
Redis来啦~~
一. 先聊点别的
1. sql & nosql
sql指关系型数据库,如Oracle,MySQL等,nosql泛指非关系型数据库,如MongoDB,Redis等;SQL数据存在特定结构的表中,而NoSQL则更加灵活和可扩展,存储方式可以是JSON文档,哈希表或其他方式;在sql中必须定义好表和字段结构后才能添加数据,如主键,索引,触发器,存储过程等,表结构虽然可以在定义之后被更新,但是如果有比较大的结构变更的化就会变得比较复杂,在nosql中,数据可以在任何时候任何地方添加,不需要先定义表,nosql也可以在数据集中船舰索引;综上:nosql更加适合初始化数据还不明确或者未定的项目中。
2. ACID & CAP & BASE
ACID是指在数据库管理系统中,事务所具有的四个特性:原子性,一致性,隔离性,持久性;
CAP是指一致性,可用性和分区容错性,CAP理论指这三个要素最多只能实现两个;
BASE接受最终一致性的理论支持,BasicallyAvalable基本可用,Soft-state软状态/柔性事务,EventuallyConsistency最终一致性;
二. Redis:REmote DIctionary Server(远程字典服务器)
1. 什么是Redis?有什么优点?
Redis是存储kv数据结构的分布式数据库;
a. 读写速度快,数据存放在内存中,结构类似于HashMap,HashMap的优势就是查找和操作的时间复杂度是O(1);
b. 支持丰富的数据类型,包括但不限于String,hash,set,zset,list等;
c. 具有丰富的特性,可以用于缓存,消息队列,可以对key设置过期时间,到期后自动删除;
d. 支持数据持久化到硬盘RDB&AOF;
e. 支持主从复制实现数据备份,可以通过哨兵模式自动选举master;
2. Redis和Memcache有什么区别,为什么能够替代它?
a. Memcache的值都是简单字符串,Redis支持更为丰富的数据类型;
b. 虽然都是内存数据库,Redis支持持久化;
c. Redis使用单核,单进程处理客户端请求,对读写事务响应通过epoll函数包装来做到,在大批量文件操作里使用多路IO复用,memcache多核;
d. Memcache 只能采用客户端使用一致性哈希实现分布式存储,Redis还支持在服务器端构建分布式存储——redis集群,保证单点故障下数据可用性,支持主从复制模式;
3. Redis是单线程的为什么还这么快?
a. 数据结构简单,对数据的操作也简单;
b. 避免了不必要的上下文切换和竞争条件,也不存在多进程或多线程导致的切换消耗CPU,不用考虑各种锁的问题;
c. 完全基于内存,绝大部分请求是存粹的内存操作,非常快速。数据在内存中类似HashMap,查找和操作的时间复杂度O(1);
d. 使用多路I/O复用模型,非阻塞IO,多路指多个网络链接的请求,复用是同一个线程;
4. Redis的应用
a. 高速缓存:合理使用缓存不仅可以加速数据访问速度,而且能有效降低后端数据源的压力,Redis提供了过期时间设置,并且提供了灵活控制最大内存和内存溢出后的淘汰机制;
b. 排行榜系统:Redis提供列表和有序集合数据结构,合理的使用这些数据结构可以很方便构建各种排行榜系统;
c. 计数器:使用INCR key可以将key存储的数据+1,如果key不存在,会先初始化为0再+1;
d. 消息队列系统:发布订阅功能和阻塞队列可以实现基本的消息队列功能;
e. Session共享:redis+tomcat+nginx;
5. 安装启动及操作
a. 修改redis.conf,设置后台启动daemonize yes;
b. redis-server /myredis/redis.conf 启动;
c. redis-cli -p 6379 链接;
d. ps -ef | grep redis 看有没有启动;
e. shutdown 关闭;
f. select id 切换DB,默认16个DB;
g. keys * 列出key;
h. flushdb:删除当前数据库所有key
6. key+五大数据类型及操作
a. key : exists kname 有返回1,无返回0;
move key dbid 把key一道dbid数据库中;
expire key 设置key的过期时间;
ttl key 查看key的过期时间, -1 表示永不过期,-2表示已过期;
type key 查看key类型;
del key 删除;
b. String : set/get/del/append/strlen
Incr/decr/incrby/decrby 一定是数字;
getrange/setrange 字符串;
setex/setnx 设置过期时间/set if not exist;
mset/mget/msetnx 批量操作;
c. List: lpush/lpop/rpush/rpop/llen;
lindex 按索引下标获得元素;
lrem key N value 删除N个value;
ltrim key begin end 提取指定范围内的值给key;
rpoplpush 原列表 目的列表;
lset key index value;
linsert key before/after 值1 值2
空value,key消失;
d. Set: sadd/smembers/sismember;
scard 获取集合中的元素;
strem key value 删除元素;
srandmember key 随机出几个数;
spop 随机出栈;
smove key1 key2 x 将key1中的x移到key2;
数学集合:sdiff 差集; sinsert交集;sunion并集;
e. Hash: key对应的value是k-v对;
hset/ hget/ hmset/ hmget/ hgetall/ hdel/ hlen/ hexists key/ hkeys / hvalues/ hincrby/
hincrebyfloat/ hsetnx;
f. zset: 在set的基础上,加一个score值,k1 score1 v1 score2 v2;
zadd key s1 v1 s2 v2;
zrange key 0 -1 (withscore);
zrem key s1 v1 删除s1 v1;
zcard/zcount key score区间;
zscore key 对应值:获得分数;
zrank key values 获取下标值;
zrevrank key values 逆序获取下标值;
zrevrangebyscore key
7. 缓存过期的策略
a. volatile-lru : 使用LRU移除过期时间的key;
b. allkey-lru:使用LRU移除任意key;
c. volatile-random : 过期集合中随机移除key;
d. allkey-random:随机移除任意key;
e. volatile-ttl:移除ttl最小的key;
f. noeviction 永不过期(默认)
8. 持久化
a. RDB:
时间段内的数据集快照存入磁盘,恢复直接将快照读取到内存;Redis会单独fork一个子进程来进行持久化,会先将数据写入一个临时文件中,该临时文件用来替换上次持久化好的文件,主进程不进行任何IO操作;
如果进行大规模数据恢复,但是对数据完整性要求不高,RDB比AOF效率更高;它的缺点是最后一个持久化的数据可能会丢失;
Fork复制一个于当前进程一样的进程,所有数据都和原进程一样,如果原进程很大,fork后可能放不下;
RDB保存的是dump.rdb文件,在配置文件中可以设置 save second changes 持久化的频率,例如,save 120 10就表示2分钟内key修改了10次就会触发RDB持久化操作;指向shutdown指令会自自动生成dump.rdb;
如何触发RDB快照:默认配置;使用命令save(阻塞式)或bgsave(后台操作),flushall也会触发;
b. AOF(Append only file): 以日志形式记录每一个写操作,只许追加不可改写,redis启动之初会读取该文件重新构建数据;
appendfsync机制:Always(同步持久化,一旦更改就写入磁盘,性能差,但是完整性好),EverySec(默认,每秒记录,一秒内如果宕机会造成数据丢失),No不执行持久化;
AOF启动:设置appendonly yes;
正常恢复:将有数据的aof文件复制一份保存到对应目录(config get dir),重启redis后重新加载;
异常恢复:备份被写坏的aof,执行redis-check-aof --fix恢复;
rewrite:文件追加越来越大,大小超过设定的阈值,内容压缩或删除,保存可恢复的最小指令集,可以使用命令bgrewriteaof;原理是fork一条新的进程将文件重写;触发机制是redis会记录上次AOF的大小。默认是当aof文件大小是上次rewrite后大小的一倍(auto-aof-rewrite-percentage 100)且文件大于64M(auto-aof-rewrite-min-size 64m)时触发;
AOF与RDB相比相同数据集的数据而言aof文件远大于rdb,恢复速度慢,且aof运行效率低;但是数据更完整;
c. RDB or AOF? 看需求,RDB在指定时间间隔内对数据进行快照存储,AOF记录每次对服务器写的操作;如果只做缓存,不会持久化;一般同时开启,先加载AOF(更完整),RDB更适合于备份数据库,快速重启,不会有AOF可能存在的bug;
9. Redis事务
a. 事务:可以一次执行多个命令,本质是一组命令的集合,按序串行执行不会被其他命令插入;使用MULTI开启,输入命令到Queue中,EXEC会执行Q中命令,Discard放弃本次任务执行;watch key [key,...] 监视,事务执行前,key不变,unwatch取消所有key的监视;
10. 消息订阅和发布
进程间的通信模式:发送者pub发送消息,订阅者sub接收;
可以一次性订阅多个:subscribe c1 c2 c3;
消息发布:publish c2 hello-redis;
订阅多个:通配符 * 例如 psubscribe new*;
11. Redis主从复制
a. 特性:主机(master:写为主)数据更新后根据配置和策略,自动同步到备机(salves,读为主);读写分离,容灾恢复;配从不配主,从库配置方法:slave of 主库ip 端口;
b. 原理:slave启动成功链接到master后会发送一个sync命令;Master接到命令会启动后台存盘进程,同时收集所有收到的用于修改数据集的命令,在后台进程执行完毕后,master将传送整个数据文件到slave,已完成一次同步;首次同步使用全量复制,只会采用增量复制;
c.缺点是延迟,造成不一致;
d. 可以考虑关闭主服务器数据的持久化功能,只从从服务器进行持久化,从服务器设置为只读模式;
12. 哨兵模式
心跳机制+投票裁决:每个sentinel会向其他sentinel,master,slave定时发送消息,以确定对方是否活着,如果发现对方在指定时间内未响应,则暂时认为对方挂了;若哨兵群中多数都报告某一master没响应,才认为彻底死亡,然后通过vote算法选出新的mster;
在sentinel.conf文件中设置sentinel monitor 主机名 ip 端口 1;
“1”表示主机挂掉后slave投票看谁接替成为主机,投票最多的成为主机;
启动哨兵:Redis-sentinel /myredis/sentinel.conf;
一组sentinel可以监视多个Master;
13. 缓存穿透
指查询一个一定不存在的数据,由于缓存不命中需要从数据库查询你,查不到数据则不写入缓存,导致每次请求该查询都要求数据库查;
解决:对所有可能查询得的参数以hash形式存储,在控制层先进行校验,不符合则丢弃(布隆过滤器将所有可能存在的数据hash到一个足够大的bitmap中);也可以采用如果一个查询返回的数据为空,仍进行缓存,但过期时间很短;
14.缓存雪崩
缓存集中在一段时间内失效,发生大量的缓存穿透,所有查询都落在数据库上
解决:缓存失效后通过加锁或者队列来控制读库写缓存的线程的数量;缓存reload预先更新缓存,在即将发生大的并大访问前手动触发加载缓存;不同的key设置不同的过期时间,让缓存失效的时间点尽量均匀;二级缓存或双缓存策略,A1失效可以访问A2,A1缓存失效时间短,A2长
15. 缓存预热
系统上线后提前将相关的缓存数据直接加载到缓存系统,避免在用户请求时先查询数据库再将数据缓存;
16. 缓存更新
除redis自带的6种缓存失效策略,还可以更具具体的业务进行自定义的缓存淘汰:定时清理过期缓存(维护大量缓存的key比较麻烦);用户请求时先判断所用到的缓存是否过期,过期就去底层系统获取数据。
17. Redis实现分布式锁
在分布式环境下,多个不同的线程需要对共享资源进行同步,那么用java的锁机制就不能实现,这时必须借助分布式锁来解决分布式环境下共享资源的同步问题:redis中提供了一个只有某个key不存在情况下才会设置key值得原子命令setnx,且该命令可以设置过期时间,这样,把获取key的行为当作获取锁,可以保证只有一个线程能够获取到锁且锁会自动过期;但是锁可能在业务执行完成之前过期,所以在设置key的时候,将calue值设置为一个随机的r,释放锁时不直接删除key,而是先getkey判断key对应的value是否等于先前设置的随机值,只有两者相等才删除key,由于是随机值,就不会误释放别的客户端申请的锁了。还有问题?getkey+delkey不是原子操作,还是可能误释放别人的锁,只能使用Lua脚本了,具有原子性。
18. 假如Redis中有1亿个key,其中10w个key以某个固定的已知前缀abc开头,怎么找出来?
使用keys abc*指令可以扫出指定模式的key列表,但是如给redis正在给线上业务提供服务,keys指令会阻塞线程一段时间(redis单线程),这个时候可以使用scan指令,结果可能会有重复,去重就行,时间较keys长。
19. Redis作异步队列
一般使用list结构作为队列,rpush生成消息,lpop消费消息,lpop没有消息时,适当sleep一会再重试或者可以使用blpop阻塞式pop;
能不能一次生产多次消费?使用pub/sub订阅者模式实现1:N的消息队列,缺点是消费者下线,生产的消息会丢失,可以用rabbitmq专业的消息队列;
redis如何实现延迟队列?使用zset,拿时间戳为score,消息内容作为key调用zadd生产消息,消费者用zrangebysocre指令获取n秒之前的数据轮询处理。
20. Redis如何保证一致性?
a. 为什么会不一致?
- 单库情况下,服务层的并发读写,缓存与数据库的操作交叉进行:
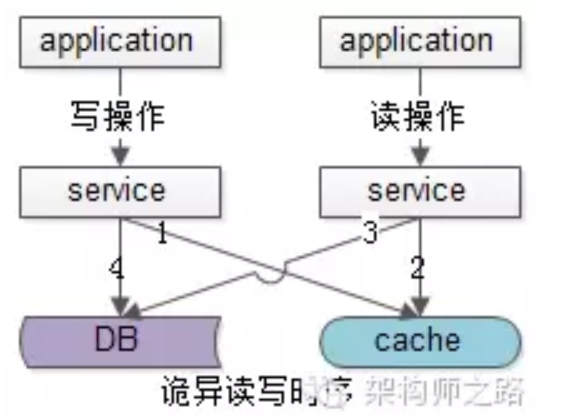
虽然只有一个DB,在上述诡异的异常时序下,可能会载入脏数据到缓存:
1)请求A发起一个写操作,第一步淘汰了cache,这个请求由于各种原因卡在服务层了,如进行大量的业务逻辑计算);
2)请求B发起一个读请求,先会去读缓存,但是读不到;;
3)请求B又去读DB,结果读出来的是一个脏数据,然后又把脏数据放到了redis里面;
4)A卡了很久终于写数据库了,写入了最新的数据,这样,redis和数据库中的数据就不一致了;
b. 主从同步,读写分离的情况下,读从库读到旧数据:
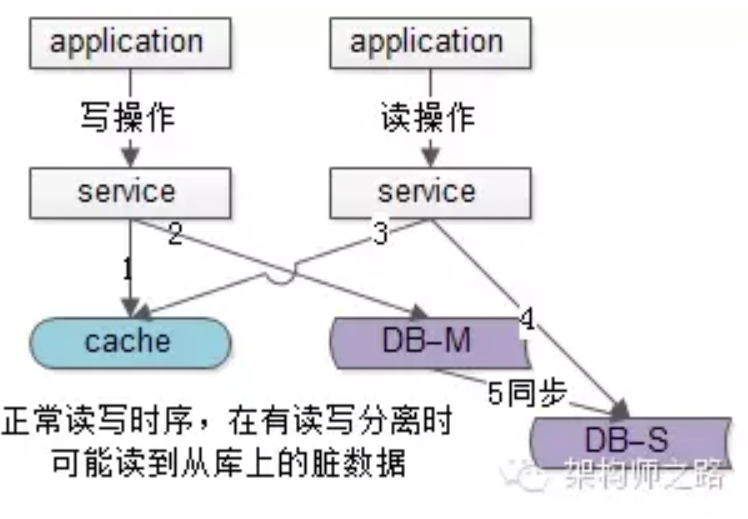
1)请求A发起一个写操作,第一步淘汰了cache;
2)请求A写数据库了,写入最新的数据;
3)请求B发起一个读操作,先去读缓存,没读到;
4)请求3继续读DB,读的是从库,此时主从同步还没有完成,读出的是脏数据,然后脏数据入缓存;
5)最后数据库主从同步完成,缓存和数据库就不一致了。
c. 优化思路:
i. 总结一下上面出现的问题的原因:单库时服务层在进行1s的逻辑计算过程中,可能读到脏数据到缓存,多库时,在1s中主从同步延迟过程中可能读脏数据到缓存,既然脏数据就是在1s时间间隙中入缓存的,是不是可以在写请求完成后,再休眠1s,再次淘汰缓存,就能将1s内写入的脏数据淘汰掉。
- ii. 二次淘汰缓存:
- 写请求的步骤由2步升级为3步:先淘汰缓存,然后写数据库,休眠一秒,再次淘汰缓存;
- 问题:如果所有的写请求都阻塞1s,会大大降低写请求的吞吐量,增加了处理的时间;
- 解决:用一个异步队列timer或者消息总线异步来做这个事情:这样,写请求由2步升级为2。5步:即先淘汰缓存,再写数据库,不再休眠1s,而是往消息总线esb上发送一个消息,发送完了就能立刻返回;然后有一个异步淘汰缓存的消费者,在接收到消息后,asy-expire在1s后淘汰缓存;
- 代价是会增加一次缓存的miss;
- iii. 二次淘汰的优化
- 业务线的写操作增加了一个步骤,为了保证业务线的代码不动,新增一个线下的读binlog的异步淘汰模块,读取到binlog中的数据,异步淘汰缓存。

