thread基本常识内容汇总
1.pthread_setschedparam
man 手册-来自Ubuntu20.04
PTHREAD_SETSCHEDPARAM(3) Linux Programmer's Manual PTHREAD_SETSCHEDPARAM(3) NAME pthread_setschedparam, pthread_getschedparam - set/get scheduling policy and parameters of a thread /*设置/获取线程的调度策略和参数*/ SYNOPSIS #include <pthread.h> int pthread_setschedparam(pthread_t thread, int policy, const struct sched_param *param); int pthread_getschedparam(pthread_t thread, int *policy, struct sched_param *param); Compile and link with -pthread. DESCRIPTION /*pthread_setschedparam()函数用于设置线程的调度策略和参数。*/ The pthread_setschedparam() function sets the scheduling policy and parameters of the thread thread. /*policy指定线程的新调度策略。 sched(7)中描述了策略支持的值及其语义。*/ policy specifies the new scheduling policy for thread. The supported values for policy, and their semantics, are described in sched(7). /*param指向的结构指定线程的新调度参数。 计划参数在以下结构中维护:*/ The structure pointed to by param specifies the new scheduling parameters for thread. Scheduling parameters are maintained in the following structure: struct sched_param { int sched_priority; /* Scheduling priority */ }; /*可以看出,仅支持一个调度参数。 各调度策略中调度优先级的允许范围详见sched(7)。*/ As can be seen, only one scheduling parameter is supported. For details of the permitted ranges for scheduling priorities in each scheduling policy, see sched(7). The pthread_getschedparam() function returns the scheduling policy and parameters of the thread thread, in the buffers pointed to by policy and param, respectively. The returned priority value is that set by the most re‐cent pthread_setschedparam(), pthread_setschedprio(3), or pthread_create(3) call that affected thread. The returned priority does not reflect any temporary priority adjustments as a result of calls to any priority inher‐itance or priority ceiling functions (see, for example, pthread_mutexattr_setprioceiling(3) and pthread_mutexattr_setprotocol(3)). /** pthread_getschedparam()函数返回线程的调度策略和参数,分别位于policy和param所指向的缓冲区中。 返回的优先级值是由受影响线程的最新pthread_setschedparam()、pthread_setschedprio(3)或pthread_create(3)调用设置的。 返回的优先级不反映调用任何优先级继承或优先级上限函数所导致的任何临时优先级调整 (参考例如,pthread_mutexattr_setprioceiling(3)和pthread_mutexattr_setprotocol(3))。 */ RETURN VALUE On success, these functions return 0; on error, they return a nonzero error number. If pthread_setschedparam() fails, the scheduling policy and parameters of thread are not changed. /*成功时,这些函数返回0;出错时,它们返回一个非零的错误数字。 如果pthread_setschedparam()失败,线程的调度策略和参数不会改变。*/ ERRORS Both of these functions can fail with the following error: ESRCH No thread with the ID thread could be found. pthread_setschedparam() may additionally fail with the following errors: EINVAL policy is not a recognized policy, or param does not make sense for the policy. EPERM The caller does not have appropriate privileges to set the specified scheduling policy and parameters. POSIX.1 also documents an ENOTSUP ("attempt was made to set the policy or scheduling parameters to an unsupported value") error for pthread_setschedparam(). /* 这两个函数都可能失败,并出现以下错误: ESRCH 找不到具有此ID的线程。 pthread_setschedparam()也可能失败,并出现以下错误: EINVAL 策略不是可识别的策略,或者param对于该策略没有意义。 EPERM 调用方没有适当的权限来设置指定的调度策略和参数。 POSIX.1还记录了pthread_setschedparam()的ENOTALK(“尝试将策略或调度参数设置为不受支持的值”)错误。 */ ATTRIBUTES For an explanation of the terms used in this section, see attributes(7). ┌─────────────────────────┬───────────────┬─────────┐ │Interface │ Attribute │ Value │ ├─────────────────────────┼───────────────┼─────────┤ │pthread_setschedparam(), │ Thread safety │ MT-Safe │ │pthread_getschedparam() │ │ │ └─────────────────────────┴───────────────┴─────────┘ CONFORMING TO POSIX.1-2001, POSIX.1-2008. NOTES /*有关更改线程的调度策略和优先级所需的权限和影响的描述,以及每个调度策略中优先级的允许范围的详细信息,请参见sched(7)。*/ For a description of the permissions required to, and the effect of, changing a thread's scheduling policy and priority, and details of the permitted ranges for priorities in each scheduling policy, see sched(7). EXAMPLE /*下面的程序演示了pthread_setschedparam()和pthread_getschedparam()的用法,以及许多其他与线程相关的pthreads函数的用法。*/ The program below demonstrates the use of pthread_setschedparam() and pthread_getschedparam(), as well as the use of a number of other scheduling-related pthreads functions. /* 在接下来的运行中,主线程将其调度策略设置为优先级为10的SCHED_FIFO,并使用调度策略属性SCHED_RR和调度优先级属性20来初始化线程属性对象。 然后,程序将线程属性对象的inheritsched属性设置(使用pthread_attr_setinheritsched(3))为PTHREAD_EXPLICIT_SCHED, 这意味着使用此属性对象创建的线程应从线程属性对象中获取其调度属性。 然后,程序使用线程属性对象创建一个线程,该线程将显示其调度策略和优先级。 */ In the following run, the main thread sets its scheduling policy to SCHED_FIFO with a priority of 10, and initializes a thread attributes object with a scheduling policy attribute of SCHED_RR and a scheduling priority at‐ tribute of 20. The program then sets (using pthread_attr_setinheritsched(3)) the inherit scheduler attribute of the thread attributes object to PTHREAD_EXPLICIT_SCHED, meaning that threads created using this attributes object should take their scheduling attributes from the thread attributes object. The program then creates a thread using the thread attributes object, and that thread displays its scheduling policy and priority. $ su # Need privilege to set real-time scheduling policies Password: # ./a.out -mf10 -ar20 -i e Scheduler settings of main thread policy=SCHED_FIFO, priority=10 Scheduler settings in 'attr' policy=SCHED_RR, priority=20 inheritsched is EXPLICIT // ----> 不同之处 Scheduler attributes of new thread policy=SCHED_RR, priority=20 /*在上面的输出中,可以看到调度策略和优先级取自线程属性对象中指定的值。*/ In the above output, one can see that the scheduling policy and priority were taken from the values specified in the thread attributes object. /*下一次运行与上一次运行相同,只是继承调度程序属性设置为PTHREAD_INHERIT_SCHED,这意味着使用线程属性对象创建的线程应忽略属性对象中指定的调度属性,而是从创建线程获取其调度属性*/ The next run is the same as the previous, except that the inherit scheduler attribute is set to PTHREAD_INHERIT_SCHED, meaning that threads created using the thread attributes object should ignore the scheduling at‐ tributes specified in the attributes object and instead take their scheduling attributes from the creating thread. # ./a.out -mf10 -ar20 -i i Scheduler settings of main thread policy=SCHED_FIFO, priority=10 Scheduler settings in 'attr' policy=SCHED_RR, priority=20 inheritsched is INHERIT // ----> 不同之处 Scheduler attributes of new thread policy=SCHED_FIFO, priority=10 /*在上面的输出中,可以看到调度策略和优先级来自创建线程,而不是线程属性对象。*/ In the above output, one can see that the scheduling policy and priority were taken from the creating thread, rather than the thread attributes object. /*注意,如果我们省略了-i i选项,输出将是相同的,因为PTHREAD_INHERIT_SCHED是继承调度器属性的默认值。*/ Note that if we had omitted the -i i option, the output would have been the same, since PTHREAD_INHERIT_SCHED is the default for the inherit scheduler attribute. Program source /* pthreads_sched_test.c */ #include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <errno.h> #define handle_error_en(en, msg) \ do { errno = en; perror(msg); exit(EXIT_FAILURE); } while (0) static void usage(char *prog_name, char *msg) { if (msg != NULL) fputs(msg, stderr); fprintf(stderr, "Usage: %s [options]\n", prog_name); fprintf(stderr, "Options are:\n"); #define fpe(msg) fprintf(stderr, "\t%s", msg); /* Shorter */ fpe("-a<policy><prio> Set scheduling policy and priority in\n"); fpe(" thread attributes object\n"); fpe(" <policy> can be\n"); fpe(" f SCHED_FIFO\n"); fpe(" r SCHED_RR\n"); fpe(" o SCHED_OTHER\n"); fpe("-A Use default thread attributes object\n"); fpe("-i {e|i} Set inherit scheduler attribute to\n"); fpe(" 'explicit' or 'inherit'\n"); fpe("-m<policy><prio> Set scheduling policy and priority on\n"); fpe(" main thread before pthread_create() call\n"); exit(EXIT_FAILURE); } static int get_policy(char p, int *policy) { switch (p) { case 'f': *policy = SCHED_FIFO; return 1; case 'r': *policy = SCHED_RR; return 1; case 'o': *policy = SCHED_OTHER; return 1; default: return 0; } } static void display_sched_attr(int policy, struct sched_param *param) { printf(" policy=%s, priority=%d\n", (policy == SCHED_FIFO) ? "SCHED_FIFO" : (policy == SCHED_RR) ? "SCHED_RR" : (policy == SCHED_OTHER) ? "SCHED_OTHER" : "???", param->sched_priority); } static void display_thread_sched_attr(char *msg) { int policy, s; struct sched_param param; s = pthread_getschedparam(pthread_self(), &policy, ¶m); if (s != 0) handle_error_en(s, "pthread_getschedparam"); printf("%s\n", msg); display_sched_attr(policy, ¶m); } static void * thread_start(void *arg) { display_thread_sched_attr("Scheduler attributes of new thread"); return NULL; } int main(int argc, char *argv[]) { int s, opt, inheritsched, use_null_attrib, policy; pthread_t thread; pthread_attr_t attr; pthread_attr_t *attrp; char *attr_sched_str, *main_sched_str, *inheritsched_str; struct sched_param param; /* Process command-line options */ use_null_attrib = 0; attr_sched_str = NULL; main_sched_str = NULL; inheritsched_str = NULL; while ((opt = getopt(argc, argv, "a:Ai:m:")) != -1) { switch (opt) { case 'a': attr_sched_str = optarg; break; case 'A': use_null_attrib = 1; break; case 'i': inheritsched_str = optarg; break; case 'm': main_sched_str = optarg; break; default: usage(argv[0], "Unrecognized option\n"); } } if (use_null_attrib && (inheritsched_str != NULL || attr_sched_str != NULL)) usage(argv[0], "Can't specify -A with -i or -a\n"); /* Optionally set scheduling attributes of main thread, and display the attributes */ if (main_sched_str != NULL) { if (!get_policy(main_sched_str[0], &policy)) usage(argv[0], "Bad policy for main thread (-m)\n"); param.sched_priority = strtol(&main_sched_str[1], NULL, 0); s = pthread_setschedparam(pthread_self(), policy, ¶m); if (s != 0) handle_error_en(s, "pthread_setschedparam"); } display_thread_sched_attr("Scheduler settings of main thread"); printf("\n"); /* Initialize thread attributes object according to options */ attrp = NULL; if (!use_null_attrib) { s = pthread_attr_init(&attr); if (s != 0) handle_error_en(s, "pthread_attr_init"); attrp = &attr; } if (inheritsched_str != NULL) { if (inheritsched_str[0] == 'e') inheritsched = PTHREAD_EXPLICIT_SCHED; else if (inheritsched_str[0] == 'i') inheritsched = PTHREAD_INHERIT_SCHED; else usage(argv[0], "Value for -i must be 'e' or 'i'\n"); s = pthread_attr_setinheritsched(&attr, inheritsched); if (s != 0) handle_error_en(s, "pthread_attr_setinheritsched"); } if (attr_sched_str != NULL) { if (!get_policy(attr_sched_str[0], &policy)) usage(argv[0], "Bad policy for 'attr' (-a)\n"); param.sched_priority = strtol(&attr_sched_str[1], NULL, 0); s = pthread_attr_setschedpolicy(&attr, policy); if (s != 0) handle_error_en(s, "pthread_attr_setschedpolicy"); s = pthread_attr_setschedparam(&attr, ¶m); if (s != 0) handle_error_en(s, "pthread_attr_setschedparam"); } /* If we initialized a thread attributes object, display the scheduling attributes that were set in the object */ if (attrp != NULL) { s = pthread_attr_getschedparam(&attr, ¶m); if (s != 0) handle_error_en(s, "pthread_attr_getschedparam"); s = pthread_attr_getschedpolicy(&attr, &policy); if (s != 0) handle_error_en(s, "pthread_attr_getschedpolicy"); printf("Scheduler settings in 'attr'\n"); display_sched_attr(policy, ¶m); s = pthread_attr_getinheritsched(&attr, &inheritsched); printf(" inheritsched is %s\n", (inheritsched == PTHREAD_INHERIT_SCHED) ? "INHERIT" : (inheritsched == PTHREAD_EXPLICIT_SCHED) ? "EXPLICIT" : "???"); printf("\n"); } /* Create a thread that will display its scheduling attributes */ s = pthread_create(&thread, attrp, &thread_start, NULL); if (s != 0) handle_error_en(s, "pthread_create"); /* Destroy unneeded thread attributes object */ if (!use_null_attrib) { s = pthread_attr_destroy(&attr); if (s != 0) handle_error_en(s, "pthread_attr_destroy"); } s = pthread_join(thread, NULL); if (s != 0) handle_error_en(s, "pthread_join"); exit(EXIT_SUCCESS); } SEE ALSO getrlimit(2), sched_get_priority_min(2), pthread_attr_init(3), pthread_attr_setinheritsched(3), pthread_attr_setschedparam(3), pthread_attr_setschedpolicy(3), pthread_create(3), pthread_self(3), pthread_setschedprio(3), pthreads(7), sched(7) COLOPHON This page is part of release 5.05 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at https://www.kernel.org/doc/man-pages/. Linux 2019-03-06 PTHREAD_SETSCHEDPARAM(3)
在ubuntu上代码测试,工具clion
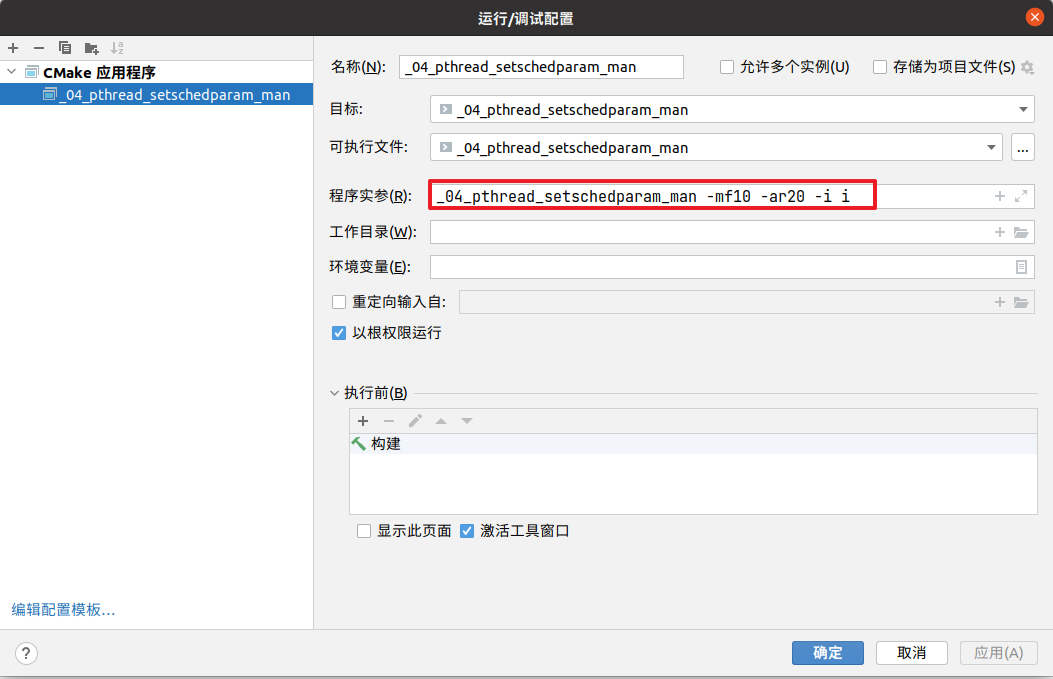
源码就是上面的man手册的源码
运行结果:
Scheduler settings of main thread policy=SCHED_FIFO, priority=10 Scheduler settings in 'attr' policy=SCHED_RR, priority=20 inheritsched is INHERIT Scheduler attributes of new thread policy=SCHED_FIFO, priority=10 //// 结果来自于main线程的属性,而不是调度Scheduler的设置属性
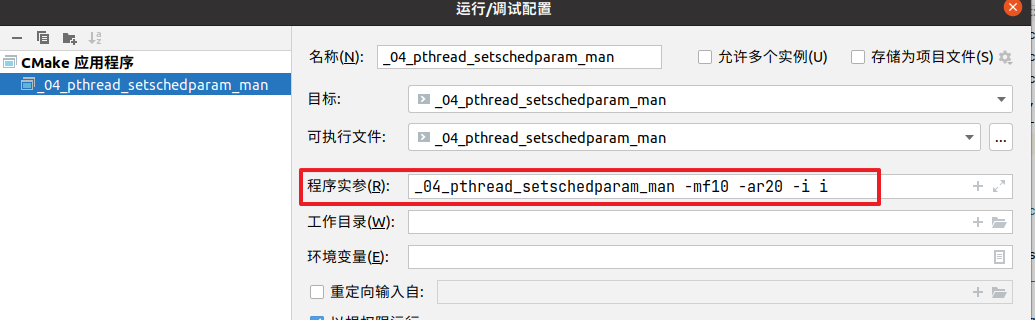
运行结果:
Scheduler settings of main thread policy=SCHED_FIFO, priority=10 Scheduler settings in 'attr' policy=SCHED_RR, priority=20 inheritsched is INHERIT Scheduler attributes of new thread policy=SCHED_FIFO, priority=10 //结果来自于调度Scheduler的设置属性,而不是main线程的属性
总结:程序主要是通过设置
inheritsched = PTHREAD_EXPLICIT_SCHED;或者inheritsched = PTHREAD_INHERIT_SCHED; 来设置main线程thread创建的线程的策略和优先级;
2. sched
man 手册-来自Ubuntu20.04
1 SCHED(7) Linux Programmer's Manual SCHED(7) 2 3 NAME 4 /*sched -CPU调度概述*/ 5 sched - overview of CPU scheduling 6 7 DESCRIPTION 8 /*从Linux 2.6.23开始,默认的调度程序是CFS,即“完全公平调度”。 CFS调度器取代了早期的“O(1)”调度器。*/ 9 Since Linux 2.6.23, the default scheduler is CFS, the "Completely Fair Scheduler". The CFS scheduler replaced the earlier "O(1)" scheduler. 10 11 API summary 12 /*Linux提供了以下系统调用,用于控制CPU调度行为、策略和进程(或者更准确地说,线程)的优先级。*/ 13 Linux provides the following system calls for controlling the CPU scheduling behavior, policy, and priority of processes (or, more precisely, threads). 14 15 nice(2) /*为调用线程设置新的nice值,并返回新的nice值。*/ 16 Set a new nice value for the calling thread, and return the new nice value. 17 18 getpriority(2) /*返回指定用户拥有的线程、进程组或线程集的nice值。*/ 19 Return the nice value of a thread, a process group, or the set of threads owned by a specified user. 20 21 setpriority(2) /*设置线程、进程组或指定用户拥有的线程集的nice值。*/ 22 Set the nice value of a thread, a process group, or the set of threads owned by a specified user. 23 24 sched_setscheduler(2) /*设置指定线程的调度策略和参数。*/ 25 Set the scheduling policy and parameters of a specified thread. 26 27 sched_getscheduler(2) /*返回指定线程的调度策略。*/ 28 Return the scheduling policy of a specified thread. 29 30 sched_setparam(2) /*设置指定线程的调度参数。*/ 31 Set the scheduling parameters of a specified thread. 32 33 sched_getparam(2) /*获取指定线程的调度参数。*/ 34 Fetch the scheduling parameters of a specified thread. 35 36 sched_get_priority_max(2) /*返回指定调度策略中可用的最大优先级。*/ 37 Return the maximum priority available in a specified scheduling policy. 38 39 sched_get_priority_min(2) /*返回指定调度策略中可用的最小优先级。*/ 40 Return the minimum priority available in a specified scheduling policy. 41 42 sched_rr_get_interval(2) /*获取用于在“循环调度”调度策略下调度的线程的量程。*/ 43 Fetch the quantum used for threads that are scheduled under the "round-robin" scheduling policy. 44 45 sched_yield(2) /*使调用者放弃CPU,以便执行其他线程。*/ 46 Cause the caller to relinquish the CPU, so that some other thread be executed. 47 48 sched_setaffinity(2) /*(特定于Linux)设置指定线程的CPU关联。*/ 49 (Linux-specific) Set the CPU affinity of a specified thread. 50 51 sched_getaffinity(2) /*(特定于Linux)获取指定线程的CPU关联。*/ 52 (Linux-specific) Get the CPU affinity of a specified thread. 53 54 sched_setattr(2) 55 Set the scheduling policy and parameters of a specified thread. 56 This (Linux-specific) system call provides a superset of the functionality of sched_setscheduler(2) and sched_setparam(2). 57 /*设置指定线程的调度策略和参数。这个(特定于Linux的)系统调用提供了sched_setscheduler(2)和sched_setparam(2)功能的超集 */ 58 59 sched_getattr(2) 60 Fetch the scheduling policy and parameters of a specified thread. 61 This (Linux-specific) system call provides a superset of the functionality of sched_getscheduler(2) and sched_getparam(2). 62 /*获取指定线程的调度策略和参数。这个(特定于Linux的)系统调用提供了sched_getscheduler(2)和sched_getparam(2)功能的超集。*/ 63 64 Scheduling policies 65 The scheduler is the kernel component that decides which runnable thread will be executed by the CPU next. 66 Each thread has an associated scheduling policy and a static scheduling priority, sched_priority. 67 The scheduler makes its decisions based on knowledge of the scheduling policy and static priority of all threads on the system. 68 /*调度程序是内核组件,它决定CPU接下来将执行哪个可运行线程。 69 每个线程都有一个相关的调度策略和一个静态调度优先级sched_priority。 70 调度程序根据对调度策略和系统上所有线程的静态优先级的了解做出决策。*/ 71 72 For threads scheduled under one of the normal scheduling policies 73 (SCHED_OTHER, SCHED_IDLE, SCHED_BATCH), sched_priority is not used in scheduling decisions (it must be specified as 0). 74 /*对于在正常调度策略之一下调度的线程(SCHED_OTHER,SCHED_IDLE,SCHED_BATCH),sched_priority不用于调度决策(必须指定为0)。*/ 75 76 Processes scheduled under one of the real-time policies (SCHED_FIFO, SCHED_RR) have a sched_priority value in the range 1 (low) to 99 (high). 77 (As the numbers imply, real-time threads always have higher priority than normal threads.) 78 Note well: POSIX.1 requires an implementation to support only a minimum 32 distinct priority levels for the real-time policies, 79 and some systems supply just this minimum. 80 ★★★ Portable programs should use sched_get_priority_min(2) and sched_get_priority_max(2) to find the range of priorities supported for a particular policy. 81 /* 82 在其中一个实时策略(SCHED_FIFO、SCHED_RR)下调度的进程的sched_priority值在1(低)到99(高)的范围内。 83 (这些数字意味着,实时线程总是比普通线程具有更高的优先级。) 84 请注意:POSIX.1要求实现仅支持实时策略的最低32个不同优先级,而有些系统只能提供最小值 85 可移植程序应该使用sched_get_priority_min(2)和sched_get_priority_max(2)来查找特定策略支持的优先级范围。 86 */ 87 88 Conceptually, the scheduler maintains a list of runnable threads for each possible sched_priority value. 89 In order to determine which thread runs next, 90 the scheduler looks for the nonempty list with the highest static priority and selects the thread at the head of this list. 91 92 A thread's scheduling policy determines where it will be inserted into the list of threads with equal static priority and how it will move inside this list. 93 94 All scheduling is preemptive: 95 if a thread with a higher static priority becomes ready to run, 96 the currently running thread will be preempted and returned to the wait list for its static priority level. 97 The scheduling policy determines the ordering only within the list of runnable threads with equal static priority. 98 99 /** 100 * 101 从概念上讲,调度程序为每个可能的sched_priority值维护一个可运行线程列表。 102 为了确定下一个运行的线程,调度程序查找具有最高静态优先级的非空列表,并选择该列表头部的线程。 103 104 线程的调度策略决定了它将被插入到具有相同静态优先级的线程列表的何处,以及它将如何在该列表中移动。 105 106 所有调度都是抢占式的: 107 如果具有较高静态优先级的线程准备好运行,则当前运行的线程将被抢占并返回到其静态优先级的等待列表。 108 调度策略仅确定具有相同静态优先级的可运行线程列表中的顺序。 109 */ 110 111 SCHED_FIFO: First in-first out scheduling /*先进先出调度*/ 112 /* 113 SCHED_FIFO只能用于静态优先级高于0的情况,这意味着当SCHED_FIFO线程变为可运行时, 114 它总是立即抢占任何当前运行的SCHED_OTHER、SCHED_BATCH或SCHED_IDLE线程。 115 SCHED_FIFO是一种简单的无时间切片的调度算法。 116 对于在SCHED_FIFO策略下调度的线程,以下规则适用: 117 */ 118 SCHED_FIFO can be used only with static priorities higher than 0, which means that when a SCHED_FIFO thread becomes runnable, 119 it will always immediately preempt any currently running SCHED_OTHER, SCHED_BATCH, or SCHED_IDLE thread. 120 SCHED_FIFO is a simple scheduling algorithm without time slicing. 121 For threads scheduled under the SCHED_FIFO policy, the following rules apply: 122 123 /*1)一个正在运行的SCHED_FIFO线程被另一个更高优先级的线程抢占,它将停留在其优先级列表的头部,并且一旦所有更高优先级的线程再次被阻塞,它将恢复执行。*/ 124 1) A running SCHED_FIFO thread that has been preempted by another thread of higher priority will stay at the head of the list for its priority and will resume execution as soon as all threads of higher priority are blocked again. 125 126 /*2)当一个被阻塞的SCHED_FIFO线程变成可运行时,它将被插入到列表的末尾,以获得其优先级。*/ 127 2) When a blocked SCHED_FIFO thread becomes runnable, it will be inserted at the end of the list for its priority. 128 129 /*3)如果调用sched_setscheduler(2)、sched_setparam(2)、sched_setattr(2)、pthread_setschedparam(3)或pthread_setschedprio(3) 130 更改了由pid标识的正在运行或可运行的SCHED_FIFO线程的优先级,则对线程在列表中的位置的影响取决于线程优先级更改的方向:*/ 131 3) If a call to sched_setscheduler(2), sched_setparam(2), sched_setattr(2), pthread_setschedparam(3), or pthread_setschedprio(3) changes the priority of the running or runnable SCHED_FIFO thread identified by pid the effect on the thread's position in the list depends on the direction of the change to threads priority: 132 133 • If the thread's priority is raised, it is placed at the end of the list for its new priority. As a consequence, it may preempt a currently running thread with the same priority. 134 /*如果线程的优先级被提升,它将被放置在列表的末尾,以获得新的优先级。 因此,它可能会抢占当前正在运行的具有相同优先级的线程。*/ 135 136 • If the thread's priority is unchanged, its position in the run list is unchanged. 137 /*如果线程的优先级不变,则其在运行列表中的位置不变。*/ 138 139 • If the thread's priority is lowered, it is placed at the front of the list for its new priority. 140 /*如果线程的优先级降低,它将被放置在列表的最前面,以获得新的优先级。*/ 141 142 /*根据POSIX.1-2008,使用pthread_setschedprio(3)以外的任何机制更改线程的优先级(或策略)都应该导致线程被放置在其优先级列表的末尾。*/ 143 According to POSIX.1-2008, changes to a thread's priority (or policy) using any mechanism other than pthread_setschedprio(3) should result in the thread being placed at the end of the list for its priority. 144 145 4) A thread calling sched_yield(2) will be put at the end of the list. 146 147 No other events will move a thread scheduled under the SCHED_FIFO policy in the wait list of runnable threads with equal static priority. 148 149 A SCHED_FIFO thread runs until either it is blocked by an I/O request, it is preempted by a higher priority thread, or it calls sched_yield(2). 150 /* 151 4)一个调用sched_yield(2)的线程将被放在列表的末尾。 152 153 在具有相同静态优先级的可运行线程的等待列表中,没有其他事件会移动根据SCHED_FIFO策略调度的线程 154 155 一个SCHED_FIFO线程会一直运行,直到它被一个I/O请求阻塞,被一个更高优先级的线程抢占,或者它调用sched_yield(2)。 156 */ 157 158 SCHED_RR: Round-robin scheduling /*循环调度*/ 159 SCHED_RR is a simple enhancement of SCHED_FIFO. 160 Everything described above for SCHED_FIFO also applies to SCHED_RR, except that each thread is allowed to run only for a maximum time quantum. 161 If a SCHED_RR thread has been running for a time period equal to or longer than the time quantum, it will be put at the end of the list for its priority. 162 A SCHED_RR thread that has been preempted by a higher priority thread and subsequently resumes execution as a running thread will complete the unexpired portion of its round-robin time quantum. 163 The length of the time quantum can be retrieved using sched_rr_get_interval(2). 164 165 /*SCHED_RR是SCHED_FIFO的简单增强。 上面针对SCHED_FIFO所描述的一切也适用于SCHED_RR,除了每个线程只允许运行一个最大时间量。 166 如果一个SCHED_RR线程已经运行了等于或长于时间量程的时间段,它将被放在列表的末尾,以确定其优先级。 167 已被较高优先级线程抢占并随后作为运行线程恢复执行的SCHED_RR线程将完成其循环时间量程的未过期部分。 168 可以使用sched_rr_get_interval(2)检索时间段的长度。*/ 169 170 SCHED_DEADLINE: Sporadic task model deadline scheduling /*最后期限调度器*/ 171 Since version 3.14, Linux provides a deadline scheduling policy (SCHED_DEADLINE). 172 This policy is currently implemented using GEDF (Global Earliest Deadline First) in conjunction with CBS (Constant Bandwidth Server). 173 To set and fetch this policy and associated attributes, one must use the Linux-specific sched_setattr(2) and sched_getattr(2) system calls. 174 175 /*从3.14版开始,Linux提供了一个截止日期调度策略(SCHED_DEADLINE)。 176 该策略目前使用GEDF(Global Earliest Deadline First)和CBS(Constant Bandwidth Server)来实施。 177 要设置和获取此策略及相关属性,必须使用特定于Linux的sched_setattr(2)和sched_getattr(2)系统调用。*/ 178 179 A sporadic task is one that has a sequence of jobs, where each job is activated at most once per period. 180 Each job also has a relative deadline, before which it should finish execution, and a computation time, which is the CPU time necessary for executing the job. 181 The moment when a task wakes up because a new job has to be executed is called the arrival time (also referred to as the request time or release time). 182 The start time is the time at which a task starts its execution. 183 The absolute deadline is thus obtained by adding the relative deadline to the arrival time. 184 /* 185 零星任务是具有作业序列的任务,其中每个作业在每个周期最多激活一次。 186 每个作业也有一个相对的截止日期,在此之前,它应该完成执行,以及计算时间,这是执行作业所需的CPU时间。 187 当一个任务因为一个新的作业必须被执行而被唤醒的时刻被称为到达时间(也被称为请求时间或释放时间)。 188 开始时间是任务开始执行的时间。 189 因此,绝对截止时间是通过将相对截止时间与到达时间相加而获得的。 190 */ 191 192 The following diagram clarifies these terms: 193 194 arrival/wakeup absolute deadline 195 | start time | 196 | | | 197 v v v 198 -----x--------xooooooooooooooooo--------x--------x--- 199 |<- comp. time ->| 200 |<------- relative deadline ------>| 201 |<-------------- period ------------------->| 202 203 When setting a SCHED_DEADLINE policy for a thread using sched_setattr(2), one can specify three parameters: Runtime, Deadline, and Period. 204 These parameters do not necessarily correspond to the aforementioned terms: 205 usual practice is to set Runtime to something bigger than the average computation time 206 (or worst-case execution time for hard real-time tasks), Deadline to the relative deadline, and Period to the period of the task. 207 Thus, for SCHED_DEADLINE scheduling, we have: 208 /* 209 当使用sched_setattr(2)为线程设置SCHED_DEADLINE策略时,可以指定三个参数:时间、期限和周期。 210 这些参数不一定对应于上述术语: 211 通常的做法是将时间设置为大于平均计算时间的值 (or硬实时任务的最坏情况执行时间),Deadline是相对的截止日期,Period是任务的周期。 212 因此,对于SCHED_DEADLINE调度,我们有: 213 */ 214 215 arrival/wakeup absolute deadline 216 | start time | 217 | | | 218 v v v 219 -----x--------xooooooooooooooooo--------x--------x--- 220 |<-- Runtime ------->| 221 |<----------- Deadline ----------->| 222 |<-------------- Period ------------------->| 223 224 The three deadline-scheduling parameters correspond to the sched_runtime, sched_deadline, and sched_period fields of the sched_attr structure; see sched_setattr(2). 225 These fields express values in nanoseconds. 226 If sched_period is specified as 0, then it is made the same as sched_deadline. 227 /* 228 三个期限调度参数对应于sched_attr结构的sched_runtime、sched_deadline和sched_period字段;参见sched_setattr(2)。 229 这些字段以纳秒为单位表示值。 230 如果sched_period被指定为0,则它与sched_deadline相同。 231 */ 232 233 The kernel requires that: 234 235 sched_runtime <= sched_deadline <= sched_period 236 237 In addition, under the current implementation, all of the parameter values must be at least 1024 (i.e., just over one microsecond, which is the resolution of the implementation), and less than 2^63. If any of these checks fails, sched_setattr(2) fails with the error EINVAL. 238 239 The CBS guarantees non-interference between tasks, by throttling threads that attempt to over-run their specified Runtime. 240 241 To ensure deadline scheduling guarantees, the kernel must prevent situations where the set of SCHED_DEADLINE threads is not feasible (schedulable) within the given constraints. The kernel thus performs an admittance test when setting or changing SCHED_DEADLINE policy and attributes. This admission test calculates whether the change is feasible; if it is not, sched_setattr(2) fails with the error EBUSY. 242 243 For example, it is required (but not necessarily sufficient) for the total utilization to be less than or equal to the total number of CPUs available, where, since each thread can maximally run for Runtime per Period, that thread's utilization is its Runtime divided by its Period. 244 245 In order to fulfill the guarantees that are made when a thread is admitted to the SCHED_DEADLINE policy, SCHED_DEADLINE threads are the highest priority (user controllable) threads in the system; if any SCHED_DEADLINE thread is runnable, it will preempt any thread scheduled under one of the other policies. 246 247 A call to fork(2) by a thread scheduled under the SCHED_DEADLINE policy fails with the error EAGAIN, unless the thread has its reset-on-fork flag set (see below). 248 249 A SCHED_DEADLINE thread that calls sched_yield(2) will yield the current job and wait for a new period to begin. 250 251 /* 252 此外,在当前实现下,所有参数值必须至少为1024(即, 刚刚超过一微秒,这是实现的分辨率),并且小于2^63。 253 如果这些检查中的任何一个失败,sched_setattr(2)将失败,并返回错误EINVAL。 254 255 CBS通过限制试图超出其指定线程的线程来保证任务之间的不干扰。 256 257 为了确保最后期限调度保证,内核必须防止SCHED_DEADLINE线程集在给定约束内不可行(不可执行)的情况。 258 因此,内核在设置或更改SCHED_DEADLINE策略和属性时执行准入测试。 259 这个准入测试计算更改是否可行;如果不可行,sched_setattr(2)将失败,并返回错误EBUSY。 260 261 例如,总利用率需要(但不一定足够)小于或等于可用CPU的总数,其中,由于每个线程可以最大地在每个周期内运行1/2,因此该线程的利用率是其1/2除以其周期。 262 263 为了满足当线程被允许进入SCHED_DEADLINE策略时所做的保证,SCHED_DEADLINE线程是系统中优先级最高(用户可控制)的线程;如果任何SCHED_DEADLINE线程是可运行的, 264 它将抢占任何在其他策略下调度的线程。 265 266 在SCHED_DEADLINE策略下调度的线程对fork(2)的调用失败,并返回错误EAGAIN,除非该线程设置了reset-on-fork标志(参见下文)。 267 268 调用sched_yield(2)的SCHED_DEADLINE线程将产生当前作业并等待新的周期开始。 269 */ 270 271 272 SCHED_OTHER: Default Linux time-sharing scheduling /*默认Linux分时调度*/ 273 SCHED_OTHER can be used at only static priority 0 (i.e., threads under real-time policies always have priority over SCHED_OTHER processes). SCHED_OTHER is the standard Linux time-sharing scheduler that is intended for all threads that do not require the special real-time mechanisms. 274 275 The thread to run is chosen from the static priority 0 list based on a dynamic priority that is determined only inside this list. The dynamic priority is based on the nice value (see below) and is increased for each time quantum the thread is ready to run, but denied to run by the scheduler. This ensures fair progress among all SCHED_OTHER threads. 276 277 In the Linux kernel source code, the SCHED_OTHER policy is actually named SCHED_NORMAL. 278 /* 279 SCHED_OTHER只能在静态优先级0使用(即, 实时策略下的线程总是优先于SCHED_OTHER进程)。 280 SCHED_OTHER是标准的Linux分时调度程序,适用于所有不需要特殊实时机制的线程。 281 282 要运行的线程是根据动态优先级从静态优先级0列表中选择的,动态优先级仅在此列表中确定。 283 动态优先级基于nice值(见下文),并且在线程准备运行但被调度程序拒绝运行的每个时间段增加。 284 这确保了所有SCHED_OTHER线程之间的公平进程。 285 286 在Linux内核源代码中,SCHED_OTHER策略实际上被命名为SCHED_NORMAL。 287 */ 288 289 The nice value 290 The nice value is an attribute that can be used to influence the CPU scheduler to favor or disfavor a process in scheduling decisions. It affects the scheduling of SCHED_OTHER and SCHED_BATCH (see below) processes. The nice value can be modified using nice(2), setpriority(2), or sched_setattr(2). 291 292 According to POSIX.1, the nice value is a per-process attribute; that is, the threads in a process should share a nice value. 293 However, on Linux, the nice value is a per-thread attribute: different threads in the same process may have different nice values. 294 295 The range of the nice value varies across UNIX systems. 296 On modern Linux, the range is -20 (high priority) to +19 (low priority). 297 On some other systems, the range is -20..20. Very early Linux kernels (Before Linux 2.0) had the range -infinity..15. 298 299 The degree to which the nice value affects the relative scheduling of SCHED_OTHER processes likewise varies across UNIX systems and across Linux kernel versions. 300 301 With the advent of the CFS scheduler in kernel 2.6.23, Linux adopted an algorithm that causes relative differences in nice values to have a much stronger effect. In the current implementation, each unit of difference in the nice values of two processes results in a factor of 1.25 in the degree to which the scheduler favors the higher priority process. This causes very low nice values (+19) to truly provide little CPU to a process whenever there is any other higher priority load on the system, and makes high nice values (-20) deliver most of the CPU to applications that require it (e.g., some audio applications). 302 303 On Linux, the RLIMIT_NICE resource limit can be used to define a limit to which an unprivileged process's nice value can be raised; see setrlimit(2) for details. 304 305 For further details on the nice value, see the subsections on the autogroup feature and group scheduling, below. 306 307 /* 308 nice值是一个属性,可用于影响CPU调度程序在调度决策中支持或不支持某个进程。 309 它影响SCHED_OTHER和SCHED_BATCH(见下文)进程的调度。 310 可以使用nice(2)、setpriority(2)或sched_setattr(2)修改nice值。 311 312 根据POSIX.1,nice值是每个进程的属性;也就是说,进程中的线程应该共享一个nice值。 313 然而,在Linux上,nice值是一个每线程属性:同一进程中的不同线程可能具有不同的nice值。 314 315 nice值的范围因UNIX系统而异。 在现代Linux上,范围是-20(高优先级)到+19(低优先级)。 316 在其他一些系统上,范围是-20...20. 非常早期的Linux内核(在Linux 2.0之前)具有无限的范围...15. 317 318 nice值对SCHED_OTHER进程的相对调度的影响程度在不同的UNIX系统和不同的Linux内核版本中也会有所不同。 319 320 随着CFS调度程序在内核2.6.23中的出现,Linux采用了一种算法,该算法使nice值的相对差异具有更强的效果。 321 在当前的实现中,两个进程的nice值的每一个单位的差异导致调度器偏向于较高优先级进程的程度的因子1.25。 322 这导致非常低的nice值(+19)在系统上存在任何其他更高优先级负载时实际上向进程提供很少的CPU, 323 并且使得高nice值(-20)将大部分CPU提供给需要它的应用程序(例如, 一些音频应用程序)。 324 325 在Linux上,RLIMIT_NICE资源限制可以用来定义一个限制,一个非特权进程的nice值可以提升到这个限制;有关详细信息,请参阅setrlimit(2)。 326 327 有关nice值的更多详细信息,请参阅下面关于自动组功能和组调度的小节。 328 */ 329 330 SCHED_BATCH: Scheduling batch processes /*调度批处理过程*/ 331 (Since Linux 2.6.16.) SCHED_BATCH can be used only at static priority 0. This policy is similar to SCHED_OTHER in that it schedules the thread according to its dynamic priority (based on the nice value). The difference is that this policy will cause the scheduler to always assume that the thread is CPU-intensive. Consequently, the scheduler will apply a small scheduling penalty with respect to wakeup behavior, so that this thread is mildly disfavored in scheduling decisions. 332 333 This policy is useful for workloads that are noninteractive, but do not want to lower their nice value, and for workloads that want a deterministic scheduling policy without interactivity causing extra preemptions (between the workload's tasks). 334 /* 335 (自Linux 2.6.16起。) SCHED_BATCH只能在静态优先级为0时使用。 336 此策略与SCHED_OTHER类似,因为它根据线程的动态优先级(基于nice值)调度线程。 337 不同之处在于,此策略将导致调度程序始终假设线程是CPU密集型的。 338 因此,调度程序将针对唤醒行为应用较小的调度惩罚,从而在调度决策中稍微不支持该线程。 339 340 此策略对于非交互式但不希望降低其nice值的工作负载以及希望确定性调度策略而不希望交互性导致额外抢占(工作负载任务之间)的工作负载非常有用。 341 */ 342 343 SCHED_IDLE: Scheduling very low priority jobs /*调度优先级非常低的作业*/ 344 (Since Linux 2.6.23.) SCHED_IDLE can be used only at static priority 0; the process nice value has no influence for this policy. 345 346 This policy is intended for running jobs at extremely low priority (lower even than a +19 nice value with the SCHED_OTHER or SCHED_BATCH policies). 347 348 /* 349 (自Linux 2.6.23起。) SCHED_IDLE只能在静态优先级为0时使用;进程nice值对此策略没有影响。 350 351 此策略用于以极低的优先级运行作业(甚至低于SCHED_OTHER或SCHED_BATCH策略的+19 nice值)。 352 */ 353 354 Resetting scheduling policy for child processes /*重置子进程的调度策略*/ 355 Each thread has a reset-on-fork scheduling flag. When this flag is set, children created by fork(2) do not inherit privileged scheduling policies. The reset-on-fork flag can be set by either: 356 357 * ORing the SCHED_RESET_ON_FORK flag into the policy argument when calling sched_setscheduler(2) (since Linux 2.6.32); or 358 359 * specifying the SCHED_FLAG_RESET_ON_FORK flag in attr.sched_flags when calling sched_setattr(2). 360 /* 361 每个线程都有一个reset-on-fork调度标志。 当这个标志被设置时,fork(2)创建的子对象不会继承特权调度策略。 reset-on-fork标志可以通过以下方式设置: 362 363 * 当调用sched_setscheduler(2)时,将SCHED_BLOCK_ON_FORK标志与策略参数进行OR运算(自Linux 2.6.32起);或者 364 365 * 当调用sched_setattr(2)时,在attr.sched_flags中指定SCHED_FLAG_ON_FORK标志。 366 */ 367 368 Note that the constants used with these two APIs have different names. The state of the reset-on-fork flag can analogously be retrieved using sched_getscheduler(2) and sched_getattr(2). 369 370 The reset-on-fork feature is intended for media-playback applications, and can be used to prevent applications evading the RLIMIT_RTTIME resource limit (see getrlimit(2)) by creating multiple child processes. 371 372 More precisely, if the reset-on-fork flag is set, the following rules apply for subsequently created children: 373 374 * If the calling thread has a scheduling policy of SCHED_FIFO or SCHED_RR, the policy is reset to SCHED_OTHER in child processes. 375 376 * If the calling process has a negative nice value, the nice value is reset to zero in child processes. 377 378 After the reset-on-fork flag has been enabled, it can be reset only if the thread has the CAP_SYS_NICE capability. This flag is disabled in child processes created by fork(2). 379 380 /* 381 请注意,这两个API使用的常量具有不同的名称。 382 reset-on-fork标志的状态可以类似地使用sched_getscheduler(2)和sched_getattr(2)来检索。 383 384 reset-on-fork特性用于媒体播放应用程序,可以用来防止应用程序通过创建多个子进程来逃避RLIMIT_RTTIME资源限制(参见getrlimit(2))。 385 386 更准确地说,如果设置了reset-on-fork标志,则以下规则适用于随后创建的子项: 387 388 * 如果调用线程的调度策略为SCHED_FIFO或SCHED_RR,则该策略在子进程中重置为SCHED_OTHER。 389 390 * 如果调用进程的nice值为负,则在子进程中将nice值重置为零。 391 392 在启用reset-on-fork标志之后,只有当线程具有CAP_REPORT_NICE功能时才能重置它。 这个标志在fork(2)创建的子进程中被禁用。 393 */ 394 395 Privileges and resource limits /*特权和资源限制*/ 396 In Linux kernels before 2.6.12, only privileged (CAP_SYS_NICE) threads can set a nonzero static priority (i.e., set a real-time scheduling policy). The only change that an unprivileged thread can make is to set the SCHED_OTHER policy, and this can be done only if the effective user ID of the caller matches the real or effective user ID of the target thread (i.e., the thread specified by pid) whose policy is being changed. 397 398 A thread must be privileged (CAP_SYS_NICE) in order to set or modify a SCHED_DEADLINE policy. 399 /* 400 在2.6.12之前的Linux内核中,只有特权(CAP_NICE)线程可以设置非零静态优先级(即,设置实时调度策略)。 401 非特权线程可以进行的唯一更改是设置SCHED_OTHER策略,并且只有当调用方的有效用户ID与目标线程的真实的或有效用户ID匹配时才能这样做(即,由PID指定的线程),其策略正在被改变。 402 403 线程必须具有特权(CAP_DEADLINE_NICE)才能设置或修改SCHED_DEADLINE策略。 404 */ 405 406 Since Linux 2.6.12, the RLIMIT_RTPRIO resource limit defines a ceiling on an unprivileged thread's static priority for the SCHED_RR and SCHED_FIFO policies. 407 The rules for changing scheduling policy and priority are as follows: 408 409 * If an unprivileged thread has a nonzero RLIMIT_RTPRIO soft limit, then it can change its scheduling policy and priority, 410 subject to the restriction that the priority cannot be set to a value higher than the maximum of its current priority and its RLIMIT_RTPRIO soft limit. 411 412 * If the RLIMIT_RTPRIO soft limit is 0, then the only permitted changes are to lower the priority, or to switch to a non-real-time policy. 413 414 * Subject to the same rules, another unprivileged thread can also make these changes, as long as the effective user ID of the thread making the change matches the real or effective user ID of the target thread. 415 416 * Special rules apply for the SCHED_IDLE policy. In Linux kernels before 2.6.39, an unprivileged thread operating under this policy cannot change its policy, regardless of the value of its RLIMIT_RTPRIO resource limit. In Linux kernels since 2.6.39, an unprivileged thread can switch to either the SCHED_BATCH or the SCHED_OTHER policy so long as its nice value falls within the range permitted by its RLIMIT_NICE resource limit (see getrlimit(2)). 417 418 /* 419 从Linux 2.6.12开始,RLIMIT_RTPRIO资源限制为SCHED_RR和SCHED_FIFO策略定义了非特权线程静态优先级的上限。 420 更改调度策略和优先级的规则如下: 421 422 * 如果一个非特权线程有一个非零的RLIMIT_RTPRIO软限制,那么它可以改变它的调度策略和优先级,但优先级不能设置为高于它的当前优先级和它的RLIMIT_RTPRIO软限制的最大值。 423 424 * 如果RLIMIT_RTPRIO软限制为0,则唯一允许的更改是降低优先级或切换到非实时策略。 425 426 * 根据相同的规则,另一个非特权线程也可以进行这些更改,只要进行更改的线程的有效用户ID与目标线程的真实的或有效用户ID匹配。 427 428 * 特殊规则适用于SCHED_IDLE策略。 429 在2.6.39之前的Linux内核中,在此策略下运行的非特权线程不能更改其策略,无论其RLIMIT_RTPRIO资源限制的值如何。 430 在Linux内核2.6.39版之后,一个非特权线程可以切换到SCHED_BATCH或SCHED_OTHER策略, 431 只要它的nice值福尔斯落在RLIMIT_NICE资源限制允许的范围内(参见getrlimit(2))。 432 */ 433 434 Privileged (CAP_SYS_NICE) threads ignore the RLIMIT_RTPRIO limit; as with older kernels, they can make arbitrary changes to scheduling policy and priority. See getrlimit(2) for further information on RLIMIT_RTPRIO. 435 /* 436 已更新的(CAP_REPORT_NICE)线程忽略RLIMIT_RTPRIO限制;与旧内核一样,它们可以对调度策略和优先级进行任意更改。 437 有关RLIMIT_RTPRIO的更多信息,请参见getrlimit(2)。 438 */ 439 440 Limiting the CPU usage of real-time and deadline processes /*限制实时和截止日期进程的CPU使用*/ 441 A nonblocking infinite loop in a thread scheduled under the SCHED_FIFO, SCHED_RR, or SCHED_DEADLINE policy can potentially block all other threads from accessing the CPU forever. Prior to Linux 2.6.25, the only way of preventing a runaway real-time process from freezing the system was to run (at the console) a shell scheduled under a higher static priority than the tested application. This allows an emergency kill of tested real-time applications that do not block or terminate as expected. 442 443 Since Linux 2.6.25, there are other techniques for dealing with runaway real-time and deadline processes. One of these is to use the RLIMIT_RTTIME resource limit to set a ceiling on the CPU time that a real-time process may consume. See getrlimit(2) for details. 444 445 Since version 2.6.25, Linux also provides two /proc files that can be used to reserve a certain amount of CPU time to be used by non-real-time processes. Reserving CPU time in this fashion allows some CPU time to be allocated to (say) a root shell that can be used to kill a runaway process. Both of these files specify time values in microseconds: 446 /* 447 在SCHED_FIFO、SCHED_RR或SCHED_DEADLINE策略下调度的线程中的非阻塞无限循环可能会永久阻止所有其他线程访问CPU。 448 在Linux 2.6.25之前,防止失控的实时进程冻结系统的唯一方法是(在控制台上)运行一个shell,该shell的静态优先级高于测试的应用程序。 449 这允许紧急终止未按预期阻塞或终止的已测试实时应用程序。 450 451 从Linux 2.6.25开始,有其他技术来处理失控的实时和截止日期进程。 452 其中之一是使用RLIMIT_RTTIME资源限制来设置实时进程可能消耗的CPU时间上限。 453 请参阅getrlimit(2)了解详细信息。 454 455 从2.6.25版开始,Linux还提供了两个/proc文件,可用于保留一定量的CPU时间供非实时进程使用。 456 以这种方式保留CPU时间允许将一些CPU时间分配给(比如说)根shell,用于杀死失控的进程。 457 这两个文件都以微秒为单位指定时间值: 458 */ 459 460 /proc/sys/kernel/sched_rt_period_us 461 This file specifies a scheduling period that is equivalent to 100% CPU bandwidth. The value in this file can range from 1 to INT_MAX, giving an operating range of 1 microsecond to around 35 minutes. The default value in this file is 1,000,000 (1 second). 462 /*此文件指定了一个相当于100% CPU带宽的调度周期。 此文件中的值范围为1到INT_MAX,工作范围为1微秒到大约35分钟。 此文件中的默认值为1,000,000(1秒)。 */ 463 464 /proc/sys/kernel/sched_rt_runtime_us 465 The value in this file specifies how much of the "period" time can be used by all real-time and deadline scheduled processes on the system. The value in this file can range from -1 to INT_MAX-1. Specifying -1 makes the run time the same as the period; that is, no CPU time is set aside for non-real-time processes (which was the Linux behavior before kernel 2.6.25). The default value in this file is 950,000 (0.95 seconds), meaning that 5% of the CPU time is reserved for processes that don't run under a real-time or deadline scheduling policy. 466 /*此文件中的值指定系统上所有实时和截止日期调度进程可以使用多少“周期”时间。 467 此文件中的值范围为-1到INT_MAX-1。 468 Linux使运行时间与周期相同;也就是说,没有为非实时进程留出CPU时间(这是内核2.6.25之前的Linux行为)。 469 此文件中的默认值为950,000(0.95秒),这意味着5%的CPU时间保留给不在实时或最后期限调度策略下运行的进程。*/ 470 471 Response time 472 A blocked high priority thread waiting for I/O has a certain response time before it is scheduled again. 473 The device driver writer can greatly reduce this response time by using a "slow interrupt" interrupt handler. 474 /* 475 等待I/O的阻塞高优先级线程在再次调度之前有一定的响应时间。 476 设备驱动程序编写器可以通过使用“慢中断”中断处理程序来大大缩短响应时间。 477 */ 478 479 Miscellaneous //杂项 480 Child processes inherit the scheduling policy and parameters across a fork(2). The scheduling policy and parameters are preserved across execve(2). 481 482 Memory locking is usually needed for real-time processes to avoid paging delays; this can be done with mlock(2) or mlockall(2). 483 /* 484 子进程通过一个fork继承调度策略和参数(2)。 调度策略和参数在execve(2)中保留。 485 486 实时进程通常需要内存锁定来避免分页延迟;这可以通过mlock(2)或mlockall(2)来完成。 487 */ 488 489 The autogroup feature 490 Since Linux 2.6.38, the kernel provides a feature known as autogrouping to improve interactive desktop performance in the face of multiprocess, CPU-intensive workloads such as building the Linux kernel with large numbers of parallel build processes (i.e., the make(1) -j flag). 491 492 This feature operates in conjunction with the CFS scheduler and requires a kernel that is configured with CONFIG_SCHED_AUTOGROUP. On a running system, this feature is enabled or disabled via the file /proc/sys/kernel/sched_autogroup_enabled; a value of 0 disables the feature, while a value of 1 enables it. The default value in this file is 1, unless the kernel was booted with the noautogroup parameter. 493 494 A new autogroup is created when a new session is created via setsid(2); this happens, for example, when a new terminal window is started. A new process created by fork(2) inherits its parent's autogroup membership. Thus, all of the processes in a session are members of the same autogroup. An autogroup is automatically destroyed when the last process in the group terminates. 495 496 When autogrouping is enabled, all of the members of an autogroup are placed in the same kernel scheduler "task group". The CFS scheduler employs an algorithm that equalizes the distribution of CPU cycles across task groups. The benefits of this for interactive desktop performance can be described via the following example. 497 498 Suppose that there are two autogroups competing for the same CPU (i.e., presume either a single CPU system or the use of taskset(1) to confine all the processes to the same CPU on an SMP system). The first group contains ten CPU-bound processes from a kernel build started with make -j10. The other contains a single CPU-bound process: a video player. The effect of autogrouping is that the two groups will each receive half of the CPU cycles. That is, the video player will receive 50% of the CPU cycles, rather than just 9% of the cycles, which would likely lead to degraded video playback. The situation on an SMP system is more complex, but the general effect is the same: the scheduler distributes CPU cycles across task groups such that an autogroup that contains a large number of CPU-bound processes does not end up hogging CPU cycles at the expense of the other jobs on the system. 499 500 /* 501 从Linux 2.6.38开始,内核提供了一个称为自动分组的功能,以提高交互式桌面在面对多进程、CPU密集型工作负载时的性能, 502 例如构建具有大量并行构建进程的Linux内核(即, make(1)-j标志)。 503 504 此功能与CFS调度程序一起运行,并且需要使用CONFIG_SCHED_AUTOGROUP配置的内核。 505 在运行的系统上,此功能通过文件/proc/sys/kernel/sched_autogroup_enabled启用或禁用;值为0时禁用此功能,值为1时启用此功能。 506 此文件中的默认值为1,除非内核使用noautogroup参数引导。 507 508 当通过setsid(2)创建一个新的会话时,会创建一个新的自动组;例如,当一个新的终端窗口启动时,就会发生这种情况。 509 fork(2)创建的新进程继承其父进程的自动组成员身份。 510 因此,会话中的所有进程都是同一个自动组的成员。 511 当组中的最后一个进程终止时,自动组将自动销毁。 512 513 当启用自动分组时,自动分组的所有成员都被放置在同一个内核调度程序“任务组”中。 514 CFS调度程序采用一种算法,使CPU周期在任务组之间的分布均衡。 515 通过下面的示例可以描述这对交互式桌面性能的好处。 516 517 假设有两个自动组竞争同一个CPU(即, 假设是单个CPU系统,或者使用taskset(1)将所有进程限制在SMP系统上的同一个CPU上)。 518 第一组包含10个CPU绑定的进程,这些进程来自以make -j10启动的内核构建。 519 另一个包含一个CPU绑定的进程:视频播放器。 自动分组的效果是两个组将各自接收一半的CPU周期。 520 也就是说,视频播放器将接收50%的CPU周期,而不仅仅是9%的周期,这可能会导致视频播放质量下降。 521 SMP系统上的情况更为复杂,但总体效果是相同的:调度程序将CPU周期分布在多个任务组中, 522 这样包含大量CPU绑定进程的自动组就不会以牺牲系统上的其他作业为代价来占用CPU周期。 523 */ 524 525 A process's autogroup (task group) membership can be viewed via the file /proc/[pid]/autogroup: 526 /*进程的autogroup(任务组)成员可以通过文件/proc/[pid]/autogroup查看:*/ 527 528 $ cat /proc/1/autogroup 529 /autogroup-1 nice 0 530 531 This file can also be used to modify the CPU bandwidth allocated to an autogroup. This is done by writing a number in the "nice" range to the file to set the autogroup's nice value. The allowed range is from +19 (low priority) to -20 (high priority). (Writing values outside of this range causes write(2) to fail with the error EINVAL.) 532 533 The autogroup nice setting has the same meaning as the process nice value, but applies to distribution of CPU cycles to the autogroup as a whole, based on the relative nice values of other autogroups. For a process inside an autogroup, the CPU cycles that it receives will be a product of the autogroup's nice value (compared to other autogroups) and the process's nice value (compared to other processes in the same autogroup. 534 535 The use of the cgroups(7) CPU controller to place processes in cgroups other than the root CPU cgroup overrides the effect of autogrouping. 536 537 The autogroup feature groups only processes scheduled under non-real-time policies (SCHED_OTHER, SCHED_BATCH, and SCHED_IDLE). It does not group processes scheduled under real-time and deadline policies. Those processes are scheduled according to the rules described earlier. 538 /* 539 该文件还可用于修改分配给自动组的CPU带宽。 540 这是通过将“nice”范围内的数字写入文件来设置自动组的nice值来实现的。 541 允许的范围是从+19(低优先级)到-20(高优先级)。 542 (写入此范围之外的值会导致write(2)失败,并出现错误EINVAL。) 543 544 autogroup nice设置与进程nice值具有相同的含义,但适用于根据其他autogroup的相对nice值将CPU周期分配给整个autogroup。 545 对于自动组内的进程,它收到的CPU周期将是自动组的nice值(与其他自动组相比)和进程的nice值(与同一自动组中的其他进程相比)的乘积。 546 547 使用cgroups(7)CPU控制器将进程放置在根CPU cgroup以外的cgroup中会覆盖自动分组的效果。 548 549 自动分组功能仅对在非实时策略(SCHED_OTHER、SCHED_BATCH和SCHED_IDLE)下调度的进程进行分组。 550 它不对根据实时和截止时间策略调度的进程进行分组。 这些进程是根据前面所述的规则进行调度的。 551 */ 552 553 The nice value and group scheduling 554 When scheduling non-real-time processes (i.e., those scheduled under the SCHED_OTHER, SCHED_BATCH, and SCHED_IDLE policies), 555 the CFS scheduler employs a technique known as "group scheduling", if the kernel was configured with the CONFIG_FAIR_GROUP_SCHED option (which is typical). 556 557 Under group scheduling, threads are scheduled in "task groups". 558 Task groups have a hierarchical relationship, rooted under the initial task group on the system, known as the "root task group". 559 Task groups are formed in the following circumstances: 560 /* 561 当调度非实时进程(即,那些在SCHED_OTHER、SCHED_BATCH和SCHED_IDLE策略下调度的进程), 562 如果内核配置了CONFIG_FAIR_GROUP_SCHED选项(这是典型的选项),CFS调度程序将采用一种称为“组调度”的技术。 563 564 在组调度下,线程在“任务组”中调度。 565 任务组之间有层次关系,根在系统上的初始任务组之下,称为“根任务组”。 566 在下列情况下成立工作组: 567 */ 568 569 570 * All of the threads in a CPU cgroup form a task group. The parent of this task group is the task group of the corresponding parent cgroup. 571 572 * If autogrouping is enabled, then all of the threads that are (implicitly) placed in an autogroup (i.e., the same session, as created by setsid(2)) form a task group. 573 Each new autogroup is thus a separate task group. 574 The root task group is the parent of all such autogroups. 575 576 * If autogrouping is enabled, then the root task group consists of all processes in the root CPU cgroup that were not otherwise implicitly placed into a new autogroup. 577 578 * If autogrouping is disabled, then the root task group consists of all processes in the root CPU cgroup. 579 580 * If group scheduling was disabled (i.e., the kernel was configured without CONFIG_FAIR_GROUP_SCHED), then all of the processes on the system are notionally placed in a single task group. 581 582 /* 583 * CPU cgroup中的所有线程组成一个任务组。 此任务组的父任务组是对应父cgroup的任务组。 584 585 * 如果启用了自动分组,则(隐式地)放置在自动分组中的所有线程(即, 由setSID(2)创建的相同会话)形成任务组。 586 因此,每个新的自动组都是一个单独的任务组。 根任务组是所有此类自动组的父级。 587 588 * 如果启用了自动分组,则根任务组由根CPU cgroup中的所有进程组成,否则这些进程不会隐式地放入新的自动组中。 589 590 * 如果自动分组被禁用,那么根任务组由根CPU cgroup中的所有进程组成。 591 592 * 如果组调度被禁用(即, 内核没有配置CONFIG_FAIR_GROUP_SCHED),那么系统上的所有进程理论上都被放置在一个任务组中。 593 594 */ 595 596 Under group scheduling, a thread's nice value has an effect for scheduling decisions only relative to other threads in the same task group. 597 This has some surprising consequences in terms of the traditional semantics of the nice value on UNIX systems. 598 In particular, if autogrouping is enabled (which is the default in various distributions), 599 then employing setpriority(2) or nice(1) on a process has an effect only for scheduling relative to other processes executed in the same session (typically: 600 the same terminal window). 601 602 Conversely, for two processes that are (for example) the sole CPU-bound processes in different sessions 603 (e.g., different terminal windows, each of whose jobs are tied to different autogroups), 604 modifying the nice value of the process in one of the sessions has no effect in terms of the scheduler's decisions relative to the process in the other session. 605 A possibly useful workaround here is to use a command such as the following to modify the autogroup nice value for all of the processes in a terminal session: 606 /* 607 在组调度下,线程的nice值仅对同一任务组中的其他线程的调度决策有影响。 608 从UNIX系统上nice值的传统语义来看,这会产生一些令人惊讶的结果。 609 特别是,如果启用了自动分组(这是各种发行版中的默认设置), 610 那么在进程上使用setpriority(2)或nice(1)只对相对于在同一会话中执行的其他进程的调度有影响(通常是:同一终端窗口)。 611 612 相反,对于(例如)作为不同会话中的唯一CPU受限进程的两个进程(例如, 不同的终端窗口,其每个作业与不同的自动组相关联), 613 修改其中一个会话中的进程的nice值对于调度器相对于另一个会话中的进程的决策没有影响。 614 一个可能有用的解决方法是使用如下命令修改终端会话中所有进程的autogroup nice值: 615 */ 616 617 $ echo 10 > /proc/self/autogroup 618 619 Real-time features in the mainline Linux kernel /*主线Linux内核中的实时特性*/ 620 Since kernel version 2.6.18, Linux is gradually becoming equipped with real-time capabilities, 621 most of which are derived from the former realtime-preempt patch set. Until the patches have been completely merged into the mainline kernel, 622 they must be installed to achieve the best real-time performance. 623 These patches are named: 624 /* 625 从内核版本2.6.18开始,Linux逐渐具备了实时能力,其中大部分是从先前的实时抢占补丁集导出的。 626 直到补丁完全合并到主线内核中,必须安装它们以实现最佳的实时性能。 627 这些修补程序的名称为: 628 */ 629 630 patch-kernelversion-rtpatchversion 631 632 and can be downloaded from ⟨http://www.kernel.org/pub/linux/kernel/projects/rt/⟩. 633 634 Without the patches and prior to their full inclusion into the mainline kernel, 635 the kernel configuration offers only the three preemption classes CONFIG_PREEMPT_NONE, CONFIG_PREEMPT_VOLUNTARY, and CONFIG_PREEMPT_DESKTOP which respectively provide no, 636 some, and considerable reduction of the worst-case scheduling latency. 637 638 With the patches applied or after their full inclusion into the mainline kernel, 639 the additional configuration item CONFIG_PREEMPT_RT becomes available. 640 If this is selected, Linux is transformed into a regular real-time operating system. 641 The FIFO and RR scheduling policies are then used to run a thread with true real-time priority and a minimum worst-case scheduling latency. 642 643 /* 644 如果没有补丁,并且在它们完全包含到主线内核中之前, 645 内核配置只提供三个抢占类CONFIG_PREEMPT_NONE、CONFIG_PREEMPT_VOLUNTARY和CONFIG_PREEMPT_DESKTOP,它们分别不提供、部分减少和显著减少最坏情况下的调度延迟。 646 647 在应用补丁或将补丁完全包含到主线内核中之后,附加配置项CONFIG_PREEMPT_RT变得可用。 648 如果选择此选项,则Linux将转换为常规的实时操作系统。 649 然后使用FIFO和RR调度策略来运行具有真正实时优先级和最小最坏情况调度延迟的线程。 650 */ 651 NOTES 652 The cgroups(7) CPU controller can be used to limit the CPU consumption of groups of processes. 653 654 Originally, Standard Linux was intended as a general-purpose operating system being able to handle background processes, interactive applications, and less demanding real-time applications (applications that need to usually meet timing deadlines). Although the Linux kernel 2.6 allowed for kernel preemption and the newly introduced O(1) scheduler ensures that the time needed to schedule is fixed and deterministic irrespective of the number of active tasks, true real-time computing was not possible up to kernel version 2.6.17. 655 656 /* 657 cgroups(7)CPU控制器可以用来限制进程组的CPU消耗。 658 659 最初,标准Linux是作为一个通用的操作系统,能够处理后台进程,交互式应用程序和要求不高的实时应用程序(通常需要满足时间期限的应用程序)。 660 尽管Linux内核2.6允许内核抢占,并且新引入的O(1)调度器确保调度所需的时间是固定的和确定的,而不管活动任务的数量如何, 661 但真正的实时计算在内核版本2.6.17之前是不可能的。 662 */ 663 664 SEE ALSO 665 chcpu(1), chrt(1), lscpu(1), ps(1), taskset(1), top(1), getpriority(2), mlock(2), mlockall(2), munlock(2), munlockall(2), nice(2), 666 sched_get_priority_max(2), sched_get_priority_min(2), sched_getaffinity(2), sched_getparam(2), sched_getscheduler(2), 667 sched_rr_get_interval(2), sched_setaffinity(2), sched_setparam(2), sched_setscheduler(2), sched_yield(2), setpriority(2), 668 pthread_getaffinity_np(3), pthread_getschedparam(3), pthread_setaffinity_np(3), sched_getcpu(3), capabilities(7), cpuset(7) 669 670 Programming for the real world - POSIX.4 by Bill O. Gallmeister, O'Reilly & Associates, Inc., ISBN 1-56592-074-0. 671 672 The Linux kernel source files 673 Documentation/scheduler/sched-deadline.txt, 674 Documentation/scheduler/sched-rt-group.txt, 675 Documentation/scheduler/sched-design-CFS.txt, 676 and 677 Documentation/scheduler/sched-nice-design.txt 678 679 COLOPHON 680 This page is part of release 5.05 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at https://www.kernel.org/doc/man-pages/. 681 682 Linux
3.pthread_setaffinity_np
1 PTHREAD_SETAFFINITY_NP(3) Linux Programmer's Manual PTHREAD_SETAFFINITY_NP(3) 2 3 NAME 4 pthread_setaffinity_np, pthread_getaffinity_np - set/get CPU affinity of a thread 5 // 设置/获取线程的CPU亲和性 6 SYNOPSIS 7 #define _GNU_SOURCE /* See feature_test_macros(7) */ 8 #include <pthread.h> 9 10 int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, 11 const cpu_set_t *cpuset); 12 int pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, 13 cpu_set_t *cpuset); 14 15 Compile and link with -pthread. 16 17 DESCRIPTION 18 The pthread_setaffinity_np() function sets the CPU affinity mask of the thread thread to the CPU set pointed to by cpuset. If the call is successful, 19 and the thread is not currently running on one of the CPUs in cpuset, then it is migrated to one of those CPUs. 20 21 The pthread_getaffinity_np() function returns the CPU affinity mask of the thread thread in the buffer pointed to by cpuset. 22 23 For more details on CPU affinity masks, see sched_setaffinity(2). For a description of a set of macros that can be used to manipulate and inspect CPU 24 sets, see CPU_SET(3). 25 26 The argument cpusetsize is the length (in bytes) of the buffer pointed to by cpuset. Typically, this argument would be specified as sizeof(cpu_set_t). 27 (It may be some other value, if using the macros described in CPU_SET(3) for dynamically allocating a CPU set.) 28 29 /*************************************************************************************************************************** 30 pthread_setaffinity_np()函数的作用是:将线程的CPU亲和掩码设置为cpuset指向的CPU集。 31 如果调用成功,并且线程当前不在cpuset中的一个CPU上运行,则将其迁移到这些CPU中的一个。 32 33 pthread_getaffinity_np() 函数的作用是:返回cpuset指向的缓冲区中线程的CPU亲和掩码。 34 35 有关CPU关联掩码的更多详细信息,请参见sched_setaffinity(2)。 36 有关可用于操作和检查CPU的一组宏的说明,请参见设置,参见CPU_SET(3)。 37 38 参数cpusetsize是cpuset指向的缓冲区的长度(以字节为单位)。 39 通常情况下,此参数将被指定为sizeof(cpu_set_t)。 40 (如果使用CPU_SET(3)中描述的宏来动态分配CPU集,则可以是其他值。) 41 ****************************************************************************************************************************/ 42 RETURN VALUE 43 On success, these functions return 0; on error, they return a nonzero error number. 44 45 ERRORS 46 EFAULT A supplied memory address was invalid. /*EFAULT提供的内存地址无效。*/ 47 48 EINVAL (pthread_setaffinity_np()) The affinity bit mask mask contains no processors that are currently physically on the system and permitted to the 49 thread according to any restrictions that may be imposed by the "cpuset" mechanism described in cpuset(7). 50 /********************************************************** 51 EINVAL(pthread_setaffinity_np()) 52 亲和位掩码不包含当前物理上位于系统上的处理器, 53 并且根据cpuset(7)中描述的“cpuset”机制可能施加的任何限制,该掩码允许线程使用。 54 ***********************************************************/ 55 56 EINVAL (pthread_setaffinity_np()) cpuset specified a CPU that was outside the set supported by the kernel. (The kernel configuration option CON‐ 57 FIG_NR_CPUS defines the range of the set supported by the kernel data type used to represent CPU sets.) 58 59 /******************************************************* 60 * cpuset指定了一个内核支持的CPU集之外的CPU。 61 (内核配置选项CON-FIG_NR_CPUS定义用于表示CPU集的内核数据类型所支持的集的范围。 62 ********************************************************/ 63 64 EINVAL (pthread_getaffinity_np()) cpusetsize is smaller than the size of the affinity mask used by the kernel. 65 /* cpusetsize小于内核使用的亲和掩码的大小。 */ 66 67 ESRCH No thread with the ID thread could be found. 68 /*找不到具有此ID的线程。*/ 69 70 71 VERSIONS 72 These functions are provided by glibc since version 2.3.4. 73 74 ATTRIBUTES 75 For an explanation of the terms used in this section, see attributes(7). 76 77 ┌──────────────────────────┬───────────────┬─────────┐ 78 │Interface │ Attribute │ Value │ 79 ├──────────────────────────┼───────────────┼─────────┤ 80 │pthread_setaffinity_np(), │ Thread safety │ MT-Safe │ 81 │pthread_getaffinity_np() │ │ │ 82 └──────────────────────────┴───────────────┴─────────┘ 83 CONFORMING TO 84 These functions are nonstandard GNU extensions; hence the suffix "_np" (nonportable) in the names. 85 86 NOTES 87 After a call to pthread_setaffinity_np(), the set of CPUs on which the thread will actually run is the intersection of the set specified in the cpuset 88 argument and the set of CPUs actually present on the system. The system may further restrict the set of CPUs on which the thread runs if the "cpuset" 89 mechanism described in cpuset(7) is being used. These restrictions on the actual set of CPUs on which the thread will run are silently imposed by the 90 kernel. 91 92 These functions are implemented on top of the sched_setaffinity(2) and sched_getaffinity(2) system calls. 93 94 In glibc 2.3.3 only, versions of these functions were provided that did not have a cpusetsize argument. Instead the CPU set size given to the underly‐ 95 ing system calls was always sizeof(cpu_set_t). 96 97 A new thread created by pthread_create(3) inherits a copy of its creator's CPU affinity mask. 98 99 /** 100 在调用pthread_setaffinity_np()之后,线程实际运行的CPU集是cpuset参数中指定的CPU集和系统上实际存在的CPU集的交集。 101 如果正在使用cpuset(7)中描述的“cpuset”机制,则系统可以进一步限制线程在其上运行的CPU的集合。 102 这些对线程将在其上运行的实际CPU集的限制是由内核静默地施加的。 103 104 这些函数在sched_setaffinity(2)和sched_getaffinity(2)系统调用之上实现。 105 106 仅在glibc 2.3.3中,这些函数的版本没有cpusetsize参数。 相反,底层系统调用的CPU集大小总是sizeof(cpu_set_t)。 107 108 由pthread_create(3)创建的新线程继承其创建者的CPU关联掩码的副本。 109 */ 110 111 EXAMPLE 112 In the following program, the main thread uses pthread_setaffinity_np() to set its CPU affinity mask to include CPUs 0 to 7 113 (which may not all be avail‐ able on the system), 114 and then calls pthread_getaffinity_np() to check the resulting CPU affinity mask of the thread. 115 116 /*在下面的程序中,主线程使用pthread_setaffinity_np()将其CPU亲和掩码设置为包括CPU 0到7(在系统上可能不全可用), 117 然后调用pthread_getaffinity_np()检查线程的CPU亲和掩码。*/ 118 119 #define _GNU_SOURCE 120 #include <pthread.h> 121 #include <stdio.h> 122 #include <stdlib.h> 123 #include <errno.h> 124 125 #define handle_error_en(en, msg) \ 126 do { errno = en; perror(msg); exit(EXIT_FAILURE); } while (0) 127 128 int 129 main(int argc, char *argv[]) 130 { 131 int s, j; 132 cpu_set_t cpuset; 133 pthread_t thread; 134 135 thread = pthread_self(); 136 137 /* Set affinity mask to include CPUs 0 to 7 */ 138 139 CPU_ZERO(&cpuset); 140 for (j = 0; j < 8; j++) 141 CPU_SET(j, &cpuset); 142 143 s = pthread_setaffinity_np(thread, sizeof(cpu_set_t), &cpuset); 144 if (s != 0) 145 handle_error_en(s, "pthread_setaffinity_np"); 146 147 /* Check the actual affinity mask assigned to the thread */ 148 149 s = pthread_getaffinity_np(thread, sizeof(cpu_set_t), &cpuset); 150 if (s != 0) 151 handle_error_en(s, "pthread_getaffinity_np"); 152 153 printf("Set returned by pthread_getaffinity_np() contained:\n"); 154 for (j = 0; j < CPU_SETSIZE; j++) 155 if (CPU_ISSET(j, &cpuset)) 156 printf(" CPU %d\n", j); 157 158 exit(EXIT_SUCCESS); 159 } 160 161 SEE ALSO 162 sched_setaffinity(2), CPU_SET(3), pthread_attr_setaffinity_np(3), pthread_self(3), sched_getcpu(3), cpuset(7), pthreads(7), sched(7) 163 164 COLOPHON 165 This page is part of release 5.05 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest ver‐ 166 sion of this page, can be found at https://www.kernel.org/doc/man-pages/. 167 168 Linux 2019-03-06 PTHREAD_SETAFFINITY_NP(3) 169 ~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号