半监督学习(五)——半监督支持向量机
半监督支持向量机(S3VMs)
今天我们主要介绍SVM分类器以及它的半监督形式S3VM,到这里我们关于半监督学习基础算法的介绍暂时告一段落了。之后小编还会以论文分享的形式介绍一些比较新的半监督学习算法。让我们开始今天的学习吧~
引入
支持向量机(SVM)相信大家并不陌生吧?但是如果数据集中有大量无标签数据(如下图b),那么决策边界应该如何去确定呢?仅使用有标签数据学得的决策边界(如下图a)将穿过密集的无标签数据,如果我们假定两个类是完全分开的,那么该决策边界并不是我们想要的,我们希望的决策边界是下图(b)中的黑色实线。

新的决策边界可以很好地将无标签数据分成两类,而且也正确地分类了有标签数据(虽然它到最近的有标签数据的距离比SVM小)。
支持向量机SVM
首先我们来讨论SVMs,为我们接下来要介绍的S3VMs算法做铺垫。为了简单起见,我们讨论二分类问题,即y{-1,1},特征空间为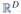 并定义决策边界如下
并定义决策边界如下 其中w是决定决策边界方向和尺度的参数向量,b是偏移量。举个例子,
其中w是决定决策边界方向和尺度的参数向量,b是偏移量。举个例子,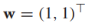 ,b=-1,决策边界就如下图蓝色线所示,决策边界总是垂直于w向量。
,b=-1,决策边界就如下图蓝色线所示,决策边界总是垂直于w向量。

我们的模型为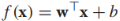 ,决策边界是f(x)=0,我们通过sign(f(x))来预测x的标签,我们感兴趣的是实例x到决策边界的距离,该距离的绝对值为,比如原点x=(0,0)到决策边界的距离为
,决策边界是f(x)=0,我们通过sign(f(x))来预测x的标签,我们感兴趣的是实例x到决策边界的距离,该距离的绝对值为,比如原点x=(0,0)到决策边界的距离为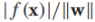 ,如上图中的绿色实线。我们定义有标签实例到决策边界的有符号距离为
,如上图中的绿色实线。我们定义有标签实例到决策边界的有符号距离为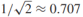 。假设训练数据是线性可分的(至少存在一条线性决策边界正确分类所有的标签数据)。有符号的决策边距是决策边界到距离它最近的有标签数据的距离:
。假设训练数据是线性可分的(至少存在一条线性决策边界正确分类所有的标签数据)。有符号的决策边距是决策边界到距离它最近的有标签数据的距离: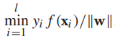 ,如果一个决策边界能分离有标签训练样本,几何边界是正的,我们通过寻找最大几何边距来发现决策边界:
,如果一个决策边界能分离有标签训练样本,几何边界是正的,我们通过寻找最大几何边距来发现决策边界: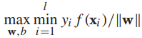 ,这个式子很难直接优化,所以我们将它重写为等价形式。首先我们注意到参数(w,b)可以任意缩放为(cw, cb),所以我们要求最接近决策边界的实例满足:
,这个式子很难直接优化,所以我们将它重写为等价形式。首先我们注意到参数(w,b)可以任意缩放为(cw, cb),所以我们要求最接近决策边界的实例满足: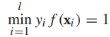 ,接下来,目标方程可以重写为约束优化问题的形式:
,接下来,目标方程可以重写为约束优化问题的形式: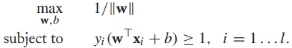 ,而且,最大化1/||w||相当于最小化||w||的平方:
,而且,最大化1/||w||相当于最小化||w||的平方:
到目前为止,我们都是基于训练样本是线性可分的,现在我们放宽这个条件,那么上述目标方程不再满足。我们要对约束条件进行松弛使得在某些实例上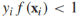 ,同时对这些松弛进行惩罚,重写目标方程为:
,同时对这些松弛进行惩罚,重写目标方程为: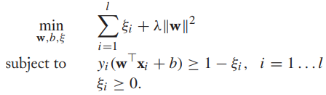
然而,将目标函数转换成一个正则化的风险最小化的形式是有必要的(这关系到我们将其拓展到S3VMs)。考虑这样一个优化问题: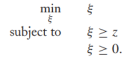
很容易可以看出当z<=0时,目标函数值为0,否则为z,所以可以简写为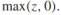
注意 (*)中的约束条件可以重写为
(*)中的约束条件可以重写为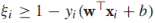 ,利用刚才的结论,我们将(*)重写为
,利用刚才的结论,我们将(*)重写为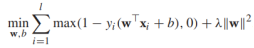
其中第一项代表的是hinge loss损失函数,第二项是正则项。
我们这里不再深入讨论SVMs的对偶形式或者核技巧(将特征映射到更高维度的空间来解决非线性问题),虽然这两个问题是SVMs的关键,但不是我们要介绍的S3VMs的重点(当然也可以将核技巧直接应用到S3VMs上),感兴趣的同学可以去看相关的论文。
半监督支持向量机(S3VMs)
在上文中我们提到用hinge loss来使有标签数据分类尽可能正确,但是如果存在无标签数据呢?没有标签的话就不能知道是否分类正确,就更别提惩罚了。
我们已经学习出来一个标签预测器sign(f(x)),对于无标签样本,它的预测标签为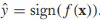 ,我们假定该预测值就是x的标签,那么就可以在x上应用hinge损失函数了
,我们假定该预测值就是x的标签,那么就可以在x上应用hinge损失函数了
我们称它为hat loss。
由于我们标签就是用f(x)生成的,无标签样本总是能被正确分类,然而hat loss 仍然可以惩罚一定的无标签样本。从式子中可以看出,hat损失函数更偏爱 (惩罚为0,离决策边界比较远),而惩罚-1<f(x)<1(特别是趋近于0)的样本,因为这些样本很有可能被分类错误,现在,我们可以写出S3VMs的在有标签和无标签数据上的目标方程:
(惩罚为0,离决策边界比较远),而惩罚-1<f(x)<1(特别是趋近于0)的样本,因为这些样本很有可能被分类错误,现在,我们可以写出S3VMs的在有标签和无标签数据上的目标方程:![]() (**)
(**)
其实我们可以看出来S3VMs的目标方程偏向于将无标签数据尽可能远离决策边界(也就是说,决策边界尽可能穿过无标签数据的低密度区域(是不是像聚类算法的作用))。其实上面的目标方程更像是 正则化的风险最小化形式(在有标签数据上使用hinge loss),其正则化项为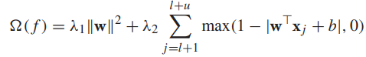
还需要注意的一点是,从经验上来看,(**)的结果是不平衡的(大多数甚至所有的无标签数据可能被分为一个类),造成这种现象的原因虽然还不清楚,为了修正这种错误,一种启发式方法就是在无标签数据上限制预测类的比例与标签数据的比例相同 ,由于是不连续的,所以这个约束很难满足,所以我们对其进行松弛,转化为包含连续函数的约束:
,由于是不连续的,所以这个约束很难满足,所以我们对其进行松弛,转化为包含连续函数的约束: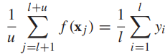 ,
,
完整的S3VMs的目标函数可以写作:
然而,S3VMs算法的目标函数不是凸的,也就是说,他有多个局部优解,这是我们求解目标函数的一个计算难点。学习算法可能会陷入一个次优的局部最优解,而不是全局最优解,S3VMs的一个研究热点就是有效的找到一个近似最优解。
熵正则化
SVMs和S3VMs 不是概率模型,也就是说他们不是通过计算类的后验概率来进行分类的。在统计机器学习中,有很多概率模型是通过计算p(y|x)来进行分类的,有趣的是对于这些概率模型也有一个对S3VMs的直接模拟,叫做entropy regularization。为了使我们的讨论更加具体,我们将首先介绍一个特定的概率模型:逻辑回归,并通过熵正则将它扩展到半监督学习上。
逻辑回归对类的后验概率进行建模,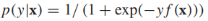 将f(x)的范围从
将f(x)的范围从 规约到[0,1],模型的参数是w和b。给定有标签的训练样本
规约到[0,1],模型的参数是w和b。给定有标签的训练样本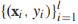 条件对数似然是
条件对数似然是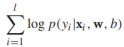 ,假定w服从高斯分布
,假定w服从高斯分布 ,I是对角矩阵,那么逻辑回归模型的训练就是最大化后验概率:
,I是对角矩阵,那么逻辑回归模型的训练就是最大化后验概率: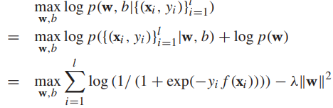
这相当于下面的正则化风险最小化问题: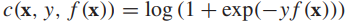
逻辑回归没有使用无标签数据,我们可以加入无标签数据,基于如下准则:如果两个类可以很好的分开,那么在任何无标签样本上的分类都是可信的:要么属于正类要么属于负类。同样,后验概率要么接近于1,要么接近于0.一种度量置信度的方法就是熵,对于概率为p的伯努利随机变量,熵的定义如下:
给定无标签样本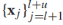 ,可以定义逻辑回归的熵正则化器为:
,可以定义逻辑回归的熵正则化器为: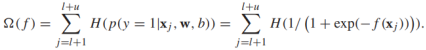
如果未标记实例的分类是确定的,则该值较小。直接将它应用到S3VMs上,我们可以定义半监督的逻辑回归模型:
The assumption of S3VMs
S3VMs和熵正则的假设就是样本的类可以很好的分开,决策边界落在样本特征空间的低密度区域且不会通过密集的未标记数据。如果这个假设不满足,S3VMs可能会导致很差的表现。
小结:
今天我们介绍了SVM分类器以及它的半监督形式S3VM,与我们前面讨论的半监督学习技术不同,S3VMs寻找一个在无标签数据的低密度区间的决策边界。我们还介绍了熵正则化,它是基于逻辑回归的概念模型的。到这里我们关于半监督学习基础算法的介绍暂时告一段落了。之后还会以论文分享的形式介绍一些比较新的半监督学习算法。后面的内容会探索人类和机器学习的半监督学习之间的联系,并讨论半监督学习研究对认知科学领域的潜在影响,敬请期待~!
希望大家多多支持我的公众号,扫码关注,我们一起学习,一起进步~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号