
Pandas , series 与 Dataframe的创建
Pandas
Pandas 可以说是人见人爱。如果说 Nympy 还有些阳春白雪的话,那么 Pandas 就更接地气!
通过带有标签的列和索引,Pandas 使我们可以以一种所有人都能理解的方式来处理数据。它可以让我们毫不费力地从诸如 csv 类型的文件中导入数据。我们可以用它快速地对数据进行复杂的转换和过滤等操作。
在学习Pandas之前,我们先开启Python绝佳的浏览器学习模式, Jupyter Notebook 。首先进入 Anaconda 的命令行模式,然后在命令行下输入以下指令:
activate study
jupyter notebook
Series & DataFrame
Series
这个可以理解成一维
import numpy as np import pandas as pd from pandas import Series, DataFrame import datetime s1 = pd.Series([1, 3, 5, np.nan, 50, 0]) print(s1)
运行结果
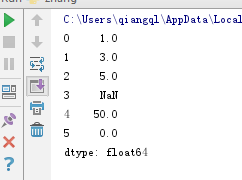
Series 的表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引。于是会自动创建一个0到N-1(N为长度)的整数型索引。
其中NaN是缺省值的意思,这里np.nan是独特的用法,就跟下边np.pi就是π一个意思
还可以通过字典的方式创建序列,字典的键自动成为 Series 的索引。
print(np.pi)
d1 = {'a': 10, 'b': np.nan, 'c': 30, 'd': 0, 'e': np.pi} s2 = pd.Series(d1) print(s2)
运行结果
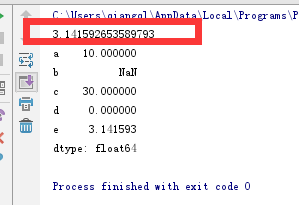
DataFrame
这个理解成二维
创建一个DataFrame
a = np.array([[1, 3, 5, 7], [2, 4, 6, 8], [0, 0, 0, 0]]) rows = ['row1', 'row2', 'row3'] cols = ['one', 'two', 'three', 'four'] df1 = pd.DataFrame(a, index=rows, columns=cols) print(df1) # 练习,通过字典创建一个和上述 df1 一样的 DataFrame # 提示, 通过字典构造 DataFrame 时,其形式是 DataFrame(dict)
运行结果
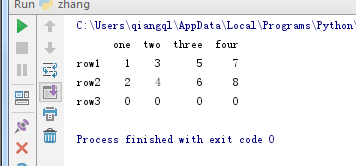
习题答案
d1={'row1':[1,3,5,7],'row2':[2,4,6,8],'row':[0,0,0,0]}
df = pd.DataFrame(d1,index=cols)
print(df)
运行结果
看到这个结果我是崩溃的,可能不是特别熟练,这个也是好几个星期之前学的,没练,咬着牙改成下边这样,但是这么写肯定不对
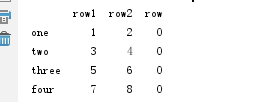
d1={'one':[1,2,0],'two':[3,4,0],'three':[5,6,0],'four':[7,8,0]}
df = pd.DataFrame(d1,index=rows)
print(df)
运行结果


one two three four row1 1 3 5 7 row2 2 4 6 8 row3 0 0 0 0
这里加一个字典创建DataFrame的实例
data = {'state':['Ohino','Ohino','Ohino','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
df = DataFrame(data,index=['one','two','three','four','five'],
columns=['year','state','pop','debt'])
print(df)
运行结果

先到这
别到这了,找到字典构造的方法了
data = {'data':[[1,3,5,7],[2,4,6,8],[0,0,0,0]],
'rows':['row1', 'row2', 'row3'],
'cols': ['one', 'two', 'three', 'four']}
df3 = DataFrame(data['data'],index=['row1', 'row2', 'row3'],
columns=['one', 'two', 'three', 'four'])
print(df3)
运行结果
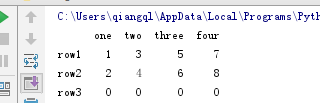
完美!
又找到方法了
d1={'row1':[1,3,5,7],'row2':[2,4,6,8],'row':[0,0,0,0]}
df = pd.DataFrame(d1,index=['one', 'two', 'three', 'four'])
print(df.T)
运行结果
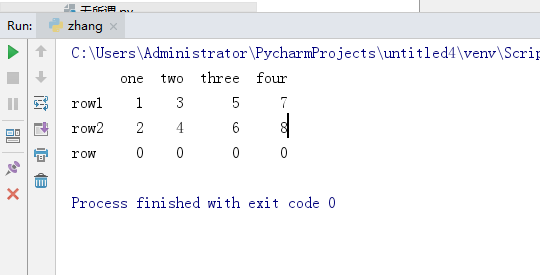
其实都是基础知识,没整理,全给忘了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号