安装solr + IK分词器
技术概述,描述这个技术是做什么
在我们开发一个搜索功能的时候,如果采用SQL 语句来查找 数据,需要使用 like % + 字符 + % 的情况下,会导致索引失效
会导致索引失效,所以推荐使用搜索引擎来实现相关的功能。
Solr作为一个外国开发的搜索引擎,自带的分词器无法对中文进行分词,所以需要安装IK分词器进行配合使用
实现过程
1.docker 拉取solr镜像
docker pull solr
2.创建并运行的solr容器
docker run --name solr -d -p 8983:8983 solr
3.防火墙放行相关端口
firewall-cmd --zone=public --add-port=8983/tcp --permanent
firewall-cmd --reload
4.创建核心
在浏览器输入主机号:端口号会出现一下页面
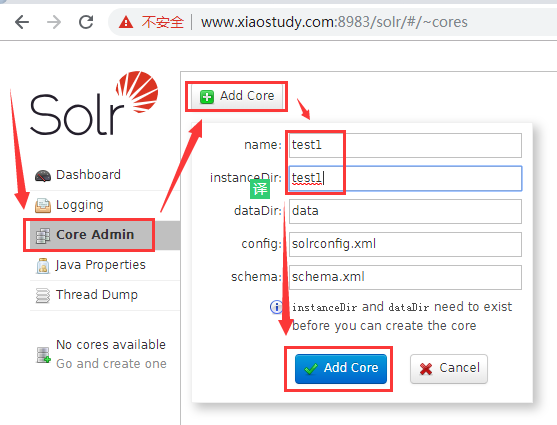
会出现

进入solr容器

复制配置文件到core文件夹


出现这个说明成功
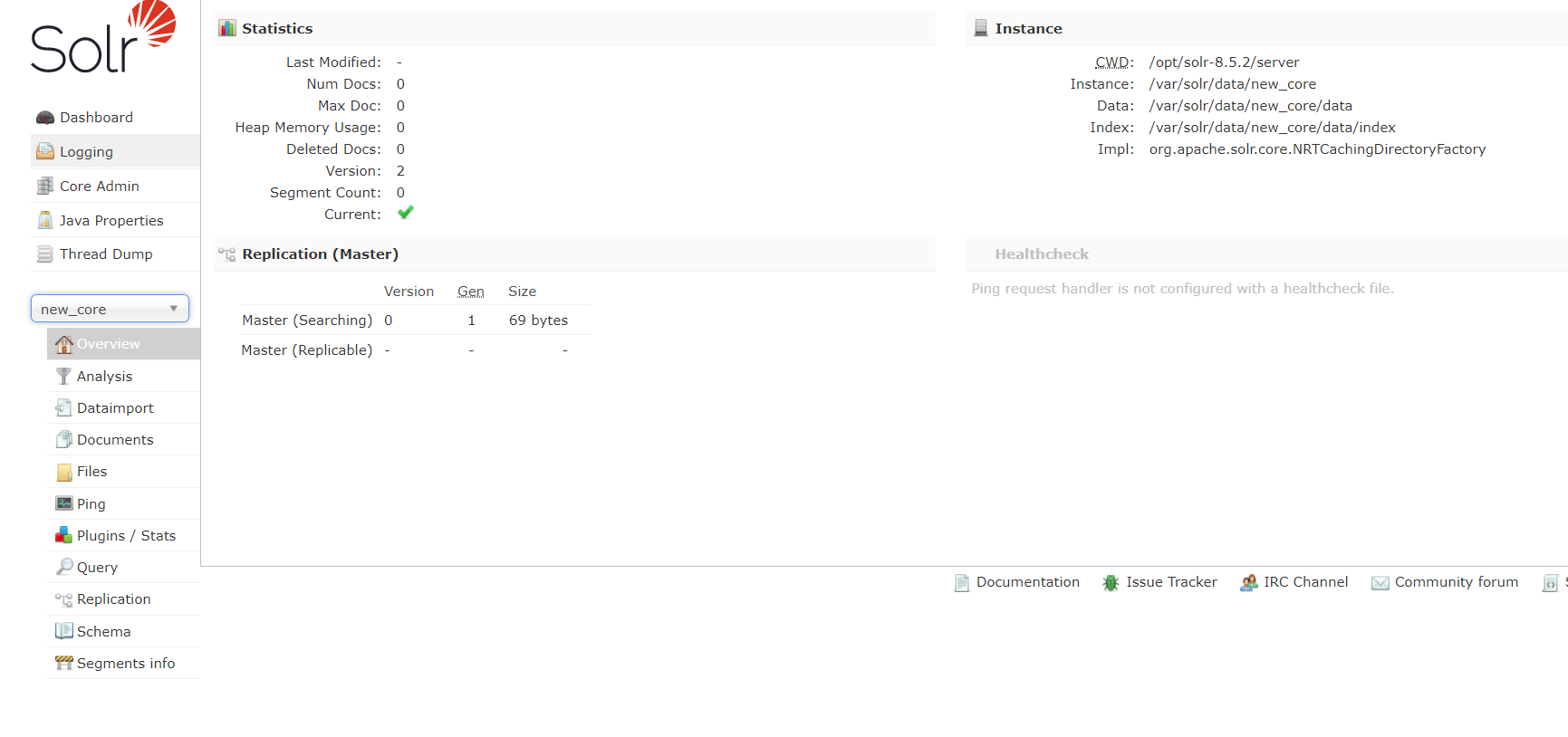
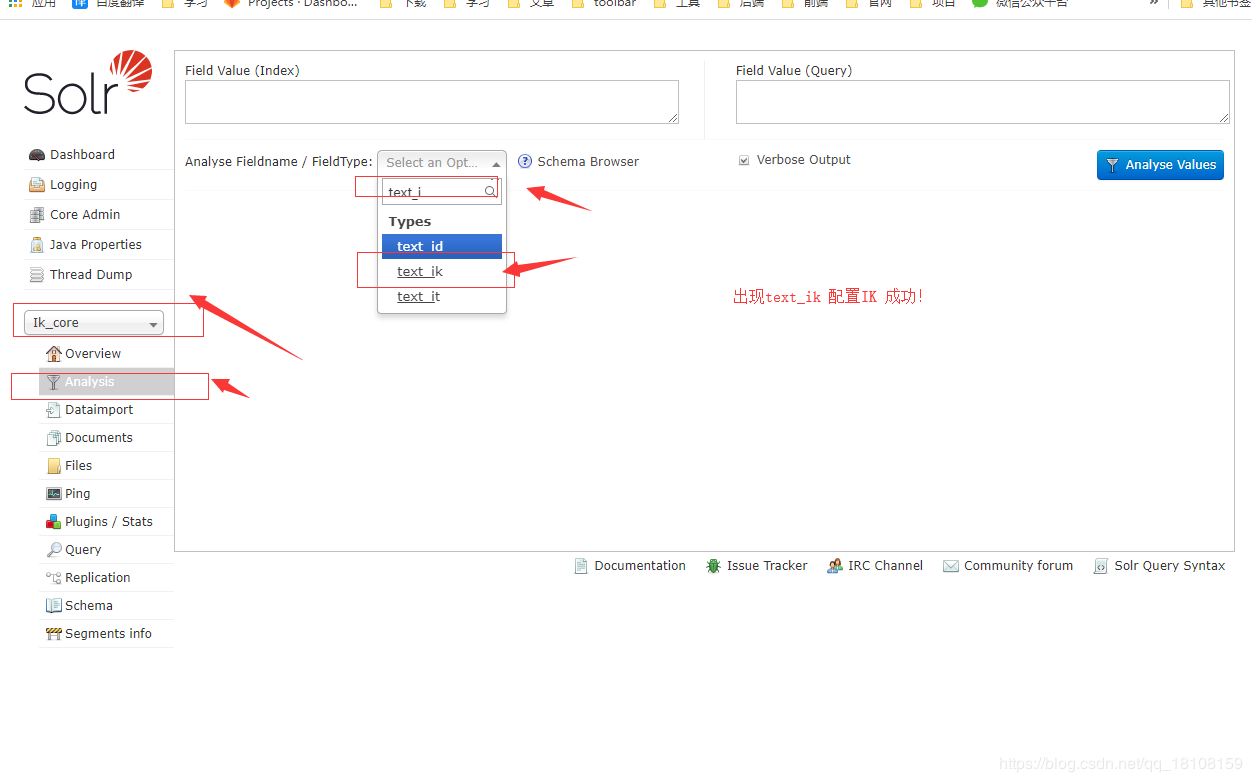
5.安装IK分词器
到下方地址下载IK分词器的资源
https://github.com/magese/ik-analyzer-solr
用root身份进入容器
docker exec -it --user=root solr /bin/bash
在容器内安装vim
apt-get update
apt-get install vim
进入下面文件夹
cd /opt/solr-x.x.0/server/solr-webapp/webapp/WEB-INF
创建文件夹(classes)
mkdir classes
退出容器:
将jar包放入Solr服务Tomcat的webapp/WEB-INF/lib/目录下
将resources目录下的5个配置文件放入solr服务Tomcat的webapp/WEB-INF/classes/目录下
- IKAnalyzer.cfg.xml
- ext.dic
- stopword.dic
- ik.conf
- dynamicdic.txt
docker cp IKAnalyzer.cfg.xml solr:/opt/solr-x.x.0/server/solr-webapp/webapp/WEB-INF/classes/
docker cp ext.dic solr:/opt/solr-x.x.0/server/solr-webapp/webapp/WEB-INF/classes/
docker cp stopword.dic solr:/opt/solr-x.x.0/server/solr-webapp/webapp/WEB-INF/classes/
docker cp ik.conf solr:/opt/solr-x.x.0/server/solr-webapp/webapp/WEB-INF/classes/
docker cp dynamicdic.txt solr:/opt/solr-x.x.0/server/solr-webapp/webapp/WEB-INF/classes/
修改managed-schema
docker exec -it solr /bin/bash
cd /var/solr/data/核心/conf
vim managed-schema
添加ik分词器,示例如下;
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
ok,配置IK 完成,退出容器:exit
重启solr 的容器:
docker restart solr
在浏览器输入主机号:8983