
数据采集与融合技术-第三次实践作业
作业1
要求:要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总下载的图片数量(学号尾数后2位)限制爬取的措施。
| Gitee链接 |
|---|
| https://gitee.com/xiaoaibit/102202131_LX/tree/master/homework3/demo1 |
单线程爬虫代码
import requests
import scrapy
from demo1.items import ImgItem
class FZuSpider(scrapy.Spider):
name = "FZu"
allowed_domains = ["news.fzu.edu.cn"]
start_urls = ["https://news.fzu.edu.cn/fdyw.htm"]
def parse(self, response):
imgs= response.xpath("//img/@src").extract()
for img in imgs:
item = ImgItem()
item['img_url'] = response.urljoin(img).split('?')[0]
item['img'] = requests.get(response.urljoin(img)).content
yield item
part_url = response.xpath("//span[@class = 'p_no_d']/following-sibling::*[position() = 1]/a/@href").extract_first()
next_url = response.urljoin(part_url)
yield scrapy.Request(url=next_url,callback=self.parse)
多线程爬虫代码
import requests
import scrapy
from demo1.items import ImgItem
class FZuSpider1(scrapy.Spider):
name = "FZu1"
allowed_domains = ["news.fzu.edu.cn"]
start_urls = ["https://news.fzu.edu.cn/fdyw.htm"]
def parse(self, response):
imgs= response.xpath("//img/@src").extract()
for img in imgs:
item = ImgItem()
item['img_url'] = response.urljoin(img).split('?')[0]
item['img'] = requests.get(response.urljoin(img)).content
yield item
part_url = response.xpath("//span[@class = 'p_no_d']/following-sibling::*[position() = 1]/a/@href").extract_first()
next_url = response.urljoin(part_url)
print(response.xpath("//span[@class = 'p_no_d']/text()").extract_first())
if int(response.xpath("//span[@class = 'p_no_d']/text()").extract_first()) != 10 :
yield scrapy.Request(url=next_url,callback=self.parse)
class FZuSpider2(scrapy.Spider):
name = "FZu2"
allowed_domains = ["news.fzu.edu.cn"]
start_urls = ["https://news.fzu.edu.cn/fdyw/711.htm"]
def parse(self, response):
imgs= response.xpath("//img/@src").extract()
for img in imgs:
item = ImgItem()
item['img_url'] = response.urljoin(img)
item['img'] = requests.get(response.urljoin(img)).content
yield item
part_url = response.xpath("//span[@class = 'p_no_d']/following-sibling::*[position() = 1]/a/@href").extract_first()
next_url = response.urljoin(part_url)
print(response.xpath("//span[@class = 'p_no_d']/text()").extract_first())
if int(response.xpath("//span[@class = 'p_no_d']/text()").extract_first()) != 20:
yield scrapy.Request(url=next_url,callback=self.parse)
class FZuSpider3(scrapy.Spider):
name = "FZu3"
allowed_domains = ["news.fzu.edu.cn"]
start_urls = ["https://news.fzu.edu.cn/fdyw/701.htm"]
def parse(self, response):
imgs= response.xpath("//img/@src").extract()
for img in imgs:
item = ImgItem()
item['img_url'] = response.urljoin(img)
item['img'] = requests.get(response.urljoin(img)).content
yield item
part_url = response.xpath("//span[@class = 'p_no_d']/following-sibling::*[position() = 1]/a/@href").extract_first()
next_url = response.urljoin(part_url)
print(response.xpath("//span[@class = 'p_no_d']/text()").extract_first())
if int(response.xpath("//span[@class = 'p_no_d']/text()").extract_first()) != 30:
yield scrapy.Request(url=next_url,callback=self.parse)
class FZuSpider4(scrapy.Spider):
name = "FZu4"
allowed_domains = ["news.fzu.edu.cn"]
start_urls = ["https://news.fzu.edu.cn/fdyw/691.htm"]
def parse(self, response):
imgs= response.xpath("//img/@src").extract()
for img in imgs:
item = ImgItem()
item['img_url'] = response.urljoin(img)
item['img'] = requests.get(response.urljoin(img)).content
yield item
part_url = response.xpath("//span[@class = 'p_no_d']/following-sibling::*[position() = 1]/a/@href").extract_first()
next_url = response.urljoin(part_url)
print(response.xpath("//span[@class = 'p_no_d']/text()").extract_first())
if int(response.xpath("//span[@class = 'p_no_d']/text()").extract_first()) != 40:
yield scrapy.Request(url=next_url,callback=self.parse)
class FZuSpider5(scrapy.Spider):
name = "FZu5"
allowed_domains = ["news.fzu.edu.cn"]
start_urls = ["https://news.fzu.edu.cn/fdyw/681.htm"]
def parse(self, response):
imgs= response.xpath("//img/@src").extract()
for img in imgs:
item = ImgItem()
item['img_url'] = response.urljoin(img)
item['img'] = requests.get(response.urljoin(img)).content
yield item
part_url = response.xpath("//span[@class = 'p_no_d']/following-sibling::*[position() = 1]/a/@href").extract_first()
next_url = response.urljoin(part_url)
print(response.xpath("//span[@class = 'p_no_d']/text()").extract_first())
if int(response.xpath("//span[@class = 'p_no_d']/text()").extract_first()) != 50:
yield scrapy.Request(url=next_url,callback=self.parse)
class FZuSpider6(scrapy.Spider):
name = "FZu6"
allowed_domains = ["news.fzu.edu.cn"]
start_urls = ["https://news.fzu.edu.cn/fdyw/671.htm"]
def parse(self, response):
imgs= response.xpath("//img/@src").extract()
for img in imgs:
item = ImgItem()
item['img_url'] = response.urljoin(img)
item['img'] = requests.get(response.urljoin(img)).content
yield item
part_url = response.xpath("//span[@class = 'p_no_d']/following-sibling::*[position() = 1]/a/@href").extract_first()
next_url = response.urljoin(part_url)
print(response.xpath("//span[@class = 'p_no_d']/text()").extract_first())
if int(response.xpath("//span[@class = 'p_no_d']/text()").extract_first()) != 60:
yield scrapy.Request(url=next_url,callback=self.parse)
items代码
import scrapy
class ImgItem(scrapy.Item):
img_url = scrapy.Field()
img = scrapy.Field()
pipelines代码
import os
from urllib.parse import urlparse, unquote
class Demo1Pipeline:
def process_item(self, item, spider):
img_url = item['img_url']
img = item['img']
# 解析URL并获取净文件名(去除查询参数)
parsed_url = urlparse(img_url)
path = unquote(parsed_url.path) # 解码路径,以防有特殊字符
filename = os.path.basename(path) # 获取文件名
# 清理文件名,去除非法字符
clean_filename = os.path.splitext(filename)[0] + os.path.splitext(filename)[1]
# 确保images目录存在
img_dir = 'images'
if not os.path.exists(img_dir):
os.makedirs(img_dir, exist_ok=True)
# 构造完整的文件路径
file_path = os.path.join(img_dir, clean_filename)
# 尝试打开文件
try:
with open(file_path, 'wb') as self.file:
self.file.write(img)
except Exception as e:
print(f"无法创建文件:{file_path}, 错误信息:{e}")
return item
结果
心得体会
效率
多线程爬取可以显著提高爬取效率,尤其是在爬取大量图片时。通过并发请求,可以减少等待时间,加快整体爬取速度。
资源消耗
多线程爬取会消耗更多的系统资源,如CPU和内存。在资源有限的情况下,需要合理设置并发请求的数量,以避免系统过载。
反爬虫机制
许多网站都有反爬虫机制,过多的请求可能会触发这些机制,导致IP被封禁。因此,在设计爬虫时,需要考虑到这一点,合理设置请求间隔和并发数量。
错误处理
在爬取过程中,可能会遇到各种错误,如网络错误、404错误等。合理地处理这些错误,可以提高爬虫的稳定性和可靠性。
遵守法律法规
在爬取网站数据时,需要遵守相关法律法规,尊重网站的robots.txt文件,不要对网站造成过大压力。
作业2
要求: 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。候选网站:东方财富网:https://www.eastmoney.com/输出信息:MySQL数据库存储和输出格式如下:表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
| Gitee链接 |
|---|
| https://gitee.com/xiaoaibit/102202131_LX/tree/master/homework3/demo2 |
爬虫代码
import scrapy
from demo2.items import StockItem
class StockSpider(scrapy.Spider):
name = "stock"
allowed_domains = ["www.eastmoney.com"]
start_urls = ["https://quote.eastmoney.com/center/gridlist.html#hs_a_board"]
def parse(self, response):
stocks = response.xpath("//tbody//tr")
for stock in stocks:
item = StockItem()
item['id'] = stock.xpath('.//td[position() = 1]//text()').extract_first()
item['code'] = stock.xpath('.//td[position() = 2]//text()').extract_first()
item['name'] = stock.xpath('.//td[position() = 3]//text()').extract_first()
item['newPrice'] = stock.xpath('.//td[position() = 5]//text()').extract_first()
item['price_change_amplitude'] = stock.xpath('.//td[position() = 6]//text()').extract_first()
item['price_change_Lines'] = stock.xpath('.//td[position() = 7]//text()').extract_first()
item['volume'] = stock.xpath('.//td[position() = 8]//text()').extract_first()
item['turnover'] = stock.xpath('.//td[position() = 9]//text()').extract_first()
item['amplitude'] = stock.xpath('.//td[position() = 10]//text()').extract_first()
item['highest'] = stock.xpath('.//td[position() = 11]//text()').extract_first()
item['lowest'] = stock.xpath('.//td[position() = 12]//text()').extract_first()
item['today'] = stock.xpath('.//td[position() = 13]//text()').extract_first()
item['yesterday'] = stock.xpath('.//td[position() = 14]//text()').extract_first()
yield item
items代码
import scrapy
class StockItem(scrapy.Item):
id = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
newPrice = scrapy.Field()
price_change_amplitude = scrapy.Field()
price_change_Lines = scrapy.Field()
volume = scrapy.Field()
turnover = scrapy.Field()
amplitude = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
使用selenium作为下载中间件
import time
from scrapy.http import HtmlResponse
from selenium import webdriver
class SeleniumMiddleware:
def process_request(self,request,spider):
url = request.url
driver = webdriver.Edge()
driver.get(url)
time.sleep(3)
data =driver.page_source
driver.close()
return HtmlResponse(url=url,body=data.encode('utf-8'),encoding='utf-8',request=request)
pipelines代码
import pymysql
host = '127.0.0.1'
port = 3306
user = 'root'
password = 'yabdylm'
database = 'pycharm'
class Demo2Pipeline:
def __init__(self):
self.con = pymysql.connect(host=host, port=port, user=user, password=password, database=database, charset='utf8mb4')
self.cursor = self.con.cursor()
self.cursor.execute(
"CREATE TABLE IF NOT EXISTS stockData (id Integer,code VARCHAR(255),name VARCHAR(255),newPrice VARCHAR(255),price_change_amplitude VARCHAR(255),price_change_Lines VARCHAR(255), volume VARCHAR(255),turnover VARCHAR(255),amplitude VARCHAR(255),highest VARCHAR(255),lowest VARCHAR(255),today VARCHAR(255),yesterday VARCHAR(255));")
def process_item(self, item, spider):
try:
id = item['id']
code = item['code']
name = item['name']
newPrice = item['newPrice']
price_change_amplitude = item['price_change_amplitude']
price_change_Lines = item['price_change_Lines']
volume = item['volume']
turnover = item['turnover']
amplitude = item['amplitude']
highest = item['highest']
lowest = item['lowest']
today = item['today']
yesterday = item['yesterday']
# 插入数据
self.cursor.execute("""
INSERT INTO stockData VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
""", (id, code, name, newPrice, price_change_amplitude, price_change_Lines, volume, turnover, amplitude,
highest, lowest, today, yesterday))
self.con.commit() # 提交事务
except Exception as e:
print(f"An error occurred: {e}")
return item
def __del__(self):
self.con.close()
结果
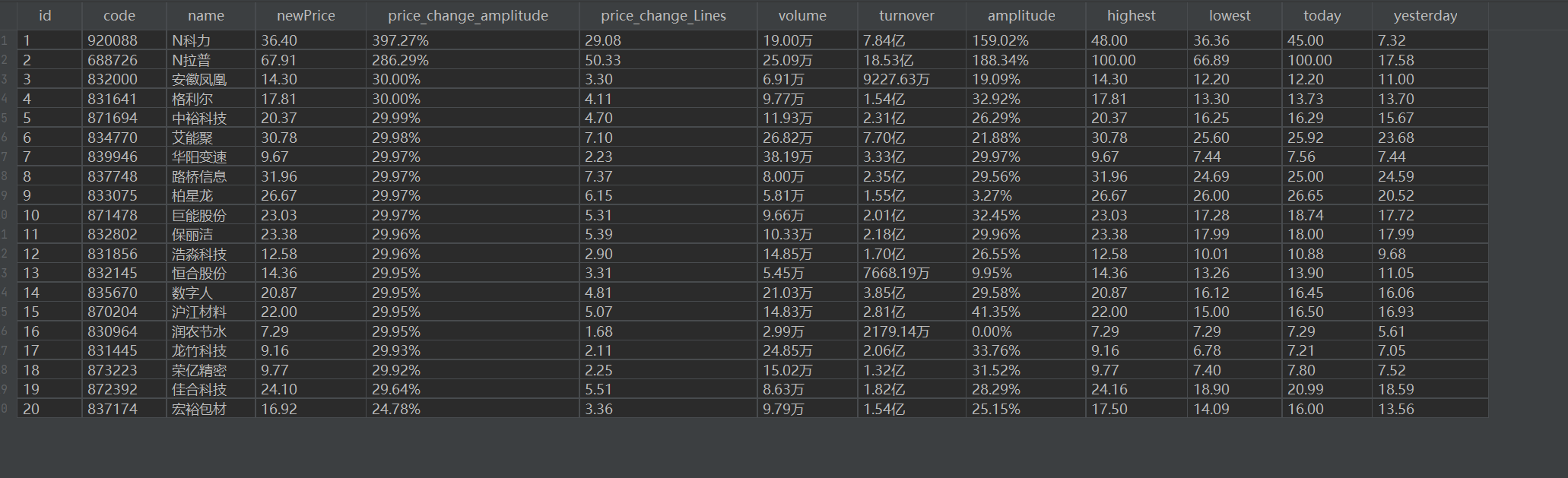
心得体会
项目结构和代码组织:
在开始编写爬虫之前,合理规划项目结构和代码组织是非常重要的。这包括定义Item、Pipelines、Spiders等组件,以及如何组织这些组件的代码文件。良好的代码组织可以提高代码的可读性和可维护性。
Item定义:
定义Item时,需要根据目标网站的数据结构来设计字段。这要求对网站的数据结构有清晰的理解,并且能够预见到未来可能需要的数据字段。在东方财富网的例子中,可能需要定义如股票代码、名称、价格、成交量等字段。
作业3
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
| Gitee链接 |
|---|
| https://gitee.com/xiaoaibit/102202131_LX/tree/master/homework3/demo3 |
爬虫代码
import scrapy
from demo3.items import BankItem
class BankSpider(scrapy.Spider):
name = "bank"
allowed_domains = ["www.boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
banks = response.xpath('//tbody[position() = 1]/tr')
for i in range(2,len(banks) - 2):
bank = banks[i]
item = BankItem()
item['Currency'] = bank.xpath(".//td[position() = 1]//text()").extract_first()
item['TBP'] = bank.xpath(".//td[position() = 2]//text()").extract_first()
item['CBP'] = bank.xpath(".//td[position() = 3]//text()").extract_first()
item['TSP'] = bank.xpath(".//td[position() = 4]//text()").extract_first()
item['CSP'] = bank.xpath(".//td[position() = 5]//text()").extract_first()
item['Time'] = bank.xpath(".//td[position() = 8]//text()").extract_first()
yield item
myDb.closeDB()
items代码
import scrapy
class BankItem(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
selenium中间件代码
import time
from scrapy.http import HtmlResponse
from selenium import webdriver
class SeleniumMiddleware:
def process_request(self,request,spider):
url =request.url
driver = webdriver.Edge()
driver.get(url)
time.sleep(1)
data = driver.page_source
return HtmlResponse(url=url,body=data.encode('utf-8'),encoding='utf-8',reques
pipelines代码
import pymysql
from scrapy.exceptions import DropItem
class BankPipeline:
def __init__(self):
# 这里填写您的数据库配置信息
self.host = 'localhost'
self.database = 'pycharm'
self.user = 'root'
self.password = 'yabdylm'
# 建立数据库连接
self.con = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
charset='utf8mb4' # 使用 utf8mb4 字符集以支持全字符集
)
self.cursor = self.con.cursor()
def process_item(self, item, spider):
# SQL 插入语句
insert_sql = """
INSERT INTO bankData (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
try:
# 执行 SQL 插入语句
self.cursor.execute(
insert_sql,
(
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
)
)
# 提交事务
self.con.commit()
except pymysql.Error as e:
# 如果发生错误,回滚事务
self.con.rollback()
raise DropItem(f"Error inserting row {item!r} into database: {e}")
return item
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.con.close()
结果
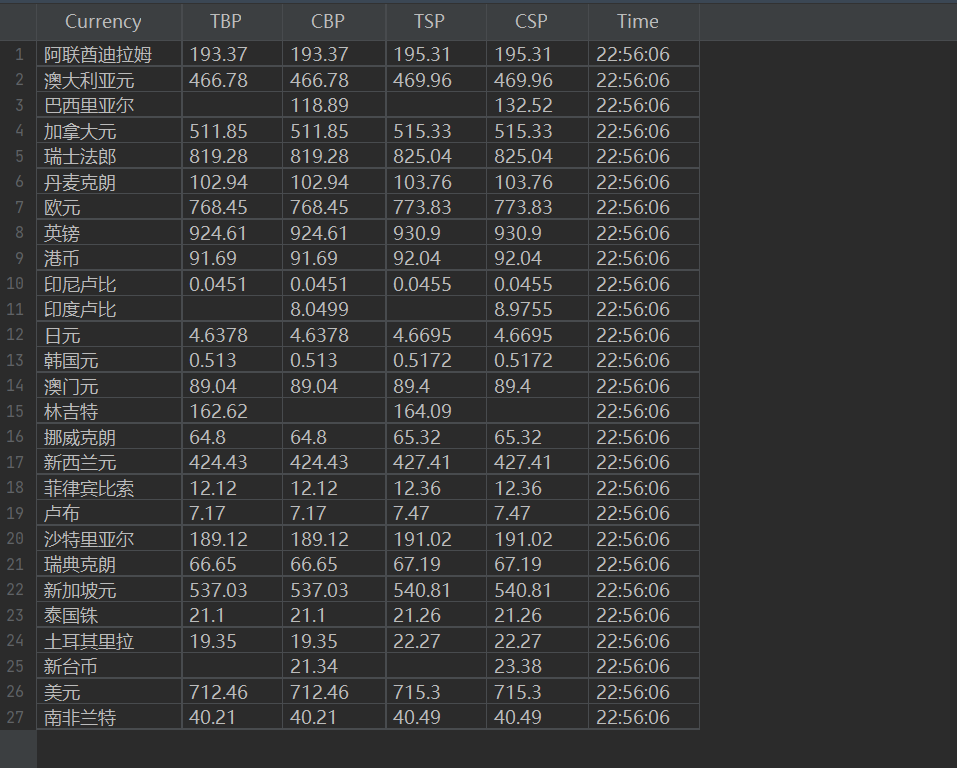
心得体会
Xpath选择器:
使用Xpath选择器提取数据时,需要对Xpath语法有一定的了解。同时,由于网站结构可能会变化,编写的Xpath选择器需要具有一定的灵活性和健壮性,以应对可能的结构变化。
数据清洗和处理:
数据库设计:
设计数据库表结构时,需要考虑到数据之间的关系和查询效率。例如,是否需要设置外键、索引等。同时,表头的英文命名需要符合数据库命名规范,易于理解且避免关键字冲突。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号