paper sharing :学习特征演化的数据流
特征演化的数据流
数据流学习是近年来机器学习与数据挖掘领域的一个热门的研究方向,数据流的场景和静态数据集的场景最大的一个特点就是数据会发生演化,关于演化数据流的研究大多集中于概念漂移检测(有监督学习),概念/聚类演化分析(无监督学习),然而,人们往往忽略了一个经常出现的演化场景:特征演化。大多数研究都考虑数据流的特征空间是固定的,然而,在很多场景下这一假设并不成立:例如,当有限寿命传感器收集的数据被新的传感器替代时,这些传感器对应的特征将发生变化。
今天要分享的文章出自周志华的实验室《Learning with Feature Evolvable Streams》(NIPS 2017),它提出了一个新的场景,即在数据流中会有特征消亡也会有新特征出现。当出现新的特征空间时,我们并不直接抛弃之前学到的模型并在新的数据上重新创建模型,而是尝试恢复消失的特征来提升模型的表现。具体来说,通过从恢复的特征和新的特征空间中分别学习两个模型。为了从恢复的特征中获得提升,论文中提出了两种集成策略:第一种方法是合并两个模型的预测结果;第二种是选择最佳的预测模型。下面我们具体来理解特征演化数据流以及论文中提出的一些有趣的方法吧~
paper link:https://papers.nips.cc/paper/6740-learning-with-feature-evolvable-streams.pdf
![]() 什么是特征演化数据流?
什么是特征演化数据流?![]()
 什么是特征演化数据流?
什么是特征演化数据流?

在很多现实的任务中,数据都是源源不断收集的,关于数据流学习的研究近年来受到越来越多的关注,虽然已经有很多有效的算法针对特定的场景对数据流进行挖掘,但是它们都基于一个假设就是数据流中数据的特征空间是稳定的。不幸的是,这一假设在很多场景下都不满足。针对特征演化的场景,最直接的想法就是利用新的特征空间的数据学习一个新的模型,但是这一方法有很多问题:首先,当新的特征刚出现的时候,只有很少的数据样本来描述这些信息,训练样本并不足够去学习一个新的模型;其次,包含消失特征的旧模型被直接丢弃了,其中可能包含对当前数据有用的信息。论文中定义了一种特征演化数据流的场景:一般情况下,特征不会任意改变,而在一些重叠时期,新特征和旧特征都存在,如下图所示:
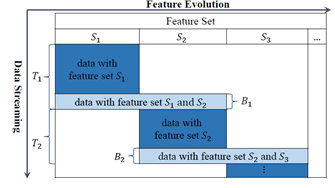
其中,T1阶段,原始特征集都是有效的,B1阶段出现了新的特征集,T2阶段原始特征集消失,只有新的特征集。
论文提出的方法是通过使用重叠(B1)阶段来发现新旧特征之间的关系,尝试学习新特征到旧特征的一个映射,这样就可以通过重构旧特征并使用旧模型对新数据进行预测
![]() 问题描述
问题描述![]()
论文中着重解决的是分类和回归任务,在每一轮学习过程中,对每一个实例进行预测,结合它的真实标签会得到一个loss(反映预测和真实标签的差异),我们将上面提到的T1+B1+T的过程称为一个周期,每个周期中只包含两个特征空间,所以,之后的研究主要关注一个周期内的模型的学习,而且,我们假设一个周期内的旧特征会同时消失。定义Ω1和Ω2分别表示两个特征空间S1和S2上的线性模型,并定义映射 ,定义第i维特征在第t轮的预测函数为线性模型
,定义第i维特征在第t轮的预测函数为线性模型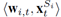 ,
,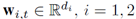 。损失函数是凸的,最直接的方式是使用在线梯度下降来求解w,但是在数据流上不适用。
。损失函数是凸的,最直接的方式是使用在线梯度下降来求解w,但是在数据流上不适用。
![]() 方法介绍
方法介绍![]()
上文提到的基本算法的主要限制是在第1,…T1轮学习的模型在T1+1,…T1+T2时候被忽略了,这是因为T1之后数据的特征空间改变了,我们无法直接应用原来的模型。为了解决这一问题,我们假设新旧特征空间之间有一种特定的关系: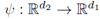 ,我们尝试通过重叠阶段B1来学习这种关系。学习两组特征之间的关系的方法很多,如多元回归,数据流多标签学习等。但是在当前的场景下,由于重叠阶段特别短,学习一个复杂的关系模型是不现实的。所以我们采用线性映射来近似。定义线性映射的系数矩阵为M,那么在B1阶段,M的估计可以基于如下的目标方程:
,我们尝试通过重叠阶段B1来学习这种关系。学习两组特征之间的关系的方法很多,如多元回归,数据流多标签学习等。但是在当前的场景下,由于重叠阶段特别短,学习一个复杂的关系模型是不现实的。所以我们采用线性映射来近似。定义线性映射的系数矩阵为M,那么在B1阶段,M的估计可以基于如下的目标方程:
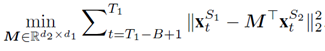
M的最优解可以解得:
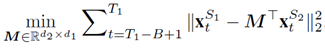
然后,当我观测到S2空间得数据,就可以通过M将其转化到S1空间,并应用旧模型对其进行预测。
除了学习这个关系映射之外,我们得算法主要包括两个部分:
-
在T1-B1+1,…T1阶段,我们学习两个特征空间之间得关系;
-
在T1之后,我们使用新特征空间的数据转化后的原特征空间数据,持续更新旧模型以提升它的预测效果,然后集成两个模型进行预测。
![]() 预测结果集成
预测结果集成![]()
论文中提出两种集成方法,第一种是加权组合,即将两个模型的预测结果求加权平均,权重是基于exponential of the cumulative loss。
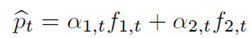
其中

这种权重的更新规则表明,如果上一轮模型的损失较大,下一轮模型的权值将以指数速度下降,这是合理的,可以得到很好的理论结果。
第二种集成方法是动态选择。
上面提到的组合的方法结合了几个模型来提升整体性能,通常来说,组合多个分类器的表现会比单分类器的效果要好,但是,这基于一个重要的假设就是每个基分类器的表现不能太差(如,在Adaboost中,基分类器的预测精度不应低于0.5)。然而在这个问题中,由于新特征空间刚出现的时候训练集较小,训练的模型不好,因此可能并不适合用组合的方法来预测,相反,用动态选择最优模型的方法反而能获得好的效果。

有趣的灵魂在等你 长按二维码识别
长按二维码识别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号