A星搜索算法的更多细节
A*搜索算法的更多内容
【2025.10.28】更新了泛用「A*搜索器」的实现,添加了示例项目:八叉树结合A*
A*算法,也许你会习惯称它为「A*寻路算法」。许多人大概是因寻路——尤其是「网格地图」寻路认识它的,网上很多教程也是以网格地图为例讲解它的算法实现。这导致了许多人在遇到同样用了A*算法的地方,例如GOAP或者基于八叉树的立体空间寻路时会一头雾水:A*算法原来有这么多「变种」吗(⊙ˍ⊙)?其实A*算法是没有变的,只是我们原先 错误地将它与「网络地图」捆绑在了一起。A*算法本身是一种 搜索算法,这次我们从另一视角看看「A*搜索算法」,并一起完成一个更泛用的「A*搜索器」,最后再探讨一些常见的正确优化方式与错误优化方式。
注意:本文并不会详细将A*算法的逻辑原理,希望你至少已了解用于网格地图的A*寻路算法 ̄へ ̄,本文算是对《人工智能:一种现代的方法(第3版)》第三章以及《游戏人工智能(Game AI Pro)2015版》第17讲相关内容的「复述」,感兴趣的同学可以亲自看看呀~
1. 启发式的搜索策略
「宁滥勿缺」的 「 广度优先搜索(Breath First Search,简称BFS)」和「不撞南墙不回头」的「 深度优先搜索(Depth First Search,简称DFS)」是最为人所知的两种 「盲目搜索策略」 。相比于它们的「一根筋」,有些搜索策略通过 记录些额外信息 就能更清楚地知道往哪搜索 「更有希望」 接近目标,这类搜索策略就是 「启发式搜索策略」 。
我们要讲的A*搜索算法就是启发式搜索策略中最出名的一种,你一定还记得A*算法中的这个式子:f(n) = g(n) + h(n)
这里的g(n)表示 从开始节点 到当前的n节点已经花费的代价,而h(n)表示 该节点 到目标节点 所需的估计代价。可以看出,f(n)可谓「瞻前顾后」,其中h(n),即启发式函数(heuristic function)的设计便是关键所在。
2. 陌生的启发式函数
如果你学过用于网格地图寻路的A*搜索算法的同学,一定会想到h(n)的几种设计方式,比如曼哈顿距离、欧式距离、对角线估价……但这些都是针对网格地图,如果我们面对的是中继点图(Waypoint)呢?

你一时或许的确不知道该怎么设计h(n),但这没关系,你应该清楚的是A*搜索算法的逻辑依旧没变,让我们对A*感到陌生的原因仅仅是 启发式函数不同 而已。
h(n)会根据搜索问题的不同而不同,比如,在GOAP中h(n)需要被设计为能估计当前状态与目标状态的接近程度的函数,这比起寻路时的距离估计明显抽象了不少。但设计h(n)依旧是有思路可循的:
- 可采纳性。可采纳性是指h(n)从不会过高(超过实际的)估计到达目标的代价。也就是说要「乐观」,h(n)估计的到达目标的代价值要小于实际执行时的代价。比如,我们在网格地图寻路时,如果允许角色斜向移动的话,一般都不会采用曼哈顿距离。因为我们都知道:三角形的两边之和大于第三边,假设实际中,当前节点n与目标节点就是一条线过去,那么曼哈顿距离这种「横平竖直」的估计方式就导致 估计值 > 实际值,不够「乐观」。

- 一致性。对于用于图搜索的A*算法,通常h(n)都是满足一致性的。「一致」说的是这么一回事:假设,现在处于n节点,我们可以采取任一行动抵达下个节点n1(下图中由红圈表示),我们需要保证 h(n) 不能大于「n→n1花费的代价 + h(n1) 」,通俗地说就是「不能与过去的h(n)的预测相矛盾」,如果h(n)不满足一致性的话,即 h(n) > 「n→n1花费的代价 + h(n1) 」,很明显h(n)的就不满足可采纳性了。这样的h(n)无法保障找到最优解。

3. 泛用的A*搜索算法
了解了这些,我们可以开始设计A*算法的通用结构了。我们需要实现四个东西:节点、边、路径返回容器以及最重要的A*搜索器。
节点接口
- 大多数情况下,我们需要记录节点的 父节点,以便搜索完成时可以回溯生成路径;但有时,我们也会关心这个节点是怎么到另一个节点的,也就是连接两个节点的边是怎样的,所以我们可以让节点中再包含 抵达父节点所用的边。
- 节点应当有用于 记录f(n)、g(n)、h(n)的值。
- 由于启发式函数的设计需要,节点需要 衡量从当前节点到目标节点代价 的函数。
- 节点还需要能 查找邻居节点 的方法。
- 还有十分重要的一点:两个节点到底怎样算相同?搜索时的同一性判断往往与对象默认的相等不同,而最好也别通过复写
Equal函数的方式来这么做,因为这可能会影响哈希表、字典等数据结构的存储判断,所以我们也为 节点的一致性判断 提供一个专门的函数
/// <summary>
/// A星节点接口(关联节点+边)
/// </summary>
/// <typeparam name="T_Node">节点类型</typeparam>
/// <typeparam name="T_Edge">边类型</typeparam>
public interface IAStarNode<T_Node, T_Edge>
where T_Node : IAStarNode<T_Node, T_Edge>, IComparable<T_Node>
{
T_Node Parent { get; set; } // 父节点
T_Edge ParentEdge { get; set; } // 父节点→当前节点的边
float GCost { get; set; } // 起点到当前节点的累计代价
float HCost { get; set; } // 当前节点到终点的估计代价
float FCost => GCost + HCost; // 总代价
/// <summary>计算与目标节点的启发式距离</summary>
float GetHeuristicDistance(T_Node targetNode);
/// <summary>获取后继节点+对应边</summary>
IEnumerable<(T_Node Successor, T_Edge Edge)> GetSuccessorsWithEdges(object nodeMap);
/// <summary> 与other相比,是否算相同,用于A星搜索时两个节点的比较</summary>
bool IsSameWith(T_Node other);
/// <summary>重置节点的搜索相关状态/// </summary>
void Reset();
}
需要注意的是,这里的 GetSuccessorsWithEdges 函数并没有返回容器,而是返回 IEnumerable。采用 IEnumerable + yield return 能动态生成后继节点,遍历到需要的元素时才生成,未遍历到的元素不会被创建,算是有利于性能。
边接口
边的接口,我们让它简单的实现一个获取边代价的属性,这样能动态地获取边的代价。接口所需内容仅此而已吗?是的,但在具体实现下,边中的内容可能会很丰富,不过只是与 A* 相关的话,这样就够了。
/// <summary>
/// 边代价接口(统一获取边的代价)
/// </summary>
public interface IAStarEdge
{
float Cost { get; }
}
/// <summary>
/// float 作为边类型时的包装器(隐式转换)
/// </summary>
public struct FloatEdge : IAStarEdge
{
public float Cost { get; private set; }
public FloatEdge(float cost) => Cost = cost;
public static implicit operator FloatEdge(float v) => new(v);
public static implicit operator float(FloatEdge e) => e.Cost;
}
路径返回容器
选择合适的路径存储方式是有必要的,我们设想两种场景:正向搜索与反向搜索
- 在正向搜索时,我们从起点找到了终点,我们现在处在终点的位置。现在要从终点往父节点溯回最终得到一条路径,如果只是单纯的用列表来存储的话,我们只会得到一个由终点到起点的路径,还得再反向遍历才能得到正确的路径。可如果我们是用
栈(Stack)存储的话,出栈顺序就是正确的序列。 - 反向搜索与正向搜索相反,最终我们会到起点的位置,此时一路回溯的顺序就是正确序列。
所以,我们可以为不同的搜索方式选择合适的路径容器:
/// <summary>
/// 路径集合的通用操作接口
/// </summary>
/// <typeparam name="T">集合元素类型</typeparam>
public interface IPathCollection<T> : IEnumerable<T>
{
void Add(T item); // 添加元素(Enqueue/Push)
void Clear(); // 清空集合
bool TryTake(out T item); // 安全取出元素(TryDequeue/TryPop)
}
/// <summary>
/// Queue 的路径集合适配器,正向溯回路径
/// </summary>
public class QueuePathCollection<T> : IPathCollection<T>
{
private readonly Queue<T> _queue;
public QueuePathCollection()
{
_queue = new Queue<T>();
}
public void Add(T item) => _queue.Enqueue(item); // 映射到 Queue.Enqueue
public void Clear() => _queue.Clear();
public bool TryTake(out T item) => _queue.TryDequeue(out item);
// 实现 IEnumerable<T> 接口的迭代器(复用 Queue 的迭代器)
public IEnumerator<T> GetEnumerator() => _queue.GetEnumerator();
// 显式实现非泛型 IEnumerable 接口(调用泛型版本)
IEnumerator IEnumerable.GetEnumerator() => GetEnumerator();
}
/// <summary>
/// Stack 的路径集合适配器,反向溯回路径
/// </summary>
public class StackPathCollection<T> : IPathCollection<T>
{
private readonly Stack<T> _stack;
public StackPathCollection()
{
_stack = new Stack<T>();
}
public void Add(T item) => _stack.Push(item); // 映射到 Stack.Push
public void Clear() => _stack.Clear();
public bool TryTake(out T item) => _stack.TryPop(out item);
// 实现 IEnumerable<T> 接口的迭代器(复用 Stack 的迭代器)
public IEnumerator<T> GetEnumerator() => _stack.GetEnumerator();
// 显式实现非泛型 IEnumerable 接口(调用泛型版本)
IEnumerator IEnumerable.GetEnumerator() => GetEnumerator();
}
A*搜索器
A*搜索器只负责搜索(寻路)并返回搜索的序列结果(路径)
- 有的任务关注节点,有的任务关注边,但无论是节点还是边,搜索时的逻辑是相同的,就不写成两个函数了。我们通过传入的参数来最终要收集节点还是边。
- 维护openList与closeList。 这是A*搜索所依赖的额外信息,在搜索过程中,那些有被搜过但还没被选中要走的节点就会放在「边缘集(openList)」中 ;而已经走过的节点则会放在「搜索集(closeList)」中。A*搜索便会不断地将结点加入到openList以备选,并不断地将走过的节点加入closeList以避免重复搜索。
- 生成路径。 在找到了目标(或实在找不到目标)时,我们需要返回一路走来的所有节点或者边,我们要考虑它们的顺序,而且最好能将路径返回到一个外部容器中存储,而不是函数内创建用于存储的容器再返回出去。为什么?因为大多数情况下,我们是为对象单独分配一个搜索的结果,比如每个角色都有自己的路径,这是个一对一的关系。如果采用后者的方案,那么即便只有一个角色要寻路,我们也会每次在生成路径时,就会重复创建容器并返回,是十分浪费的。

下面就来看看具体代码吧:
using System;
using System.Collections.Generic;
using UnityEngine;
/// <summary>
/// 泛用A星搜索器
/// </summary>
/// <typeparam name="T_Map">搜索空间</typeparam>
/// <typeparam name="T_Node">节点类型</typeparam>
/// <typeparam name="T_Edge">边类型(需实现IHasCost)</typeparam>
public class AStarSearcher<T_Map, T_Node, T_Edge>
where T_Node : IAStarNode<T_Node, T_Edge>, IComparable<T_Node>
where T_Edge : IAStarEdge
{
private readonly HashSet<T_Node> closeList = new();
private readonly MyHeap<T_Node> openList;
private readonly T_Map nodeMap;
private readonly int maxSteps; // 最大搜索步数(防死循环)
#region 构造函数
public AStarSearcher(T_Map map, int maxHeapSize = 200, int maxSearchSteps = 1000)
{
nodeMap = map;
maxSteps = maxSearchSteps;
openList = new MyHeap<T_Node>(maxHeapSize, isMinHeap: true); // A星默认小根堆
}
#endregion
#region 核心搜索方法
/// <summary>
/// 执行A星搜索,按需收集路径
/// </summary>
/// <param name="start">起点</param>
/// <param name="target">终点</param>
/// <param name="nodePath">接收节点路径(传null则不记录)</param>
/// <param name="edgePath">接收边路径(传null则不记录)</param>
/// <returns>是否成功找到路径</returns>
public bool FindPath(
T_Node start,
T_Node target,
IPathCollection<T_Node> nodePath = null,
IPathCollection<T_Edge> edgePath = null)
{
nodePath?.Clear();
edgePath?.Clear();
closeList.Clear();
openList.Clear();
// 合法性校验
if (start == null || target == null)
{
Debug.LogWarning("起点/终点不能为null");
return false;
}
if (start.IsSameWith(target))
{
Debug.LogWarning("起点与终点相同,无需搜索");
return true;
}
// 起点入队
start.GCost = 0;
start.HCost = start.GetHeuristicDistance(target);
start.Parent = default;
start.ParentEdge = default;
openList.Push(start);
// 搜索主循环
int stepCount = 0;
while (!openList.IsEmpty && stepCount < maxSteps)
{
stepCount++;
var curNode = openList.Peak;
openList.Pop();
// 找到终点:生成路径并返回
if (curNode.IsSameWith(target))
{
GeneratePath(start, curNode, nodePath, edgePath);
return true;
}
// 跳过已探索节点
if (!closeList.Contains(curNode))
{
closeList.Add(curNode);
UpdateSuccessors(curNode, target);// 处理后继节点
}
}
// 搜索失败(无路径/超时)
Debug.LogWarning($"A星搜索失败:{(openList.IsEmpty ? "无可达路径" : $"超过最大步数({maxSteps})")}");
return false;
}
#endregion
#region 辅助方法
/// <summary>处理后继节点(更新代价与父关联)</summary>
private void UpdateSuccessors(T_Node curNode, T_Node target)
{
var successors = curNode.GetSuccessorsWithEdges(nodeMap);
if (successors == null)
return;
foreach (var (sucNode, edge) in successors)
{
if (closeList.Contains(sucNode))
continue;
// 计算新代价(边的代价属于边,而非节点)
float newGCost = curNode.GCost + edge.Cost;
bool isInOpenList = openList.Contains(sucNode);
// 新节点入队 或 已有节点更新代价
if (!isInOpenList)
{
sucNode.GCost = newGCost;
sucNode.HCost = sucNode.GetHeuristicDistance(target);
sucNode.Parent = curNode;
sucNode.ParentEdge = edge;
openList.Push(sucNode);
}
else if (newGCost < sucNode.GCost)
{
sucNode.GCost = newGCost;
sucNode.Parent = curNode;
sucNode.ParentEdge = edge;
openList.UpdateNodePriority(sucNode); // 更新堆优先级
}
}
}
/// <summary>
/// 生成路径
/// </summary>
private void GeneratePath(
T_Node start,
T_Node end,
IPathCollection<T_Node> nodes,
IPathCollection<T_Edge> edges)
{
var recNodes = nodes != null;
var recEdges = edges != null;
if (recNodes || recEdges)
{
var cur = end;
// 回溯路径时:
// 节点:从终点 push 到起点
// 边:从终点对应的 ParentEdge push,最后栈里顺序就是起点→终点
while (cur != null)
{
if (recNodes)
nodes.Add(cur);
if (recEdges && cur.ParentEdge != null)
edges.Add(cur.ParentEdge);
if (cur.IsSameWith(start))
break;
cur = cur.Parent;
}
}
}
#endregion
}
上面有用到自己实现的优先队列(MyHeap),如果你也有自己的实现也可以进行替换。如果没有的话,可以暂时用用我的:
using System;
using System.Collections.Generic;
public class MyHeap<T> where T : IComparable<T>
{
public int CurLength {get; private set;}
public readonly int capacity;
public bool IsFull => CurLength == capacity;
public bool IsEmpty => CurLength == 0;
public T Peak => heapArr[0];
private readonly bool isMinHeap; // true=小根堆(A星默认),false=大根堆
private readonly T[] heapArr;
private readonly Dictionary<T, int> idxTable; //记录结点在数组中的位置,方便查找
public MyHeap(int size, bool isMinHeap = false)
{
CurLength = 0;
capacity = size;
heapArr = new T[size];
idxTable = new Dictionary<T, int>();
this.isMinHeap = isMinHeap;
}
public void Push(T value)
{
if(!IsFull)
{
if (idxTable.ContainsKey(value))
idxTable[value] = CurLength;
else
idxTable.Add(value, CurLength);
heapArr[CurLength] = value;
Swim(CurLength++);
}
}
public void Pop()
{
if(!IsEmpty)
{
idxTable[heapArr[0]] = -1;
heapArr[0] = heapArr[--CurLength];
idxTable[heapArr[0]] = 0;
Sink(0);
}
}
/// <summary>
/// 更新节点优先级(当节点的比较属性变化时调用,如A星节点的FCost变化)
/// </summary>
public bool UpdateNodePriority(T value)
{
if (!idxTable.ContainsKey(value))
{
return false;
}
int index = idxTable[value];
Swim(index); // 先尝试上浮(代价变小,优先级提高)
Sink(index); // 再尝试下沉(代价变大,优先级降低)
return true;
}
public bool Contains(T value)
{
return idxTable.ContainsKey(value) && idxTable[value] > -1;
}
public T Find(T value)
{
return Contains(value) ? heapArr[idxTable[value]] : default;
}
public void Clear()
{
idxTable.Clear();
CurLength = 0;
}
private void Swim(int index)
{
int father;
while(index > 0)
{
father = (index - 1) / 2;
if(IsBetter(heapArr[index], heapArr[father]))
{
SwapValueByIndex(father, index);
index = father;
}
else return;
}
}
private void Sink(int index)
{
int best, left = index * 2 + 1, right;
while(left < CurLength)
{
right = left + 1;
best = right < CurLength && IsBetter(heapArr[right], heapArr[left]) ? right : left;
if(IsBetter(heapArr[best], heapArr[index]))
{
SwapValueByIndex(best, index);
index = best;
left = index * 2 + 1;
}
else return;
}
}
private void SwapValueByIndex(int i, int j)
{
(heapArr[j], heapArr[i]) = (heapArr[i], heapArr[j]);
idxTable[heapArr[i]] = i;
idxTable[heapArr[j]] = j;
}
private bool IsBetter(T v1, T v2)
{
return isMinHeap && (v1.CompareTo(v2) < 0);
}
}
4. 正确优化A*的方式
- 良好的启发式函数。 前面我们讨论的那些正好可以说明这一点,故不再赘述。
- 合适的搜索空间表示。 「搜索空间」可以理解为我们要来寻路的地图,合适的表示能够减少搜索时的结点数量,从而减少搜索时间。一般的表示方式有:网格图、中继点图、导航网络。
(虽说一般也只能自主设计前面两种就是了

- 预分配所有必要的内存。 就是说,在实际搜索时不要分配内存,当然,这并不是说不能使用临时变量,只是说不要使用需要分配大量内存的临时变量,比如一个大数组。如果真有需要,也可以使用像「内存池」提前分配好内存,避免重复的开辟与回收。
- 用优先队列做开结点表(openList)。 A*搜索时常需要找出「开结点表」中最小代价的结点。如果使用「优先队列(一般二叉堆即可)」就可以省去排序的过程,以O(1)的时间复杂度找到这个结点。
- 缓存后继节点。 在静态场景中,一个节点的后继节点(邻居节点)通常是固定的,如果我们在查找一次后就将它们记录下来,那么后续查找可以节省很多时间(因为查找节点的邻居是很经常的事),只不过需要额外的内存开销。
顺带提一下平滑路径的方法,Catmull-Rom 样条可以做到生成一条 穿过所有初始路径点 的曲线,这样能尽可能保证平滑后的路径依旧是通畅的(贝塞尔曲线就无法保证穿过初始点)它的公式如下:
public Vector3 CatmullRom_Normal(float u, Vector3 p0, Vector3 p1, Vector3 p2, Vector3 p3)
{
return p0 * (-0.5f * u * u * u + u * u - 0.5f * u) +
p1 * (1.5f * u * u * u - 2.5f * u * u + 1.0f) +
p2 * (-1.5f * u * u * u + 2.0f * u * u + 0.5f * u) +
p3 * (0.5f * u * u * u - 0.5f * u * u);
}
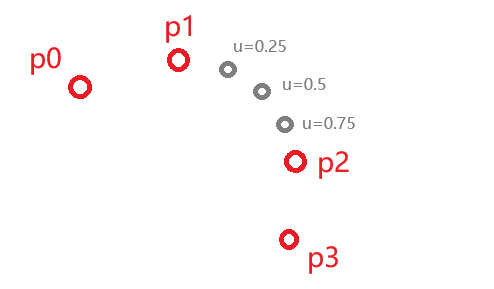
它会在p1和p2之间,近似u%的地方给出一个点,而p0和p3是辅助点。显然它需要四个点输入,但如果是针对起始两个点或者末尾两个点,该如何处理呢?
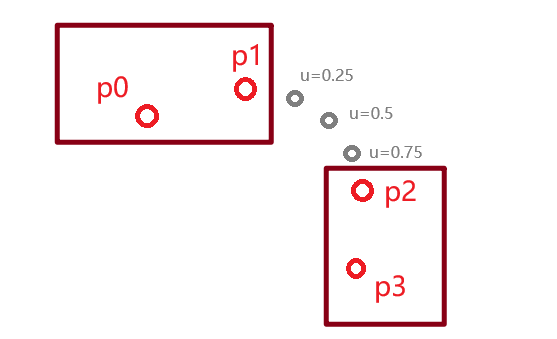
可以把一个点传入两次。对于没有前一个点的情况,可以将第一个点传入p0、p1,接着再正常传入第二个点、第三个点作为p2、p3;对于没有后一个点的情况也是同理,正常传入p0、p1,最后一个点传入两次分别作为p2、p3。
如果你对u的取值间隔已有定数,可以预计算 Catmull-Rom,省去重复计算多个u相乘的结果。例如想将两点分成4段,就需要插入3个点,分别在0.25%、0.5%、0.75%的位置:
// 预计算:u=0.25时的Catmull-Rom
public Vector3 CatmullRom_025u(Vector3 p0, Vector3 p1, Vector3 p2, Vector3 p3)
{
return p0 * (-0.0703125f) + p1 * 0.8671875f + p2 * 0.2265625f + p3 * (-0.0234375f);
}
// 预计算:u=0.5时的Catmull-Rom
public Vector3 CatmullRom_050u(Vector3 p0, Vector3 p1, Vector3 p2, Vector3 p3)
{
return p0 * (-0.0625f) + p1 * 0.5625f + p2 * 0.5625f + p3 * (-0.0625f);
}
// 预计算:u=0.75时的Catmull-Rom
public Vector3 CatmullRom_075u(Vector3 p0, Vector3 p1, Vector3 p2, Vector3 p3)
{
return p0 * (-0.0234375f) + p1 * 0.2265625f + p2 * 0.8671875f + p3 * (-0.0703125f);
}
// 完整获取平滑路径的过程
public List<Vector3> GetSmoothPath_ArticleMethod()
{
List<Vector3> smoothPath = new List<Vector3>();
if (points == null || points.Length < 2)
return smoothPath;
// 转换为世界坐标点列表
List<Vector3> pathPoints = new List<Vector3>();
foreach (var t in points)
pathPoints.Add(t.position);
// 遍历每一段相邻的原始点,为每段构造4个输入点
for (int i = 0; i < pathPoints.Count - 1; ++i)
{
Vector3 p0, p1, p2, p3;
// 构造当前段的4个输入点:
if (i == 0)
{
// 第一段(第1点→第2点):输入“第1点、第1点、第2点、第3点”
p0 = pathPoints[i];
p1 = pathPoints[i];
p2 = pathPoints[i + 1];
p3 = (pathPoints.Count >= 3) ? pathPoints[i + 2] : pathPoints[i + 1]; // 若只有2个点,用第2点代替第3点
}
else if (i == pathPoints.Count - 2)
{
// 最后一段(倒数第2点→最后1点):输入“倒数第3点、倒数第2点、最后1点、最后1点”
p0 = pathPoints[i - 1];
p1 = pathPoints[i];
p2 = pathPoints[i + 1];
p3 = pathPoints[i + 1];
}
else
{
// 中间段:输入“前1点、当前点、下1点、下2点”(正常4个相邻点)
p0 = pathPoints[i - 1];
p1 = pathPoints[i];
p2 = pathPoints[i + 1];
p3 = pathPoints[i + 2];
}
// 采样当前段的曲线点
if(samplePointsPerSegment == 4)
{
smoothPath.Add(p1);
smoothPath.Add(CatmullRom_025u(p0, p1, p2, p3));
smoothPath.Add(CatmullRom_050u(p0, p1, p2, p3));
smoothPath.Add(CatmullRom_075u(p0, p1, p2, p3));
smoothPath.Add(p2);
}
else
{
for (int s = 0; s <= samplePointsPerSegment; s++)
{
float u = s / (float)samplePointsPerSegment;
Vector3 curvePoint = CatmullRom_Normal(u, p0, p1, p2, p3);
smoothPath.Add(curvePoint);
}
}
}
return smoothPath;
}
最终平滑后的路径:
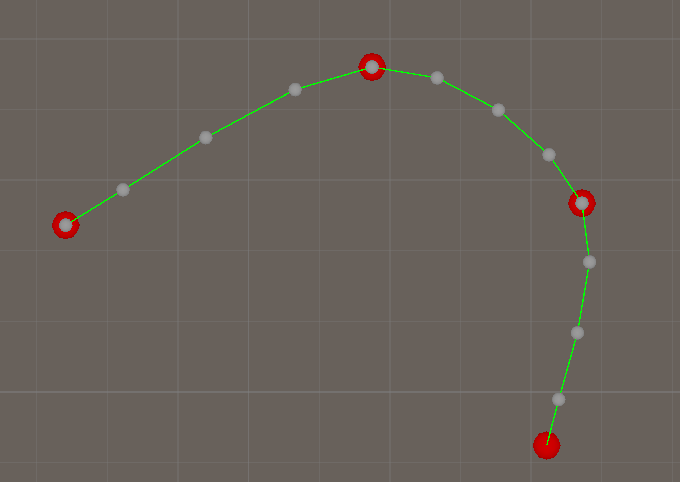
5. 错误优化A*的方式
-
并行执行多个搜索。 通过多线程,我们可以在只消耗一次搜索的时间里同时处理10个搜索,这不是很好吗?问题在于,如果你要同时进行10次搜索,那势必要在单独多开一些openList和closeList,这 需要大量的内存 。而且如果在这10次搜索中,有一次搜索情况「不顺」导致它 拖延了其它的搜索 ,又当如何(做好搜索上限判断,这种情况一般就不会发生)?其实也不是不能使用多线程,我们可以同时只执行2个搜索,一个负责处理较为快速的搜索,另一个负责处理需要长时间的搜索。
-
双向搜索。 可能有些同学曾做过一些搜索相关(主要是关于BFS和DFS)的算法题,发现「双向搜索」似乎能更快地找到路径。但其实这对于A*搜索,会 花费双倍的工作量 。我们可以看看下面几张图(横着看):


通过这两次寻路不难看出,正向寻路所得的路径和反向寻路的 路径重合度非常低 ,换句话说,几乎就是找了两条路。如果你不信,也可以自己动手试试看,在这个网页中找到下图部分,自己编辑下地形、切换起点和终点,观察路径情况。

造成这现象的一大原因,就是正反搜索时同一个节点的h(n)是不同的。因此,如下图般理想的双向搜索,在A*中是很难见到的。

-
缓存路径。 有时可能会想:将这次找到的路保存下来,下次再找时可以直接调用。这种做法的价值并不大,「两次相同的寻路」概率并不大,而且保存过多的路径会占用很大的内存。
6. 尾声
在我初学A*时,总以为它是基于网格寻路而生的一种算法,希望这次与大家交流的内容也能帮助曾经和我一样有类似想法的同学更准确地认识A*。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号