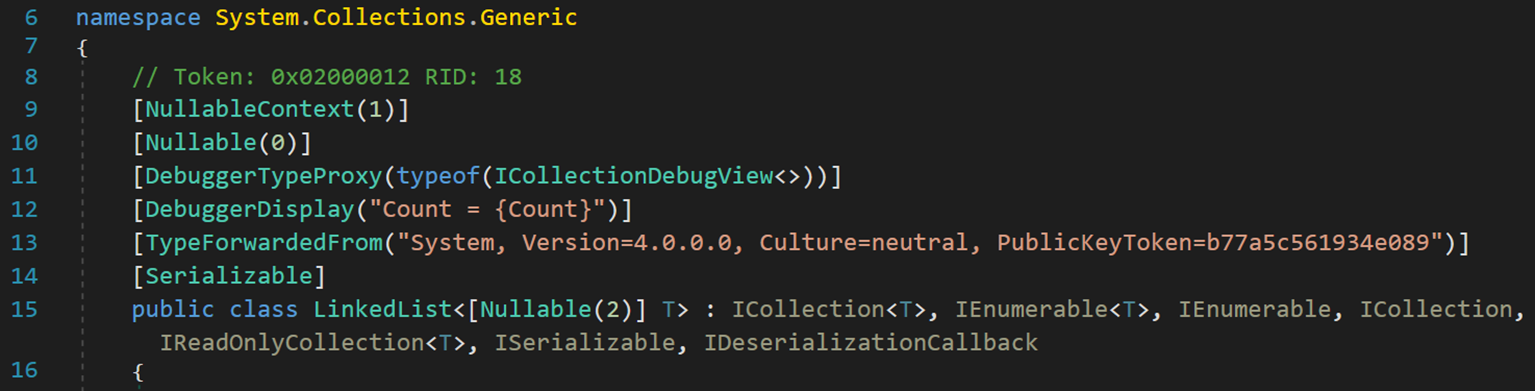
C# 中的LinkedList 为双向链表(双重链接链表),位于程序集 System.Collections.dll中的命名空间 System.Collections.Generic 之下。
简单解释一下其拥有的特性:【注:特性基本介绍请参阅本人的文章([算法2-数组与字符串的查找与匹配] (.NET源码学习) - PaperHammer - 博客园 (cnblogs.com))】
- Line 9:NullableContext() 表示可空的上下文。括号中的值对应的功能如下图:

这里解释一下“上下文”:
上下文并不是一个具体的东西,就和阅读小说一样,需要结合前后进行理解。
在计组中也出现过上下文的概念,CPU 在用户态与内核态相互切换时,需要保留当前任务的上下文信息,并挂起该任务,直到优先级更高的任务结束后,再根据上下文信息,继续原任务。这里的上下文信息相当于对某个进程当前的状态描述。
根据这样的方式,那么此处对于LinkedList 的该特性可以解释为对其当前状态描述的可空性。
- Line 10:Nullable() 表示存储的元素是否可空。其中,0表示可空可不空;1 表示不为空;2表示可为空。
【注:有关特性 Nullable 的详细介绍会在文末进行补充说明】
- Line 11:DebuggerTypeProxy() 用于指定代理类型的显示。其会对被修饰的对象指定某个类型的代理或替身,并更改类型在调试器窗口中的显示方式。查看具有代理的变量时,代理将代替“显示”中的原始类型。 调试器变量窗口仅显示代理类型的公共成员。不会显示私有成员。这里的 typeof(ICollectionDebugView<>) 就是 LinkedList 的代理类型。
说人话就是,在调试过程中,若要查看变量内部的元素,则会显示代理类型的相关成员,不会显示原本类型的相关成员。其主要作用是,在调试时得到最希望最关心的信息。
【更多有关该特性的内容会在今后专门发文详解】
- Line 12:DebuggerDisplay() 可以帮助我们直接在局部变量窗格或者鼠标划过的时候就看到对象中我们最希望了解的信息。
- Line 13:TypeForwardedFrom() 获取被修饰对象的来源。
- Line 14:Serializable 可序列化标志。
解释一下“序列化”:
有时为了使用介质转移对象,并且把对象的状态保持下来,就需要把对象所有信息保存下来,这个过程就叫做序列化。通俗点,就是把人的魂(对象)收伏成一个石子(可传输的介质)。各种序列化类各自有各自的做法,这些序列化类只是读取这个标签,之后就按照自己的方式去序列化。
【注:下一篇会对序列化与反序列化进行补充说明】
(一) 三个构造方法
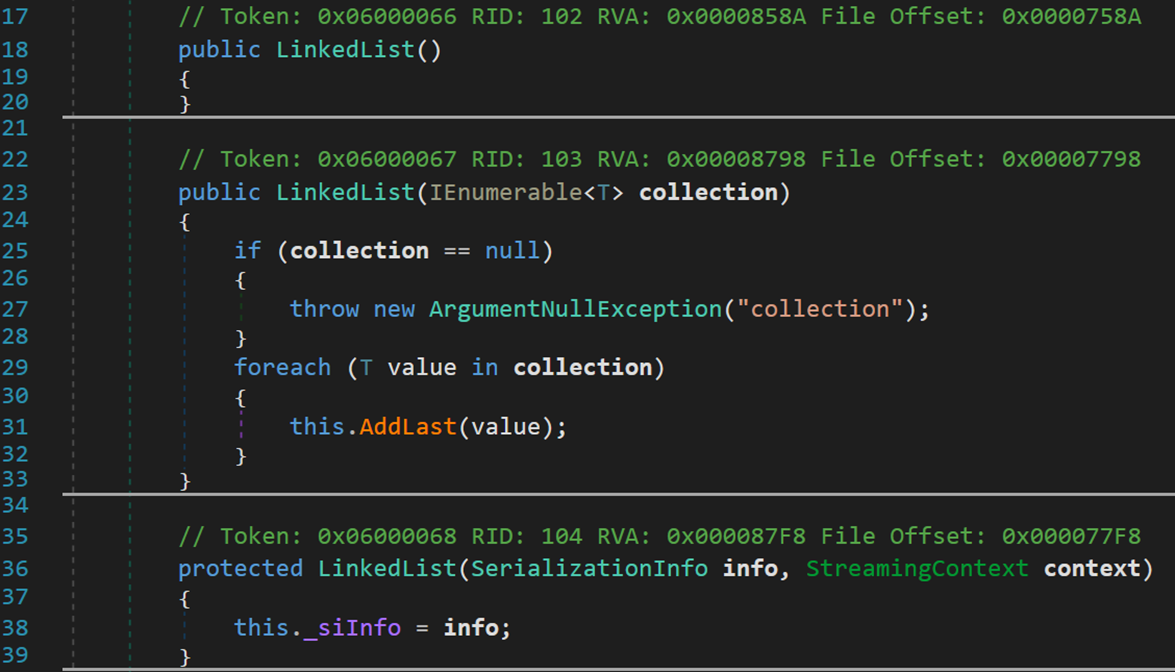
- Line 18:无参默认构造函数。
- Line 23:以非空集合进行初始化的构造函数,利用范型临时变量迭代器,自动以集合中的元素生成链表。
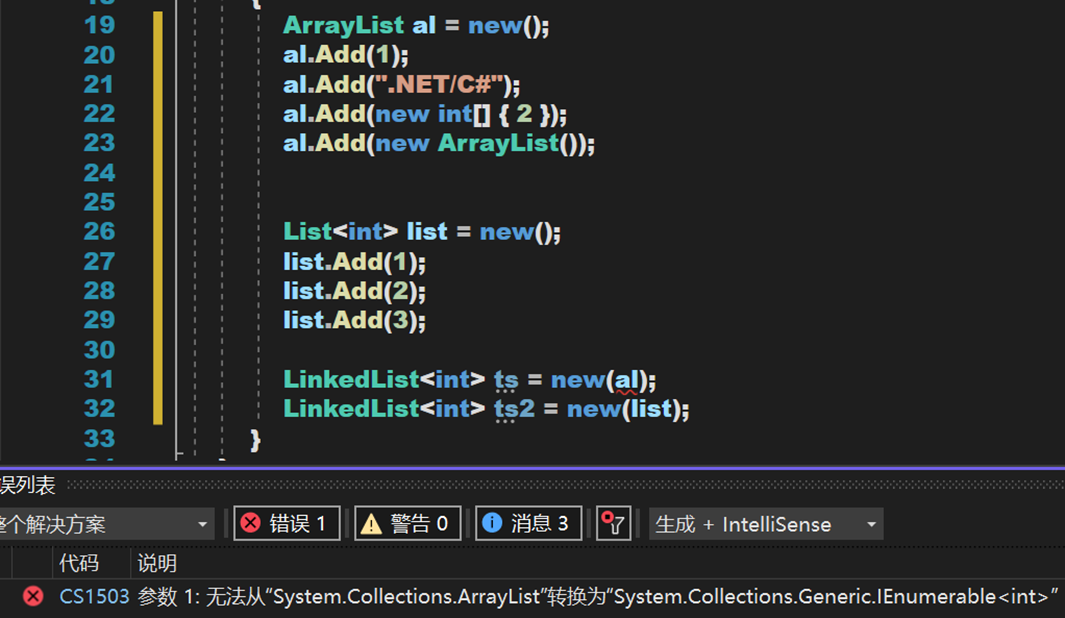
![]()
注意,由于 ArrayList 内部存储的元素并不是同一个类型,因此其并未继承泛型接口 IEnumerable<T>,其只继承了普通接口 IEnumerable,因此不能将其通过构造函数直接转化为链表。
- Line 36:传入了一个对象进行序列化或反序列化所需的全部数据,将这些数据赋值给字段 _siInfo。contest 表示该对象的数据流的信息,作用是说明给定序列化流的源和目标,并提供另一个调用方定义的上下文。
(二) 六个属性
1. Count
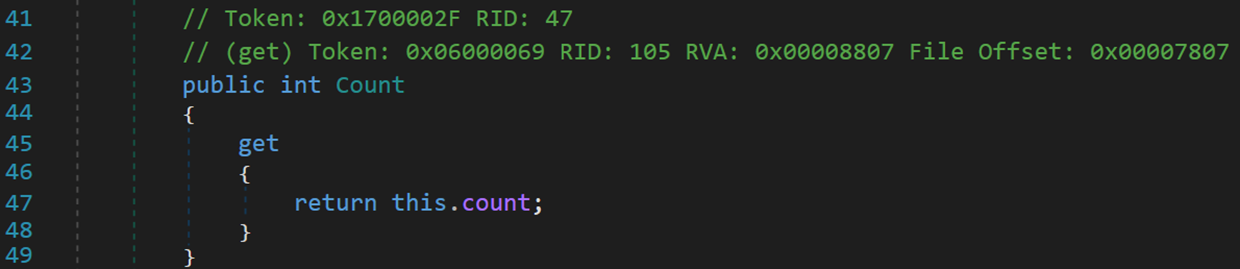
只读属性,返回链表长度。
2. First
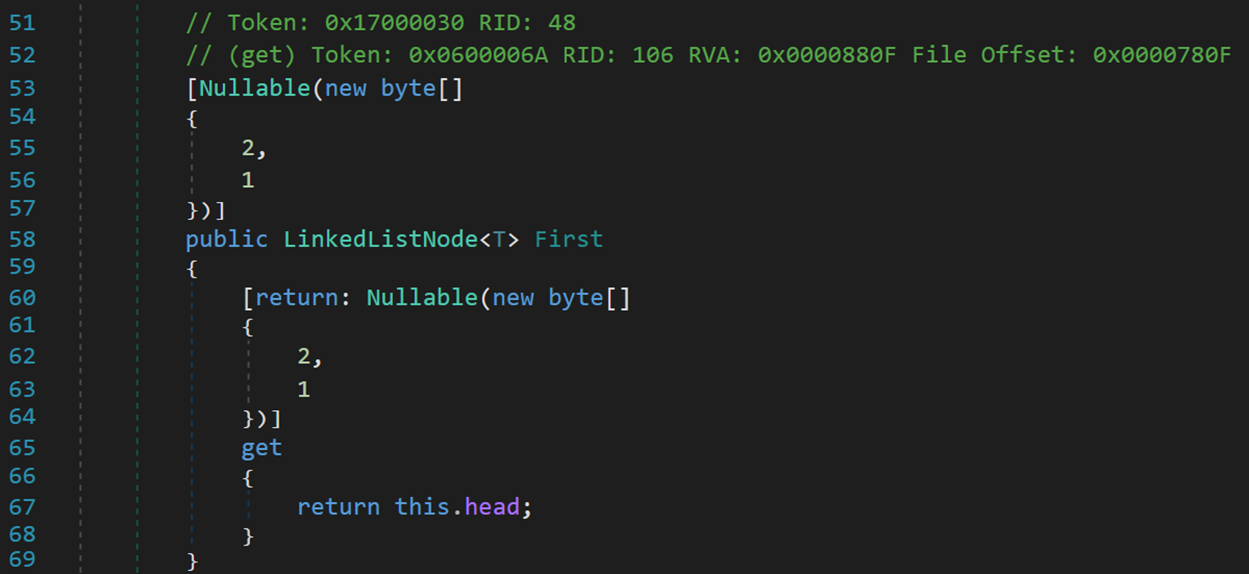
只读属性,返回链表头结点,若不存在则根据特性 Nullable 返回空。每个数字对应修饰的对象,此处 2表示可为空,对应 Linkedlist;1表示不能为空,对应 <T>。
一般地,被 Nullable 修饰的变量可以为空。以 Nullable 作为特性,可以修饰方法、属性等,拓宽了数据可为空的范围。
3. Last

只读属性,返回链表尾结点。因为LinkedList 默认是双向链表,因此 tail == head.prev。
4. IsReadOnly、IsSynchronized与SyncRoot
注:这三个属性为非公共属性,只限于类自己内部调用。
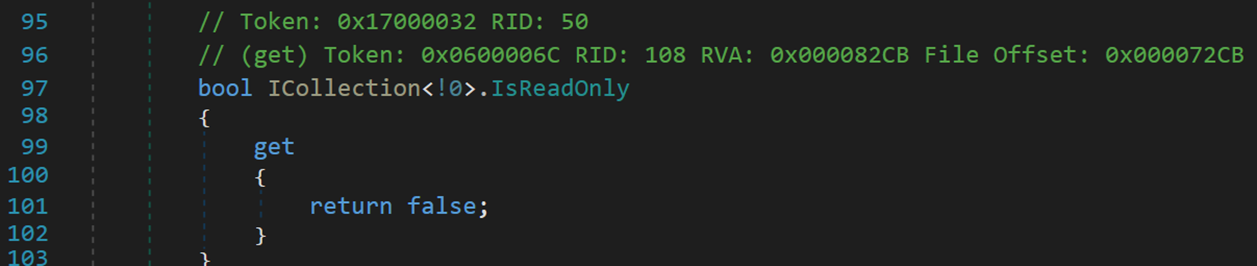

只读属性,分别表示 LinkedList 的非只读、对堆栈的访问不同步 (线程安全)、获取可用于同步对 ICollection 的访问的对象。其中,符号<!0>可能表示非 NULL
这三个属性在此处似乎只有定义,并没有在其他地方调用,推测其作用是作为该对象的一种标识属性,在进行某些操作时,供 CLR 检测访问是否允许执行该操作。
【注:碍于篇幅,后两个属性将在之后的文章进行补充说明】
(三) 五个字段
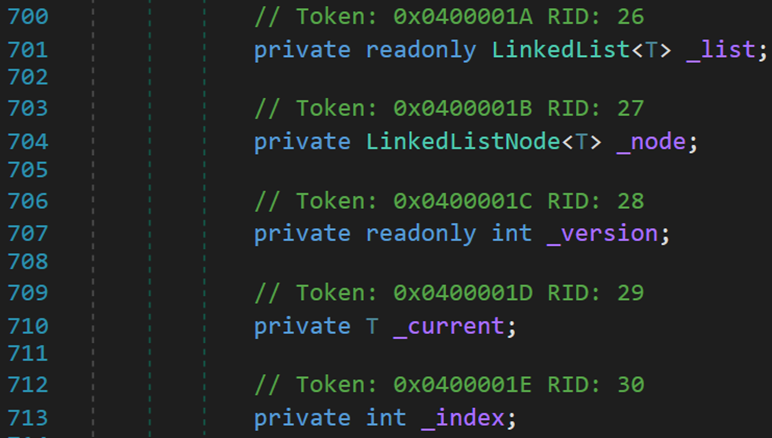
- Line 701:_list 表示当前的链表对象,仅用于内部访问。
- Line 704:_node 表示链表中的每个结点。其内部包含:结点所在的链表、该结点的下一个结点与上一个结点、当前结点存储的值。
- Line 707:_version 执行修改操作的次数。
- Line 710:_current 用于在枚举器中,记录当前所在的结点。
- Line 713:_index 用于在枚举器中,记录当前结点所对应的索引值。
(四) 一个结构 -> 迭代器 or 枚举器
1. 结构体的构造方法

初始化内部字段,为之后的迭代器遍历与结点做准备。
2. 两个属性

- Line 625:Current属性,返回当前所指向的结点。
- Line 637:IEnumerator.Current属性,迭代过访问程中,若存在还未访问到的元素,则返回当前迭代器所指向的对象。
3. MoveNext()方法
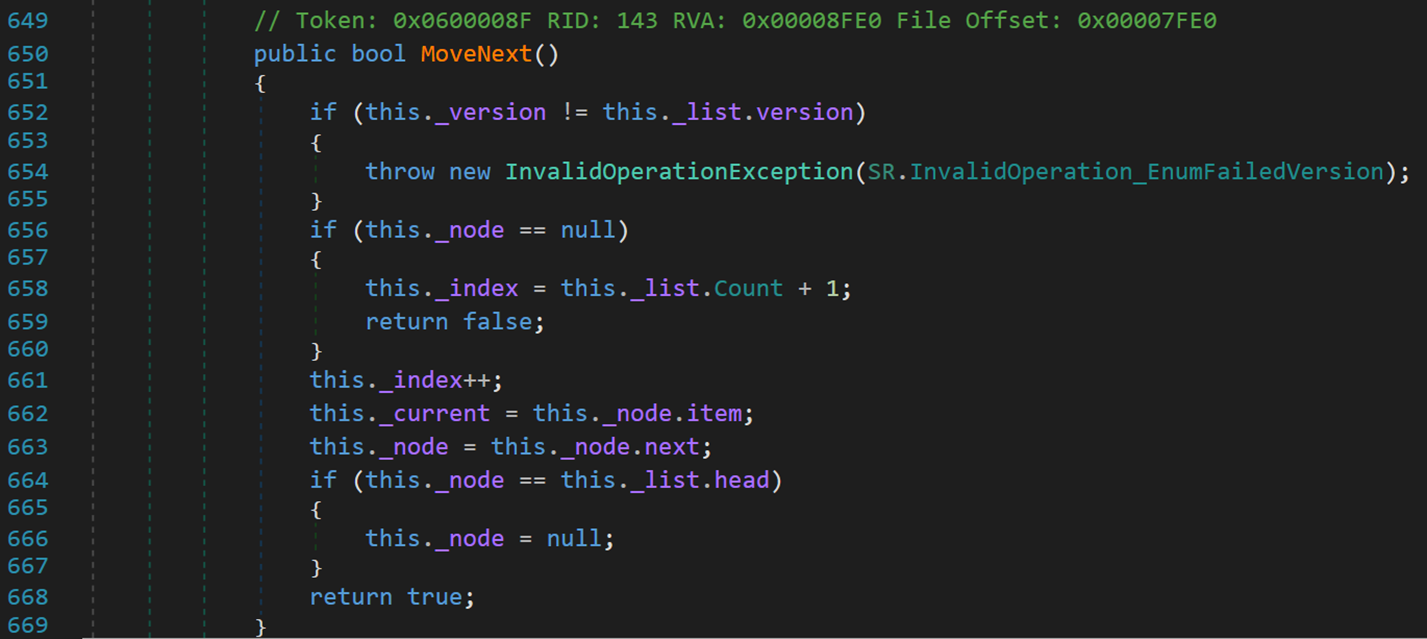
将指向当前结点对象的引用,向后移动到下一个结点。配合迭代器访问,逐一向后遍历元素。
- Line 652:若两个 version 不相同,无法执行操作。在文章([数据结构1.2-线性表] 动态数组ArrayList(.NET源码学习) - PaperHammer - 博客园 (cnblogs.com))中,简要分析了 version 在ArrayList 中的作用,在执行某些操作后,会使版本号+1。主要是一些会修改集合内部元素的操作。因此 version 可以是做是一个集合的标识符。
在枚举器的构造方法里,已将 _list.version 赋值给 version,理论上每次进行枚举迭代均会更新 version。因此该判断语句的目的可能是防止经过浅层拷贝的两个集合,在职u型某些操作后,调用另一个不属于自身的迭代器。
【有关浅层拷贝请参阅([数据结构1.1-线性表] 数组 (.NET源码学习) - PaperHammer - 博客园 (cnblogs.com))】
- Line 656:若 node 为 null,说明没有元素可以继续向下访问,则返回 false。
- Line 661~663:index 指针向后移动;_current 记录当前结点;访问下一个结点。
- Line 664:若再次访问到头结点,则终止。
4. Reset()方法
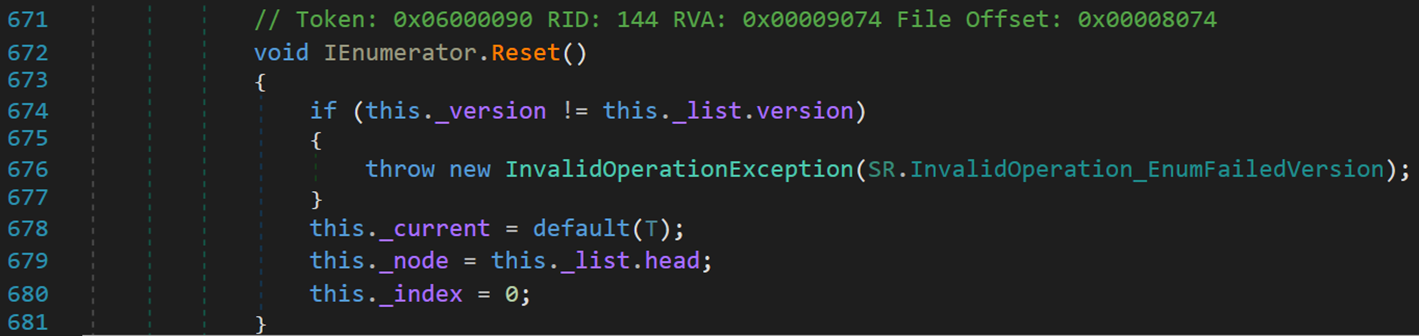
在每次调用完枚举器后,需要恢复原有的信息,以便下一次继续调用。可以理解为回溯。
【注:有关迭代器的实现原理,会在文末进行补充说明】
(五) 常用方法
1. 添加 AddFirst()、AddLast() 与 AddBefore()、AddAtfer()
首先是方法 AddFirst()。其有两个重载方法,不同之处体现在返回值类型与参数。
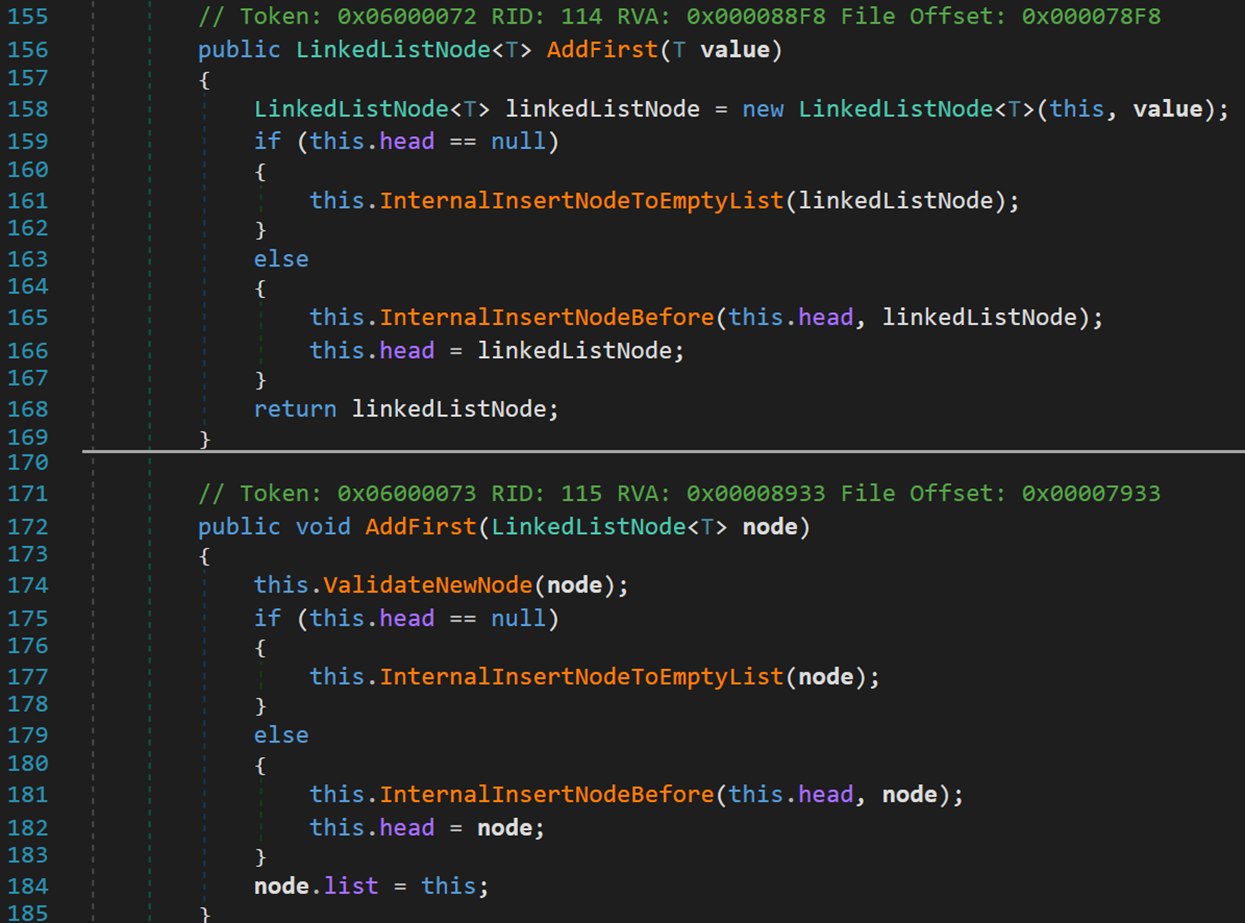
- Line 156:返回类型为某一结点,参数为某一值。
- Line 161:若头结点为空,说明当前链表内没有结点,则调用方法InternalInsertNodeToEmptyList()。
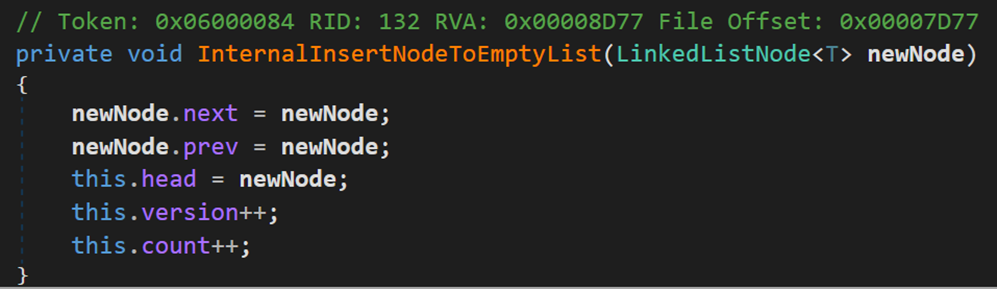
该方法的作用是:在空表中创建一个结点,其既是头结点,也是尾结点。
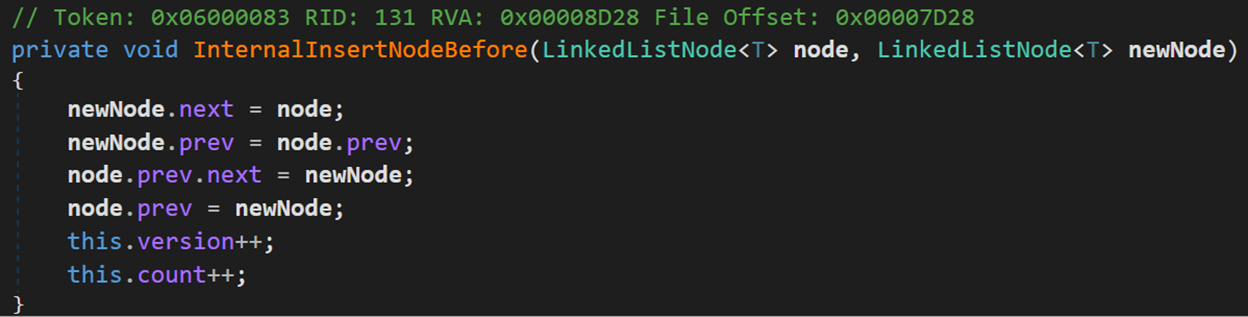
- Line 165:若头结点不为空,说明此时表中已经存在节点,则调用方法InternalInsertNodeBefore(),将新结点加入到当前头结点之前,成为新的头结点。
- Line 168、184:最终的返回结果/指向是头结点。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
方法 AddLast() 与 AddFirst() 大同小异,在此不做过多分析
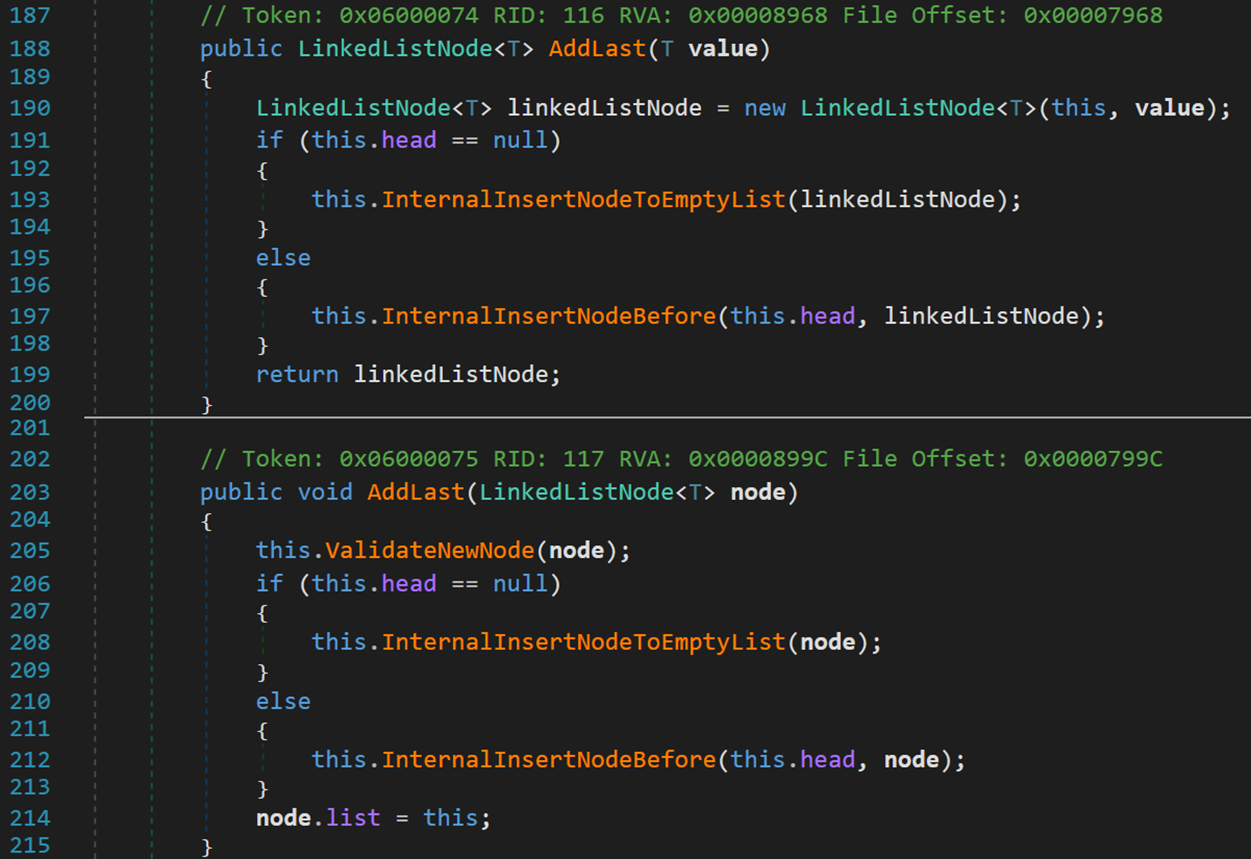
- Line 199、214:执行完毕后,返回/指向的结点是尾结点。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
接下来是方法 AddBefore(),其和前两个方法一样,均有两个重载方法,主要是返回类型与参数不同。
(1) 对于无返回值、待添加元素为链表(结点)的方法

- Line 121:node 为目标结点,在其之后进行添加;newNode 为新结点。
- Line 123、124:方法 ValidateNode() 与 ValidateNewNode() 用于判断 node 的合法性

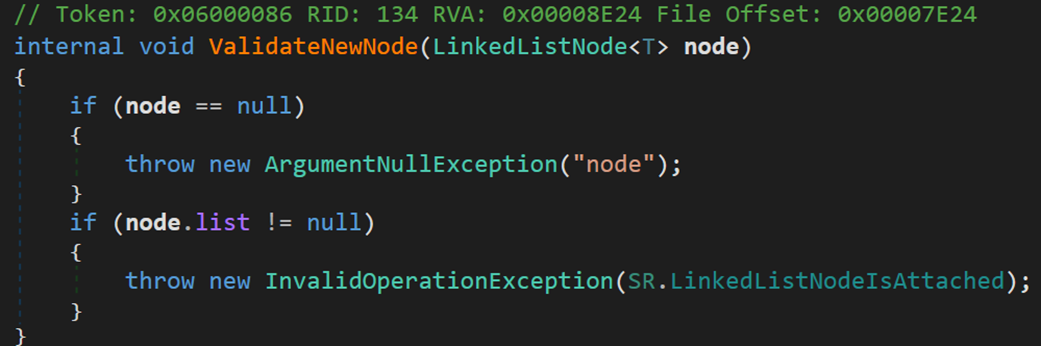
是否为空;是否为该链表的成员(目的可能是防止多线程同步访问出现的错误调用)
- Line 125:方法 InternalInsertNodeBefore() 实现添加操作。
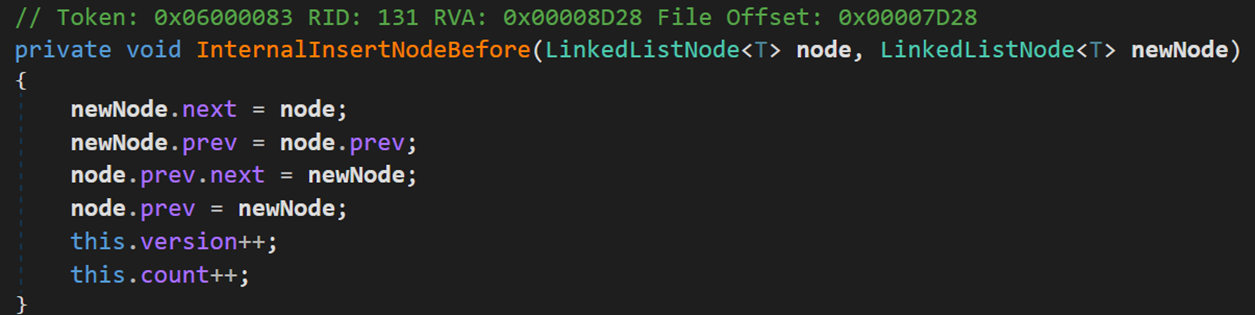
就是普通的双向链表的插入。
(2) 对于返回类型为 LinkedList<T>,添加元素为某个值的方法
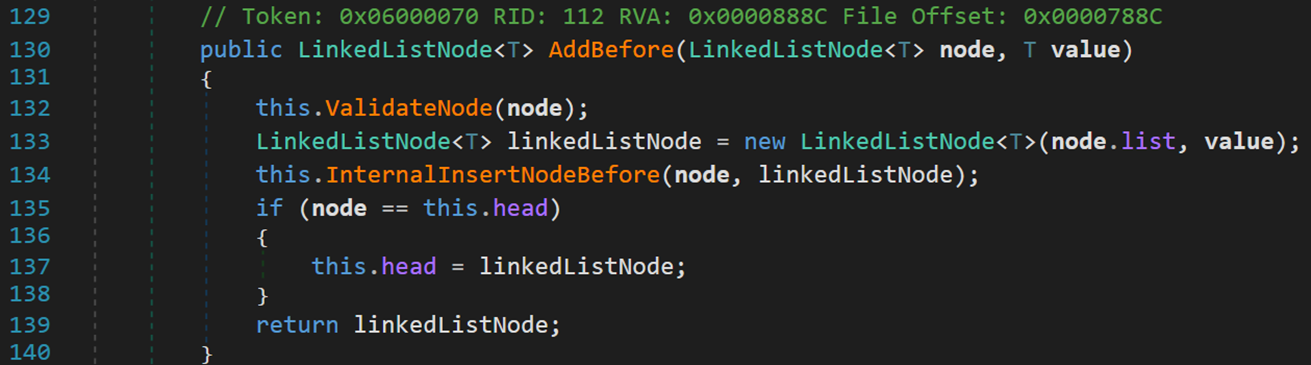
- Line 132~134:判断 node 合法性;初始化一个以 node 为首,node 值为 value的新链表;将新链表连接到 node 之前。
- Line 137:当 node 为头结点时,添加后需要更新头结点。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
方法 AddAfter() 大同小异,不做过多分析
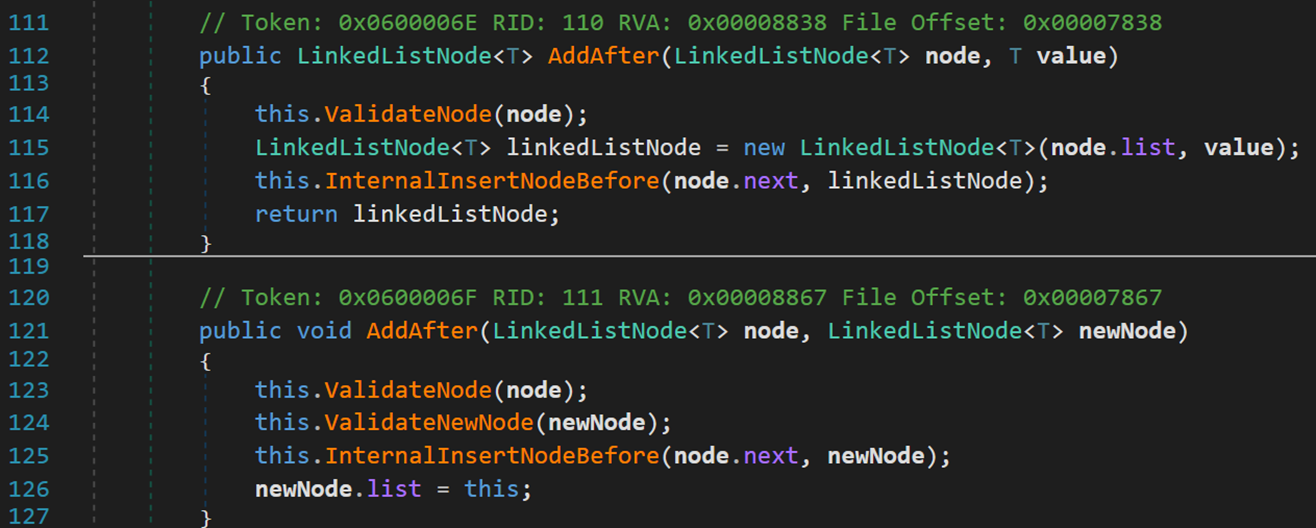
2. 包含 Contains() [ Find() 方法]

方法套方法,Find 可以用来查找元素,其在其他的方法(如:Remove())中也可以使用,为了减少冗余,因此此处直接复用了方法 Find() 来实现。
复用的思想在竞赛、开发中十分常用,既能有效减少工程量,还能提高代码可读性。
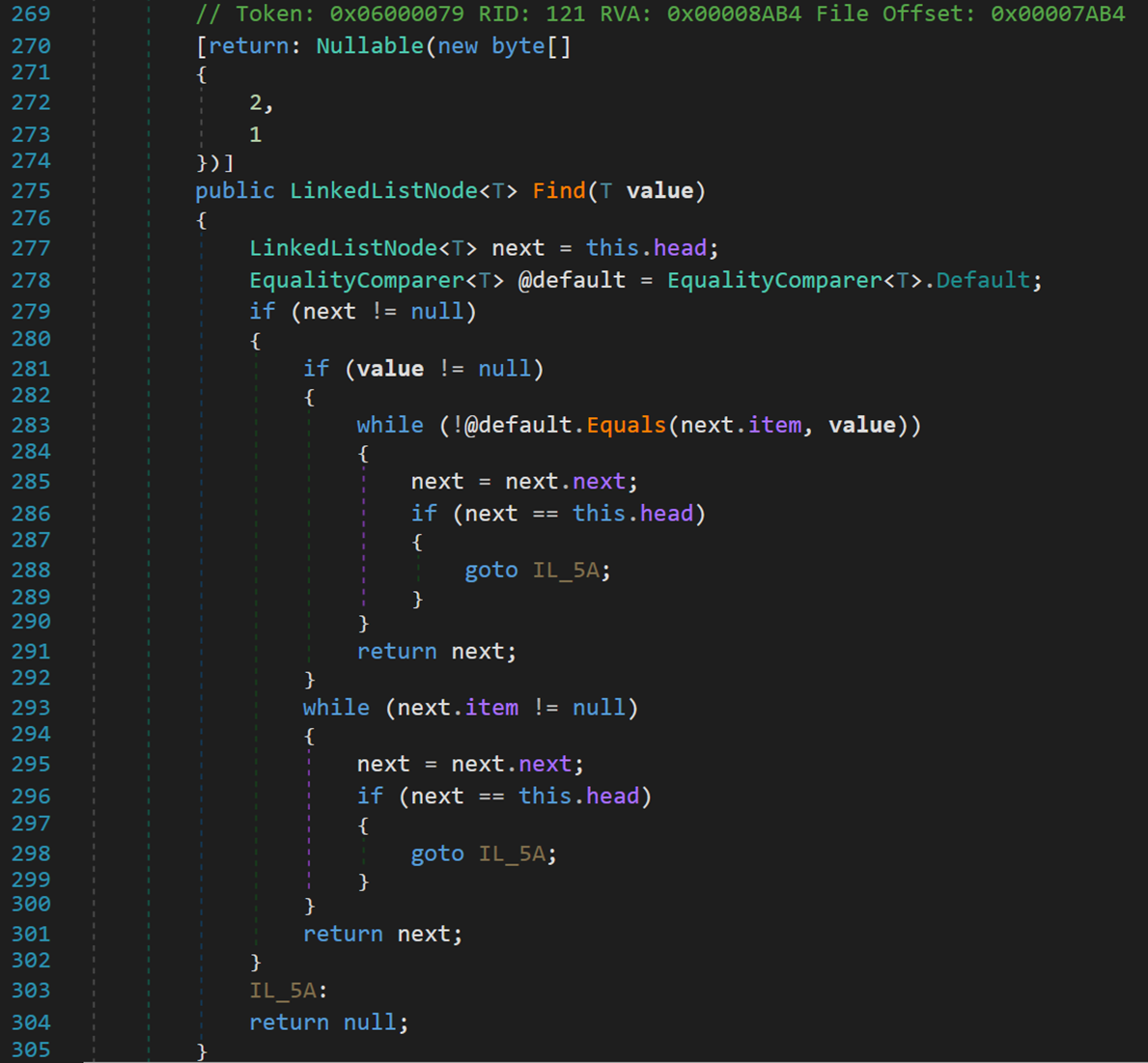
- Line 270:Nullable 特性,其中 LinkedList 可为空;<T> 不可为空。
- Line 277:next 表示当前即将访问的元素,从 head 开始。
- Line 278:定义了一个默认比较方式的变量,用于之后调用比较方法。EqualityCompare<T> 类型,一个抽象类,内部提供了一个 Equals() 方法,进行对象间的比较。
【思考:为什么需要定义该类型的变量,调用该类中的比较方法,而不直接用判断运算符 “==” 或 Object.Equals() 方法?文末进行解释】
- Line 279:若 next 为空,即 head 为空,说明没有元素在链表中,则直接返回值为空的 next( Line: 304 )。
- Line 281:若要查找的对象值为空,则不进行比较操作,直接判断是否存在空元素。
- Line 283:若当前结点值 item != value 则向后访问下一个结点,继续比较,直到找到符合的结点或再次访问到头结点。
- Line 288、298:若没有找到符合的结点,则直接转调并返回 null。
3. 查找 FindLast()
从方法名来看,其作用是找到值 value 在链表中出现的最后一次所对应的结点。

相比方法 Find(),只是将 next 换成了 prev,其他地方大同小异,主要来分析一下这个 prev 的作用。
当 linkedListNode == prev 时,说明已经遍历完了一遍,此时还未找到目标元素,返回 null。
4. 删除 Remove()
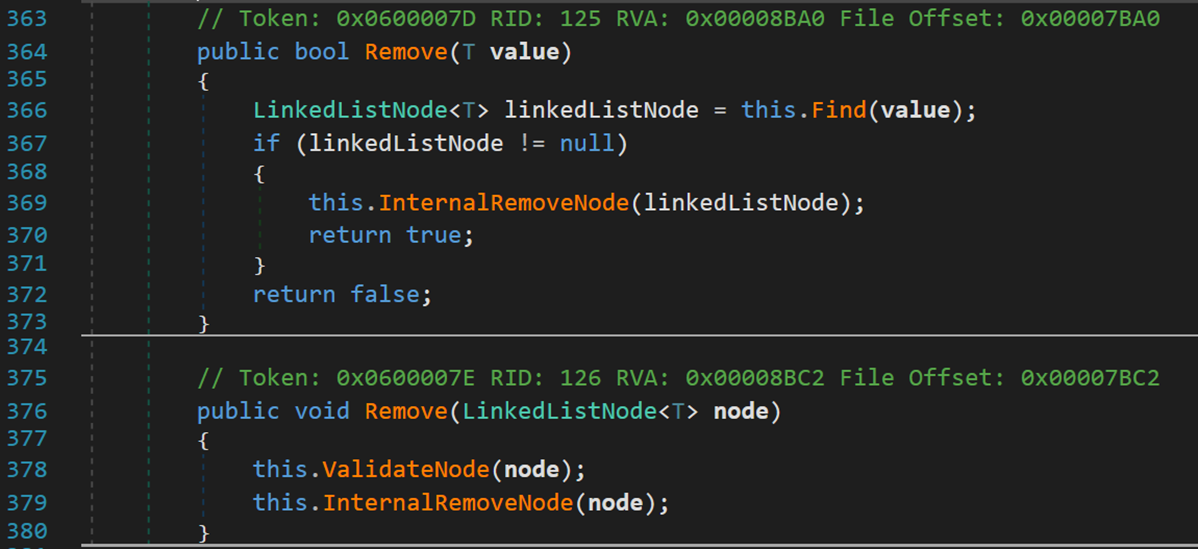
其基本思路说判断合法性,然后执行操作。其中 ValidateNode 在之前提到过,用于判断结点合法性。
下面看一下方法 InternalRemoveNode()

和添加方法中的那个 InternalInsert…() 基本一致,改变结点的指向即可,记得最后要修改结点数量。
(六) 结点类 LinkedListNode<T>
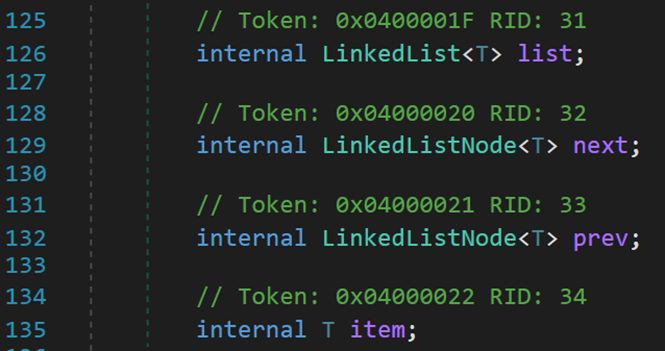
包含四个字段:list 结点所在的链表;next 结点的下一个节点;prev 结点的上一个结点;item 结点内部存储的元素。
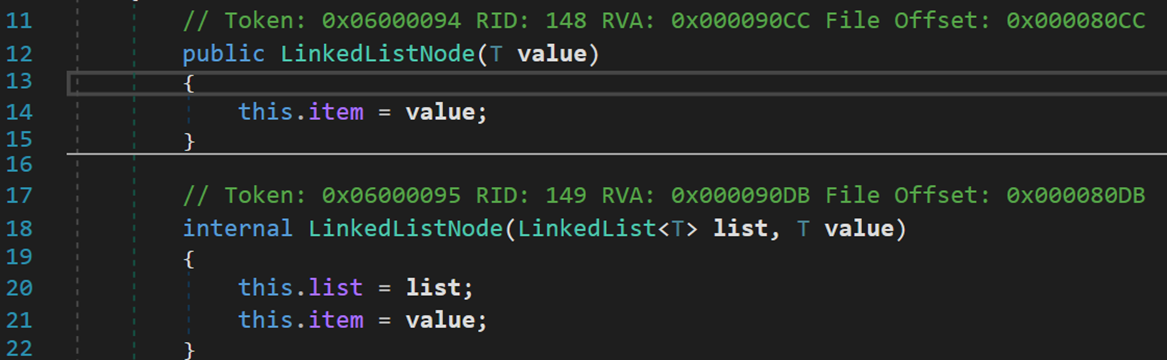
两种初始化的方式,没有默认构造器。也就是说,在定义节点时必须对其赋值(默认为 null)。但链表 LinkedList 是有默认构造器的。
对结点包括以下三种查询操作(Next、Previous、Value):
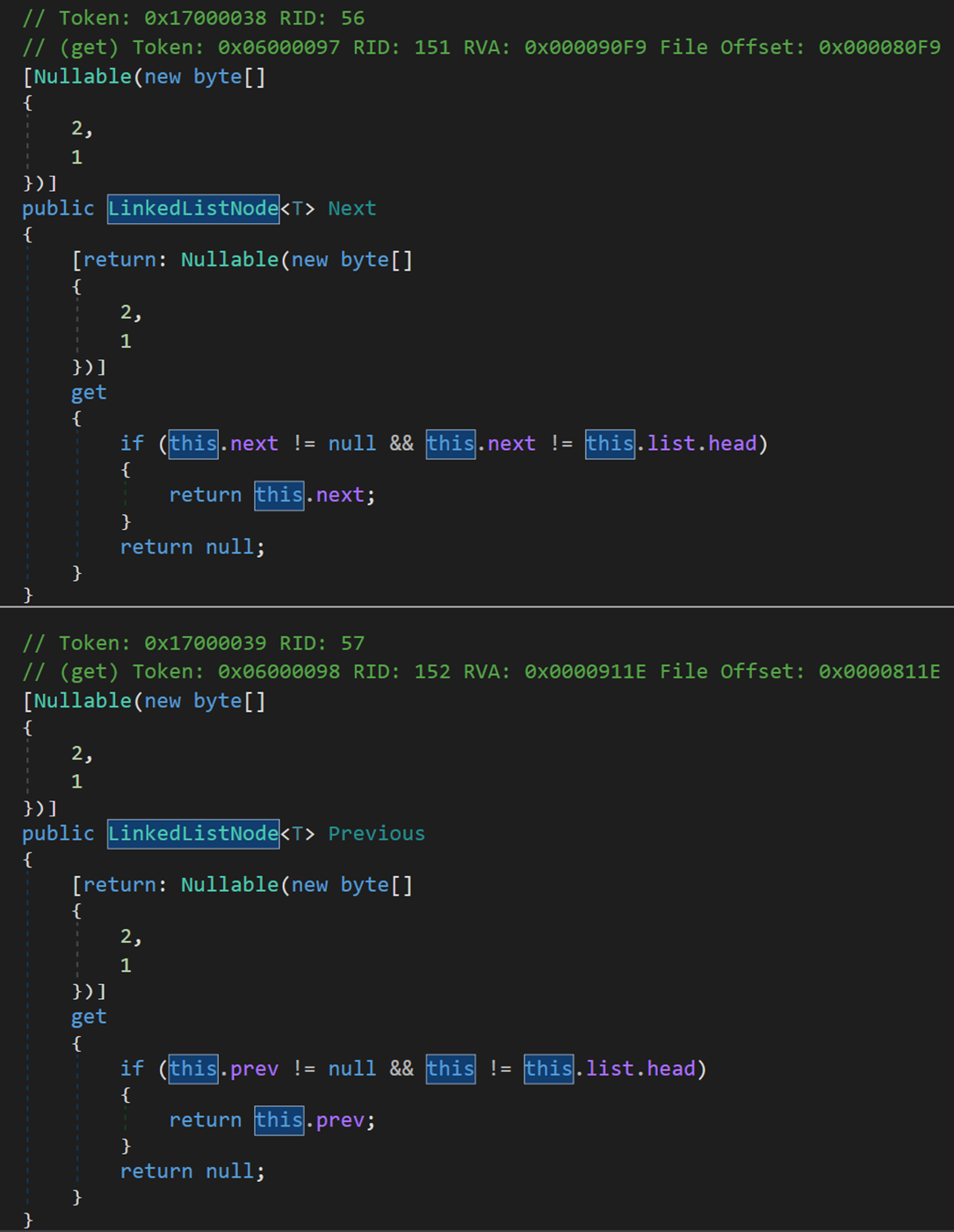
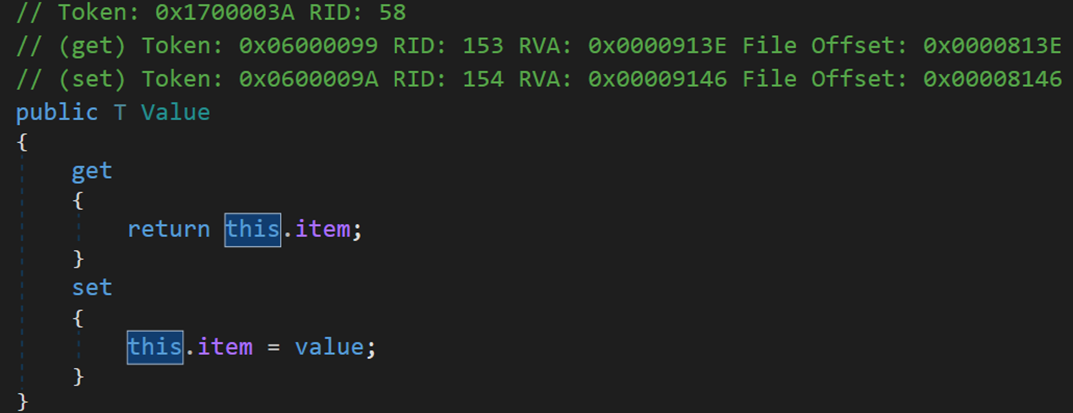
三、C# 与 Java 中的链表结构
单个数据结构其实没有太多要讲的内容,既然 C# 与 Java 是两大较为著名的 OO 语言,那在此就对比一下二者在实现链表结构时的异同。
(一) 结点类 Node<E>
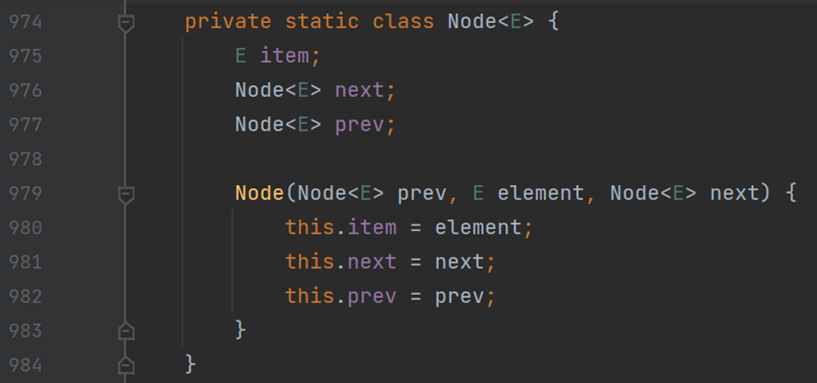
可以知道,Java 中的链表结构也是双向链表。
(二) 构造方法

Java 中的 LinkedList 有两个构造方法。不过差别不大,只不过 C# 中的 LinekdList<T> 还多了一个可列化的元素集。
(三) 属性
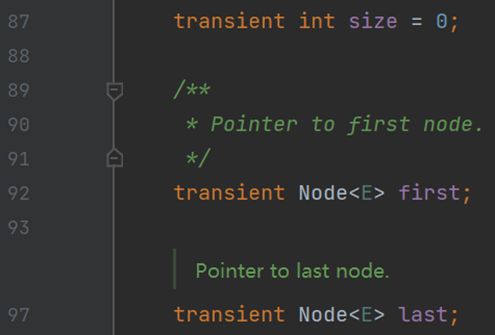
注:在 Java 中此类变量称作属性,没有字段的概念;在 C# 中此类变量称作字段,而属性是针对字段而设计的访问器,用于增强安全性。
除去 C# LinkedList 中的三个特殊字段,其余与 Java LinkedList 一致。
(四) 方法:添加 add()、addFirst() 与 addLast() 方法


可以看到,C# 中的添加方法内置方法 InternalInsert…();Java 中也和 C# 类似,均调用其他来实现。鉴于相似性,下面就只展示一下方法 linkLast() 不做分析。
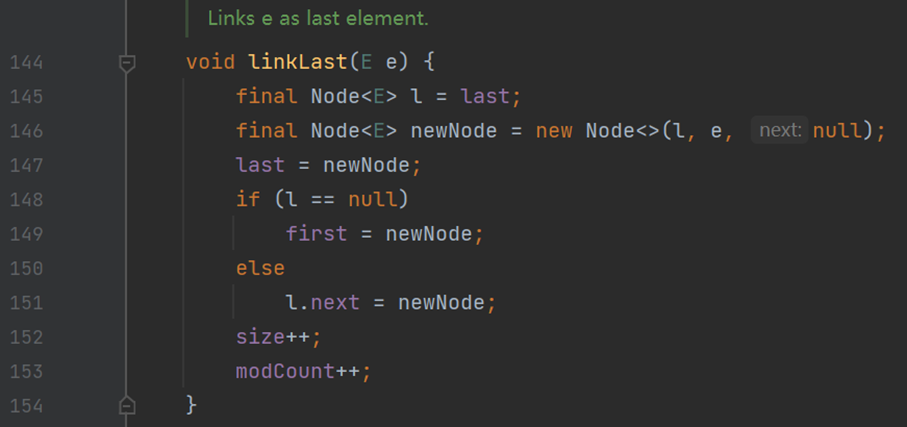
总结
区别不大。硬要说,就可能是运行时 CLR(公共语言运行库) 于 JVM(Java 虚拟机) 优化性能的差异了。
[# 有关可空类型、Nullable<T>与特性 [Nullable] ]
一、可空类型
众所周知,在C# 中,值类型时不可空的,引用类型是可空的:
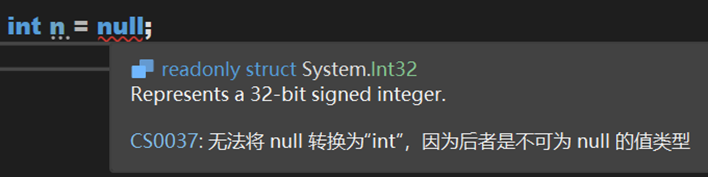
过了一段时间,大概在 C# 5 时期,引入了可空值类型,长这样:
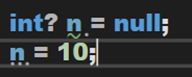
然后又又又过了一段时间,应该是在 C# 8 引入了,可空引用类型:
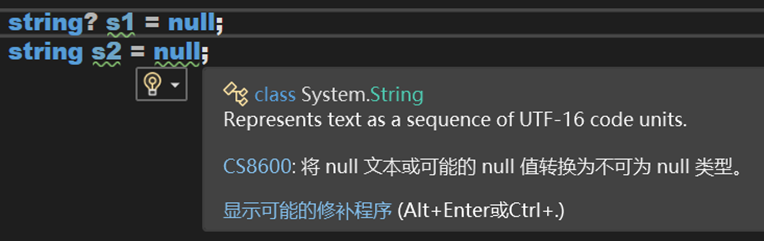
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
调用一下反汇编,看看加了一个问号会不会对数据类型产生影响

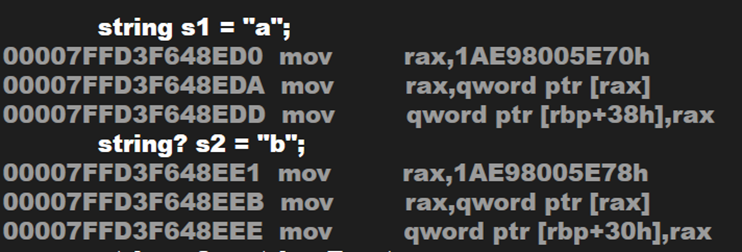
string? 依然是 string,int? 不再是 int,而是变成了 Nullable 类型,相当于:
二、为什么要引入可空引用类型?
分析一下这个有意思的 CS8600 警告:
|
严重性 |
代码 |
说明 |
|
警告 |
CS8600 |
将 null 文本或可能的 null 值转换为不可为 null 类型。 |
嘿!我大引用类型什么时候变成不可为 null 类型了?根据微软文档的解释:该警告的目的是将应用程序在运行时引发 System.NullReferenceException 的可能性降至最低。简单说就是降低代码在运行时引发空引用异常的概率,这一做法会让程序在运行时带来一些效率上的提高。至于是怎么提高的,应该是避免了异常的频繁发生,导致程序频繁终止。(个人观点,仅供参考)。
三、Nullable<T> 的实现
[注意:Nullable<T> 和 Nullable 是两个不同的概念,前一个是结构体,后一个是类;当然二者都是数据类型]
(一) 一个构造方法

- Line 14:特性 [NonVersionable]

上述文本摘自 Reference Source .NET Framework 4.8。直译:这个特性用于表示特定成员的实现或结构布局不能以不兼容的方式在给定的平台进行更改。这允许跨模块内联方法和数据结构,这些方法和结构的实现在ReadyToRun的本机映像中永远不会改变,对这些成员或类型的任何更改都将破坏对ReadyToRun的更改。说人话大概就是,不允许在某些平台上乱改被其修饰的对象,以此保证在本机映像和实际使用时的一致性,避免在不同的环境下同一个内容出现不同的形式。
- Line 18:表示当前对象是否存储了元素。
(二) 两个只读属性
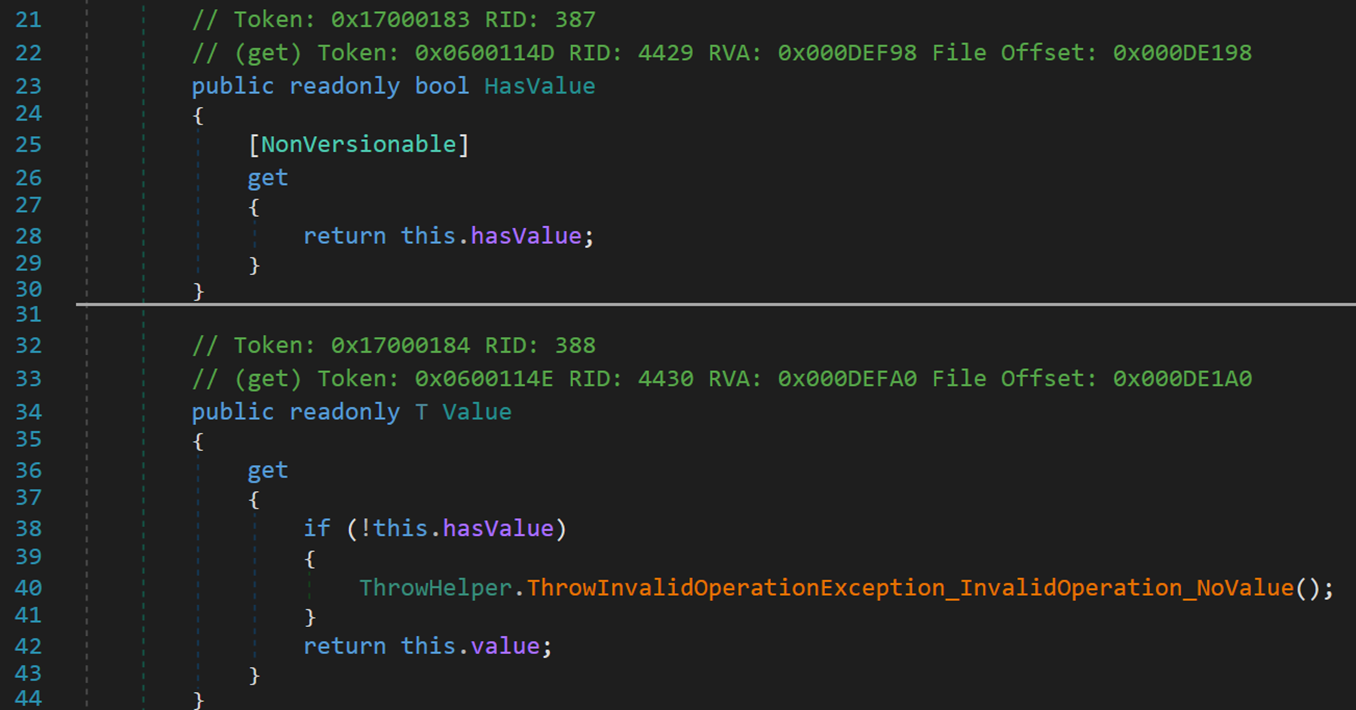
判断是否存储了元素以及返回存储的元素。
(三) 两个字段

hasValue 用于表示当前对象是否存储了某个值;value 表示存储的值。
(四) 两个重载运算符
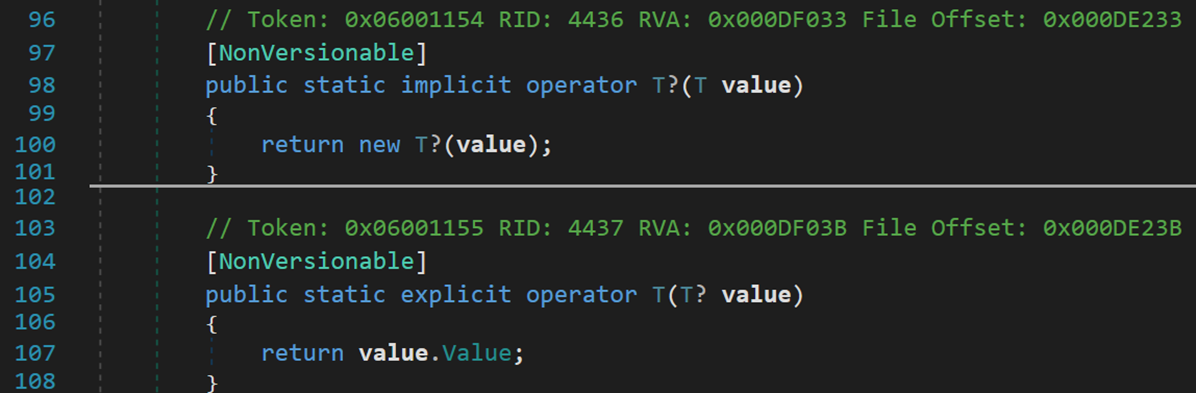
implicit 用于声明隐式的自定义类型转换运算符,实现2个不同类型的隐式转换。使用隐式转换操作符之后,在编译时会跳过异常检查,可能会出现某些异常或信息丢失。
explicit 用于声明必须通过显示转换来调用的自定义的类型转换运算符。不同于隐式转换,显式转换运算符必须通过转换的方式来调用,如果缺少了显式转换,在编译时会产生错误。
简单来说,这两个关键字用于声明类型转换的运算符,针对自定义类型间的转换,一种为隐式转换,另一种为显示转换。
- Line 98:将 value 从类型 T 隐式转换为 T?
- Line 105:将 value 从类型 T? 显示转换为 T
(五) 常用方法
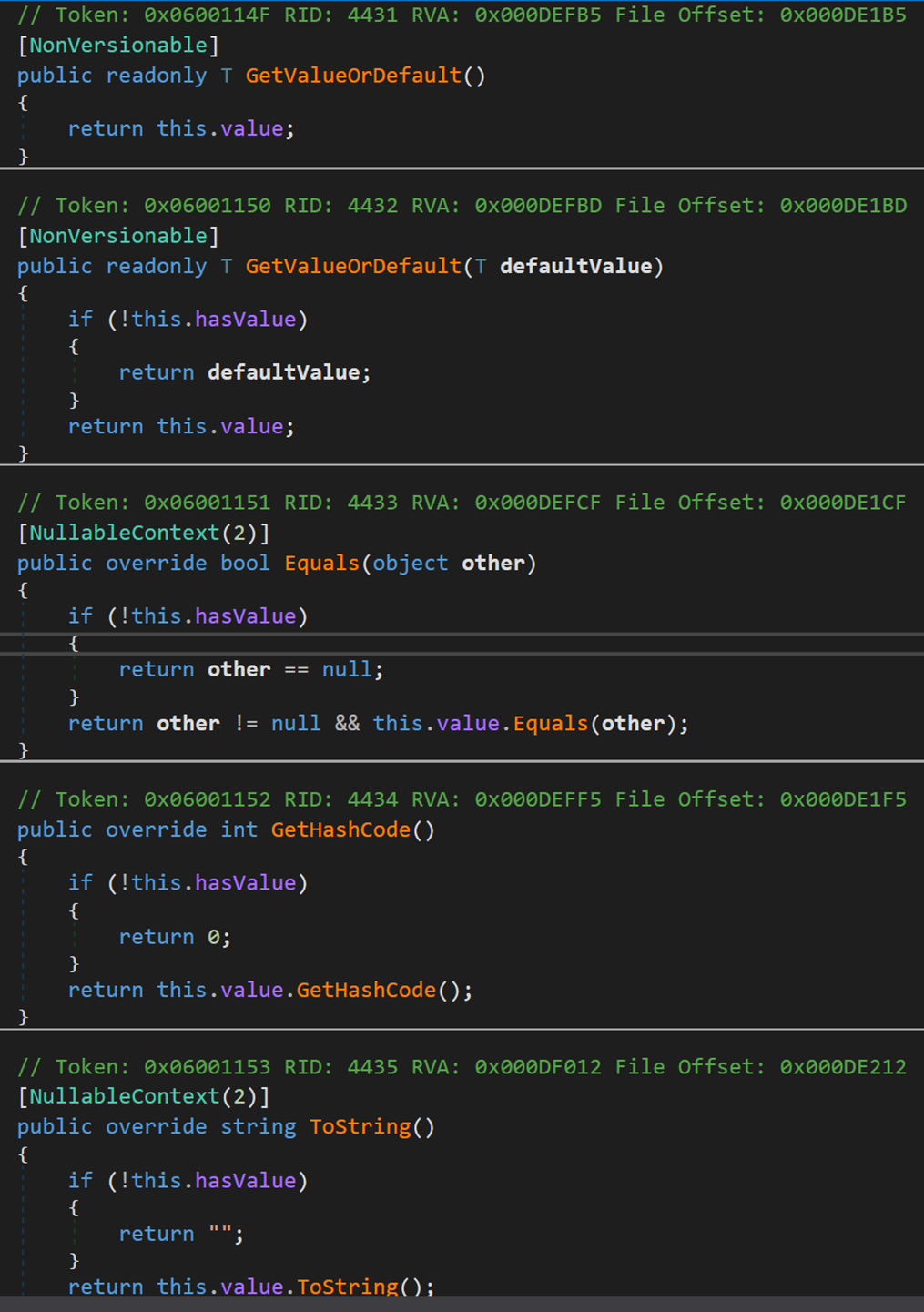
其包含的方法和其他类型中的方法大致相同,在此不作解释。
四、(空)合并运算符 ??
单个问号在 C# 中是三元表达式的结构之一,也是定于可空类型的符号。而两个问号被定义为合并运算符,其工作原理如下:对于表达式 <par> = <par1> ?? <par2> 如果左操作数 par1 的值不为 null,则合并运算符返回该值,即 par1;否则,它会计算右操作数并返回其结果。如果左操作数的计算结果为不为 null,则 ?? 运算符不会计算其右操作数。
仅当左操作数的计算结果为 null 时,Null 合并赋值运算符 ??= 才会将其右操作数的值赋值给其左操作数。 如果左操作数的计算结果为非 null,则 ??= 运算符不会计算其右操作数。其中 ??= 运算符的左操作数必须是变量、属性或索引器元素。
举例如下:
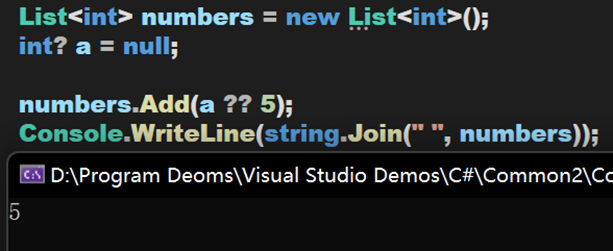
此时 a 为 null,因此返回 5
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——

此时 a 不为 null,因此返回 a 的值。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
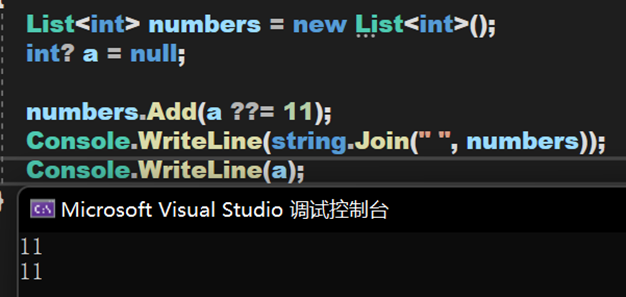

同理可得,a 为空返回11;a 不为空返回 a。
五、可空容忍 !

其实这是一个补充,在代码中如果我们判断出某个变量在使用时一定不为null,但是编译器会在可空上下文中抛出警告,这是一个不太正常的行为,可空容忍可以消除这种警告,将不可为空的引用类型转换成可为空的引用类型。


假如我们知道 obj 和 obj.ToString() 在这里一定不为空,那么就可以在 obj 与 ToString() 的结果后加上可空容忍运算符,将其转换为不可空类型,以此消除警告。
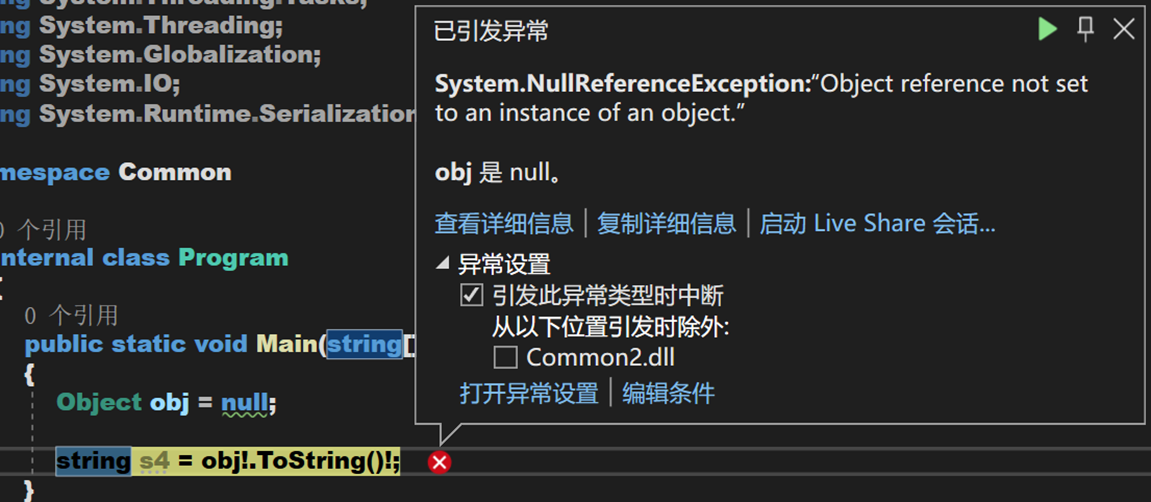
这样操作后,obj 不可再被赋值为 null。
六、更多的可空特性
【注:
1. 特性一般用来解决警告问题,并不能解决错误或进行强制类型转换。
2. 特性的修饰更多地,只起到标识告知的作用。】
需要引入命名空间

(一) AllowNull
性质:前置条件,即放在修饰对象前。
作用:将不可为 null 的参数、字段或属性使其可以为 null。【注意,这里的“不可为”指的是警告内容,不是数据类型上的不可为空】
举例:
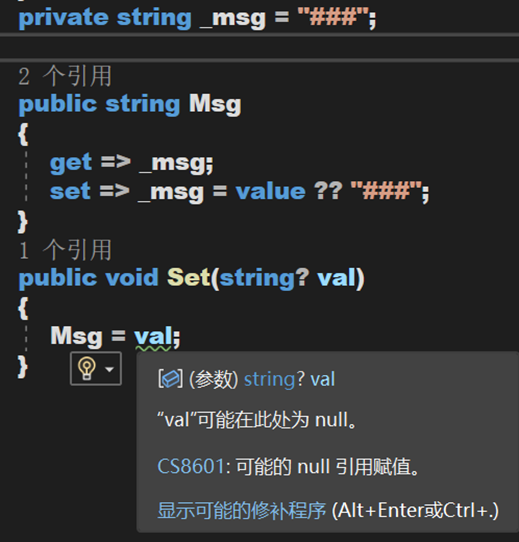
现在有一个字段,当通过属性获取字段值的时候,一定不会获得到 null,因为在 set 里面指定了非 null 的默认值。然而在方法 Set() 里是允许设置 null 到这个属性,但属性 Msg 是不可为空的。于是,为了解决警告的出现,要么将字段定义为可空,要么将这个加上特性 [AllowNull]。这样,获取此字段的时候会得到非 null 值,但设置的时候却可以传递 null。
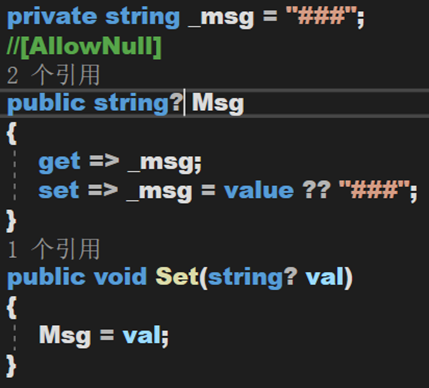

即,将不可为空的属性 Msg 标记为可为空(可以传入空值),但传入空时会保持其默认值。
大多数情况下,属性或 in、out 和 ref 参数需要此特性。 当变量通常为非 null 时,[AllowNull] 是最佳选择,但需要允许 null 作为前提条件。
(二) 其余可空特性
特性一般主要用于处理警告方面的问题,使得程序更加规范化,在此不作过多演示,更多内容,请参考下表(来自:C# 编译器解释的属性:可为 null 的静态分析 | Microsoft Learn)
|
Attribute |
Category |
含义 |
|
不可为 null 的参数、字段或属性可以为 null。 |
||
|
可为 null 的参数、字段或属性应永不为 null。 |
||
|
不可为 null 的参数、字段、属性或返回值可能为 null。 |
||
|
可为 null 的参数、字段、属性或返回值将永不为 null。 |
||
|
当方法返回指定的 bool 值时,不可为 null 的参数可以为 null。 |
||
|
当方法返回指定的 bool 值时,可以为 null 的参数不会为 null。 |
||
|
如果指定参数的自变量不为 null,则返回值、属性或自变量不为 null。 |
||
|
当方法返回时,列出的成员不会为 null。 |
||
|
当方法返回指定的 bool 值时,列出的成员不会为 null。 |
||
|
方法或属性永远不会返回。 换句话说,它总是引发异常。 |
||
|
如果关联的 bool 参数具有指定值,则此方法或属性永远不会返回。 |
七、特性 [Nullable]
特性,在之前的文章中也讲述过,主要是进行修饰,使得对象具有某些额外性质。
Nullable,属于内部密封类 NullableAttribute,派生自类 Attribute。
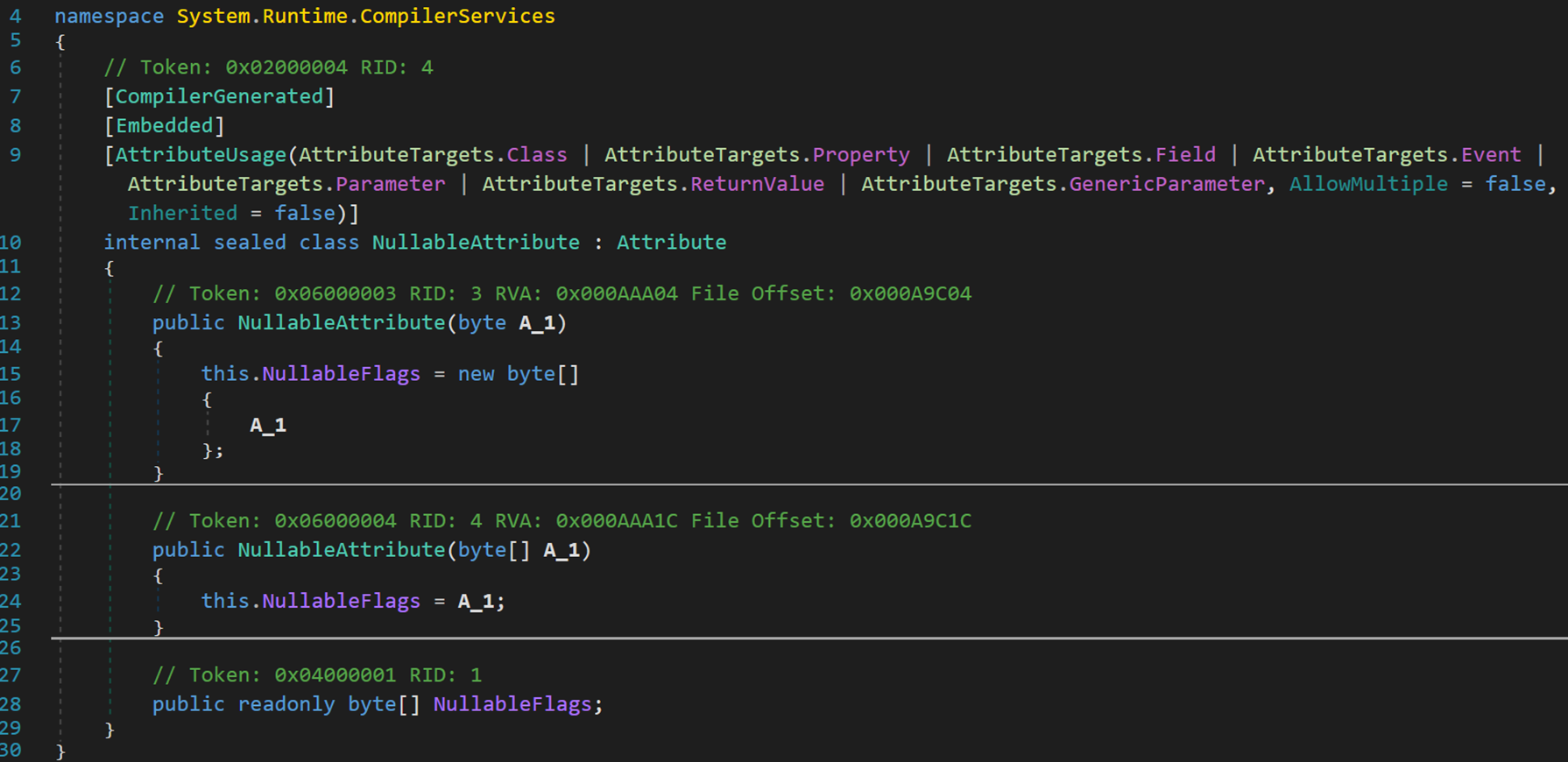
- Line 13、22:该特性有两种表示方式,就是经常看到的:在括号里写上数字或一个数组
![]()
- Line 28:最后均存储到名为 NullableFlags的 byte 数组中,据名称可以推测,每个不同的数字赋予了 Nullable 这个特性不同的额外功能。
根据 C# 的编译器roslyn的GitHub页面(roslyn/nullable-metadata.md at main · dotnet/roslyn · GitHub):Each type reference in metadata may have an associated NullableAttribute with a byte[] where each byte represents nullability: 0 for oblivious, 1 for not annotated, and 2 for annotated. 也就是说,该数组中的有效值仅为0、1、2,且具有不同的含义。【由于无法找到相关文档,也无法进行相关实验操作,数值所代表的含义在此暂不做分析,后续可能会补上】
总结
- 可空引用类型是在编译时起作用,在运行时和普通的引用类型没有任何区别,它主要是在编译时结合可空上下文,帮助我们分析代码中可能出现空指针引用异常的地方,这是一个非常好的语法糖,我们只需要遵守上面三种规则,就可以很大程度减少空指针异常的几率,其实,如果仔细看的话,.NET 基础库已经遵守了这个规则,比如object 类的 ToString() 方法和 Equals() 方法等。
- 添加这些特性将为编译器提供有关 API 规则的更多信息。当调用代码在可为 null 的上下文中编译时,编译器将在调用方违反这些规则时发出警告。这些特性不会启用对实现进行更多检查。
- 添加可为 null 的引用类型提供了一个初始词汇表,用于描述 API 对可能为 null 的变量的期望。这些特性提供了更丰富的词汇来将变量的 null 状态描述为前置条件和后置条件。 这些特性更清楚地描述了期望,并为使用 API 的开发人员提供了更好的体验。在为可为 null 的上下文中更新库时,添加这些特性可指导用户正确使用 API。这些特性有助于全面描述参数和返回值的 null 状态。
[# 有关迭代器的实现原理]
在讲 LINQ 时,提到过迭代器 Iterator,也分析了其源码,感兴趣的可参阅本人的文章([算法1-排序](.NET源码学习)& LINQ & Lambda - PaperHammer - 博客园 (cnblogs.com))[# 有关Iterator的源码]
[# 有关接口 IEqualityComparer<T> 与 相等判断]
在 C# 中,用来比较元素/对象是否相等有以下几种方式:运算符 “==”,方法 Equals(),方法 SequenceEqual(),接口 IEquatable<T>,接口 IEqualityComparer<T>。
一、运算符“==“
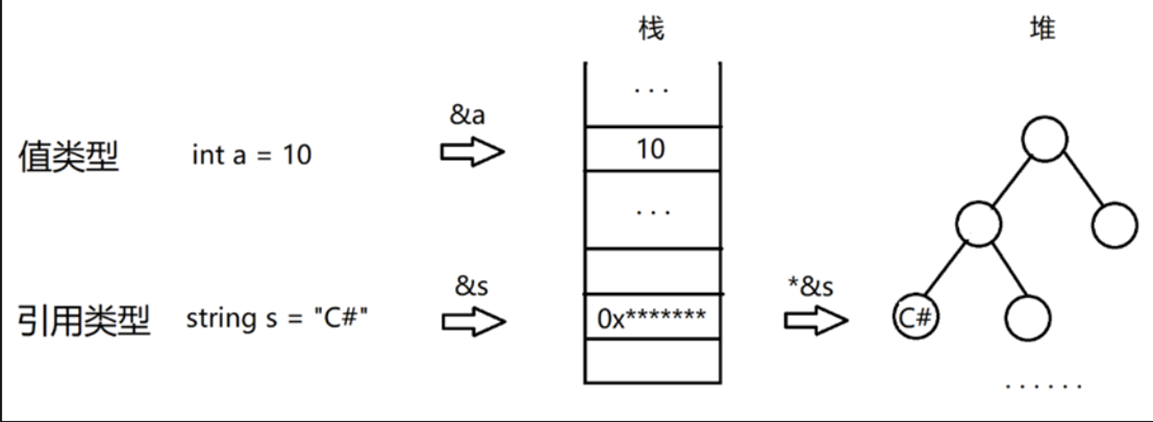
其比较规则较为简单:“==” 是对方法 Equals() 的重载,对于值类型,比较的是值内容(即,栈中的内容);对于引用类型,比较的是引用地址(即,堆/堆栈中的内容)。
(一) 值类型:

—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
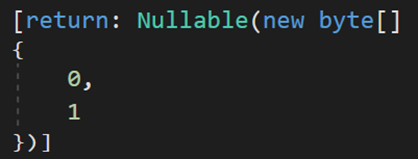
(二) 引用类型
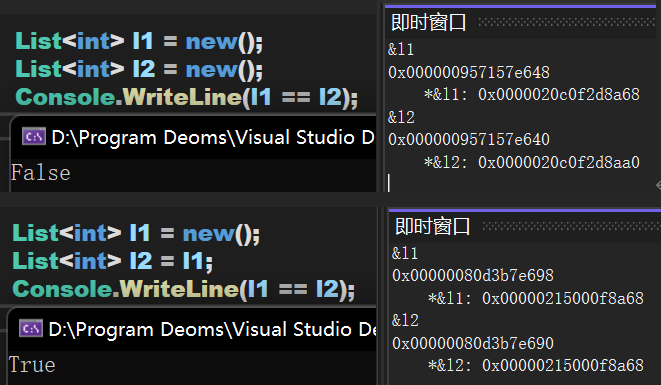
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
虽然在之前的文章中提到过,这里还是再解释一下即使窗口里的信息。此处显示了两个地址:一个是 &x 后的地址;另一个时 *&x 后的地址。
对于 C# 而言总会将变量本身存储在栈中,变量内部的值存储在相应的位置(值类型在栈中,引用类型在堆/堆栈中)。对于获取到的第一个地址,是变量在栈中存储的位置,也就是说:C# 中的 &x 获取的是变量在栈中的位置。
而 *&x 的含义是:解析地址 &x,即读取其中的值。对于值类型而言,其值就存储在栈中,因此解析后直接得到对应的值;对于引用类型而言,其值存储在堆/堆栈中,因此解析后会得到一个堆中的位置,这个位置就是存储实际值的位置。
二、方法 Equals()
类 Object:

类 RuntimeHelpers:

方法 Equals() 最初被定义在类 RuntimeHelpers 中,再由类 Object 与类 ValueType 进行扩展,而 C# 中其他所有类型(包括值类型、引用类型、自定义类型)均派生自这两个类,并重写了这个方法,因此对于任意一个变量均可使用这个方法;且均有各自的比较据。
【关于方法 Equals() 的更多说明与应用,请参阅C# 有关List<T>的Contains与Equals方法 - PaperHammer - 博客园 (cnblogs.com)】
小结一
在 C# 中,对于值类型的比较不管是用 “==” 还是 Equals 都是对于其内容的比较,也就是说对于其值的比较,相等则返回 true 不相等则返回 false;
但是对于除 string 类型以外的引用类型 “==” 比较的是对象在栈上的引用是否相同,而 Equals 则比较的是对象在堆上的内容是否相同。
三、方法 Comapre()
该方法主要用于字符串间的比较,比较的是字符串的大小,根据字符对应的 ASCII 码进行比较。
对于 Compare(s1, s2):s1 == s2 返回 0;s1 > s2 返回 1;s1 < s2 返回 -1。
四、泛型类型 EqualityCompare<T>



该类是一个抽象类,位于程序集 CoreLib.dll 中的 命名空间 System.Collections.Generic

包含 8 个方法,一个属性。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
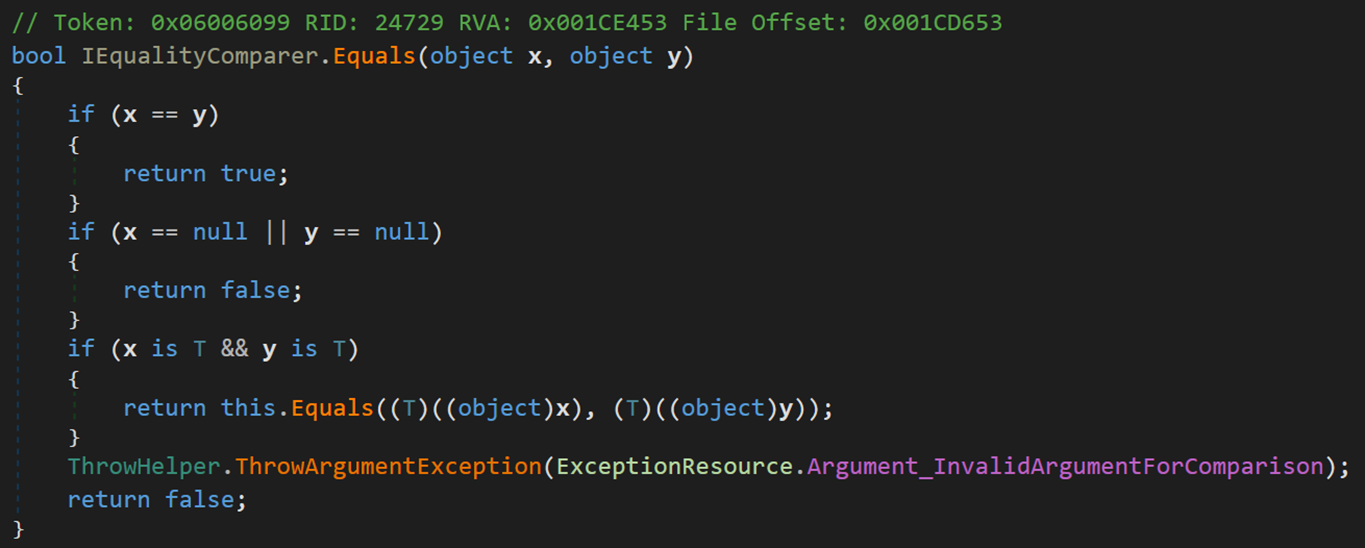
此处主要关注方法 IEqualityComparer.Equals(object x, object y)
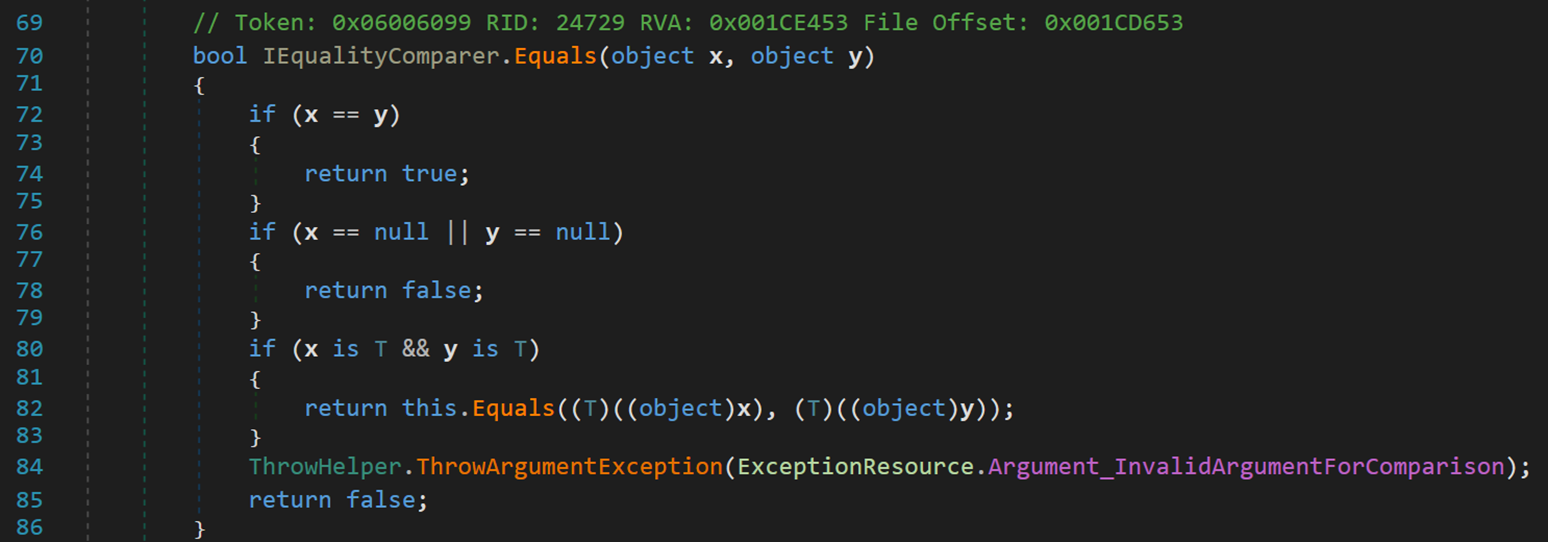
其实该方法的比较依旧主要过运算符 “==” 完成。
- Line 82:当两个对象不相等且均不为空时,在确保二者为相同类型的情况下,将其转换为各具体类型,按照具体类型的比较规则进行比较。
总结
对于比较,其实并不复杂,只需要区分开值类型与引用类型的比较规则就可以。虽然有许多工具都可以用来比较,但其比较的本质依旧是不变的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号