
09 PIE-Hyp非监督分类
PIE-Hyp非监督分类
非监督分类是不加入任何先验知识,利用遥感图像特征的相似性,即自然聚类的特性进行的分类。分类结果区分了存在的差异,但不能确定类别的属性。类别的属性需要通过目视判读或实地调查后确定。
非监督分类包括ISODATA分类、K-Means分类、神经网络聚类、模糊C均值分类、MPC分类和RFCM等分类方法。
1.ISODATA分类
ISODATA(IterativeSelf-OrganizingDataAnalysisTechniqueAlgorithm)即迭代式自组织数据分析技术,其大致原理是首先计算数据空间中均匀分布的类均值,然后用最小距离规则将剩余的像元进行迭代聚合;每次迭代都重新计算均值,且根据所得的新均值,对像元进行再分类;这一处理过程持续到每一类的像元数变化少于所选的像元变化阀值或者达到了迭代的最大次数。
ISODATA算法通过设置初始参数而引入人机对话环节,并使用归并和分裂等机制,当两类聚中心小于某个阀值时,将它们合并为一类。当某类的标准差大于某一阀值时或其样本数目超过某一阀值时,将其分裂为两类,在某类样本数目小于某一阀值时,将其取消。这样根据初始类聚中心和设定的类别数目等参数迭代,最终得到一个比较理想的分类结果。ISODATA算法是一种常用的聚类分析方法,是一种非监督学习方法。
1.1主要内容
通过PIE-Hyp对演示数据进行ISODATA分类操作。
1.2学习目标
-
熟练掌握ISODATA分类基本操作。
1.3使用数据
|
序号 |
数据名称 |
|
1 |
练习数据_Ortho_Sub.tif |
1.4 ISODATA分类操作
在"图像分类"标签下的"非监督分类"组,单击【ISODATA分类】,打开"ISODATA分类"参数设置对话框,如下图所示:
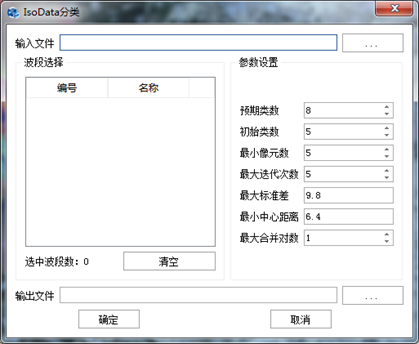
图 ISODATA分类参数设置对话框
-
输入文件:设置待处理的影像;
-
波段选择:选择需要分类的波段,可以选择所有波段,也可以选择部分波段;
-
参数设置:
-
预期类数:期望得到的聚类数,数值越大,图像中分类越详细;
-
初始类数:初始给定的聚类个数;
-
最少像元数:形成一类所需的最少像元数,如果某一类中的像元数小于构成一类所需的最少像元数,该类将被删除,其中的像元被归并到距离最近的类中;
-
最大迭代次数:最大的运行迭代次数(一般6次以上),迭代次数越多,计算耗时越长;
-
最大标准差:如果某一类的标准差比该阈值大,该类将被拆分成两类;
-
最小中心距离:如果两类中心点的距离小于输入的最小值,则类别将被合并;
-
最大合并对数:一次迭代运算中可以合并的聚类中心的最多对数。
-
-
输出文件:设置输出文件保存路径和文件名。
所有参数设置完毕后,点击【确定】按钮即可进行ISODATA分类,并输出分类结果。
1.5操作技巧
暂无。
1.6常见问题
暂无。
1.7复习思考题
(1)使用课程提供的课后练习数据,使用ISODATA算法进行非监督分类,掌握非监督分类的处理过程。
2.K-Means分类
K-Means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
算法首先随机从数据集中选取K个点作为初始聚类中心,然后计算各个样本到聚类中的距离,把样本归到离它最近的那个聚类中心所在的类。计算新形成的每一个聚类的数据对象的平均值来得到新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明样本调整结束,聚类准则函数已经收敛。本算法的一个特点是在每次迭代中都要考察每个样本的分类是否正确。若不正确,就要调整,在全部样本调整完后,再修改聚类中心,进入下一次迭代。如果在一次迭代算法中,所有的样本被正确分类,则不会有调整,聚类中心也不会有任何变化,这标志着已经收敛,因此算法结束。
2.1主要内容
通过PIE-Hyp对演示数据进行K-Means分类操作。
2.2学习目标
-
熟练掌握ISODATA分类基本操作。
2.3使用数据
| 序号 | 数据名称 |
| 1 | 练习数据_Ortho_Sub.tif |
2.4K-Means分类操作
在"图像分类"标签下的"非监督分类"组,单击【K-Means分类】,打开"K-Means分类"参数设置对话框,如下图所示。
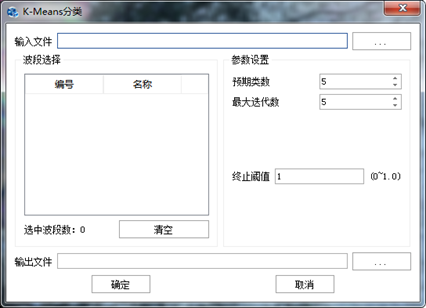
图 K-Means分类参数设置对话框
-
输入文件:设置待处理的影像;
-
波段选择:选择需要分类的波段,可以选择所有波段,也可以选择部分波段;
-
参数设置:
-
预期数类:期望得到的类数,数目越大种类越多,分类越详细;
-
最大迭代次数:迭代运算的最大次数,不满足阈值时,达到该次数算法运行终止,最大迭代次数数值越大,计算耗时越长,分类精度越高;
-
终止阈值:终止运算的阈值,阈值设置越小分类更详细。
-
-
输出文件:设置输出文件保存路径和文件名。
所有参数设置完毕后,点击【确定】按钮即可进行K-Means分类,并输出分类结果。
2.5操作技巧
暂无。
2.6常见问题
问题1:对话框中"终止阈值"的具体含义?
解决办法:"终止阈值"是指小于终止阈值时聚类中心没有任何变化,计算的前后两次聚类中心差值小于该值即认为聚类中心没有任何变化。
2.7复习思考题
(1)使用课程提供的课后练习数据,使用K-Means算法进行非监督分类,掌握非监督分类的处理过程。
3.神经网络聚类
神经网络是模仿人脑神经系统的组成方式与思维过程而构成的信息处理系统,具有非线性、自学性、容错性、联想记忆和可以训练性等特点。在神经网络中,知识和信息的传递是由神经元的相互连接来实现的,分类时采用非参数方法,不需对目标的概率分布函数作某种假定或估计,因此网络具备了良好的适应能力和复杂的映射能力。神经网络的运行包括两个阶段:一是训练或学习阶段(Training or Learning Phase),向网络提供一系列的输入-输出数据组,通过数值计算和参数优化,不断调整网络节点的连接权重和阈值,直到从给定的输入能产生期望输出为止;二是预测(应用)阶段(Generalization Phase),用训练好的网络对未知的数据进行预测。
3.1主要内容
通过PIE-Hyp对演示数据进行神经网络聚类操作。
3.2学习目标
-
熟练掌握神经网络聚类基本操作。
3.3使用数据
| 序号 | 数据名称 |
| 1 | 练习数据_Ortho_Sub.tif |
3.4神经网络聚类操作
在"图像分类"标签下的"非监督分类"组,选择【神经网络聚类】,打开"神经网络聚类"参数设置对话框,如下图所示:
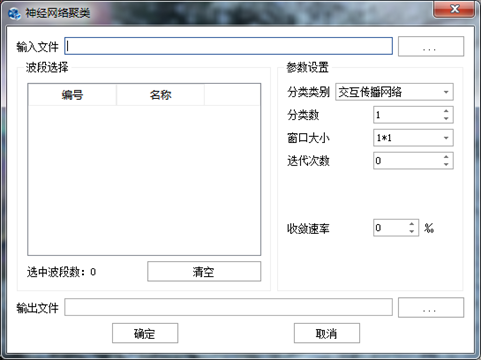
图 神经网络分类参数设置对话框
-
输入文件:设置待处理的影像;
-
波段选择:选择需要分类的波段,可以选择所有波段,也可以选择部分波段;
-
参数设置:
-
分类类别:选择分类规则,有交互传播网络,自组织特征映射网络;
-
分类数:设置分类个数,至少2个;
-
窗口大小:选择分类窗口大小,即1*1、3*3、5*5;
-
迭代次数:迭代运算的最大次数,理论上迭代次数越大,分类结果越准确;
-
收敛速率:设置分类收敛的速率,即连续2次误差的比值的极限。
-
-
输出文件:设置输出文件保存路径和文件名。
所有参数设置完毕后,点击【确定】按钮即可进行神经网络分类,并输出分类结果。
3.5操作技巧
暂无。
3.6常见问题
暂无。
3.7复习思考题
(1)使用课程提供的课后练习数据,使用神经网络聚类算法进行非监督分类,掌握非监督分类的处理过程。
4.模糊C均值
模糊C均值(FCM)算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。模糊C均值算法是普通K均值算法的改进,普通C均值算法对于数据的划分是硬性的,而FCM则是一种柔性的模糊划分。
4.1主要内容
通过PIE-Hyp对演示数据进行模糊C均值操作。
4.2学习目标
-
熟练掌握模糊C均值基本操作。
4.3使用数据
| 序号 | 数据名称 |
| 1 | 练习数据_Ortho_Sub.tif |
4.4模糊C均值操作
在"图像分类"标签下的"非监督分类"组,单击【模糊C均值】,打开"FCM"参数设置对话框,如下图所示:
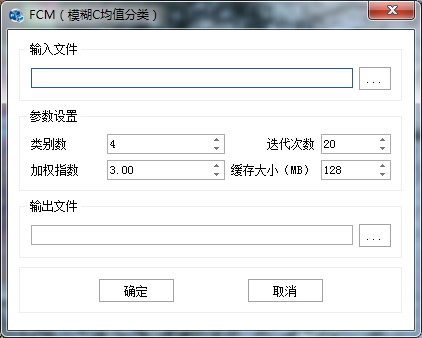
图 FCM分类参数设置对话框
-
输入文件:设置待处理的影像;
-
类别数:高光谱影像中需要进行分类的数目,分类数目设置越大,种类越多,分类结果越详细;
-
迭代次数:算法中计算的迭代次数,迭代次数越大,计算耗时越长,根据分类精度对迭代次数进行取舍调整;
-
加权指数:该值表示"模糊聚类中,模糊类间的分享程度",如果加权指数过大,则聚类效果会比较差,而如果加权指数过小则算法会接近K均值聚类算法,因此该值需要根据实际分类效果进行调整,一般取值范围为[1.5-2.5],默认为2;
-
缓存大小(MB):当分类数据过大时,可以对数据进行分块处理,该值代表分块数据的大小,需要根据当前计算机的配置及输入数据的大小进行设置。默认128,表示分配128MB内存空间进行计算;
-
输出文件:输出分类结果影像。
4.5操作技巧
暂无。
4.6常见问题
暂无。
4.7复习思考题
(1)使用课程提供的课后练习数据,使用模糊C均值算法进行非监督分类,掌握非监督分类的处理过程。
5.MPC分类
高光谱影像中的混合像元是大量存在的,混合像元如果从精确的角度出发不应当被划归为某一个类别。基于混合像元的模糊分类算法(MPC),就是利用端元提取获得相关类别的端元光谱,并进行混合像元丰度反演,获得各像元中不同类别的隶属度,可按照一定规则将其进行分类。
5.1主要内容
通过PIE-Hyp对演示数据进行MPC分类操作。
5.2学习目标
-
熟练掌握MPC分类基本操作。
5.3使用数据
| 序号 | 数据名称 |
| 1 | 练习数据_Ortho_Sub.tif |
5.4MPC分类操作
在"图像分类"标签下的"非监督分类"组,单击【MPC】,打开"MPC"参数设置对话框,如下图所示:
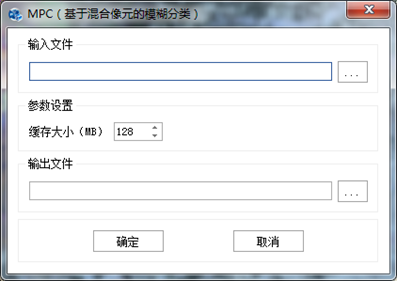
图 MPC分类参数设置对话框
-
输入文件:设置待处理的影像;
-
缓存大小(MB):当分类数据过大时,可以对数据进行分块处理,该值代表分块数据的大小,需要根据当前计算机的配置及输入数据的大小进行设置。默认128,表示分配128MB内存空间进行计算;
-
输出文件:输出分类结果影像。
5.5操作技巧
暂无。
5.6常见问题
问题1:MPC分类对话框中是如何利用端元波谱进行分类的?
解决办法:该功能属于非监督分类算法,不提供端元光谱进行分类。
5.7复习思考题
(1)使用课程提供的课后练习数据,使用MPC算法进行非监督分类,掌握非监督分类的处理过程。
6.RFCM分类
整合空间信息的模糊C均值非监督分类(简称RFCM算法)是在传统C均值聚类基础上,加入空间上下文相关性的一种模糊聚类算法,通过迭代,逐次移动各类的中心,直至达到一定迭代次数或目标函数收敛为止,即得到聚类结果。
6.1主要内容
通过PIE-Hyp对演示数据进行RFCM分类操作。
6.2学习目标
-
熟练掌握RFCM分类基本操作。
6.3使用数据
| 序号 | 数据名称 |
| 1 | 练习数据_Ortho_Sub.tif |
6.4RFCM分类操作
在"图像分类"标签下的"非监督分类"组,单击【RFCM】,打开"RFCM"参数设置对话框,如下图所示:
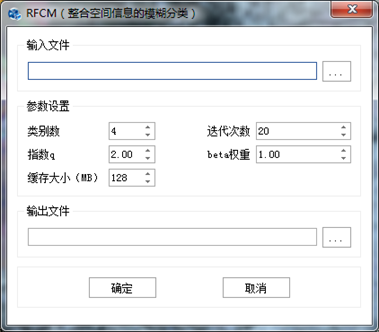
图 RFCM分类参数设置对话框
-
输入文件:设置待处理的影像;
-
类别数:高光谱影像中需要进行分类的数目;
-
迭代次数:算法中计算的迭代次数,迭代次数需要根据分类效果进行调整;
-
指数q:是一个加权指数,一般取值1.5≤q≤2.5(默认为2);
-
Beta权重:Beta为权重系数,可以取值较大的值如1000,Beta默认取值1000;
-
缓存大小(MB):当分类数据过大时,可以对数据进行分块处理,该值代表分块数据的大小,需要根据当前计算机的配置及输入数据的大小进行设置。默认128,表示分配128MB内存空间进行计算;
-
输出文件:输出分类结果影像。
6.5操作技巧
暂无。
6.6常见问题
暂无。
6.7复习思考题
(1)使用课程提供的课后练习数据,使用RFCM算法进行非监督分类,掌握非监督分类的处理过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号