

数据采集与融合技术-第四次实践作业
作业1
要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、 “上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
o 候选网站: 东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
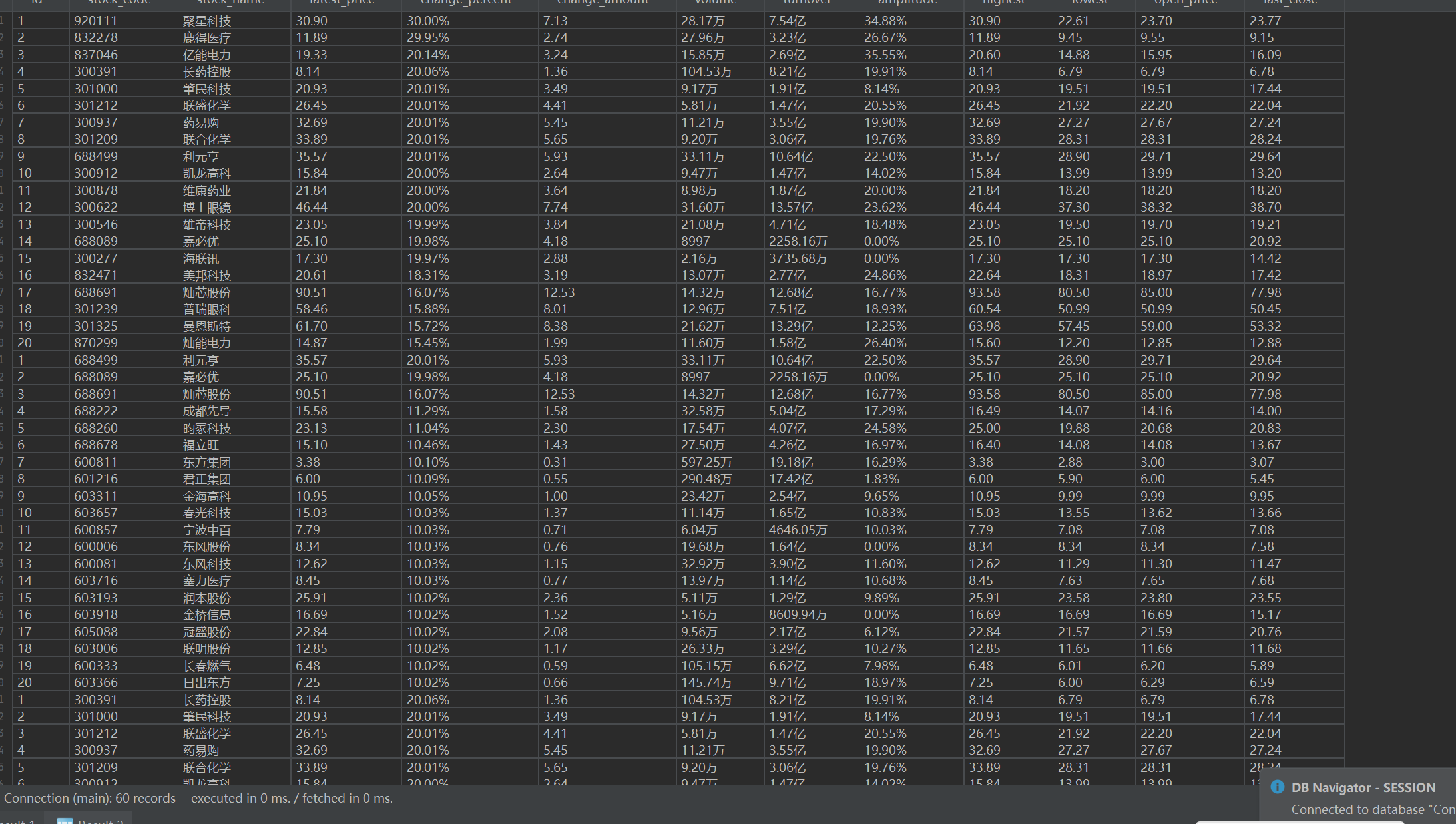
o 输出信息: MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码: bStockNo……,由同学们自行定义设计表头:
• Gitee 文件夹链接
–务必控制总下载的图片数量(学号尾数后2位)限制爬取的措施。
| Gitee链接 |
|---|
| https://gitee.com/xiaoaibit/102202131_LX/blob/master/homework4/demo1.py |
爬虫代码
import sqlite3
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建数据库连接
conn = sqlite3.connect('stock_data.db') # 'stock_data.db' 是数据库文件名
cursor = conn.cursor()
# 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id TEXT,
stock_code TEXT,
stock_name TEXT,
latest_price TEXT,
change_percent TEXT,
change_amount TEXT,
volume TEXT,
turnover TEXT,
amplitude TEXT,
highest TEXT,
lowest TEXT,
open_price TEXT,
last_close TEXT
)
''')
# 初始化Selenium WebDriver
driver = webdriver.Edge()
driver.get("https://quote.eastmoney.com/center/gridlist.html#hs_a_board")
time.sleep(2)
# 获取数据
ts = driver.find_elements(By.XPATH, "//tbody//tr")
for t in ts:
id = t.find_element(By.XPATH, ".//td[1]").text
stock_code = t.find_element(By.XPATH, ".//td[2]").text
stock_name = t.find_element(By.XPATH, ".//td[3]").text
latest_price = t.find_element(By.XPATH, ".//td[5]").text
change_percent = t.find_element(By.XPATH, ".//td[6]").text
change_amount = t.find_element(By.XPATH, ".//td[7]").text
volume = t.find_element(By.XPATH, ".//td[8]").text
turnover = t.find_element(By.XPATH, ".//td[9]").text
amplitude = t.find_element(By.XPATH, ".//td[10]").text
highest = t.find_element(By.XPATH, ".//td[11]").text
lowest = t.find_element(By.XPATH, ".//td[12]").text
open_price = t.find_element(By.XPATH, ".//td[13]").text
last_close = t.find_element(By.XPATH, ".//td[14]").text
cursor.execute('''
INSERT INTO stocks (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close))
button1 = driver.find_element(By.XPATH,'//*[@id="nav_sh_a_board"]/a')
button1.click()
time.sleep(2)
ts = driver.find_elements(By.XPATH, "//tbody//tr")
for t in ts:
id = t.find_element(By.XPATH, ".//td[1]").text
stock_code = t.find_element(By.XPATH, ".//td[2]").text
stock_name = t.find_element(By.XPATH, ".//td[3]").text
latest_price = t.find_element(By.XPATH, ".//td[5]").text
change_percent = t.find_element(By.XPATH, ".//td[6]").text
change_amount = t.find_element(By.XPATH, ".//td[7]").text
volume = t.find_element(By.XPATH, ".//td[8]").text
turnover = t.find_element(By.XPATH, ".//td[9]").text
amplitude = t.find_element(By.XPATH, ".//td[10]").text
highest = t.find_element(By.XPATH, ".//td[11]").text
lowest = t.find_element(By.XPATH, ".//td[12]").text
open_price = t.find_element(By.XPATH, ".//td[13]").text
last_close = t.find_element(By.XPATH, ".//td[14]").text
cursor.execute('''
INSERT INTO stocks (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close))
button1 = driver.find_element(By.XPATH,'//*[@id="nav_sz_a_board"]/a')
button1.click()
time.sleep(2)
ts = driver.find_elements(By.XPATH, "//tbody//tr")
for t in ts:
id = t.find_element(By.XPATH, ".//td[1]").text
stock_code = t.find_element(By.XPATH, ".//td[2]").text
stock_name = t.find_element(By.XPATH, ".//td[3]").text
latest_price = t.find_element(By.XPATH, ".//td[5]").text
change_percent = t.find_element(By.XPATH, ".//td[6]").text
change_amount = t.find_element(By.XPATH, ".//td[7]").text
volume = t.find_element(By.XPATH, ".//td[8]").text
turnover = t.find_element(By.XPATH, ".//td[9]").text
amplitude = t.find_element(By.XPATH, ".//td[10]").text
highest = t.find_element(By.XPATH, ".//td[11]").text
lowest = t.find_element(By.XPATH, ".//td[12]").text
open_price = t.find_element(By.XPATH, ".//td[13]").text
last_close = t.find_element(By.XPATH, ".//td[14]").text
cursor.execute('''
INSERT INTO stocks (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close))
# 提交事务
conn.commit()
# 关闭数据库连接
cursor.close()
conn.close()
# 关闭WebDriver
driver.quit()
结果
心得体会
1. 精确的元素定位
- 在使用 Selenium 进行网页元素定位时,精确的 XPath 或 CSS 选择器至关重要。这直接影响到数据抓取的准确性和效率。
2. 等待元素加载
time.sleep()是一种简单的等待页面加载的方法,但在实际应用中,使用 Selenium 提供的显式等待(如WebDriverWait)更为高效和可靠。
3. 多线程或异步处理
- 对于需要抓取大量页面的情况,可以考虑使用多线程或异步 IO 来提高效率。多线程或异步处理
- 对于需要抓取大量页面的情况,可以考虑使用多线程或异步 IO 来提高效率。
作业2
要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站: 中国 mooc 网: https://www.icourse163.org
o 输出信息: MYSQL 数据库存储和输出格式
• Gitee 文件夹链接https://www.eastmoney.com/输出信息:MySQL数据库存储和输出格式如下:表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
| Gitee链接 |
|---|
| https://gitee.com/xiaoaibit/102202131_LX/blob/master/homework4/demo2.py |
爬虫代码
import time
import sqlite3
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建数据库连接
conn = sqlite3.connect('courses.db')
cursor = conn.cursor()
# 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS courses (
Id TEXT,
cCourse TEXT,
cCollege TEXT,
cTeacher TEXT,
cTeam TEXT,
cCount TEXT,
cProcess TEXT,
cBrief TEXT
)
''')
# 初始化Selenium WebDriver
driver = webdriver.Edge()
driver.get("https://www.icourse163.org/channel/2001.htm") # 修复了URL
driver.implicitly_wait(20)
driver.execute_script("window.scrollTo(0, 0);")
# 获取课程列表
courses = driver.find_elements(By.XPATH, '//ul[@class="_2mEuw"][position()=1]/div')
i = 1
for course in courses:
window_handles = driver.window_handles
driver.switch_to.window(window_handles[0])
if i == 6:
break
course.click()
window_handles = driver.window_handles
driver.switch_to.window(window_handles[i])
i += 1
driver.implicitly_wait(20)
Id = i - 1
cCourse = driver.find_element(By.XPATH, '//span[@class="course-title f-ib f-vam"]').text
cCollege = driver.find_element(By.XPATH, "//img[@class='u-img']").get_attribute('alt')
cTeacher = driver.find_element(By.XPATH, "//div[@class='cnt f-fl']").text
cTeam = driver.find_element(By.XPATH, "//div[@class='cnt f-fl']").text
cCount = driver.find_element(By.XPATH, "//span[@class='count']").text
cProcess = driver.find_element(By.XPATH, "//div[@class='course-enroll-info_course-info_term-info_term-time']").text
cBrief = driver.find_element(By.XPATH, "//div[@class='f-richEditorText']").text
# 插入数据到数据库
cursor.execute('''
INSERT INTO courses (Id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
''', (Id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
# 提交事务
conn.commit()
# 关闭Cursor和Connection
cursor.close()
conn.close()
# 关闭WebDriver
driver.quit()
结果

1. 精确的 XPath 定位
- 使用 XPath 定位元素时,需要确保路径的准确性。错误的路径会导致元素无法被正确识别,从而影响数据抓取。
2. 等待页面加载
- 使用
implicitly_wait和execute_script来确保页面加载完成,避免因页面未完全加载而导致的数据抓取不准确。
3. 多窗口处理
- 在处理新标签页或弹窗时,需要使用
switch_to.window来切换窗口,确保在正确的窗口中进行元素操作。
作业3
要求:
掌握大数据相关服务,熟悉 Xshell 的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
环境搭建:
任务一:开通 MapReduce 服务
实时分析开发实战:
任务一:Python 脚本生成测试数据
任务二:配置 Kafka
任务三: 安装 Flume 客户端
任务四:配置 Flume 采集数据
环境搭建:
任务一:开通 MapReduce 服务

实时分析开发实战:
任务一:Python 脚本生成测试数据
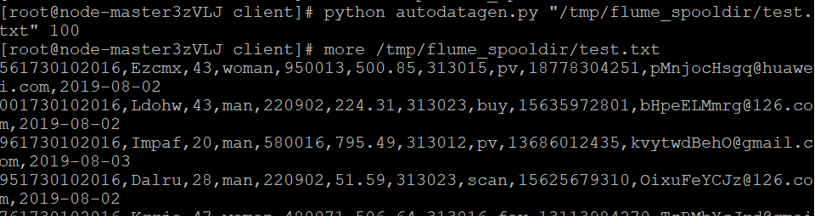
执行脚本测试
执行Python命令,测试生成100条数据
使用more命令查看生成的数据(enter键向下一行,space键向下一屏,b向上一屏,q键退出)。
任务二:配置 Kafka
进入MRS Manager集群管理
下载Kafka客户端
校验下载的客户端文件包
使用PuTTY登录到master节点服务器上,进入/tmp/FusionInsight-Client/目录。
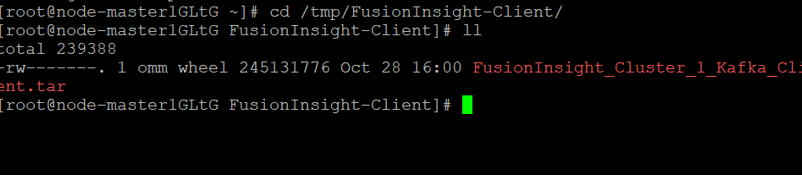
执行以下命令,解压压缩包获取校验文件与客户端配置包

执行命令,校验文件包。

安装Kafka运行环境
解压“MRS_Flume_ClientConfig.tar”文件。
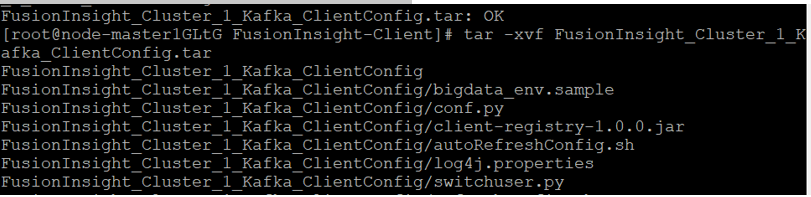
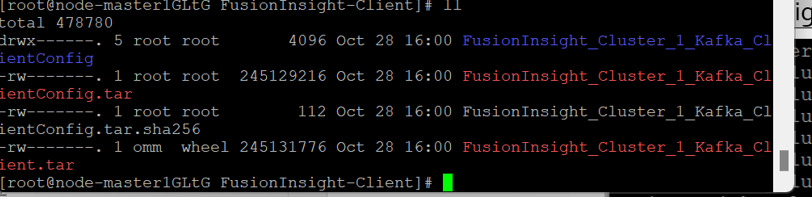
查看解压后文件
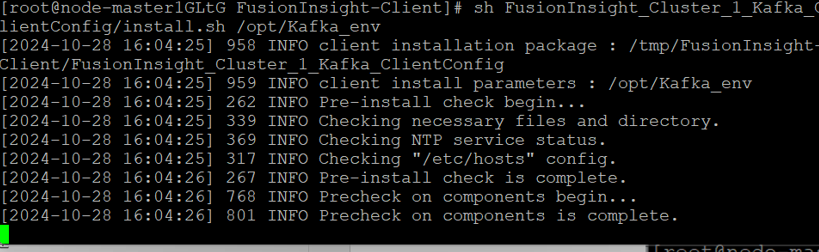
安装客户端运行环境到目录“/opt/Kafka_env”(安装时自动生成目录)。
执行命令配置环境变量。

安装Kafka客户端
安装Kafka到目录“/opt/KafkaClient”(安装时自动生成目录,-d:表示Kafka客户端安装路径)。
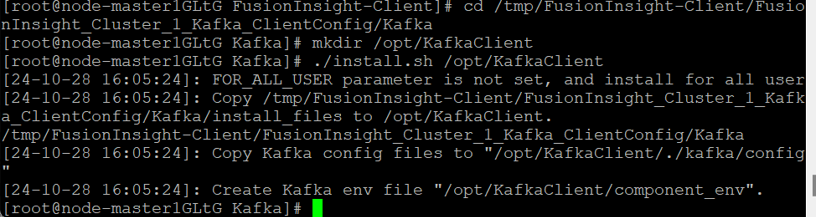
设置环境变量
使用Putty登录MRS的master节点服务器后,首先使用source命令进行环境变量的设置使得相关命令可用。

在kafka中创建topic
执行如下命令创建topic(--bootstrap-server替换成你的kafka的IP,如何获取IP请参见附录步骤)。

查看topic信息

任务三: 安装 Flume 客户端
下载Flume客户端
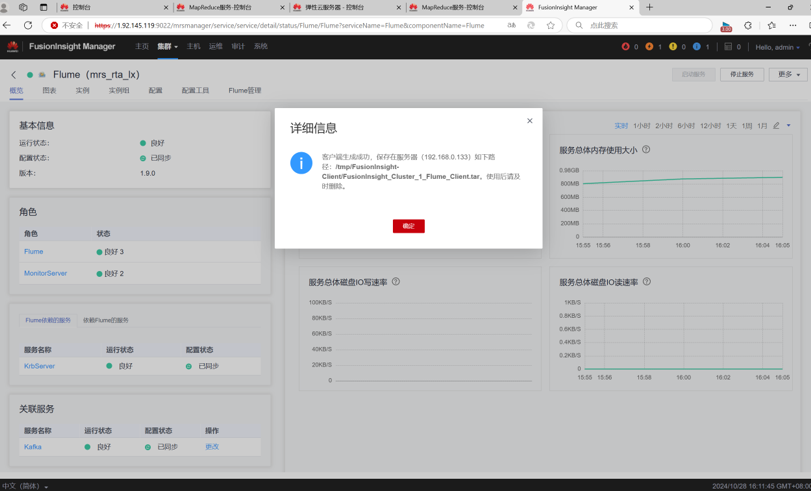
校验下载的客户端文件包
使用PuTTY登录到master节点服务器上,进入/tmp/FusionInsight-Client/目录。
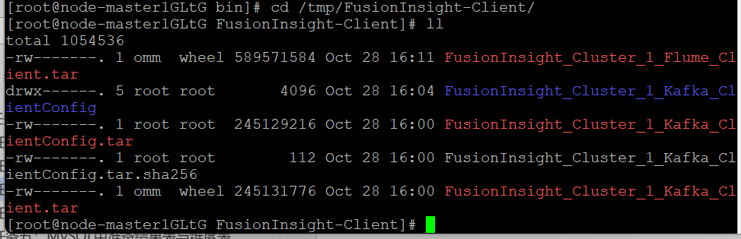
执行以下命令,解压压缩包获取校验文件与客户端配置包

执行命令,校验文件包。

安装Flume运行环境
解压“MRS_Flume_ClientConfig.tar”文件。
查看解压后文件。
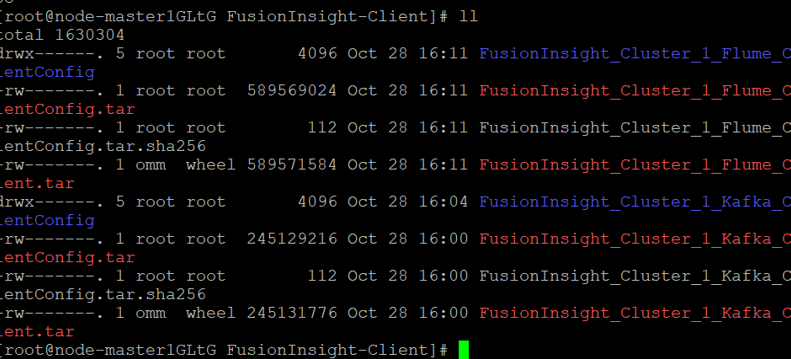
安装客户端运行环境到目录“/opt/Flume_env”(安装时自动生成目录)。
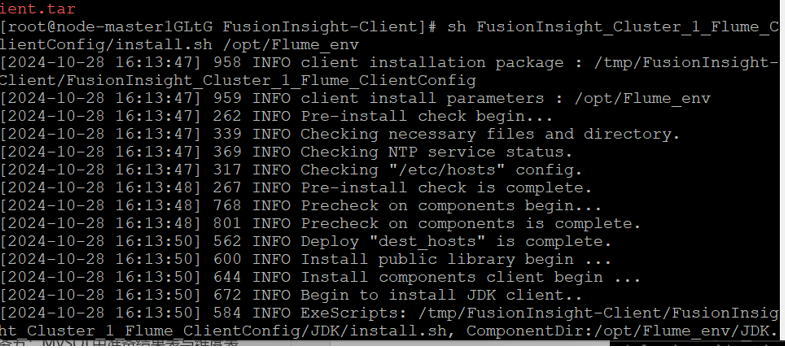
执行命令配置环境变量。

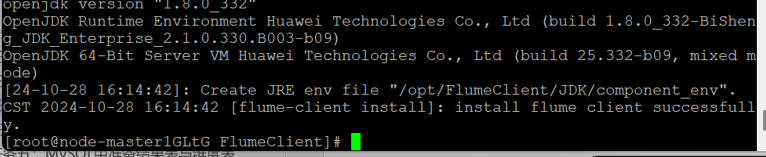
安装Flume客户端
安装Flume到目录“/opt/FlumeClient”(安装时自动生成目录,-d:表示Flume客户端安装路径)。
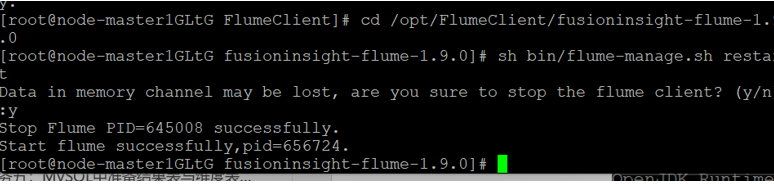
重启Flume服务
执行以下命令重启Flume的服务。
任务四:配置 Flume 采集数据
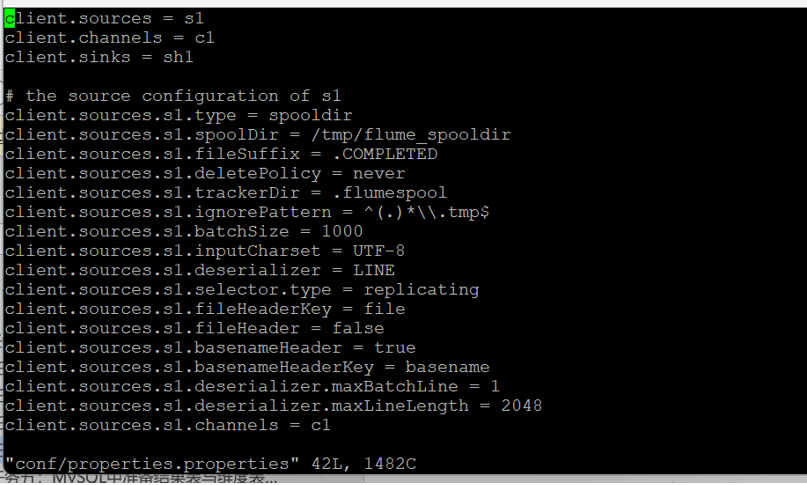
修改配置文件
进入Flume安装目录

在conf目录下编辑文件properties.properties

创建消费者消费kafka中的数据
使用PuTTY登录master节点后,执行命令(此处bootstrap-server的ip对应的是Kafka的Broker的IP):

执行以上命令后,需要新开一个PuTTY会话窗口。
点击PuTTY标题栏左侧的图标,在弹出的菜单中选择“Duplicate Session”复制会话。
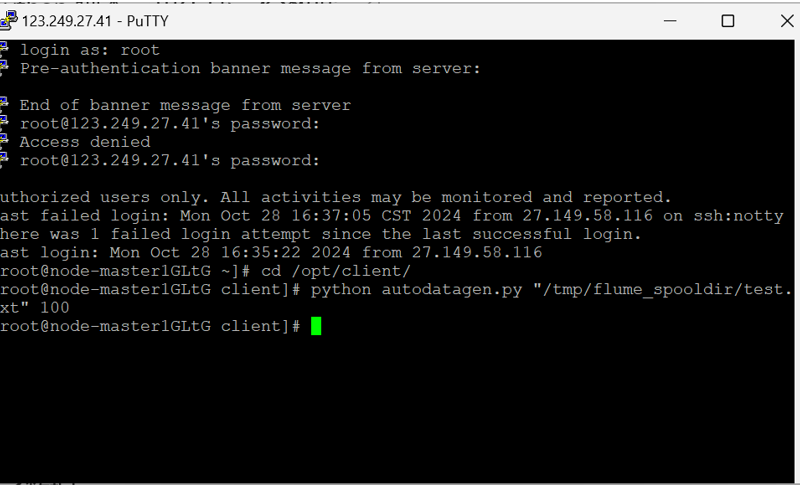
进入Python脚本所在目录,执行python脚本,再生成一份数据。
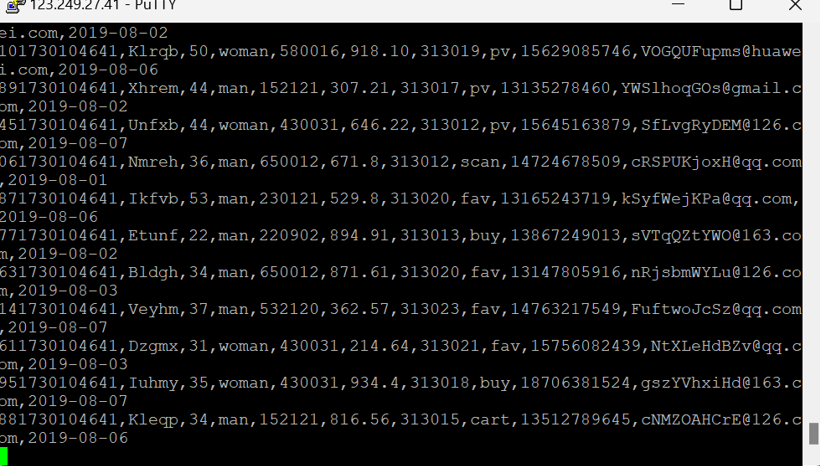
查看原窗口,可以看到已经消费出了数据:
心得体会
开通 MapReduce 服务
- 理解 MapReduce 原理:在实际操作之前,深入理解 MapReduce 的工作原理对于后续的配置和优化至关重要。
- 环境配置的重要性:正确配置 Hadoop 环境是成功运行 MapReduce 作业的前提。这包括合理设置内存、存储等资源。
- 监控与调试:在 MapReduce 服务运行过程中,实时监控作业的执行情况,并学会如何调试常见的问题。
Python 脚本生成测试数据
- 数据多样性:生成测试数据时,要确保数据的多样性和覆盖面,以模拟真实场景下的各种情况。
- 性能考量:在生成大量数据时,需要考虑脚本的执行效率,避免成为整个数据处理流程的瓶颈。
配置 Kafka
- 集群与分区:合理规划 Kafka 的集群架构和分区数量,以满足数据吞吐量和负载均衡的需求。
- 消息持久性:配置 Kafka 的消息持久化策略,确保数据的可靠性和一致性。
安装 Flume 客户端
- 依赖管理:安装 Flume 时,需要注意其依赖的 Java 环境和其他库的版本兼容性。
- 配置文件编写:Flume 的配置文件编写需要细致,确保数据源、处理器和数据存储的配置正确无误。
任务五:配置 Flume 采集数据
- 数据源适配:根据数据源的不同,选择合适的 Flume 源适配器,以实现高效的数据采集。
- 数据转换:在数据采集过程中,可能需要对数据进行格式化或转换,以适配下游的处理系统。
- 容错与恢复:配置 Flume 的容错和恢复机制,确保在发生故障时能够快速恢复数据采集。
