Golang学习笔记(二)—— 基本语法和常见数据结构
Golang基本语法和常见数据结构
变量和常量
变量声明
- 标准声明
var name type
- 批量声明
var ( name1 type1
name2 type2
... )
- 声明时初始化
var name type = value
- 类型推导
var name = value
- 短变量声明
name := value
- 匿名声明
在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线_表示,多用于占位
func foo() (int, string) { return 10, "name" } func main() { x, _ := foo() _, y := foo() fmt.Println("x=", x) fmt.Println("y=", y) }
常量声明
const identifier [type] = value //显式类型定义 const identifier = value //隐式类型定义
-
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型
iota
特殊常量,可以认为是一个可以被编译器修改的常量,代表了const声明块的行索引,可以被用作枚举值:
package main import "fmt" func main() { const ( a = iota //0 b = iota //1 c //2 d = "ha" //独立值,iota += 1 e //"ha" iota += 1 f = 100 //iota +=1 g //100 iota +=1 h = iota //7,恢复计数 i //8 )
const a1 = iota //0 fmt.Println(a,b,c,d,e,f,g,h,i) }
结果为:0 1 2 ha ha 100 100 7 8
如果中断iota自增,则必须显式恢复;自增默认是int类型,可以自行进行显示指定类型。
指针
- 区别于C/C++中的指针,Go语言中的指针不能进行偏移和运算,是安全指针,指针操作只需要记住两个符号:
&(取地址)和*(根据地址取值)即可。 - 空指针的值为nil
new
用于分配内存空间。
func new(Type) *Type —— new函数返回一个指向该类型内存地址的指针
make
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
func make(t Type, size ...IntegerType) Type
1 func main() { 2 var b map[string]int //声明map类型 3 b = make(map[string]int, 10) //初始化,不初始化会引发panic 4 b["测试"] = 100 //赋值 5 fmt.Println(b) 6 }
数据类型
| 布尔型 | bool |
1.布尔类型变量的默认值为 2.Go 语言中不允许将整型强制转换为布尔型. 3.布尔型无法参与数值运算,也无法与其他类型进行转换. |
| 整数型 | int8、int16、int32、int64 | 有符号整型 |
| uint8、uint16、uint32、uint64 | 无符号整型 | |
| int | 32位操作系统上就是int32,64位操作系统上就是int64 |
|
| uint | 32位操作系统上就是uint32,64位操作系统上就是uint64 |
|
| uintptr | 无符号整型,用于存放一个指针 | |
| rune | 代表一个 UTF-8字符,实际上是uint8 |
|
| byte | 代表一个ASCII码字符,实际上是int32 |
|
| 浮点型 | float32、float64 | 浮点型 |
| complex64、complex128 | 复数,实部和虚部各占一半 | |
| 字符串型 | string | Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型一样。 |
| 复合类型 |
1、指针类型(Pointer) 2、数组类型 3、结构化类型(struct) 4、Channel 类型 5、函数类型 6、切片类型 7、接口类型(interface) 8、Map 类型 |
字符串类型
- 字符串修改
字符串是不允许修改的,想要修改字符串,需要先将其转换成 []rune 或 []byte,修改后再转换为 string。无论哪种转换,都会重新分配内存,并复制字节数组。


func chageString() { s1 := "go" byteS1 := []byte(s1) byteS1[0] = 't' fmt.Println(string(byteS1)) s2 := "白萝卜" runeS2 := []rune(s2) runeS2[0] = '胡' fmt.Println(string(runeS2)) }
- 字符串拼接
在Go中,字符串可以很方便的拼接:str := str1 + str2 + str3
字符串拼接在编译时都会被存放到一个切片中,拼接过程需要遍历两次切片,第一次遍历获取总长度,据此申请内存,第二次遍历会把字符串逐个拷贝过去。
为什么字符串不允许修改?
C++语言中的string,其本身拥有内存空间,修改string是支持的。但Go的实现中,string不包含内存空间,只有一个内存的指针,且通常指向字符串字面量,而字符串字面量存储位置是只读段,而不是堆或栈上,所以才有了string不可修改的约定。
[]byte 转换成 string 一定会拷贝内存吗?
在临时需要字符串的场景下,byte切片转换成string时并不会拷贝内存,而是直接返回一个string,这个string的指针(string.str)指向切片的内存。例如以下场景:
- 使用m[string(b)]来查找map(map是string为key,临时把切片b转成string);
- 字符串拼接,如"<" + "string(b)" + ">";
- 字符串比较:string(b) == "foo"
Slice 类型
- Slice又称动态数组,依托数组实现,可以方便的进行扩容、传递等,实际使用中比数组更灵活
切片和数组的关系示意图:

package main import "fmt" func main() { s := []int{0, 1, 2, 3} p := &s[2] // *int, 获取底层数组元素指针。 *p += 100 fmt.Println(s) //输出:[0 1 102 3] s1 := s[0:2] s1[0] += 100 //读写底层数组 fmt.Println(s1) //输出:[100 1] fmt.Println(s) //输出:[100 1 102 3] ... s2 := make([]int, 6, 8) // 使用 make 创建,指定 len 和 cap 值。 fmt.Println(s2, len(s2), cap(s2)) //输出:[0 0 0 0 0 0] 6 8 s3 := make([]int, 6) // 省略 cap,相当于 cap = len。 fmt.Println(s3, len(s3), cap(s3)) //输出:[0 0 0 0 0 0] 6 6 ... data := [][]int{ []int{1, 2, 3}, []int{100, 200}, []int{11, 22, 33, 44}, } fmt.Println(data) //输出:[[1 2 3] [100 200] [11 22 33 44]] }
切片追加
Go语言的内建函数 append() 可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素。还可以使用 append() 来变相删除元素。
func main(){ var s []int s = append(s, 1) // [1] s = append(s, 2, 3, 4) // [1 2 3 4] s2 := []int{5, 6, 7} s = append(s, s2...) // [1 2 3 4 5 6 7]
// 从切片中删除元素
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
// 要删除索引为2的元素
a = append(a[:2], a[3:]...)
fmt.Println(a) //[30 31 33 34 35 36 37]}
字符串切片

切片扩容
切片追加时,由于每个切片会指向一个底层数组,若这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在 append() 函数调用时,所以我们通常都需要用原变量接收 append 函数的返回值。
func main() { //append()添加元素和切片扩容 var numSlice []int for i := 0; i < 10; i++ { numSlice = append(numSlice, i) fmt.Printf("%v len:%d cap:%d ptr:%p\n", numSlice, len(numSlice), cap(numSlice), numSlice) } } 输出: [0] len:1 cap:1 ptr:0xc0000a8000 [0 1] len:2 cap:2 ptr:0xc0000a8040 [0 1 2] len:3 cap:4 ptr:0xc0000b2020 [0 1 2 3] len:4 cap:4 ptr:0xc0000b2020 [0 1 2 3 4] len:5 cap:8 ptr:0xc0000b6000 [0 1 2 3 4 5] len:6 cap:8 ptr:0xc0000b6000 [0 1 2 3 4 5 6] len:7 cap:8 ptr:0xc0000b6000 [0 1 2 3 4 5 6 7] len:8 cap:8 ptr:0xc0000b6000 [0 1 2 3 4 5 6 7 8] len:9 cap:16 ptr:0xc0000b8000 [0 1 2 3 4 5 6 7 8 9] len:10 cap:16 ptr:0xc0000b8000
可以看出:切片容量以 1、2、4、8、16 的规则再扩容,每次扩容后是扩容前的两倍。
源码:runtime/slice.go line:267 func nextslicecap(newLen, oldCap int) int { //newLen = oldLen + num newcap := oldCap doublecap := newcap + newcap if newLen > doublecap { return newLen } const threshold = 256 if oldCap < threshold { return doublecap } for { newcap += (newcap + 3*threshold) >> 2 //从小切片的2倍增长转变为大切片的1.25倍增长。这个公式在两者之间提供了一个平稳的过渡。 if uint(newcap) >= uint(newLen) { //检查newcap >= newLen 和 newcap是否溢出 break } } if newcap <= 0 { //newcap溢出时 return newLen } return newcap } slice扩容源码
从源码中可得:
- 如果新的长度(newlen)大于两倍旧容量(doublecap),最终容量(newcap)就是新的长度(newlen)
- 否则,如果旧容量小于256,最终容量就是两倍旧容量
- 否则,扩容计算方式变为 旧容量 +(旧容量 + 768)/4,也就是扩充(25%+192)的容量,不断扩容直到最终容量大于新长度
- 最后,若newcap溢出后,最终容量 就设为 新的长度
切片拷贝
- 浅拷贝
只拷贝了对象的全部内容,但不拷贝对象的引用的内容
func main() { s1 := make([]int, 3) //[0 0 0] s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组 s2[0] = 100 fmt.Println(s1) //[100 0 0] fmt.Println(s2) //[100 0 0] }
- 深拷贝
使用 Go 语言内建的 copy() 函数可以轻松做到对切片的深拷贝
func main() { // copy()复制切片 a := []int{1, 2, 3, 4, 5} c := make([]int, 5, 5) copy(c, a) //使用copy()函数将切片a中的元素复制到切片c fmt.Println(a) //[1 2 3 4 5] fmt.Println(c) //[1 2 3 4 5] c[0] = 1000 fmt.Println(a) //[1 2 3 4 5] fmt.Println(c) //[1000 2 3 4 5] }
Map 类型
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用
- 使用 make()函数分配内存,语法为:
make ( map[KeyType]ValueType, cap)
- 判断某个键是否存在,语法为:
value,ok := map[key]
- map的遍历
Go 中使用 for range 遍历map
- 使用 delete() 函数删除键值对,语法为:
delete(map, key)
数据结构
-
hmap数据结构
了解map的大致用法后,看一下 map 的底层结构能更好的理解 map,Go 语言中 map 使用哈希表作为底层实现,map 类型的变量本质上是一个指针,指向 hamp 结构体。其数据结构如下:
源码文件:runtime/map.go line:117、134 type hmap struct { count int //当前元素个数 flags uint8 //当前状态 B uint8 //记录桶的数目是2^B noverflow uint16 //记录使用的溢出桶数量 hash0 uint32 //hash种子 buckets unsafe.Pointer //数组指针,记录桶的位置 oldbuckets unsafe.Pointer //扩容时,记录旧桶的位置 nevacuate uintptr //渐进式扩容阶段,记录下一个迁移的旧桶编号 extra *mapextra //指向mapextra结构体,里面记录溢出桶相关信息
}
type mapextra struct {
overflow *[]*bmap //记录已经使用的溢出桶的地址
oldoverflow *[]*bmap //旧桶使用的溢出桶的地址
nextOverflow *bmap //下一个空闲溢出桶的地址
}
一个哈希表可以有多个 bucket (哈希桶),而每个 bucket 能保存若干个键值对。
注意:当B大于4时,会额外创建 2^(B-4) 个桶用作溢出桶 (这些溢出桶和常规桶 在内存中是连续的)
-
bucket数据结构
源码文件:runtime/map.go line:64、151
const bucketCnt = abi.MapBucketCount //=8 type bmap struct { tophash [bucketCnt]uint8 //存储哈希值的高8位
//以下属性在编译期间生成;源码位于 src/cmd/compile/internal/reflectdata/reflect.go:MapBucketType line:91
keys [8]keytype
values [8]valuetype
pad uintptr //用于对齐内存
overflow uintptr //溢出桶的地址}
显而易见,每个桶中定义了有8个哈希值的容量,即每个桶的容量为8,超过8个就要用到溢出桶。
除此之外,bucket 还有一些属性会在编译时动态生成,因为哈希表中可能存储不同类型的键值对,而且 Go 语言也不支持泛型,所以键值对占据的内存空间大小只能在编译时进行推导。
整体结构如下:

哈希冲突
从数据结构就能看出来,Go 语言使用拉链法来解决哈希冲突
负载因子用于衡量一个哈希表冲突情况,公式为:负载因子 = 键值对数量 / bucket 数量
- 负载因子过小,说明空间利用率低
- 负载因子过大,说明冲突严重,存取效率低
负载因子同时也作为是否需要扩容的判断依据。
map扩容
触发扩容的条件有二个:
- 负载因子 > 6.5时,也即平均每个 bucket 存储的键值对达到6.5个。
- noverflow >= 2^15(B > 15)或 noverflow >= 2^B(B <= 15) 时,也即溢出桶数量 超过 常规桶数量 或 32768 时。
条件不同触发的扩容方法也不同:
- 增量扩容
当负载因子过大时,就新建一个 bucket,新的 bucket 长度是原来的2倍,然后旧 bucket 数据分流到两个新的 bucket 中。
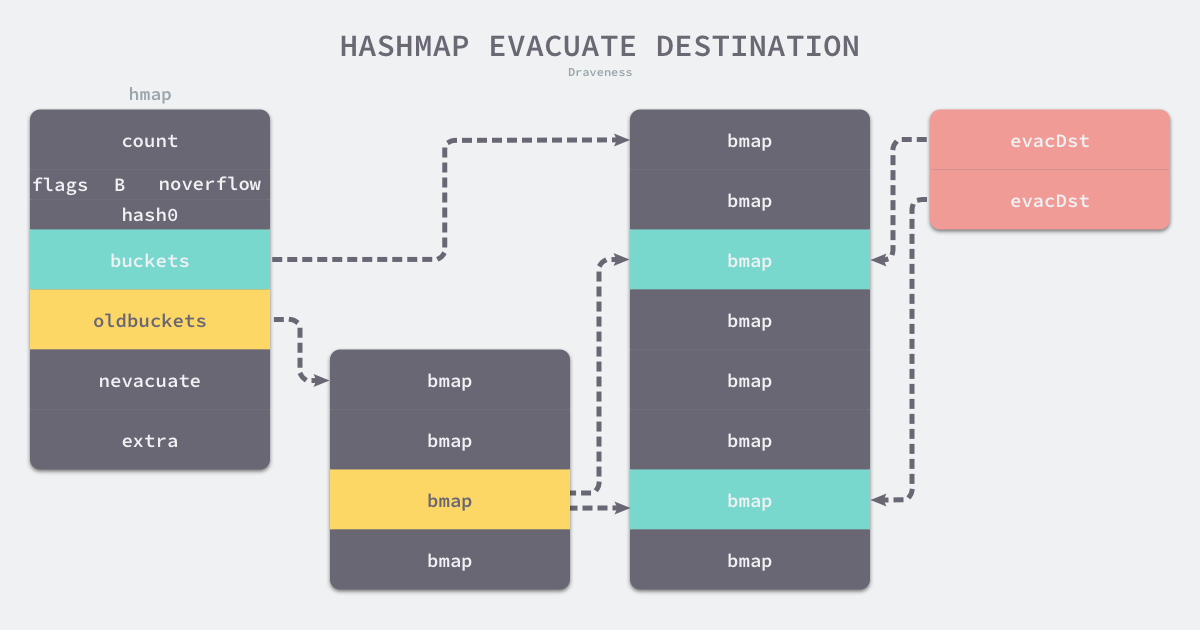
- 等量扩容
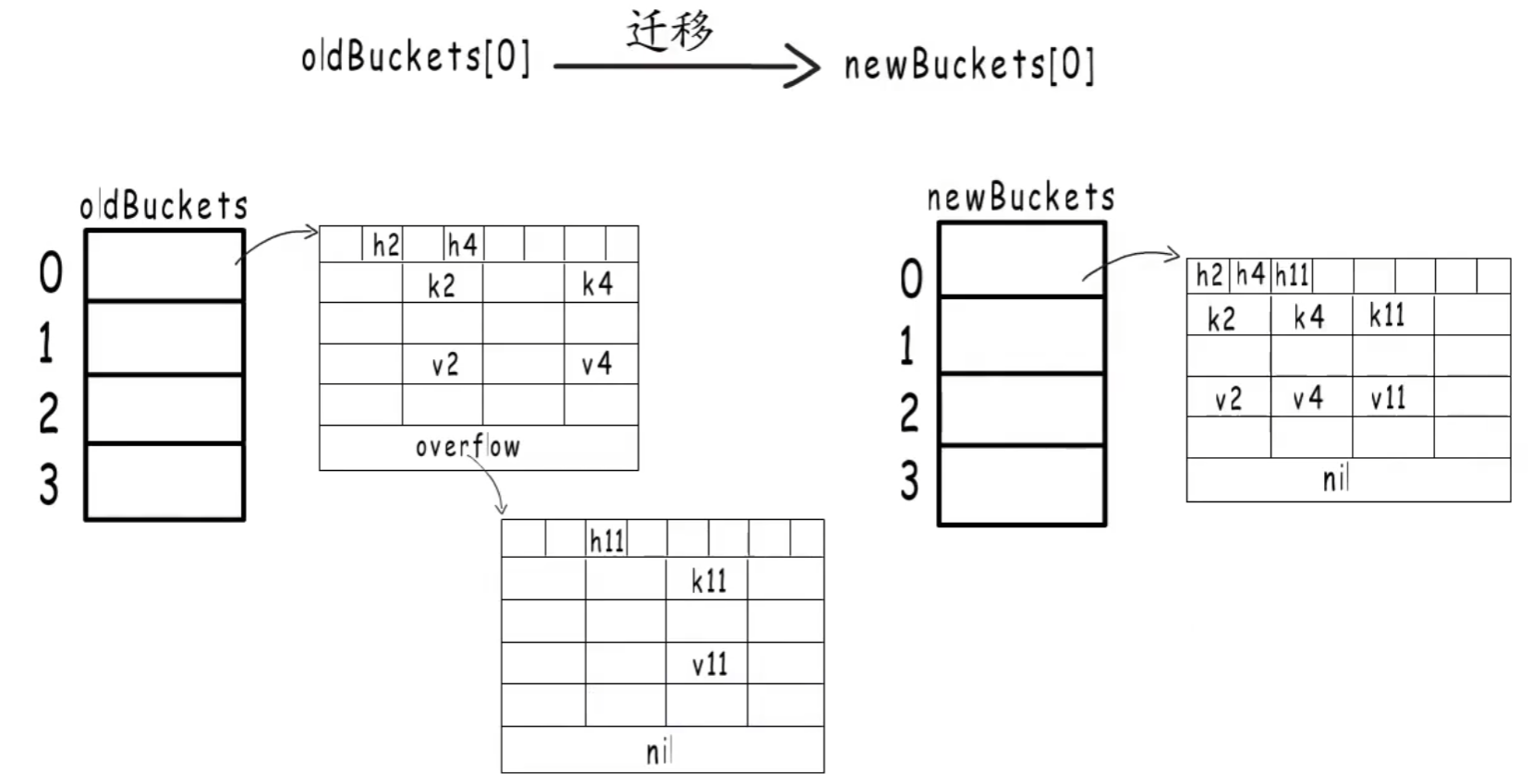
当溢出桶过多,但负载因子又没有超过阈值时,就进行等量扩容。(即条件2)
所谓等量扩容,实际上并不是扩大容量,而是创建和旧桶一样多的新桶,然后搬迁键值对,把松散的键值对重新排列一次,以使 bucket 的使用率更高,进而保证更快的存取。
struct 类型
-
结构体的定义
使用 type 和 struct 关键字来定义结构体,语法如下:
type 类型名 struct { 字段名 字段类型 字段名 字段类型 … }
在 Go 1.9 版本新增了类型别名的新功能,语法如下:
type 类型别名 = 类型名
-
结构体实例化
package main import ( "fmt" ) type A struct { a string b int8 } func main() { //普通实例化 var a1 A //没初始化前,成员变量都是零值 a1.a = "a" a1.b = 1 //匿名结构体 var user struct { Name string Age int } user.Name = "小王子" user.Age = 18 fmt.Printf("%#v\n", user) //struct { Name string; Age int }{Name:"小王子", Age:18} //指针类型结构体 var a2 = new(A) fmt.Printf("%T\n", a2) //*main.A //取结构体的地址实例化 var a3 = &A{} //相当于进行了 new a3.a = "a3" //底层是(*a3).a = "a3",是 Go 语言的语法糖 fmt.Printf("%T\n", a3) //*main.A }
-
构造函数
Go 语言的结构体并没有构造函数,但我们可以通过初始化来简便的实现构造函数。
func newA(a string, b int8) *A {
return &A{
a: a,
b: b,
}
}
//调用构造函数
func main() {
a1 := NewA("a",1)
fmt.Println(a1)
}
-
方法
在 Go 语言中,结构体就像是类的简化形式。但结构体内不允许定义函数,也没有类的概念,怎么定义方法呢?通过绑定类型来实现方法。
Go 语言的方法,是作用在接收者(receiver)上的一个函数,是一种特殊的函数。举个例子:
type Person struct{ name string age int } func (this *Person) GetName() { fmt.Printf(this.Name) } func main(){ person := Person{ Name: "xiaofan", Age: 18, } person.GetName() //执行Person绑定的方法GetName return }
方法与函数的区别是,函数不属于任何类型,方法属于特定的类型。方法的调用看起来就像 C++ 中调用类的成员函数一样 —— 对象.方法。
-
结构体的“继承”
Go 语言中可以通过(组合)结构体嵌套来实现“继承”。
package main import ( "fmt" ) type Person struct { //结构体大写开头 —— 公有 Name string //属性大写开头 —— 公有属性 age int //属性小写开头 —— 私有属性 } func (p *Person) GetName() { //方法大写开头 —— 共有 fmt.Printf("%s\n", p.Name) } type Student struct { Person //这样Student类就可以继承Person类了 score int //student类自己的属性 } func (s *Student) getscore() { //方法小写开头 —— 私有 fmt.Println(s.score) } func main() { stu := Student{} stu.Name = "小饭" //继承父类的属性 stu.score = 100 stu.GetName() //继承父类的方法 stu.getscore() }
Go 语言的公有是可挎包访问,在同一包内 私有属性同样可访问。
-
结构体标签(Tag)
Go的struct声明允许字段附带 Tag 来对字段做一些标记。
Tag 是结构体的元信息,可以在运行的时候通过反射的机制读取出来。 Tag 在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
`key1:"value1" key2:"value2"`
举个例子:
//Student 学生 type Student struct { ID int `json:"id"` //通过指定tag实现json序列化该字段时的key Gender string //json序列化是默认使用字段名作为key name string //私有不能被json包访问 } func main() { s1 := Student{ ID: 1, Gender: "男", name: "学生", } data, err := json.Marshal(s1) if err != nil { fmt.Println("json marshal failed!") return } fmt.Printf("json str:%s\n", data) //json str:{"id":1,"Gender":"男"} }
Tag 常见用法主要是JSON数据解析、ORM映射等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号