
一文彻底搞定谱聚类
Clustering 聚类
谱聚类
上文我们引入了是聚类,并介绍了第一种聚类算法K-means。今天,我们来介绍一种流行的聚类算法——谱聚类(Spectral Clustering),它的实现简单,而且效果往往好于传统的聚类算法,如k-means,但是其背后的原理涉及了很多重要而复杂的知识,如图论,矩阵分析等。别担心,今天小编就带你一举攻克这些难关,拿下谱聚类算法。
Q:什么是谱聚类?
A:谱聚类是最流行的聚类算法之一,它的实现简单,而且效果往往胜过传统的聚类算法,如K-means。它的主要思想是把所有数据看作空间中的点,这些点之间用带权重的边相连,距离较远的点之间的边权重较低,距离较近的点之间边权重较高,通过对所有数据点和边组成的图进行切图,让切图后不同子图间边权重和尽可能低,而子图内边权重和尽可能高来达到聚类的目的。
接下来我们先介绍图的基础知识以及图拉普拉斯,然后引入谱聚类算法,最后从图分割的角度来解释谱聚类算法。
图的概念
对于一个图G,我们通常用G(V,E)来表示它,其中V代表数据集合中的点{v1,v2,...vn},E代表边集(可以有边相连,也可以没有)。在接下来的内容中我们用到的都是带权重图(即两个顶点vi和vj之间的连边带有非负权重wij>0).由此可以得到一个图的加权邻接矩阵W=(Wij)i,j=1,...n。如果Wij=0代表两个顶点之间无边相连。无向图G中wij=wji,所以权重矩阵是对称的。
对于图中的任意一个点vi,定义它的度为与它相连的所有边的权重之和,即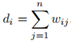 。度矩阵就是对角元素分别为每个点的度,非对角元素为0的矩阵。
。度矩阵就是对角元素分别为每个点的度,非对角元素为0的矩阵。
给定点的一个子集A属于V,定义A的补集为![]() A的指示向量为
A的指示向量为 如果fi=1,则顶点vi在子集A中,否则为0。为了方便,在下文中,我们使用
如果fi=1,则顶点vi在子集A中,否则为0。为了方便,在下文中,我们使用![]() 来表示顶点i在集合A中。对于两个不相交子集A,B属于V,我们定义
来表示顶点i在集合A中。对于两个不相交子集A,B属于V,我们定义![]() 表示两个子集之间的权重和。
表示两个子集之间的权重和。
有两种度量V中子集A大小的方法:|A|表示A中顶点的个数,vol(A)表示A中顶点的度的和。
相似图
思考我们构建相似性图的目的是什么?是为了对点之间的局部邻域关系建模。那么根据我们所关注的邻域关系,相似性图的定义也可以不同,以下提到的图都经常在谱聚类中使用:
ε邻域图:将所有距离小于ε的点相连,由于有边相连的点之间都差不多,加权边不会包含关于图中数据点更多的关系,因此,这种图常常是无权重的;
k近邻图:将vi与它前k近的顶点相连,要注意,这种定义的图是有向图,因为k近邻关系并不是对称的(A是B的k近邻,而B不一定是A的k近邻)。我们可以通过两种方式将它变成无向图:一种是只要A是B的k近邻,AB之间就会连一条边;另一种是必须同时满足A,B是彼此的k近邻,才能在AB之间连一条边。在构建好图之后,在根据点的相似性给边赋权重;
全连接图:任意两点之间都连一条边,并根据两点之间的相似性给边赋权重。由于图必须能代表局部邻居关系,所以使用的相似性度量方法必须能对这种关系建模。比如,高斯相似性方程![]() ,其中参数σ控制邻域的宽度(作用类似ε邻域图中的ε参数)。
,其中参数σ控制邻域的宽度(作用类似ε邻域图中的ε参数)。
图拉普拉斯矩阵及其基本性质
图拉普拉斯矩阵是谱聚类的主要工具,对这些矩阵的研究有一个专门的领域,叫做谱图理论,感兴趣的同学可以去了解下。在这章中我们定义不同的图拉普拉斯并介绍它们最重要的性质。
在接下来的介绍中,我们定义的图G是无向的,带权重的(权重矩阵为W),我们假定所有特征向量都是标准化的(如常向量C和aC是一样的),特征值是有序且可重复的,如果提到了前k个特征向量,就意味着这k个特征向量对应k个最小的特征值。D代表上文提到的度矩阵,W代表权重矩阵。
非规范化图拉普拉斯矩阵:
非规范化图拉普拉斯矩阵定义为L:D-W,它具有如下重要特性:
1. 对于任意特征向量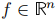 ,有:
,有:
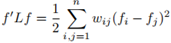 ;
;
证明:
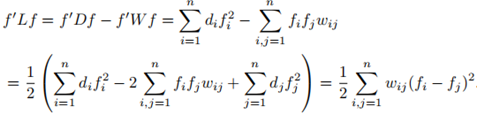
2. L是对称半正定的;
证明:D,W都是对称的,且特性1的证明表明L是半正定的;
3. L的最小特征值是0,对应的特征向量是单位向量;
4. L有n个非负的实值特征向量:
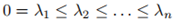
证明:由前三个特性可以直接得出;
注意非规范化图拉普拉斯矩阵以及它的特征向量,特征值可以被用在描述图的很多特性,其中在谱聚类中的一个重要性质如下:
连通分量数与L的普:G是一个非负权重无向图,那么L的特征值0的重数k就等于图中联通分量A1,...Ak的个数,特征值0的特征空间由这些联通分量的指示向量 表示;
表示;
证明:以k=1为例,代表这是一个连通图,假设特征值0对应的特征向量为f,则![]() ,由于权重w是非负的,要使和为0当且仅当每一项都为0。因此,如果两个顶点vi和vj有边相连(wij>0),fi必须等于fj,从这里可以看出如果图中的顶点可以有一条路径相连,那么f必须是常向量。此外,由于无向图中连通分量的所有顶点都可以通过一条路径相连,所以f在整个连通分量上必须是常数。因此在只有一个连通分量的图中,只有一个常向量作为0的特征向量(作为唯一一个联通部分的指示向量)。
,由于权重w是非负的,要使和为0当且仅当每一项都为0。因此,如果两个顶点vi和vj有边相连(wij>0),fi必须等于fj,从这里可以看出如果图中的顶点可以有一条路径相连,那么f必须是常向量。此外,由于无向图中连通分量的所有顶点都可以通过一条路径相连,所以f在整个连通分量上必须是常数。因此在只有一个连通分量的图中,只有一个常向量作为0的特征向量(作为唯一一个联通部分的指示向量)。
现在考虑k大于1的场景,不失一般性,我们假设顶点是按照它们所属的连通分量排序的,在这种情形下,邻接权重矩阵W可以写成分块对角矩阵的形式,同样,L可以写作
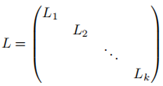
注意,每一个块Li 也是一个图拉普拉斯矩阵,分别对应图的第i个连通分量,L的普就由Li的普组合而成,而且L对应的特征向量就是Li的特征向量。由于Li一个连通图的图拉普拉斯矩阵,而每一个Li有重数为1的特征值0,也就是对应第i个联通子图的常向量。
规范化图拉普拉斯矩阵
规范化图拉普拉斯矩阵有如下两种定义:

我们先来介绍它们的性质:
1. 对任意特征向量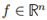 ,我们有:
,我们有:
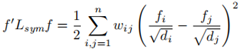 ;
;
2. λ是Lrw的特征向量u的特征值 当且仅当 λ是Lsym的特征向量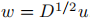 的特征值;
的特征值;
3. λ是Lrw的特征向量u的特征值当且仅当λ和u满足Lu=λDu;
4. 0是Lrw的常数特征向量 的特征值,那么0也是Lsym的特征向量
的特征值,那么0也是Lsym的特征向量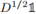 的特征值。;
的特征值。;
5. Lsym和Lrw是半正定的且有n个非负的实特征值;
与非规范化图拉普拉斯矩阵相同,Lsym和Lrw的0特征值的重数k就等于图中联通分量的个数,证明与上面类似,不再赘述。
谱聚类算法
现在我们来介绍最常见的谱聚类算法。
解释:首先构建相似性图,并用W表示权重邻接矩阵,构建度矩阵D,求出拉普拉斯矩阵L;计算L的前m个特征向量,以这m个特征向量作为列组成n*m的矩阵U,其中每一行作为一个m维的样本,共n个,对这n个行向量进行kmeans聚类。
对于规范化的谱聚类有两种不同的版本,依赖于两种标准化图拉普拉斯矩阵。
第一种是:

注意这里使用的是generalized eigenvectors(广义特征向量),即矩阵Lrw对应的特征向量,所以这一算法针对的是标准化的拉普拉斯矩阵Lrw。
下一个算法也是标准化的谱聚类,不过用的是Lsym,该算法介绍了一种额外的行标准化步骤:

上面三种算法的步骤其实都差不多,只不过是使用的拉普拉斯矩阵有差别。在算法中,主要的工作就是将x抽象表征为k维的数据点(降维),接下来我们将揭晓为什么这样做能提高聚类的效果。我们将从图分割的角度来介绍谱聚类的工作原理。
图切分的观点
聚类算法的思想就是根据数据点之间的相似性将它们划分到不同组。当我们的数据以相似性图的形式给出时,聚类问题又可以这样解释:我们想要找到图的一种划分,不同组点的边之间有很低的权重而同一个组中点之间的边有较高的权重。在本节中,我们将介绍如何将谱聚类问题近似于图的划分问题。
给定一个相似性图,邻接权重矩阵W,最简单直接的方法来创建一个图的分割就是解决最小割问题。前面我们已经提到过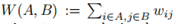 和A的补集的概念。给定子集个数k,最小割方法就是选择一种划分A1,...,Ak使得
和A的补集的概念。给定子集个数k,最小割方法就是选择一种划分A1,...,Ak使得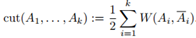 最小。特别是对k=2,最小割问题相对是一个简单的问题,可以被有效地解决。然而在实际中,最小割的解并不能很好地将图划分,因为它只是简单地将一个独立的点从剩余的图中划分出来,这显然不符合聚类的需求。解决这种问题的一种方法是必须保证子集A1,...,Ak足够大,实现这一限制的最常见的目标函数有两种:RatioCut和Ncut。RatioCut用子集A中点的个数表示A的大小,Ncut用子集A中边的权重和来度量A的大小,它们的定义分别如下:
最小。特别是对k=2,最小割问题相对是一个简单的问题,可以被有效地解决。然而在实际中,最小割的解并不能很好地将图划分,因为它只是简单地将一个独立的点从剩余的图中划分出来,这显然不符合聚类的需求。解决这种问题的一种方法是必须保证子集A1,...,Ak足够大,实现这一限制的最常见的目标函数有两种:RatioCut和Ncut。RatioCut用子集A中点的个数表示A的大小,Ncut用子集A中边的权重和来度量A的大小,它们的定义分别如下:
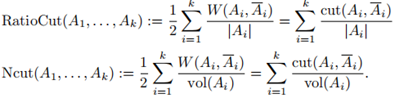
假如簇Ai不是特别小,两个目标函数的值都会有较小的值,因此这两种函数都试图达到聚类的平衡,但是,引入这一“平衡”条件使得之前简单的最小割问题变成了np难问题。谱聚类就是解决这一问题的一种松弛版本,我们将看到松弛Ncut将会导致规范化谱聚类,而松弛RatioCut将导致非标准化谱聚类。
从RatioCut切图的角度解释谱聚类算法
我们先讨论k=2的情形,我们的目标函数是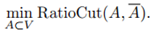 ,首先重写这个问题。给定子集A,我们定义向量
,首先重写这个问题。给定子集A,我们定义向量 ,其中
,其中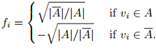
现在RatioCut目标函数可以写作非规范化图拉普拉斯矩阵的形式:
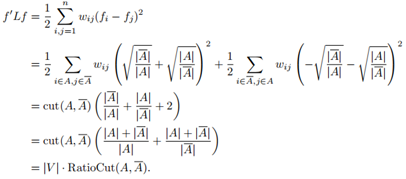
而,
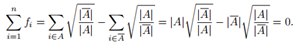
最后,由于f满足
![]()
所以,优化问题重写为:
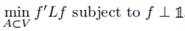
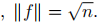
这是一个离散优化问题因为仅允许解向量f中的每一个值只能是两个特殊值,仍是Np难问题。最常用的松弛就是将离散条件改为fi可以取任意实数,松弛后的目标函数为
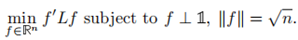
根据Rayleigh-Ritz理论,问题的解f为拉普拉斯矩阵L的第二小的特征值所对应的特征向量(最小的特征值为0,对应常向量)。所以我们可以通过求L的第二特征向量来解决RatioCut问题。然而我们得到的f是实值向量,要把它转化为离散的指示向量,最简单的方式就是使用sign,![]()
推广到k>2的场景,将V划分成k个子集A1,...Ak,我们定义k个指示向量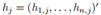 ,其中
,其中![]() 代表每个点的划分情况。定义矩阵
代表每个点的划分情况。定义矩阵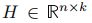 作为以k个指示向量为列向量的矩阵,显然H中的列相互正交
作为以k个指示向量为列向量的矩阵,显然H中的列相互正交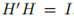 ,于上面的计算类似,我们可以得到
,于上面的计算类似,我们可以得到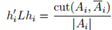 ,进而
,进而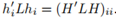 ,然后得到RatioCut问题的定义:
,然后得到RatioCut问题的定义:![]()
Tr表示矩阵的迹,所以最小化RatioCut问题可以写作
![]()
同样的,我们运行H中的取值为任意实数,松弛后的问题为:
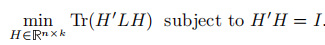
这是迹极小化问题的标准形式,同样根据Rayleigh-Ritz理论,问题的解就是选择包含L的前k个特征向量作为列而组成的H矩阵。其实矩阵H就是上面非标准化谱聚类算法中提到的矩阵U。然后将实值矩阵转化成离散的形式。最后用kmeans对U的每一行进行聚类。
从NCut的角度解释谱聚类算法:
与在RatioCut中用到的相似的技术同样可以用到规范化谱聚类作为最小化Ncut的松弛。当k=2时我们定义聚类的指示向量f中的每个元素为
和上面类似我们可以检查![]() ,
,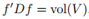 ,以及
,以及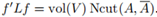 因此,可以重写最小化Ncut问题为
因此,可以重写最小化Ncut问题为
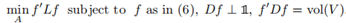
然后对问题进行松弛:
![]()
定义![]() ,有
,有
![]()
其中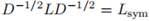 ,
,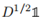 是Lsym的第一特征向量,vol(V)是常数。因此,上述目标函数符合Rayleigh-Ritz理论,最优解g就是Lrw的第二特征向量。
是Lsym的第一特征向量,vol(V)是常数。因此,上述目标函数符合Rayleigh-Ritz理论,最优解g就是Lrw的第二特征向量。
推广到k>2的场景,我们定义指示向量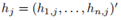 ,且
,且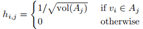
定义H为包含k个指示向量(作为列)的矩阵。显然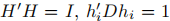 ,
,
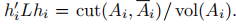
那么最小化Ncut问题可以写作
![]() ,松弛后为
,松弛后为
![]()
这又是一个标准的迹最小化问题,问题的解T是包含Lsym的前k个特征向量为列向量的矩阵。再将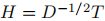 代入,可以发现H包含矩阵Lrw的前k个特征向量。
代入,可以发现H包含矩阵Lrw的前k个特征向量。
谱聚类算法总结
谱聚类的优点:
1. 对于处理稀疏数据的聚类效果很有效;
2. 使用了降维,在处理高维数据聚类时比传统聚类好;
3. 当聚类的类别个数较小的时候,谱聚类的效果会很好;
4. 谱聚类算法建立在谱图理论上,与传统的聚类算法相比,具有能在任意形状的样本空间上聚类且收敛于全局最优解。
谱聚类的缺点:
1. 谱聚类对相似图和聚类参数的选择非常敏感;
2. 谱聚类适用于均衡分类问题,即簇之间点的个数差别不大,对于簇之间点的个数相差悬殊的问题不适用。

扫码关注
获取有趣的算法知识




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· Java 中堆内存和栈内存上的数据分布和特点
· 开发中对象命名的一点思考
· DeepSeek 解答了困扰我五年的技术问题。时代确实变了!
· PPT革命!DeepSeek+Kimi=N小时工作5分钟完成?
· What?废柴, 还在本地部署DeepSeek吗?Are you kidding?
· 赶AI大潮:在VSCode中使用DeepSeek及近百种模型的极简方法
· DeepSeek企业级部署实战指南:从服务器选型到Dify私有化落地