数据采集与融合技术-第一次实践作业
作业1
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
# 导入所需的库
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 定义要抓取的网页URL
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 使用requests库发送HTTP GET请求到指定的URL
res = requests.get(url)
# 设置响应的编码为utf-8,以确保中文字符能够正确显示
res.encoding = 'utf-8'
# 使用BeautifulSoup库解析响应内容,这里使用'html.parser'作为解析器
soup = BeautifulSoup(res.text, 'html.parser')
# 选择页面中所有的表格行(tr元素)
rows = soup.select("tbody tr")
# 初始化一个空列表,用于存储抓取的数据
data = []
# 遍历每一行,提取所需的数据
for row in rows:
# 提取排名信息
ranking = row.select("div[class *= 'ranking']")[0].text.strip()
# 提取学校名称
name = row.select("span[class = 'name-cn']")[0].text.strip()
# 提取省市信息
province = row.select("td[data-v-68a1907c]")[3].text.strip()
# 提取学校类型
type_of_institution = row.select("td[data-v-68a1907c]")[4].text.strip()
# 提取总分信息
total_score = row.select("td[data-v-68a1907c]")[5].text.strip()
# 将提取的数据作为一个字典添加到data列表中
data.append({
'排名': ranking,
'学校名称': name,
'省市': province,
'学校类型': type_of_institution,
'总分': total_score
})
# 使用Pandas库创建一个DataFrame,DataFrame是一种表格型数据结构
df = pd.DataFrame(data)
# 打印DataFrame,显示抓取的数据
print(df)
结果
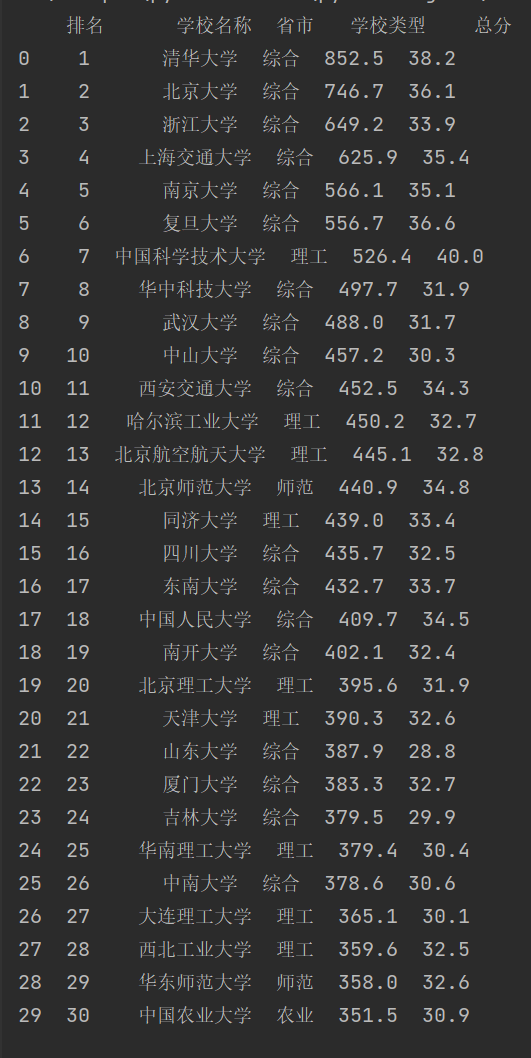
心得体会
HTTP请求
使用requests.get(url)发送GET请求到指定的URL,这是获取网页内容的第一步。设置响应的编码为utf-8,这是处理中文网页时常见的步骤,确保中文字符能够正确显示。
HTML解析
使用BeautifulSoup(res.text, 'html.parser')解析响应内容,这是提取网页数据的关键步骤。BeautifulSoup是一个非常强大的库,可以轻松地导航、搜索和修改解析树,提取所需的数据。
数据提取
通过.select()方法选择页面中所有的表格行(tr元素),这是基于CSS选择器的,非常灵活。遍历每一行,提取排名、学校名称、省市、学校类型和总分信息。这里使用了.select()方法和属性选择器来定位具体的数据。
数据存储
将提取的数据存储在一个字典列表中,每个字典代表一行数据,这是一种常见的数据组织方式。使用pandas.DataFrame创建一个DataFrame,这是一种类似于表格的数据结构,非常适合数据的存储和分析。
数据展示
最后,使用print(df)打印DataFrame,显示抓取的数据。这是查看数据是否正确抓取的直观方式。
作业2
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
import urllib.request
import requests
from bs4 import BeautifulSoup, UnicodeDammit
import time
import random
import re
# 定义要抓取的网页URL
url = 'https://h5api.m.taobao.com/h5/mtop.relationrecommend.wirelessrecommend.recommend/2.0/?jsv=2.7.4.....'
# 随机等待1到4秒,模拟真实用户行为,防止被网站反爬虫机制检测
time.sleep(random.randint(1,4))
# 设置请求头,模拟浏览器访问,绕过简单的反爬虫机制
headers = {
'cookie' : 'cna=8P6xHjo7RWACAdIiO0goTvVj; thw=cn; t=7bdca2220f1dff918bc2ce93590e2772; wk_cookie2=125570f3820cbf9095758ecaa86d9a9e; wk_unb=UUphzOZ6XAYiESGxLQ%3D%3D; lgc=tb396827488; dnk=tb396827488; tracknick=tb396827488; cancelledSubSites=empty; _hvn_lgc_=0; sn=; havana_lgc2_0=eyJoaWQiOjIyMDY0NDM0OTMzMzksInNnIjoiMTZiMDU1ZjZlMmE5MDZiMGJkMmYwYjg3YWZhOThiMTciLCJzaXRlIjowLCJ0b2tlbiI6IjFQTHBtUFpBU1VOUEpkM0N4UTY4eS1RIn0; _cc_=UIHiLt3xSw%3D%3D; 3PcFlag=1728976796693; fastSlient=1728976796711; mtop_partitioned_detect=1; _m_h5_tk=8cde232b458a0bd793a65520b075093a_1729010368860; _m_h5_tk_enc=3ddf762e54352343a8c1e8c56f3244f7; _tb_token_=f33b5ee733e3f; _samesite_flag_=true; sgcookie=E100ZKW2KZgXC0VSOii1QuqZ32WyR10me6a1%2F4uLpXcb%2FhSr%2BVwqQGzBhRZsHSRrLl7asqxHPr8e9pnUIuIFu4OLBDPjq6Lx215tJUOO%2B%2BiRwo2ofey4VRY%2FEBWUBw8%2FVihr; havana_lgc_exp=1760107170239; unb=2206443493339; uc1=pas=0&cookie14=UoYcCoAar%2FYCFg%3D%3D&existShop=false&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&cookie21=VFC%2FuZ9ainBZ&cookie15=VFC%2FuZ9ayeYq2g%3D%3D; uc3=lg2=W5iHLLyFOGW7aA%3D%3D&nk2=F5RGP7frn1bYXxk%3D&vt3=F8dD37nk3RyQOQoWgjI%3D&id2=UUphzOZ6XAYiESGxLQ%3D%3D; csg=c49d42a2; cookie17=UUphzOZ6XAYiESGxLQ%3D%3D; skt=e82ae79d71303ad9; cookie2=12c986eaf64df3f921a093888a1a6644; existShop=MTcyOTAwMzE3MA%3D%3D; uc4=nk4=0%40FY4NCuKlkU0Z2pFTd9pmEfq3pn6%2FNw%3D%3D&id4=0%40U2grF834Ex9bOpEXSbwvNVBscSTUmljz; _l_g_=Ug%3D%3D; sg=890; _nk_=tb396827488; cookie1=VAKFUV%2Fw6zk3Qemx3vEug%2BIqUR%2FWgglh1tb4%2FI6Oaus%3D; sdkSilent=1729089570242; havana_sdkSilent=1729089570242; tfstk=g3fiMLAr_OJ_2hkBcyR_n-yo4-yp5VOXFihvDIK4LH-IXchOuERcYiU6XZr1msxe_K69DhKDiZsuJuF8wN_6GLr827KuHQhWNjoqgmdeLURVw7bsTN_6G2gK08BF5mAhJe72unzHTEYx3IJw72keAEHw0i-wLD8kPI-V0i-ELUYognkwuwReAER20iRqK5kXqGsRTlNgWjSBGOCHSdxP-LGi_j8E23_wxjl4kFvi-N-ngj5hdc92khySJnO9fsYGc7G6_KX5kEjgsfScP6sH8gPmwh7CyTp1_-hJECKMH1S0mxYGeGjXbNoZQUAMjL5wd4cf-KWhtCCacY_d-hJk99eQXKdGjTtWQJZCmwxO01vEjkKAewCwKgrKti9cFZLcj5cN4gJiLYPd9jTUk6kjhd8B-3eUj13569SSZy4nFWJwRFN3-yDjhd8B-3U3-YkeQeT_t; isg=BJeXsO3RvOBLUjlJyQQ_dHy0Jgvh3Gs-ZIWGlunEqGbNGLda8ahhjjM-ejgG60O2',
'Referer': 'https://s.taobao.com/search?...',
'Sec - Ch - Ua': '"Microsoft Edge";v="129", "Not=A?Brand";v="8", "Chromium";v="129"',
'Sec - Ch - Ua - Mobile': '?0',
'Sec - Ch - Ua - Platform': '"Windows"',
'Sec - Fetch - Dest': 'script',
'Sec - Fetch - Mode': 'no-cors',
'Sec - Fetch - Site': 'same-site',
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0',
}
# 发送HTTP GET请求到指定的URL
res = requests.get(url=url, headers=headers)
# 获取响应内容
data = res.text
# 使用UnicodeDammit来处理可能的编码问题,确保中文字符能够正确显示
dammit = UnicodeDammit(data, ['utf-8'])
data = dammit.unicode_markup
# 使用正则表达式提取价格信息
price = r'"SALEPRICE":"(\d+\.\d+)"'
# 使用正则表达式提取商品标题信息
title = r'"ADGTITLE":"([^"]*)"'
# 使用re.findall查找所有匹配的价格和标题
saleprice_match = re.findall(price, data)
adgtitle_match = re.findall(title, data)
# 遍历匹配结果,打印商品的价格和标题
for i in range(len(saleprice_match)):
print("价格:" + saleprice_match[i] + " 商品名:" + adgtitle_match[i])
结果

心得体会
请求头设置
代码中设置了复杂的请求头,包括cookie、Referer、User-Agent等,这些通常用于模拟浏览器行为,以规避简单的反爬虫策略。
随机等待时间
使用time.sleep(random.randint(1,4))添加随机等待时间,这是一种常见的反反爬虫技巧,可以减少被服务器识别为爬虫的风险。
编码处理
使用UnicodeDammit处理响应内容的编码,确保即使服务器返回的内容编码不是UTF-8,也能正确处理并显示中文字符。
正则表达式提取数据
使用正则表达式提取价格和标题信息。这种方法依赖于API返回的数据格式,如果API的返回格式发生变化,正则表达式可能需要更新。
作业3
要求爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
import requests
from bs4 import BeautifulSoup
import os
# 确保URL是正确的
url = "https://news.fzu.edu.cn/yxfd.htm"
res = requests.get(url)
res.encoding = 'utf-8' # 设置响应的编码为utf-8,以确保中文字符能够正确显示
data = res.content
soup = BeautifulSoup(data, 'html.parser') # 使用BeautifulSoup库解析响应内容
# 创建一个文件夹来保存图片,如果文件夹已存在则不进行任何操作
os.makedirs('images', exist_ok=True)
# 选择页面中所有的li元素
rows = soup.select("li")
for row in rows:
# 查找所有后缀为jpg的图片
jpg_images = row.select("img[src $= 'jpg']")
# 查找所有后缀为jpeg的图片
jpeg_images = row.select("img[src $= 'jpeg']")
# 遍历jpg图片
for img in jpg_images:
img_url = img['src'] # 获取图片的URL
img_url = 'https://news.fzu.edu.cn/' + img_url # 确保URL是完整的
img_data = requests.get(img_url).content # 发送GET请求,获取图片数据
with open('images/' + os.path.basename(img_url),'wb') as f: # 以二进制写入模式打开文件
f.write(img_data) # 将图片数据写入文件
# 遍历jpeg图片
for img in jpeg_images:
img_url = img['src'] # 获取图片的URL
img_url = 'https://news.fzu.edu.cn/'+ img_url # 确保URL是完整的
img_data = requests.get(img_url).content # 发送GET请求,获取图片数据
with open('images/' + os.path.basename(img_url),'wb') as f: # 以二进制写入模式打开文件
f.write(img_data) # 将图片数据写入文件
结果
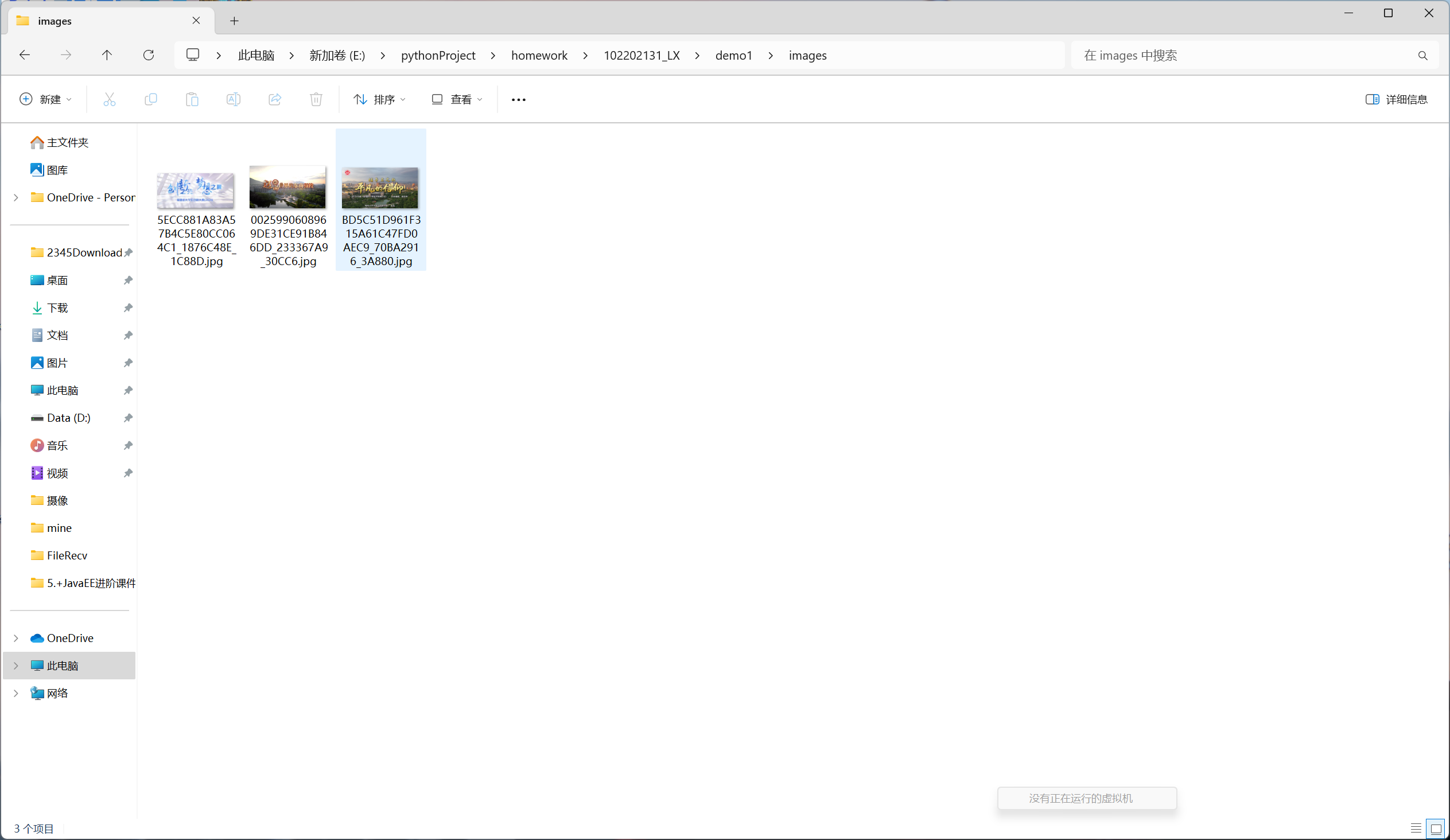
心得体会
请求和编码设置
在进行网页爬取时,首先使用requests库发送HTTP GET请求到指定的URL。设置响应编码为utf-8是关键步骤,这确保了中文字符能够被正确显示。
解析HTML内容
随后,使用BeautifulSoup库解析响应内容。BeautifulSoup是一个功能强大的库,它提供了丰富的方法来导航、搜索和修改解析树,使得数据提取变得简单。
创建保存图片的文件夹
在保存图片之前,使用os.makedirs创建一个名为images的文件夹是一个好习惯。设置exist_ok=True参数可以避免在文件夹已存在时抛出异常。
下载图片
代码遍历页面中的li元素,查找所有后缀为jpg和jpeg的图片,并下载保存到本地文件夹中。这个过程涉及到为每个图片发送GET请求,并以二进制写入模式将图片数据保存到文件中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号