BUAA软工__个人项目作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2020春季计算机学院软件工程(罗杰 任健) (北京航空航天大学 - 计算机学院) |
| 这个作业的要求在哪里 | 个人项目作业 |
| 我的教学班级 | 005 |
| 这个项目的GitHub地址 | https://github.com/LastWhisper1/IntersectionCounter |
PSP项目表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 5 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 180 |
| · Design Spec | · 生成设计文档 | 90 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 90 | 90 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 90 | 180 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 730 | 755 |
从实际结果来看,整个项目的实现时间还是太长了。我码代码的能力果然还是令人捉急,虽然前期有过很复杂的想法,但在具体编码时并没有得到实现,对最后的程序性能也不太满意。虽然不熟悉C++可以作为一部分原因,但总的来说在效率上还是有很大的提升空间,今后还是要加强自己的编码能力,避免有想法而实现不了的情况。
解题思路描述
为了避免各种误差对结果造成的影响,解题中避免了使用浮点数,具体的实现方式上,使用了以下三个类:
1. 直线类Line
直线采用最万能的标准式
来保存,通过给定的两点计算出三个参数即可,并且无需化简。
这个类中还实现了检验两条直线是否平行的函数,由于不考虑重合,只需对两条直线
验证是否成立
即可。
2. 交点类Intersection
题目要求已经确保直线不会重合,通过函数验证两条直线不平行后,方程
的唯一解是
在保存时,分别保存\(x, y\)的分子和分母(都是整数),这样就避免了浮点数导致的精度问题。如果接下去考虑把圆加进来的话,可以再额外保存根式下的分子和分母。但程序中没有实现圆相关的部分,故不再赘述。
3. 交点数统计类Counter
每读入一条直线便与每一条现有直线比较,若两条直线不平行,则计算交点值并放入set容器中,最后将新读入的直线放入vector容器中。这样做的话,如果使用unordered_set,在平均情况下的时间复杂度为\(O(n^{2})\),若使用set则为\(O(n^{2}logn)\)。
在set与unordered_set的选择中,发现程序在输入规模 \(N = 10000\) 时,使用set会导致超过60秒时间限制,但使用unorder_set会导致bad_alloc异常。经过权衡,既然想不到更好的方法提升性能,不如使用set尽可能保证准确性,也能避免使用unorder_set后因hash函数导致的bug。
4. 优化上的一些没实现的想法
程序中,存储和计算交点是必不可少的工作量。对每个交点,如果在计算中,发现直线通过某个交点,那么该直线和通过这个交点的所有直线,都不可能再有其他交点,这样就可以省去和一些直线计算交点的步骤。考虑到性能测试中交点个数\(h\)远小于\(N(N-1)/2\),暗示多线共点的情况较多,那么这种方法能起到比较大的优化作用。
针对平行线的优化可能收效不大,举个例子,若一条直线与一组\(m\)条平行线中的某一条相交,可以知道该直线与该组平行线共产生了\(m\)个交点,但由于存在多线共点的情况,仍需要计算每个交点的位置。
设计实现过程
如上一段所说,我实现了Line,Intersection,Counter三个类,并采用了上面所说的容器。在命令行参数的识别上,采用比较普通的while循环来实现参数的读取和处理。下面主要讲一下使用的测试方法与测试样例的构建。
在构建的单元测试样例中,我做了基本的功能测试和边界测试。在基本的功能测试中,我尽可能测试了每个函数的功能是否正确,包括直线标准式是否正确、交点计算是否正确(也就是Line和Intersection的构造函数),同时构建了几个比较基础的样例测试。在边界测试中,考虑了诸如边界点确定直线、两条直线的交点非常接近的情况进行样例构建,测试结果并没有问题。下面这张图描述了其中一个测试样例的构建:

在性能方面的压力测试中,我另写了一个cpp文件(代码不在git仓库中),使用随机生成的方法构建大量样例。虽然这样生成的直线并不能保证不重合(实际上概率非常小),但在我自己的程序逻辑中,两条直线重合被视为平行,不会引发崩溃性的bug,故在性能测试中可以接受。实际上,随机生成的直线几乎不存在平行或重合的情况,得出的交点数基本都是\(N(N-1)/2\)。
程序性能改进
程序写好以后,实际上并没有做大的框架上的改动,但在细节处理上还是改过很多地方。例如,判断两条直线是否平行的函数和Counter类中插入新直线的函数,由于函数体较为简短,故改成了inline函数提高性能。另外,程序中还尝试使用double代替之前介绍的分数表示方法来存储交点,实际显示性能提升不是那么明显。如下是在使用set容器存储交点集合,\(N = 5000\)时性能测试的截图:
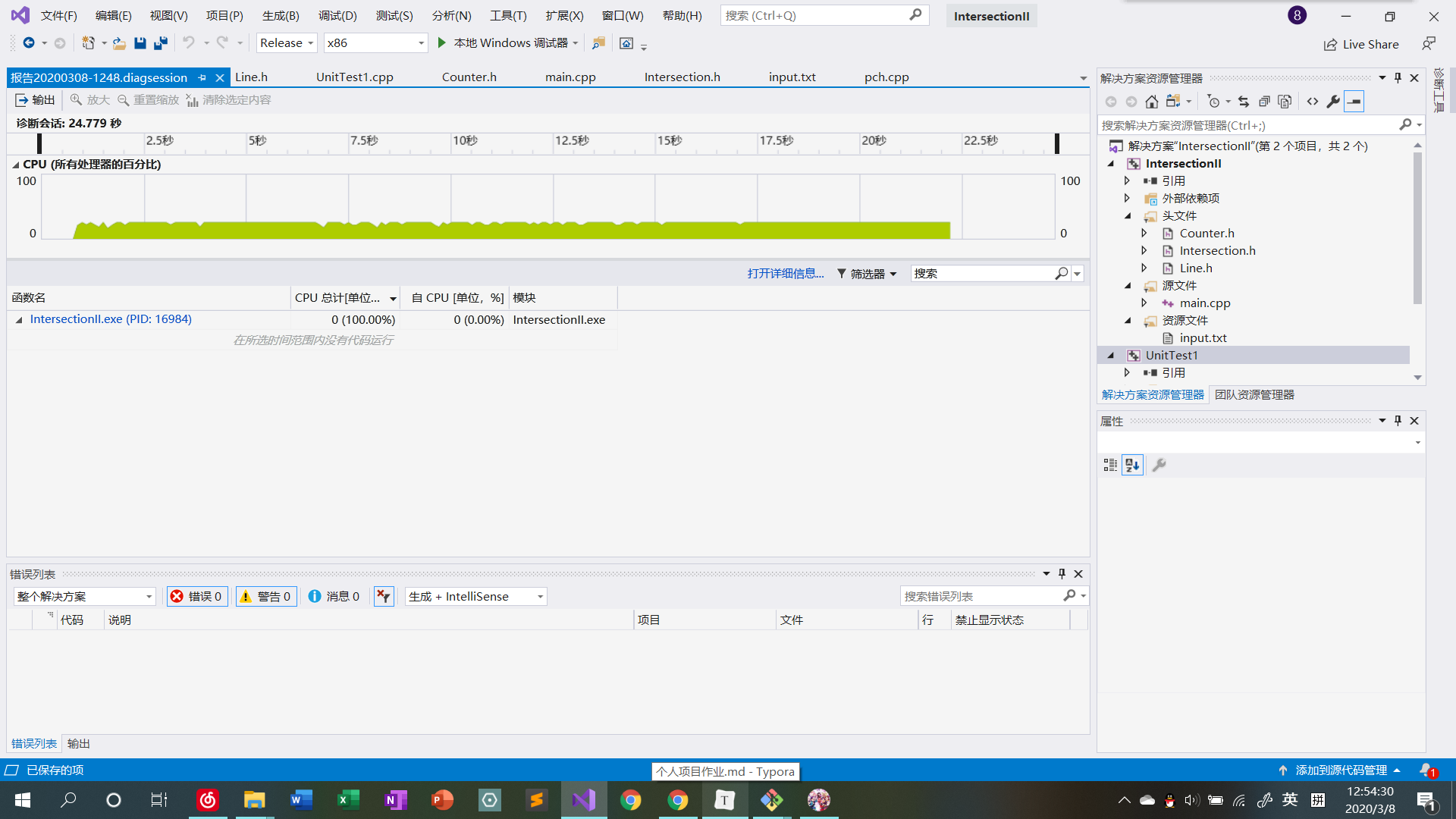
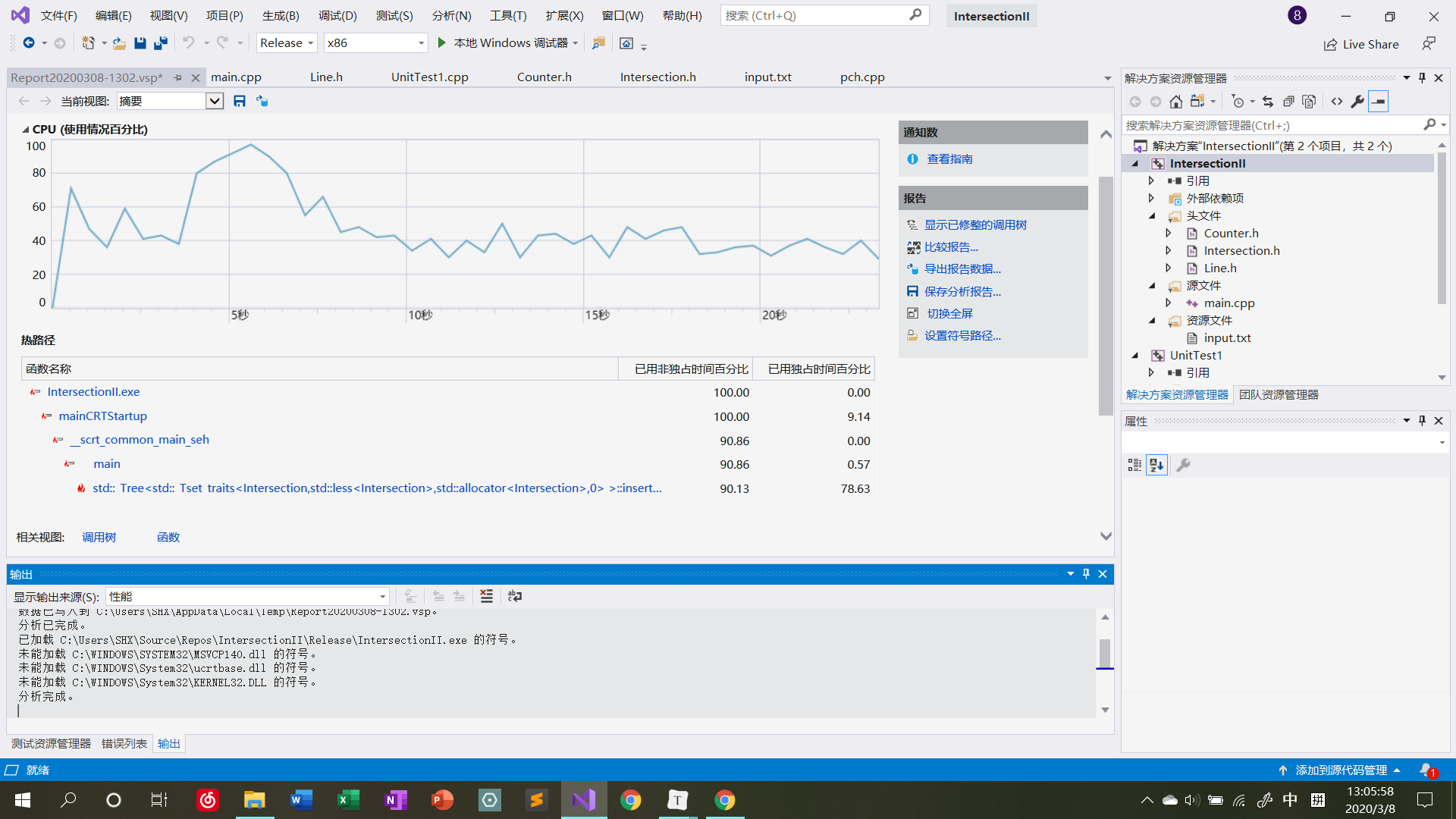
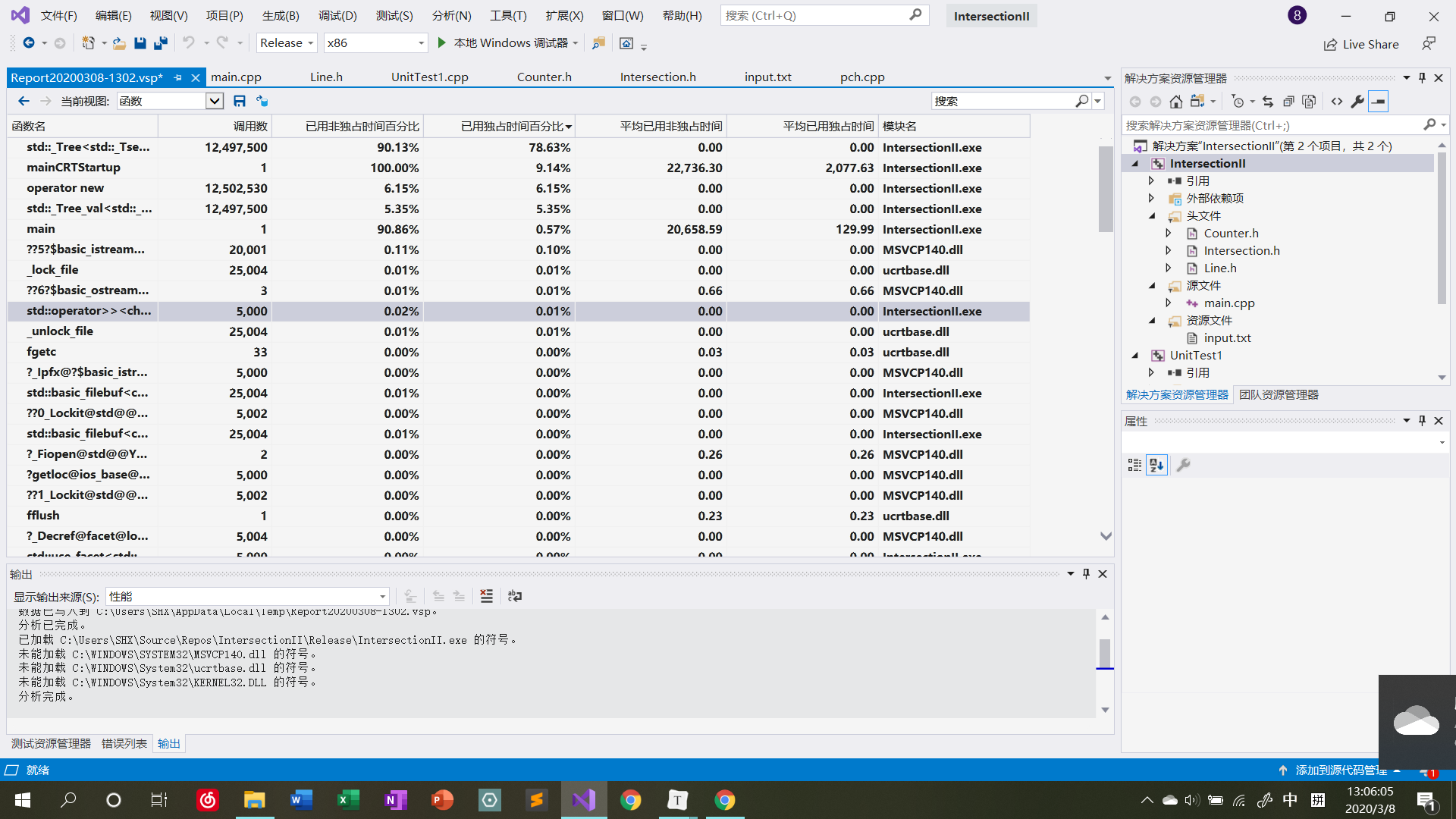
从截图中可以看出,程序运行时间中相当一部分都在set的RB树构建上(当然之前测试的时候也对其他时间占比较大的地方进行了优化)。
若把set替换成unordered_set的话,性能会有比较明显的提升(经测试,在相同\(N\)值下,平均可减少\(1/3\)执行时间),但由于没办法很好解决掉内存分配异常的问题,加上hash函数可能存在错误,故还是采用set容器尽可能保证程序正确性。
关键代码说明
首先展示交点的构造函数,这里的A1, B2等使用了宏定义,对应了两条直线标准式的相应参数,具体含义之前的部分已经提及:
Intersection::Intersection(Line* line1, Line* line2) {
int xnume = C1 * B2 - C2 * B1;
int xdeno = B1 * A2 - B2 * A1;
int ynume = A1 * C2 - A2 * C1;
int ydeno = xdeno;
}
代码中的xnume对应交点x坐标的分子,xdeno对应x的分母,y坐标依此类推。通过分子分母分别存储的方法,避免了浮点数可能带来的精度问题。
下面是整个程序的核心函数CountIntersections:
int Counter::CountIntersections() {
for (size_t i = 0; i < lineSet->size(); i++) {
Line* line1 = lineSet->at(i);
for (size_t j = 0; j < i; j++) {
Line* line2 = lineSet->at(j);
if (!line1->isParallel(line2)) {
Intersection intsec(line1, line2);
intersectionSet->insert(intsec);
}
}
}
return intersectionSet->size();
}
代码的逻辑在上文中已经介绍过了,这段函数中的isParallel()为平行线的判定函数,并写成了内联函数以提高性能。若想要继续提高这个函数的性能,除了将set改成unordered_set之外,只能从循环条件出发,略去一些不必要的交点计算。
Code Quality Analysis截图
还请老师助教提出批评意见。
3/10追记:在和结对搭档对拍程序的时候,发现了比较严重的bug,初步判断是Intersection类中运算符重载错误引起的,但短时间内难以找出消除bug的方法。在之前和搭档对double精度的讨论中,同伴的观点是double精度足够完成实验需求,所以在最后一次提交时,利用程序中预留的宏定义开关将Intersection类改为double实现,直接存储交点x, y坐标的double值(在博客代码的基础上做除法即可得到)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号