
操作系统:内存管理(概念)
1、物理地址和逻辑地址
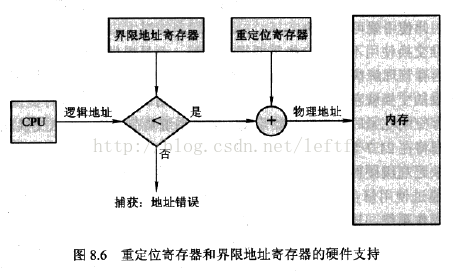
物理地址:加载到内存地址寄存器中的地址,内存单元的真正地址。在前端总线上传输的内存地址都是物理内存地址,编号从0开始一直到可用物理内存的最高端。这些数字被北桥(Nortbridge chip)映射到实际的内存条上。物理地址是明确的、最终用在总线上的编号,不必转换,不必分页,也没有特权级检查(no translation, no paging, no privilege checks)。
逻辑地址:CPU所生成的地址。逻辑地址是内部和编程使用的、并不唯一。例如,你在进行C语言指针编程中,可以读取指针变量本身值(&操作),实际上这个值就是逻辑地址,它是相对于你当前进程数据段的地址(偏移地址),不和绝对物理地址相干。
2、连续内存分配方案:
内存必须容纳操作系统和各种用户进程,因此必须尽可能有效得分配内存,在分配内存过程中,通常需要将多个进程放入内存中,前面提到过,我们需要每个进程的空间相互独立,而且我们必须保护每个进程的内存空间的独立性,如果不同的进程间需要通信,可以按照我们前面提到的通信方法进行通信,但是在此时,我们考虑内存空间独立性的实现。这就涉及到内存分配:
我们将整个内存区域多个固定大小的分区,每个分区容纳一个进程,当一个分区空闲时,可以将内存调入内存,等待执行,这是最简单的内存分配方案,但是这种方案存在很多问题,我们并不知道每个进程需要多大的空间,如果空间过小,那么我们的进程就存不下,如果进程都很小,但是我们分区很大的话,那么会造成很大程度的浪费,这些在每个分区未被利用的空间,我们称之为碎片。
3、分页内存管理方案
(1) 分页的最大作用就在于:使得进程的物理地址空间可以是非连续的。
物理内存被划分为一小块一小块,每块被称为帧(Frame)。分配内存时,帧是分配时的最小单位,最少也要给一帧。在逻辑内存中,与帧对应的概念就是页(Page)。
逻辑地址的表示方式是:前部分是页码后部分是页偏移。
例如,已知逻辑空间地址为2^m个字节(也就是说逻辑地址的长度是m位),已知页大小是2^n字节。那么一共可以有2^(m-n)个页。因此页码部分会占m-n位,之后的n位,用来存储页偏移。
举个例子, 页大小为4B,而逻辑内存为32B(8页),逻辑地址0的页号为0,页号0对应帧5,因此逻辑地址映射为物理地址5*4+0=20。逻辑地址3映射物理地址5*4+3=23。逻辑地址13(4*3+1,页号为3,偏移为1,因此帧号为2),映射到物理地址9。

采用分页技术不会产生外部碎片(内存都被划分为帧),但可能产生内部碎片(帧已经是最小单元,因此帧内部可能有空间没有用到),按概率计算下来,每个进程平均可有半个帧大小的内部碎片。
(2) 页表的硬件实现
上一小节中写到页表是逻辑地址转化到物理地址的关键所在。那么页表如何存储?
每个操作系统都有自己的方法来保存页表。绝大多数都会为每个进程分配一个页表。现在由于页表都比较大,所以放在内存中(以往是放在一组专用寄存器里),其指针存在进程控制块(PCB)里,当进程被调度程序选中投入运行时,系统将其页表指针从进程控制块中取出并送入用户寄存器中。随后可以根据此首地址访问页表。
页表的存储方式是TLB(Translation look-aside buffer, 转换表缓冲区)+内存。TLB实际上是一组硬件缓冲所关联的快速内存。若没有TLB,操作系统需要两次内存访问来完成逻辑地址到物理地址的转换,访问页表算一次,在页表中查找算一次。TBL中存储页表中的一小部分条目,条目以键值对方式存储。
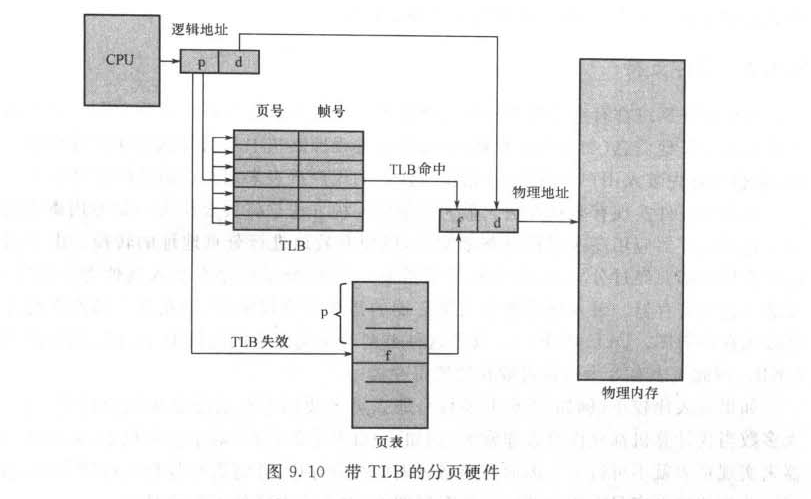
(3) 页表的数据结构
1)层次化分页
现有的笔记本电脑,内存地址空间一般为2^32字节以上。对于具有32位逻辑地址空间的计算机系统,如果系统的页大小为4KB(2^12B),那么页表可以拥有2^(32-12)个,也就是一百多万个条目,假设每个条目占有4B,那每个进程都需要4MB的物理地址空间来存放页表本身。而且,页表本身需要分配在连续内存中。
为此,Hierarchical Paging(层次化分页)被提出,实际上就是将页号分为两部分,第一部分作为索引,第二部分作为页号的偏移。
以一个4kb页大小的32位系统为例。一个逻辑地址被分为20位的页码和12位的页偏移。因为要对页表进行再分页,所以该页号可分为10位的页码和10位的页偏移。这样一个逻辑地址就表示如下形式:

地址转换过程如下:
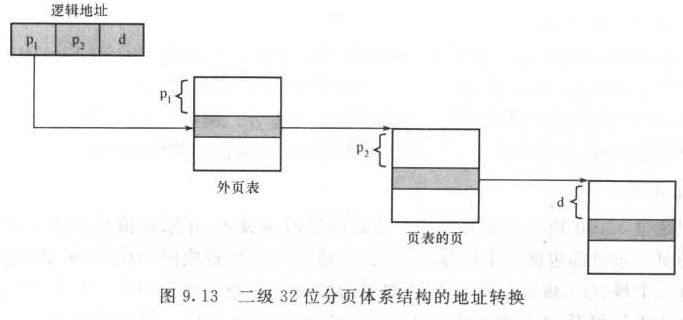
地址由外向内转换,因此此方法也被称为forward-mapped page table(向前映射表)。
2)Hashed Page Tables 哈希页表
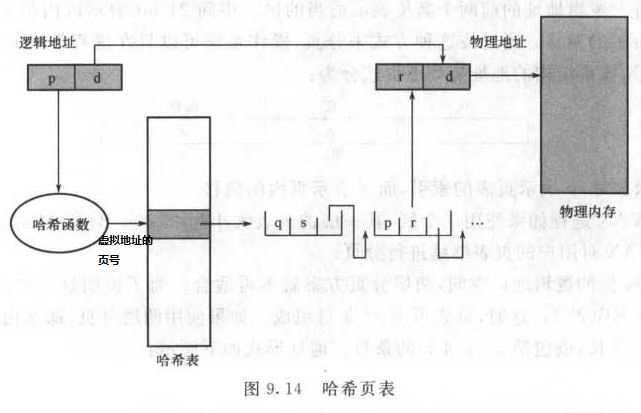
处理超过32位地址空间的常用方法是使用hashed page table(哈希页表),并以虚拟页码作为哈希值。哈希页表的每一条目都包括一个链表的元素,这些元素哈希成同一位置。每个元素有三个域:虚拟页码,所映射的帧号,指向链表中下一个元素的指针。
个人看来,哈希页表的地址转换方式,实际上是Chaining(链接)方式,也就是一种哈希函数的溢出处理方式(另一种溢出处理方式叫做Open Addressing,开放寻址),具体过程如下:
逻辑地址需要大于32bit的地址空间来表示,但是操作系统仍只有32bit来表示地址。此时人们便想到虚拟页地址,虚拟地址可以在32bit表示范围之内,然后利用哈希函数完成逻辑地址到虚拟地址的映射,由于虚拟地址更少,哈希函数会出现溢出,这里使用Chaining来解决溢出。
逻辑地址中的页号(下图中的p)经过哈希函数的计算,算出虚拟地址中的页号,根据虚拟页号可以在哈希表中查找,用p与链表中的每一个元素的第一个域相比较。如果匹配,那么相应的帧号就用来形成物理地址。如果不匹配,就对链表中的下一个节点进行比较,以寻找一个匹配的页号。为什么要存在下一个元素的指针呢??就是因为哈希函数用开放地址法处理碰撞。
3)反向页表
在分页系统中为每个进程配置一张页表,进程逻辑地址空间中的每一页,在页表中都对应有一个页表项。在现代计算机系统中通常允许一个进程的逻辑地址空间非常大,因此就有很多页表项,从而占用很多的内存空间。为了减少页表占用的内存空间而引入了反向页表(Inverted Page Table)。一般页表的表项是按页号进行排序,页表项中的内容是物理块号。而反向页表是为每一个物理块设置一个页表项并将按物理块号排序,其中的内容则是页号及其隶属进程的标志符。
在利用反向页表进行地址变换时,是用进程标志符和页号去检索反向页表;若检索完整个页表都未找到与之匹配的页表项,表明此页此时尚未调入内存,对于具有请求调页功能的存储器系统应产生请求调页中断,若无此功能则表示地址出错;如果检索到与之匹配的表项,则该表项的序号i便是该页所在的物理块号,将该块号与页内地址一起构成物理地址。
虽然反向页表可以有效地减少页表占用的内存,然而该表中却只包含已经调入内存的页面,并未包含那些未调入内存的各个进程的页面,因而必须为每个进程建立一个外部页表(External Page Table),该页表与传统页表一样,当所访问的页面在内存时并不访问这些页表,只是当不在主存时才使用这些页表。该页表中包含了页面在外存的物理位置,通过该页表可将所需要的页面调入内存。
4、分段内存管理方案
采用分页内存管理有一个不可避免的问题:用户视角的内存和实际内存的分离。设想一段main函数代码,里面包含Sqrt函数的调用。按照编写者的理解,这段代码运行时,操作系统应该分配内存给:符号表(编译时使用),栈(存放局部变量与函数参数值),Sqrt代码段,主函数代码段等。这样,编写者就可以方便地指出:"函数sqrt内存模块的第五条指令",来定位一个元素。而实际上,由于采用分页的管理方式,所有的一切都只是散落在物理内存中的各个帧上,并不是以编写者的理解来划分模块。
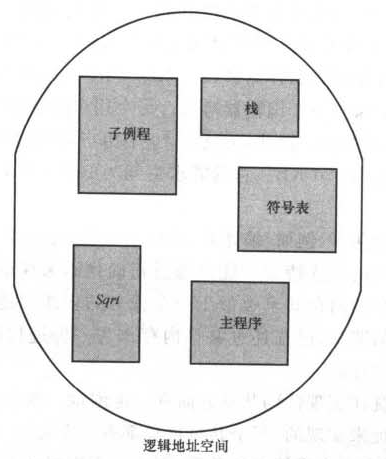
分段的内存管理方式可以支持这种思路。逻辑地址空间由一组段组成。每个段都有名字和长度。地址指定了段名称和段内偏移。因此用户通过两个量来指定地址:段名称和偏移。段是编号的,通过段号而非段名称来引用。因此逻辑地址由有序对构成:
<segment-number,offset>(<段号s, 段内偏移d>)
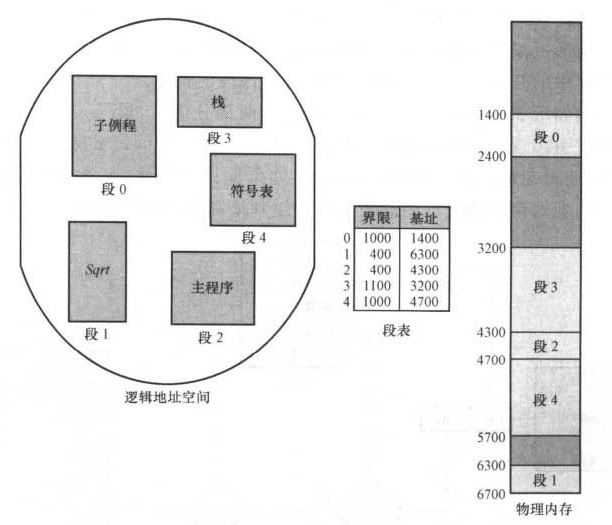
段偏移d因该在0和段界限之间,如果合法,那么就与基地址相加而得到所需字节在物理内存中的地址。因此段表是一组基地址和界限寄存器对。

例如下图,有5个段,编号0~4,例如段2为400B开始于位置4300,对段2第53字节的引用映射成位置4300+53=4353。而段0字节1222的引用则会触发地址错误,因为该段的仅为1000B长(界限为1000)。
本文部分内容参考http://blog.csdn.net/u010953266/article/details/42774117和http://blog.csdn.net/cn_wk/article/details/52736466


