DataFrame基本操作 <一> 删除行,删除列,选择行,选择列,过滤,取行与列的值
基本操作,查询就找这里
首先生成一个dataframe数据
df2 = pd.DataFrame(np.arange(16).reshape((4, 4)), #print(np.arange(20).reshape(4,5)) index=['Qingdao', 'Jinan', 'Yantai', 'Linyi'], columns=['A', 'B', 'C', 'D']) print(df2)
运行结果
A B C D Qingdao 0 1 2 3 Jinan 4 5 6 7 Yantai 8 9 10 11 Linyi 12 13 14 15
删除行
这里用法要注意,这个删除不是在df2的基础上“删除”,是生成了一个信的二维数组。
df2.drop(['Jinan', 'Linyi']) #这里打印df2,是没有任何改变的
a=df2.drop(['Jinan', 'Linyi'])
print(a) #正确的是打印a
a=df2.drop(['Jinan', 'Linyi'],axis=0) #也可以写成这样,axis=0 是确定轴
运行结果
A B C D Qingdao 0 1 2 3 Yantai 8 9 10 11
删除列
同理
a=df2.drop(['B', 'D'], axis=1)
print(a)
运行结果
A C Qingdao 0 2 Jinan 4 6 Yantai 8 10 Linyi 12 14
选择列,多列
print(df2['B'] ) # 选择列,这是一维 print(type(df2['B'])) print(df2[['B', 'C']]) # 选择多列,这是二维 print(type(df2[['B', 'C']]))
运行结果
Qingdao 1 Jinan 5 Yantai 9 Linyi 13 Name: B, dtype: int32 <class 'pandas.core.series.Series'> B C Qingdao 1 2 Jinan 5 6 Yantai 9 10 Linyi 13 14 <class 'pandas.core.frame.DataFrame'>
按照条件过滤
按照条件过滤优先获得的是二维的 #我就是这么理解的就行了,不是获得一个串,是一个面
print(df2)
a=df2[df2['C'] > 5] #这里不太好理解,总之输出的是个二维的
print(a)
运行结果
A B C D Qingdao 0 1 2 3 Jinan 4 5 6 7 Yantai 8 9 10 11 Linyi 12 13 14 15 A B C D Jinan 4 5 6 7 Yantai 8 9 10 11 Linyi 12 13 14 15
为了更好的理解,下边是几个对比
b=df2[df2['C'] > 0] print(b) c=df2[df2['D'] > 8] print(c)
运行结果
A B C D Qingdao 0 1 2 3 Jinan 4 5 6 7 Yantai 8 9 10 11 Linyi 12 13 14 15 #c > 0 A B C D Yantai 8 9 10 11 Linyi 12 13 14 15 #d > 8
数据选取
通过标签索引取行与列
这里loc都是取索引值,也就是说取行的时候用,取列不需要用loc,直接找列的‘name’即可。 行是loc,列是‘name’
df2.loc['Yantai'] # 通过标签索引取行 这里的索引就是用loc获取
print(df2['A']) # 取列,直接用‘name’
df2.loc['Yantai', 'D'] # 通过标签索引同时取行和列 同时取行与列,确定一个点,两条直线相交 df2.iloc[0] # 通过数字标签取行 index【0】的行 df2.iloc[0, [1, 2]] # 通过数字标签同时取行和列 index【0】的行的第【1,2】两个元素
运行结果
A 8 B 9 C 10 D 11 Name: Yantai, dtype: int32
#对比 Qingdao 0 Jinan 4 Yantai 8 Linyi 12 Name: A, dtype: int32 ############## 11 #这里两个条件确定一个点 ############## A 0 B 1 C 2 D 3 Name: Qingdao, dtype: int32 ############## B 1 C 2 Name: Qingdao, dtype: int32
练习:
# 练习,下面这行代码会有什么效果?
df2.loc[:'Yantai', 'B':]
# 练习,取出后三行中 ‘C’ 列 > 5 的那些行,如何写?
理解第一个小练习需要用到切片的知识
这里复习下切片的知识
Python中符合序列的有序序列都支持切片(slice),例如列表,字符串,元组。
格式:【start:end:step】
start:起始索引,从0开始,-1表示结束
end:结束索引
step:步长,end-start,步长为正时,从左向右取值。步长为负时,反向取值
注意切片的结果不包含结束索引,即不包含最后的一位,-1代表列表的最后一个位置索引
那么就很好理解了
a=[1,2,3,'ww',4,5,6,7,'b',8,9] print(a[2:]) print(a[:2]) print(a[1:]) print(a[-1:]) print(a[::-1]) print(df2.loc[:'Yantai', 'B':])
运行结果
[3, 'ww', 4, 5, 6, 7, 'b', 8, 9] [1, 2] [2, 3, 'ww', 4, 5, 6, 7, 'b', 8, 9] [9] [9, 8, 'b', 7, 6, 5, 4, 'ww', 3, 2, 1] B C D Qingdao 1 2 3 Jinan 5 6 7 Yantai 9 10 11
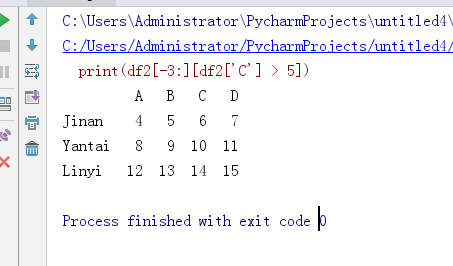
# 练习,取出后三行中 ‘C’ 列 > 5 的那些行,如何写?
print(df2[-3:][df2['C'] > 5])
我是这么想的,但是报警了UserWarning: Boolean Series key will be reindexed to match DataFrame index.
但是结果是对的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号